 夜雨聆风
夜雨聆风





AI顶会审稿革命?AAAI-26 首次让 AI 审稿人"持证上岗",2.3 万篇论文一天审完,准确性竟被评优于人类专家

封面图
导读:学术同行评审正面临前所未有的规模压力——AAAI-26 单届收到逾 3 万篇投稿,所需审稿委员会规模几乎是上届的三倍。本文报告了有史以来首次在顶级会议全量部署 AI 审稿的真实实验:所有进入全审阶段的 22,977 篇论文,每篇均在 24 小时内获得一份由 AI 系统生成的、明确标注身份的 AI 审稿意见,单篇成本不足 1 美元。大规模用户调查(5,834 份有效问卷)表明:参与者不仅认为 AI 审稿有用,更在技术准确性、研究建议等关键维度上偏好 AI 审稿意见优于人类审稿,为 AI 辅助同行评审的大规模落地提供了迄今最有力的实证支撑。
论文标题:AI-Assisted Peer Review at Scale: The AAAI-26 AI Review Pilot
发表会议:AAAI 2026(Association for the Advancement of Artificial Intelligence)
作者:Joydeep Biswas, Sheila Schoepp, Gautham Vasan, Anthony Opipari, Arthur Zhang, Zichao Hu, Sebastian Joseph, Matthew Lease, Junyi Jessy Li, Peter Stone, Kiri L. Wagstaff, Matthew E. Taylor, Odest Chadwicke Jenkins
单位:The University of Texas at Austin(CS / School of Information / Linguistics);University of Alberta(Computing Science / Alberta Machine Intelligence Institute);University of Michigan(EECS);Oregon State University(The Valley Library);Sony AI
最近我们更新了一系列vibe-coding用于研究物理信息神经网络PINN的推文和教程,期望这种【AI人机协作的全新科研范式】得到充分验证和不断发展。
一句提示词,Gemini 3.1 高效高精度实现物理信息神经网络PINNs求解高频PDEs——与Claude Sonnet 4.6的正面交锋(一)(附代码和提示词)
10天产出100篇科研论文,claude code类AI智能体正在重新定义”做科研”
Vibe Coding&Vibe Researching科研系列(一):神经切线核NTK的自适应权重物理信息神经网络PINN求解高频波动方程
Physics-Informed Vibe Coding(2)||NTK自适应加权+多尺度物理信息神经网络求解高频PDEs
Physics-Informed Vibe Coding(3)||变量尺度变换物理信息神经网络求解Navier-Stokes 方程
Physics-Informed Vibe Coding(4):物理信息神经网络训练经常失败?试试梯度自适应加权PINN
Physics-Informed Vibe Coding(5)||仅需100秒,Scale-PINN仿真Navier-Stokes方程Re=7500

系列教程开源代码地址
有帮助的话,请给我们点一颗star收藏!
https://github.com/xgxgnpu/Physics-informed-vibe-coding
https://github.com/xgxgnpu/Physics-informed-vibe-coding
https://github.com/xgxgnpu/Physics-informed-vibe-coding
一、研究背景与问题动机
1.1 学术评审的规模危机
科学出版的体量正在以加速度膨胀。AAAI-26 收到逾 30,000 篇初始投稿,相较 AAAI-25 的约 15,000 篇翻倍增长;Nature 期刊指数在 2024 年同比增长 16%;NeurIPS 的投稿量同样呈指数级上升趋势。
问题核心:审稿人资源的增长速度远跟不上投稿量的增速。AAAI-26 的审稿委员会规模超过 28,000 人(程序委员会成员 PC、高级程序委员会成员 SPC 及领域主席 AC),几乎是 AAAI-25 的三倍。这意味着招募经验不足的审稿人比例不断上升,审稿质量的方差持续扩大,审稿时间也愈发压缩。
在此背景下,AI 辅助评审的研究迅速升温。然而,此前的研究大多局限于:
-
以历史论文为基础的事后评估(post-hoc study),缺乏真实部署的实证 -
聚焦于有限方面的评审辅助(如 NeurIPS-24 的作者核查清单、ICLR-25 的审稿人反馈) -
从未在顶级会议全量论文上完整部署 AI 生成的审稿意见
因此,一个关键问题始终悬而未决:当前最先进的 AI 系统,能否在真实会议规模下生成技术上有意义、实践中切实有用的审稿意见?
