 夜雨聆风
夜雨聆风





从 Claude Code 的源码与公关,看透 Agent 记忆系统设计的 4 个胜负手
本文价值速览
如果你正在设计一个 Agent,那么你一定绕不开“记忆”。但市面上的技术文章往往只教你“如何调包”,却很少告诉你“真正的坑在哪里”。
今天,我们借一次真实的工业级案例——Claude Code 源码泄露与其官方公告的微妙差异——为你拆解 Agent 记忆系统的 4 个核心博弈点。
读完之后,你不仅会知道“该怎么选”,还会理解“为什么这么选”。当你的同事还在争论用 Redis 还是 Pinecone 时,你可以把这篇文章甩给他,告诉他:“问题根本不在于向量数据库。”
引言:一次泄露,撕开了“记忆”的包装纸
2026年,Claude Code 的部分源码意外泄露。在工程师们争相翻阅的同时,Anthropic 官方很快发布了一篇题为《Claude 托管代理的内置记忆功能》的公告,宣布记忆功能进入公测。
如果我们把两份材料放在一起对比阅读,会发现一件很有意思的事:官方在讲“能做什么”,而源码在讲“实际是怎么做的”。 两者之间存在一种微妙的“纪实与修辞”的张力。
我们不想在这里做阴谋论的推手。但作为一个技术频道的编辑,我必须指出:这种差异恰好为我们提供了一个绝佳的教学样本。在一个数据即壁垒的时代,Agent 的记忆系统绝不仅仅是一个技术组件,它是产品策略、用户信任和工程现实的交汇点。
当官方宣布“记忆由服务器智能优化处理”时,源码却忠实地展示了一套精密、完备的本地文件级记忆管理逻辑。有人说,这是产品化对技术真相的公关梳理;而我们更愿意说,这恰好印证了一条铁律:
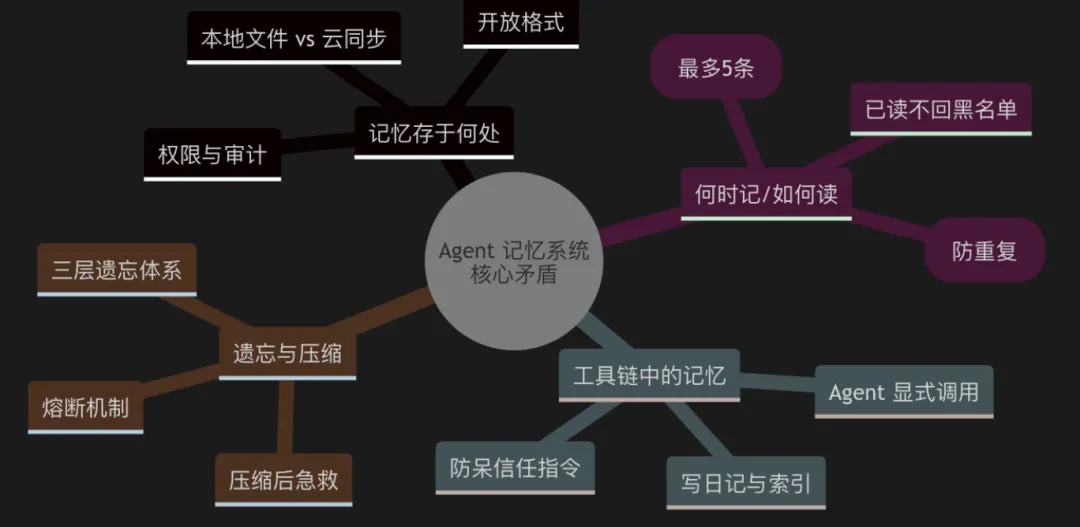
一个成熟 Agent 的记忆系统,其核心矛盾从来不是“记什么”,而是“谁控制记忆,以及记忆如何被消费”。