AAAI-26 的 AI 审稿试点项目(AI Review Pilot Program)正是为回答这一问题而设计的首个全规模真实实验。
1.2 先验工作的局限
既有研究揭示了一个共同结论:直接要求现成 LLM 进行论文评审,效果并不理想。单一 prompt 的审稿系统在技术错误识别、文献综述准确性等维度上表现平庸,生成的评审意见往往流于表面。
近期工作开始探索更结构化的审稿方案,包括:
-
基于层次化问题分解的深度推理(TreeReview) -
结合多模态智能体与共享记忆的评审设计(Agent Reviewers) -
分阶段的多步推理框架(DeepReview)
AAAI-26 AI 审稿系统正是在此基础上设计的多阶段、多工具、多模型协作流水线。
二、AAAI-26 AI 审稿系统的设计架构
2.1 整体流程
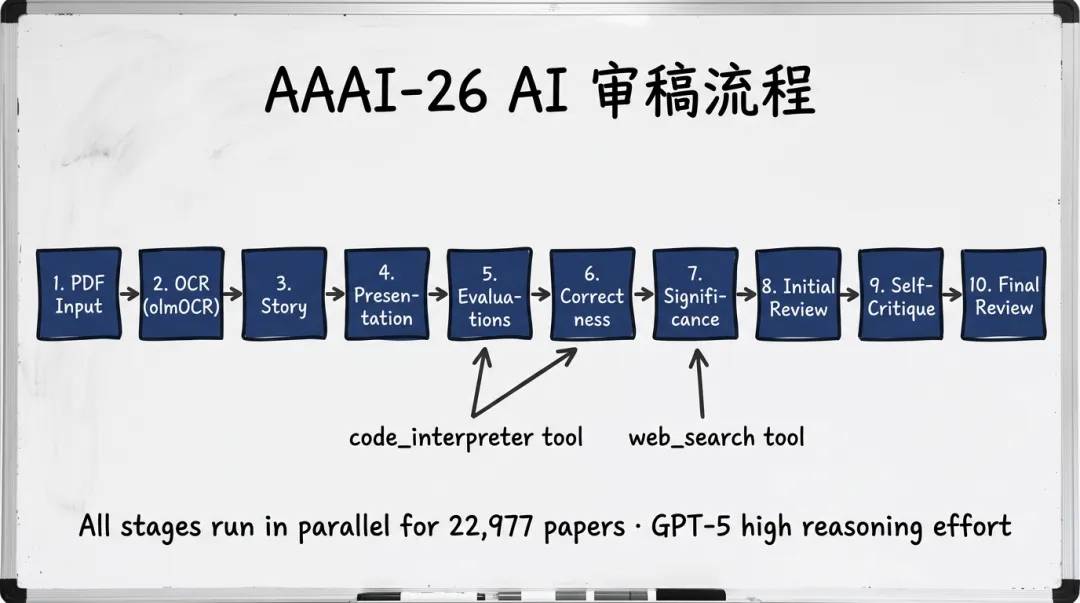
系统以论文 PDF 为唯一输入,经过预处理后进入多阶段评审流水线,最终输出一份结构化的 Markdown 格式审稿意见。
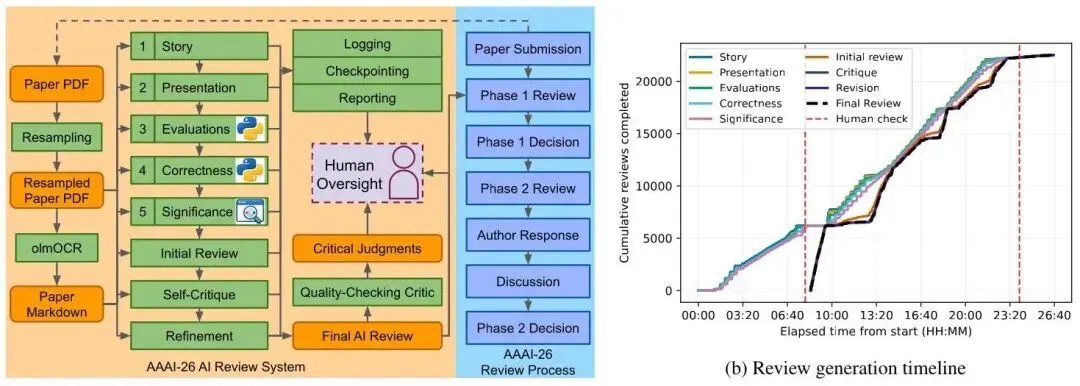
图1:左图为 AI 审稿系统的五阶段架构及自我批评修订流程;右图为所有 22,977 篇论文的审稿生成时间线,展示了先处理 30% 样本进行人工抽查、再推进全量生成的分批策略。
完整流程共分为以下阶段:
预处理阶段
-
对论文 PDF 重采样至 250 DPI(控制图像 token 消耗,避免超出上下文窗口) -
使用专业 OCR 工具 olmOCR 将 PDF 转为 Markdown,保留 LaTeX 数学公式与表格结构(这对准确理解方程式和表格至关重要,单纯使用 PDF 会导致数学符号误读)
核心五阶段评审(SPECS)3. Story(问题陈述与故事完整性) 4. Presentation(清晰度、组织性、可读性) 5. Evaluations(基线、指标、统计证据、可重复性)——启用 code_interpreter 工具 6. Correctness(方程、证明、算法、图表正确性)——启用 code_interpreter 工具 7. Significance(文献定位、新颖性、与已发表工作的竞争力)——启用 web_search 工具
综合与修订阶段8. Initial Review:综合五阶段所有发现,生成初始结构化审稿 9. Self-Critique:对初始审稿进行自我批评,标记无依据的断言、事实错误与引用问题 10. Final Review:依据自我批评修订并输出最终审稿
每篇论文同时提供 PDF 和 Markdown 两个版本供模型交叉参考。最终审稿报告包含:论文标题、摘要概述、审稿摘要、优点列表、不足列表、APA 格式参考文献。
部署细节:AAAI-26 采用两阶段评审流程。AI 审稿在第一阶段与至少两份人类审稿同时发放。AI 审稿不包含打分或录用建议,也不替代任何人类审稿员。SPC 和 AC 可在决定是否将论文推进至第二阶段时参考 AI 审稿。进入第二阶段的论文将收到额外的人类审稿,作者有机会就包括 AI 审稿在内的所有审稿意见进行反驳(rebuttal)。
2.2 LLM 技术选型
系统使用 OpenAI GPT-5(high 推理模式)作为所有阶段的核心模型,该模型具有:
-
400,000 token 上下文窗口,128,000 token 最大输出(含推理 token) -
知识截止日期:2024 年 9 月 30 日 -
Zero Data Retention(ZDR)协议:模型输入输出均不被 OpenAI 日志记录,仅驻留于临时内存,以保障论文双盲保密性