下面,我们就以这次事件为引,从四个维度拆解 Agent 记忆系统的设计要点。你会发现,那些真正重要的决策,往往发生在你看不到的地方。
第一章 Agent记忆存于何处?——文件、数据库与“可移植”的迷思
官方想让你知道的
Claude Code 的公告开宗明义,强调记忆是“以文件形式存在”的,并且可以“导出、通过 API 管理、完全控制代理所保留的内容”。他们称之为“可移植记忆”,并给出了 Netflix、Rakuten 等客户案例,证明企业可以跨会话、跨代理地共享记忆,同时拥有详细的审计日志。
听起来完美无缺:你拥有你 Agent 的记忆,就像你拥有你的 Word 文档一样。
源码告诉你的实情
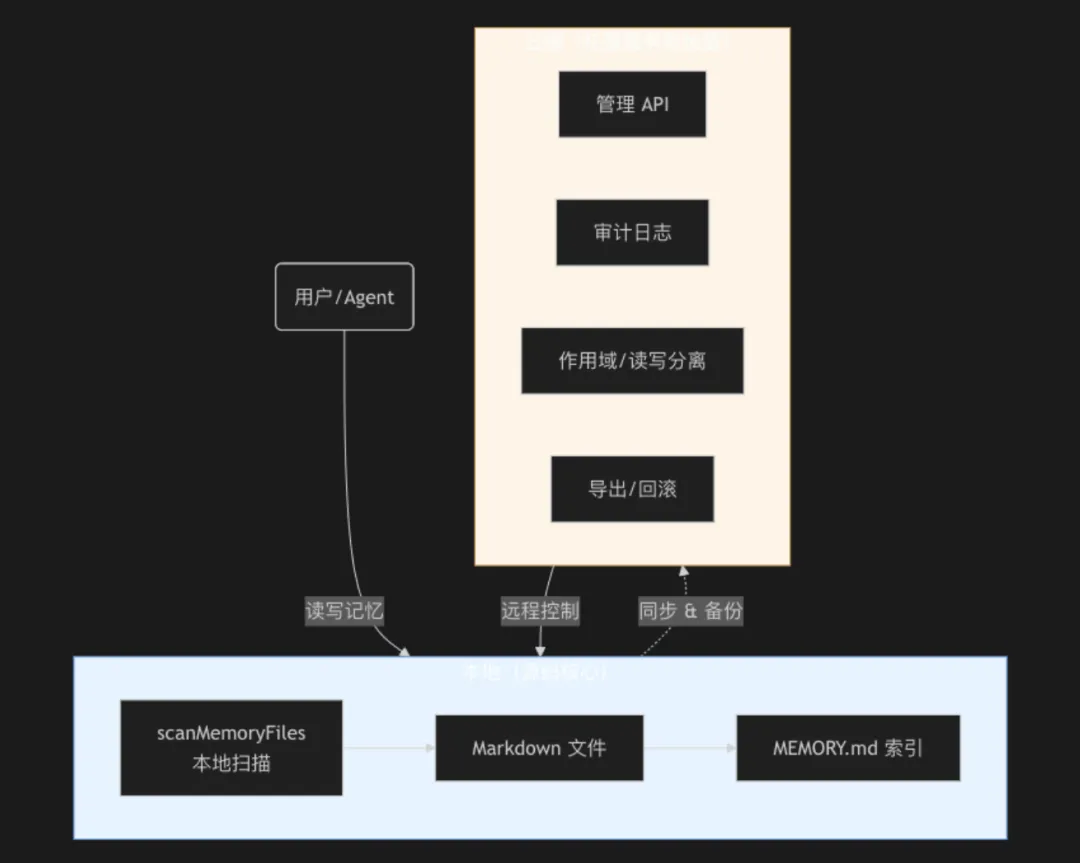
让我们翻开泄露的源码,找到 loadAgentMemoryPrompt 函数。你会发现,Agent 的记忆系统本质上是一个基于 Markdown 文件的文件系统。它在本地维护一个 MEMORY.md 作为索引文件,其他记忆则分类存储为独立的 Markdown 文件。
更重要的是,在底层的 scanMemoryFiles 函数中,记忆的选择和加载完全是本地优先的。它扫描指定目录,解析 Markdown 头部,然后交给模型去判断哪些记忆对当前查询有帮助——这一切,在没有网络请求的情况下完全可以运行。
而公告中提到的“审计日志”、“作用域权限”、“只读与读写分离”,在源码中是看不到强绑定的。这些能力更像是服务端包装层提供的附加值服务,而不是记忆核心的本来面貌。
这对你意味着什么?——设计决策 1:存储形态决定信任边界
当你为自己的 Agent 设计记忆模块时,你需要问自己的第一个问题不是“存多少”,而是“谁拥有这些记忆的所有权?”