所有 API 调用均采用 flex tier,并实现了指数退避(exponential backoff)的错误重试逻辑(最多 5 次重试),以应对大批量并行处理时的限流和服务器负载波动。
2.3 核心数学模型:调查响应的量化分析
论文对 AI 审稿与人类审稿的比较采用了严格的统计框架。设 和 分别为作者群体对 AI 审稿和人类审稿的问卷响应集合, 和 为审稿委员群体的对应响应集合。
均值计算:对任意响应集合 ,均值定义为
其中 为响应总数, 为五点 Likert 量表的得分。
分组差异:作者群体和审稿委员群体分别计算 AI 与人类审稿的均值差异:
加权总体均值:综合所有参与者(作者+审稿委员)的总体均值采用加权平均:
统计检验:采用 Mann-Whitney U 检验(非参数检验)评估 AI 与人类审稿响应分布差异的统计显著性,零假设为两个响应集合来自同一分布。所有 9 项评审质量维度的 AI-人类差异均在 显著性水平下统计显著。
方法论要点:Mann-Whitney U 检验对分布形状无正态假设,适合有序 Likert 量表数据的非参数比较,较 t 检验更为稳健。
2.4 prompt 设计策略
系统采用分层 prompt 架构,而非单一的整体指令,具体包含 9 个提示组件:
|
|
|
|
|---|---|---|
| 基础指令 |
|
|
| Story 提示 |
|
|
| Presentation 提示 |
|
|
| Evaluations 提示 |
|
|
| Correctness 提示 |
|
|
| Significance 提示 |
|
|
| Initial Review 提示 |
|
|
| Self-Critique 提示 |
|
|
| Final Review 提示 |
|
|
注意:出于防止 prompt 注入攻击和针对性优化的安全考虑,论文未公开具体的 prompt 文本,仅披露提示组件的结构和功能描述。
三、SPECS 基准评测:量化 AI 审稿质量
3.1 基准设计动机
现有的 AI 审稿评测基准存在明显局限:
-
FLAWS 基准:仅关注技术错误,且要求结构化输出格式,而非自由文本全量审稿 -
其他基准:仅评估审稿分数与人类的一致性,或针对特定错误类型
为此,论文提出 SPECS(Story, Presentation, Evaluations, Correctness, Significance)基准,在五个维度上综合评估 AI 审稿的错误检测能力,并以自由文本格式的完整审稿为评估对象。
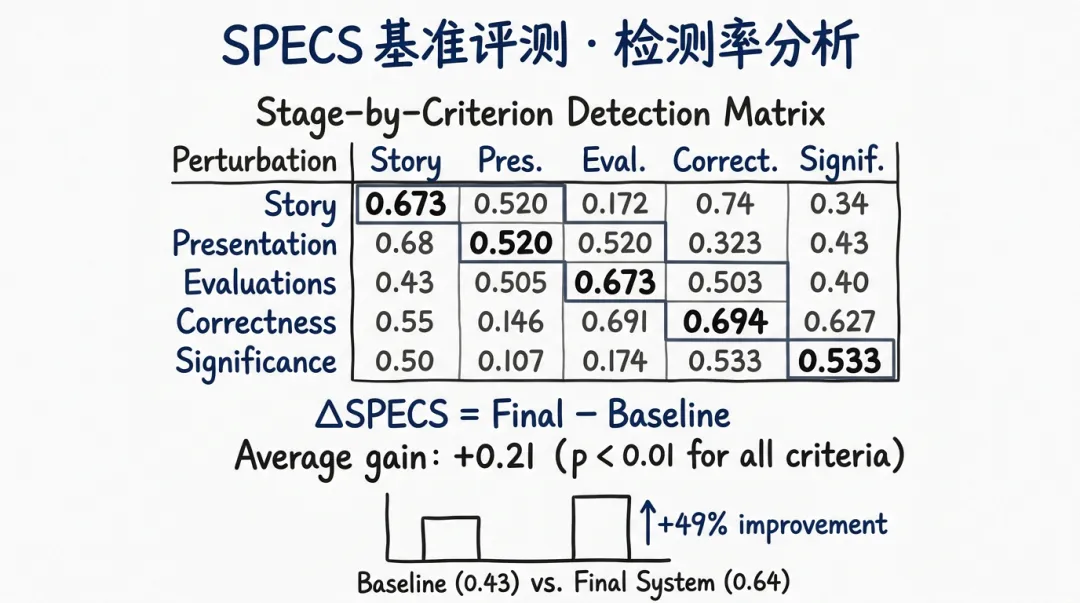
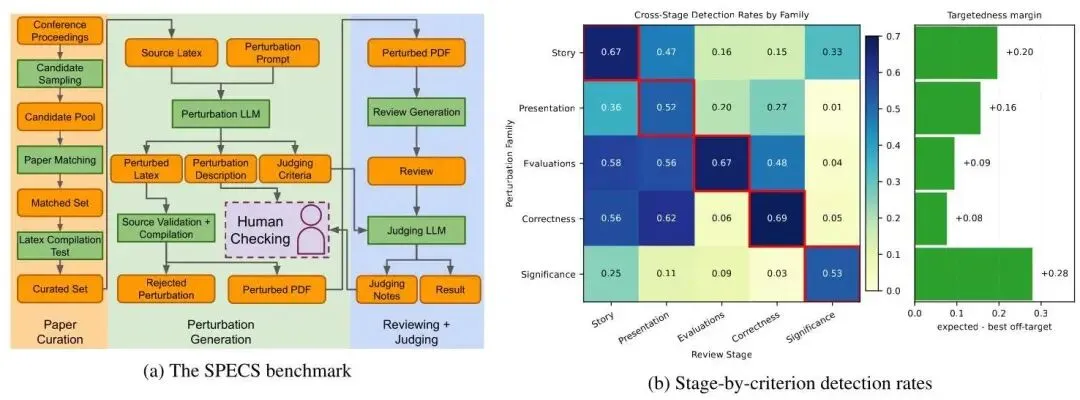
图4:左图为 SPECS 基准的数据构建流程(从 AAAI-25 论文集→arXiv 匹配→LaTeX 扰动生成→编译验证);右图为各审稿阶段在各 SPECS 维度上的检测率矩阵,对角线元素均为最高值,证明每个阶段对其目标维度的专项检测效果最强。
3.2 基准数据构建流程
论文筛选:从 AAAI-25 论文集中采样,匹配 arXiv 版本并下载 LaTeX 源码,要求 LaTeX 能无错编译,最终获得 120 篇论文,涵盖游戏论(32.5%)、机器学习(25.0%)、知识表示(11.7%)等 8 个类别。
扰动生成:对每篇论文,使用 LLM(GPT-5.4,high 推理)在 LaTeX 源码层面注入五类科学错误(SPECS 五维度)。一个扰动被接受的条件:
-
识别的原始源码片段必须精确匹配论文源文件(正确的文件名和行号) -