这里有一个看似矛盾却至关重要的辨析:文件系统存储与数据收集并非互斥,而是叠加关系。
Claude Code 的记忆同时存在于客户端本地(用户可控的 .md 文件)和服务端(为托管代理提供长期记忆优化)。这恰恰揭露了现代 Agent 产品的通用策略:本地存储赢得开发者信任,服务端同步实现产品闭环。 没错,将记忆同步到服务器确实可以收集人类反馈数据、优化模型,但前提是你必须先让用户敢于把记忆写下来。
因此,你的设计清单上应该写下:
- 透明分层:
明确告知用户,哪些记忆存本地、哪些会同步云端。本地部分应具备独立运行能力,不依赖服务端即可工作。 - 可移植第一:
选择开放格式(如 Markdown、JSON Lines)作为持久化格式,而非私有二进制。这是给用户的“逃生舱”。 - 权限设计前置
:如果未来要做多用户、多代理共享,现在就要考虑基于文件的权限映射。比如,将来你可以为每个用户生成独立的目录和 .gitignore式的访问控制,而不是用中心化数据库的 RBAC 去生搬硬套。
记住:用户对 Agent 的信任,始于他们能亲手打开一个 .md 文件。
第二章 何时记,如何读?——记忆的写入过滤与按需召回
官方描述的“智能”滤镜
公告说,Claude Code 使用“一种经智能优化的记忆层”,代理可以“跨会话逐步改进,并相互分享所学到的内容”。它强调“判断特定任务应该记住哪些内容时更加精准”。但究竟如何精准?话止于此。
源码里的“防御式读写”
这一部分,源码简直是一本教科书。让我们聚焦 queryloop 函数周围的记忆处理:
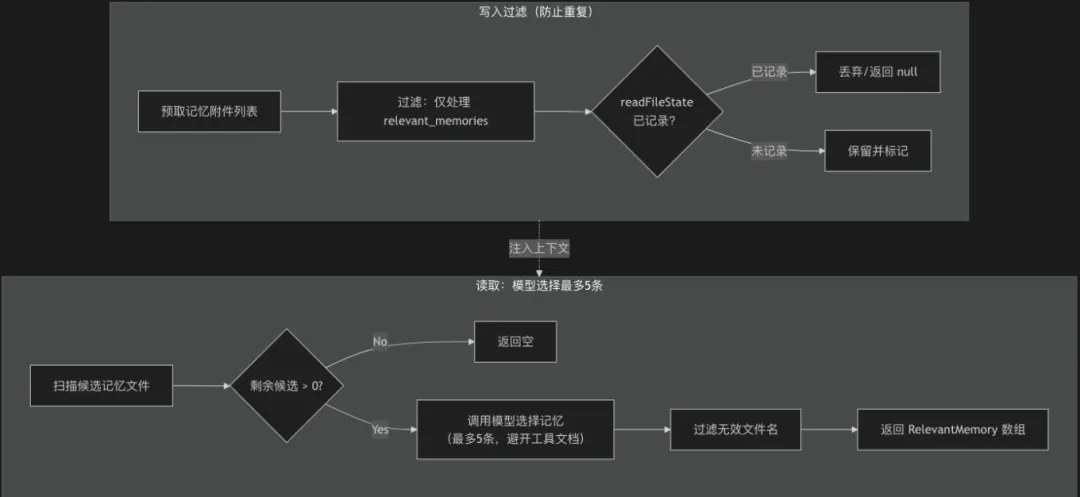
写入:不是“记下来”,而是“别让它再出现”
看到 write-after-filter 那个函数时,我被震了一下。它的核心逻辑是:
-
遍历所有预取到的记忆附件。 -
只处理类型为 'relevant_memories'的。 -
检查 readFileState——如果某个文件路径已经被模型在当前轮次读取过,就过滤掉,不再塞进上下文。 -
将新记忆写入 readFileState,标记为“已提供”。