修改后的 LaTeX 源码必须能无错编译
最终生成 783 个合成扰动,分布:Story 153(19.5%)、Presentation 173(22.1%)、Evaluations 159(20.3%)、Correctness 144(18.4%)、Significance 154(19.7%)。
人工验证:随机抽取 35 个扰动,由两位独立人工审核员评估。结果:22/35 的扰动被一致认定为应当在审稿中指出的显著科学错误,9 个为不值一提的轻微问题,4 个有分歧。说明基准的有效扰动率约为 63%,具有较高的实质性。
3.3 SPECS 基准实验结果
系统对每个扰动论文生成完整审稿,并使用裁判 LLM 判断审稿是否明确识别了注入的错误(需提供支撑文本片段)。
|
|
|
|
|
|
|
|---|---|---|---|---|---|
| Story |
|
|
0.673 |
|
|
| Presentation |
|
|
0.567 |
|
|
| Evaluations |
|
|
0.755 |
|
|
| Correctness |
|
|
0.764 |
|
|
| Significance |
|
|
0.448 |
|
|
| 全部 SPECS |
|
|
0.639 |
|
+0.210 |
关键发现:与单一 prompt 基线相比,完整 AAAI-26 AI 审稿系统在所有 SPECS 维度上均实现了统计显著提升(),**平均增益 **(使用双侧精确 McNemar 检验,)。这是已知的对 AI 审稿多阶段框架优越性的最强统计证据之一。
靶向性验证:图4(b) 中的检测率矩阵表明,每个专项阶段对其目标维度的检测率均高于其他维度(对角线元素最大),证明系统的分工设计具有实质性的靶向效果,并非每个阶段对所有维度均等有效。
值得注意的是:Significance 维度的完整系统(0.448)略低于目标阶段(0.533),说明某些 Significance 错误在目标阶段被正确识别后,可能在最终审稿整合过程中被隐含处理而未显式标注——这揭示了系统在”信息蒸馏”阶段存在的信息丢失问题,是未来改进的方向之一。
四、核心结果:大规模用户调查
4.1 调查设计与规模
调查针对所有参与者(作者、PC、SPC、AC)发放,采用五点 Likert 量表(-2:强烈反对,-1:反对,0:中立,1:赞同,2:强烈赞同)评估 9 项评审质量标准及一系列 AI 审稿专项问题。
参与规模(有效响应):
|
|
|
|
|---|---|---|
| 作者(Author) |
|
|
| 程序委员(PC) |
|
|
| 高级程序委员(SPC) |
|
|
| 领域主席(AC) |
|
|
| 合计 | 2009 | 3825 |
总计有效响应 5,834 份,样本量足以保障在 水平下达到强统计显著性。
4.2 量化分析:AI vs. 人类审稿,9 项维度对比
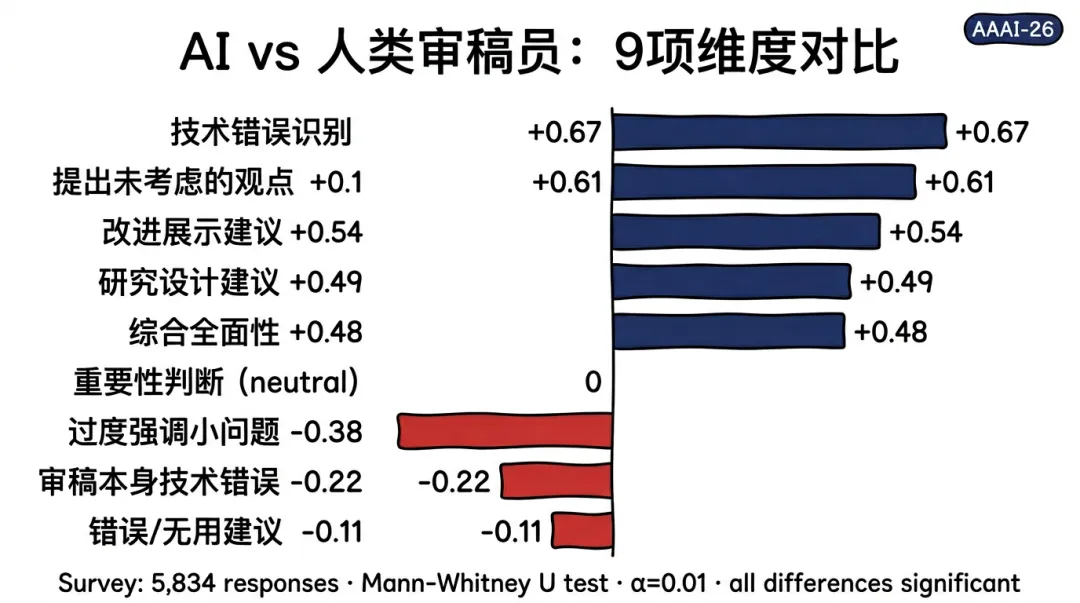
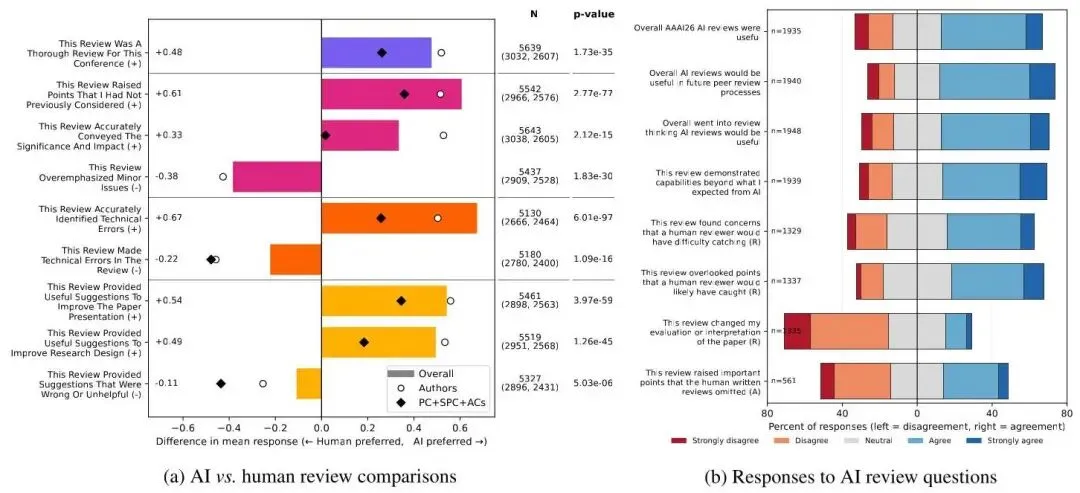
图2:左图展示 9 项评审质量标准的 AI-人类均值差异;右图为 AI 审稿专项问题的响应分布。
在 9 项评审质量标准中,AI 审稿在 6/9 项优于人类审稿,所有 9 项差异均在 下统计显著:
AI 优势显著(正向差异,共 6 项):
-
🔴 技术错误识别:(五点量表上最大的单项优势,AI 识别技术错误能力显著强于人类) -
🔴 提出未被考虑的观点:(AI 能系统性挖掘人类审稿员未提及的潜在问题) -