它的目的不是“记住新东西”,而是防止同一个记忆在上下文中重复出现,造成 token 污染。 这是一种“仆人式”的记忆管理:模型负责判断要记什么,系统负责保证它不会被重复记忆干扰。
读取:让模型亲自选,最多 5 个
getRelevantMemoryAttachments 背后的逻辑更绝:它将所有候选记忆文件列表(文件名 + 描述)发给一个专用的小模型(或主模型),要求它只选确定有帮助的,不确定就别选,最多 5 个。而且,如果提供了最近用过的工具列表,模型还必须避开那些工具的常规使用文档,只选“警告、注意事项或已知问题”。
这是一种信噪比优先的策略。它默认记忆是无用的,除非模型强烈认为有用。这恰恰与很多“一股脑把向量相似度前 10 条全塞进去”的 RAG 方案形成了鲜明对比。
设计决策 2:Agent 的记忆应该有一个“独裁者”式的守门人
很多工程师在设计记忆模块时,会陷入一种收集癖:能记多少记多少,然后靠向量检索召回 Top-K。但 Claude Code 的做法告诉我们,记忆的质量远比数量重要,而写入和读取需要遵循不同的法则。
在你的设计里,你应该:
- 写入实行“双盲审核”:
不要让 Agent 自己决定把什么写进长期记忆,也不要不经筛选全盘记录。回忆一下源码的做法:Agent 产生内容,记忆系统过滤重复,人类(或下游校验)在会话中给出隐式反馈。写入应该是严肃的,需要经过“噪声过滤 + 人类教正”两次格式化。 - 读取实行“饥饿营销”:
限制记忆回调的数量(比如最多 5 条),并且强制模型给出理由。你可以在提示词里这样写:“你眼前的记忆文件是稀缺资源。只选出那些如果不提供,任务就会失败的记忆。如果你不确定,请留空。” - 建立“已读不回”黑名单:
维护一个会话级的 readFileState,确保同一条记忆不会因为模型反复调用工具而被重复注入上下文。这是防止记忆膨胀的最廉价手段。
真相很残酷:一个好的记忆系统,首要能力是遗忘和克制,其次才是存储。
第三章 当 Agent 开始写日记——记忆与工具链的深度集成
官方简单的“挂载到文件系统”
公告中有一句很妙的话:“托管代理的记忆直接挂载到文件系统上,因此 Claude 可以依赖同样高效的 bash 和代码执行能力来完成代理任务。” 这听起来很美好,但究竟如何“依赖 bash”去管理记忆?