改进展示的建议:(写作与排版层面的具体可操作意见) -
改进研究设计的建议:(对实验设计缺陷的更系统性识别) -
综合全面性:(审稿覆盖维度更广,遗漏率更低) -
准确传达重要性与影响:小幅正向(论文报告 6/9 均为正,此项差距相对前五项较小)
AI 相对劣势(负向差异,共 3 项):
-
🔵 过度强调次要问题:(最显著劣势——全面性的代价是”鸡蛋里挑骨头”) -
审稿本身的技术错误:(AI 在读取复杂公式和表格时仍会误读) -
错误或无用建议:(小比例建议被认为不正确或无实际意义)
重要观察:作者群体的差异效应量普遍大于审稿委员(PC/SPC/AC)群体,说明直接接受评审的作者群体对 AI 审稿的正面感受更为突出。
4.3 AI 审稿整体有用性评估
对 AI 审稿专项问题的响应结果如下:
-
53.9% 的受访者认为 AI 审稿有用,仅 20.2% 认为无用 -
61.5% 认为 AI 审稿在未来评审中将有用,仅 14.5% 认为无用 -
57.8% 事前预期 AI 审稿有用,16.8% 持负面预期 -
55.6% 表示 AI 审稿展示了超出其预期的能力
关于 AI 与人类审稿的互补性(PC/SPC/AC 群体):
-
46.6% 认为 AI 发现了人类审稿员难以发现的问题;21.3% 不认为 -
49.4% 认为 AI 遗漏了人类审稿员可能抓住的问题;14.0% 不认为
这两组数据共同指向一个重要结论:受访者将 AI 审稿定位为人类审稿的互补而非替代。
仅 13.8% 的审稿委员表示 AI 审稿改变了其对论文的评价,55.6% 表示没有改变。
4.4 质性分析:五大正面与负面主题
论文收集了 320 份有效的开放式自由文本反馈,采用 LLM 辅助的主题分类方法(GPT-5.4,high reasoning)抽取主题,再由人工验证。

图3:AAAI-26 AI 审稿的前五大正面与负面主题,百分比为该主题在所有专项分类提及中的占比。
前五大正面主题:
-
可操作的修改建议(Actionable Revision Guidance):AI 擅长将批评转化为具体的改进指导 -
广度与全面性(Breadth and Thoroughness):审稿覆盖面广,不遗漏细节 -
技术错误检测(Technical Error Detection):能识别人类审稿员可能忽略的技术问题 -
相对客观性与一致性(Relative Objectivity and Consistency):受主观偏见影响较小 -
展示与写作润色(Presentation and Writing Polish):能检测排版错误与写作问题
前五大负面主题:
-
整体意义判断薄弱(Weak Big-Picture Judgment):对贡献新颖性和科学影响的判断能力不足 -
过度纠结小问题(Nitpicking and Overemphasis on Minor Issues):本质上是全面性的副作用 -
过于冗长,认知负担重(Excessive Verbosity and Cognitive Overload):长度超过读者偏好 -
事实错误与误读(Factual Errors and Misreadings):尤其在读取复杂方程与表格时 -
上下文与领域理解浅层化(Shallow Contextual and Domain Understanding):缺乏领域专家的深度背景知识
五、核心代码解读:系统实现关键细节
5.1 PDF 预处理:上下文窗口管理
# PDF 预处理:将所有图像重采样至 250 DPI# 目的:控制 PDF 转 token 时的图像 token 消耗量# OpenAI 视觉模型处理 PDF 时会同时提取文本和渲染页面图像# 因此 PDF 的 token 消耗包含文本内容和视觉内容两部分defpreprocess_pdf(pdf_path, target_dpi=250):""" 将 PDF 重采样至目标 DPI,控制多模态 token 消耗 GPT-5 上下文窗口:400,000 token(含推理 token) """# 重采样逻辑(使用 pdf2image 或 pymupdf 等库) images = convert_from_path(pdf_path, dpi=target_dpi)return images5.2 OCR 转 Markdown:数学公式精确保留
# 使用 olmOCR 将 PDF 转为保留 LaTeX 的 Markdown# 关键:PDF 版本单独使用时,LLM 经常误读数学符号# 测试中发现:仅 PDF 输入会导致生成的审稿出现数学解读错误# 因此系统向所有后续阶段同时提供 PDF + Markdown 两个版本defconvert_to_markdown(pdf_path):""" olmOCR: 将 PDF 转为包含 LaTeX 数学公式和结构化表格的 Markdown 输出包含:$...$ 内联公式、$$...$$ 块级公式、| | 格式表格 """ markdown = olmocr_convert(pdf_path)return markdown5.3 多阶段审稿流水线(伪代码)
# 五阶段 SPECS 评审核心逻辑SPECS_STAGES = ["story", "presentation", "evaluations", "correctness", "significance"]TOOLS = {"evaluations": ["code_interpreter"],"correctness": ["code_interpreter"],"significance": ["web_search_preview"], # 仅限已发表工作}defgenerate_review(pdf_path, markdown_path): context = {"pdf": pdf_path,"markdown": markdown_path,"base_instruction": BASE_INSTRUCTION, # 所有阶段共享的基础指令"stage_outputs": {} }# 五阶段串行执行(每阶段可见所有前序阶段输出)for stage in SPECS_STAGES: tools = TOOLS.get(stage, []) stage_prompt = load_stage_prompt(stage)# GPT-5 high reasoning effort,含指数退避重试(最多 5 次) output = call_gpt5( context=context, stage_prompt=stage_prompt, tools=tools, reasoning_effort="high", max_retries=5, backoff="exponential" ) context["stage_outputs"][stage] = output# 综合生成初始审稿 initial_review = generate_initial_review(context)# 自我批评阶段(不提供原始 prompt,避免偏见) critique = self_critique(initial_review, context["pdf"])# 依据批评修订,输出最终审稿(Markdown 格式) final_review = revise_with_critique(initial_review, critique)return final_review# 质量检查:使用 o4-mini 作为批评模型defquality_check(review):""" 检查项目: 1. 是否暴露作者身份 2. 是否含有冒犯性内容 3. 是否存在性别/地域等偏见判断 4. 是否缺失结构性元素 5. 伦理问题、格式违规等 """ critic_output = call_o4mini(review, critic_prompt)return critic_output5.4 引用幻觉检测
系统对随机抽取的 100 份审稿(共 1,356 条引用)使用 GPTZero API 进行引用验证:
-
1,346 条:被标记为有效并匹配到已发表文献(正确的作者、标题、期刊/会议) -
8 条:标记为”不确定”(人工复核后实为正确引用) -
2 条:标记为”虚假”(人工复核:1 条实际存在但为技术手册非期刊论文;1 条论文存在但期刊名有误)
**实际引用幻觉率约为 1/1356 ≈ 0.07%**,远低于公众对 LLM 引用可靠性的普遍预期。需注意,这一检测使用了 GPTZero API(专为识别 LLM 生成引用而设计),而非人工逐条核查,且仅针对随机抽取的 100 份样本,实际分布可能存在偏差——但结果仍具有重要的参考价值。
六、总结与展望
6.1 核心贡献总结
本文的主要贡献可从三个层面归纳:
实践层面:在 AAAI-26 这一顶级 AI 会议的真实评审流程中,成功完成了有史以来规模最大的 AI 审稿部署实验。22,977 篇论文、24 小时内、<$1/篇——这三个数字证明了 AI 辅助评审在真实会议规模下的操作可行性。
质量层面:大规模用户调查(5,834 份有效响应)显示,在 9 项评审质量维度中,AI 审稿在 6 项上获得了参与者的更高评分,尤其是技术错误识别(+0.67)和提出未被考虑的新观点(+0.61)两项领先优势最为突出,且所有差异均达到强统计显著性()。
基准层面:SPECS 基准提供了一套可复现的、覆盖五个评审维度的综合评测框架,为后续 AI 审稿系统的研发和比较提供了标准化工具。完整系统相对单一 prompt 基线的平均检测率提升 +0.21(p 远小于 0.01)。
6.2 当前局限性
即便取得了上述成果,以下局限性不容忽视:
-
重要性与新颖性判断薄弱:这是质性反馈中最频繁提及的缺陷。判断一项贡献的真正科学意义,需要对领域发展脉络的深度理解,这超出了当前 LLM 的能力边界。
-
数学公式与复杂表格的误读:尽管使用了 olmOCR,仍有部分公式和表格未能被准确解析,导致 Correctness 阶段出现误判。
-
过度冗长:AI 审稿的篇幅超出了多数参与者的偏好,增加了认知负担。这是一个相对容易通过输出长度控制来缓解的工程问题。
-
自选择偏差:调查为自愿参与,实际响应者为 5,834 人,而调查对象涵盖所有论文作者与 28,000+ 名审稿委员,响应率有限。倾向于参与调查的个体(例如对 AI 审稿持强烈态度者)可能与未参与者系统性地不同,这对调查结论的外部推广性构成潜在威胁。
-
知识截止日期的限制:GPT-5 的知识截止于 2024 年 9 月,对于 Significance 阶段的文献核查(尤其是 2024 年底至 2025 年的新工作)存在盲区。
6.3 未来值得探索的方向
值得重点关注的研究空白:
① 人机协同的最优分工模式
本研究的调查结果清晰显示:AI 审稿擅长技术细节检测,人类审稿擅长整体意义判断。如何设计人机协同的分工架构——例如 AI 完成技术审查,人类专注于科学意义评估——是下一代评审系统最核心的研究问题。
② AI 审稿对审稿人行为的长期影响
当前证据显示仅 13.8% 的审稿委员表示 AI 审稿改变了其判断,但长期效应尚不清楚。未来需要研究:AI 审稿是否会导致人类审稿员过度依赖 AI 意见(anchoring 效应),进而产生”AI 认同偏差”?
③ 防止论文针对 AI 偏好优化
部分调查参与者提出了一个值得警惕的风险:作者可能会根据 AI 审稿系统的已知偏好来优化论文呈现,而非提升真实科学质量。这是一个对抗性适应(adversarial adaptation)问题,需要审稿系统的持续更新和多样性设计。
④ 跨学科与非英语领域的适用性
本研究集中于 AI/CS 领域的英语论文。AI 审稿系统对物理、生命科学、社会科学等领域论文的适用性,以及对非英语母语论文的处理能力,有待系统性验证。
⑤ 动态 SPECS 基准的持续维护
SPECS 基准的数据集基于 AAAI-25 论文,具有时效性。随着 LLM 训练数据截止日期推进,需要定期用新论文更新基准,以维持评估的有效性,防止数据污染(data contamination)导致评测虚高。
⑥ 成本持续下降的战略影响
当前成本已低于 $1/篇,若 LLM 推理成本按历史趋势继续下降,未来单篇成本可能降至分位级别。这将从根本上改变同行评审的经济学,有必要提前研究这一变化对学术发表生态的影响。
编者按:AAAI-26 的 AI 审稿实验,是科学同行评审走向人机协同时代的一个清晰的里程碑。它告诉我们:AI 审稿在技术层面已经足够成熟,足以在真实顶会场景中有益于科研共同体;但它同时也以 的”过度纠结小问题”这一缺陷,提醒我们 AI 还不能替代人类对科学意义的整体判断。互补而非替代,或许是未来最可持续的人机协同评审范式。
参考文献(关键引用):
-
Biswas et al., “AI-Assisted Peer Review at Scale: The AAAI-26 AI Review Pilot,” AAAI 2026 -
Liang et al., “Can Large Language Models Provide Useful Feedback on Research Papers?” NEJM AI, 2024 -
Liu & Shah, “ReviewerGPT? An Exploratory Study on Using Large Language Models for Paper Reviewing,” arXiv 2023 -
Xi et al., “FLAWS: A Benchmark for Error Identification and Localization in Scientific Papers,” arXiv 2025 -
Poznanski et al., “olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models,” arXiv 2025 -
Thakkar et al., “A large-scale randomized study of large language model feedback in peer review,” Nature Machine Intelligence, 2026 -
Naddaf, “More than half of researchers now use AI for peer review—often against guidance,” Nature, 2026