源码中的 agentTool:记忆是 Agent 的一个“副业”
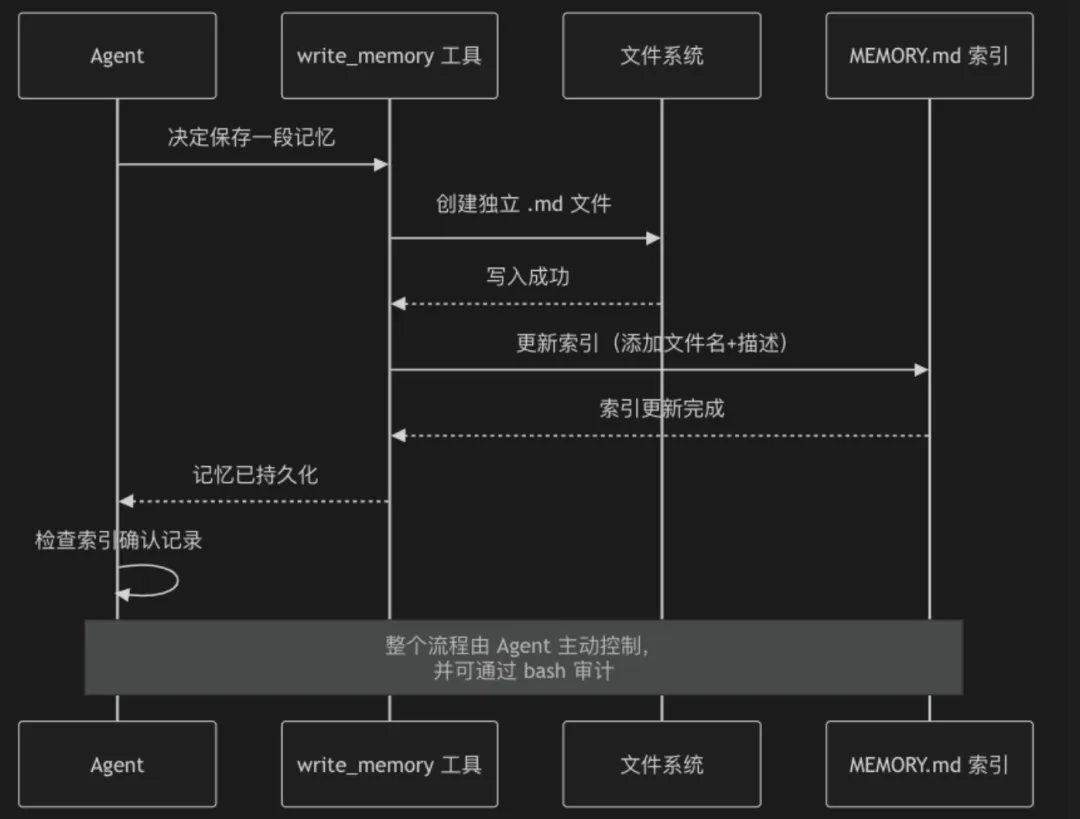
在 agentDefinitions.ts 中,loadAgentMemoryPrompt 为每个启用了持久化记忆的自定义 Agent 动态生成记忆系统提示。其中最关键的一段指令是让 Agent 在需要保存记忆时:
-
将记忆内容写入一个独立的 Markdown 文件。 -
更新 MEMORY.md索引文件,把新文件的路径和描述加进去。
这意味着:记忆不再是一个神秘的后台进程,而是 Agent 工具箱里的一个普通工具。bash 被用来执行 echo 或文件写入,代码执行能力 被用来格式化 Markdown。Agent 像程序员写代码一样,显式地调用工具去“记住”某件事。
这样做的好处是双向的:
- 对于 Agent:
记忆行为变成了可计划、可验证的步骤。Agent 可以自己检查 MEMORY.md是否更新成功。 - 对于开发者:
记忆变成了可审计、可回滚的操作。你可以在终端里 cat MEMORY.md,而不是对着一个黑盒向量数据库抓狂。
设计决策 3:把记忆权柄交给 Agent,但用工具约束它
这一点对于设计 Agent 产品的架构师来说,价值连城。你不需要建立一个强大的、单独的记忆管理微服务。你应该:
- 让记忆操作工具化:
暴露 write_memory和update_memory_index这样的工具给 Agent。Agent 在完成任务后,如果学到新东西,就显式调用它们。你甚至可以在系统提示中加入:“如果你发现你犯了某个错误,请立刻写入反馈记忆,并注明‘不应再犯’。” - 设计记忆类型学:
参考源码中“用户/反馈/项目/参考”的分类。在你的 MEMORY.md里为不同用途的记忆分区块。告诉 Agent:用户偏好存这里,项目决策存那里,操作注意事项存另一个地方。这比一股脑让模型自己归类要可靠得多。 - 提供“不信任但验证”的提示模板:
就像源码在提示中写道“信任回忆,但若与当前事实冲突,以当前对话为准”。你要在系统中埋入这种防呆指令,防止错误记忆污染任务。
让 Agent 自己写日记的好处是:你得到的不只是记忆的内容,更是记忆的“成因”。 哪天 Agent 犯错了,你可以回看日记,分析它在哪一步下了错误判断。这是一种最高级别的可解释性。
[交叉引用:这与第二章的“写入需过滤”相互印证——Agent 调用工具写记忆只是第一步,系统级的去重和校验才能保证写进去的东西质量。]
第四章 记忆的尽头是遗忘——压缩、遗忘与上下文窗口的博弈
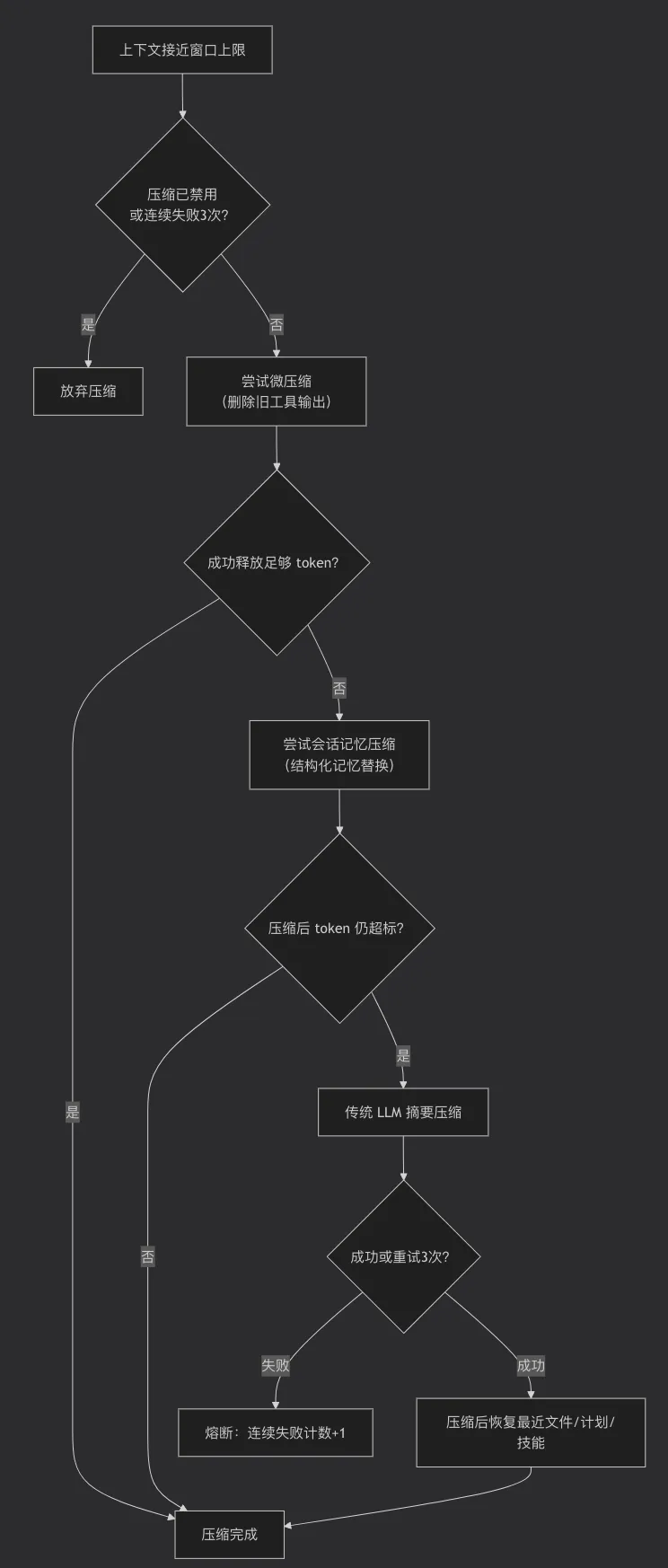
一场官方不愿多谈的硬仗
在 Claude Code 的记忆公告里,有一个词几乎没有被正面提及:压缩(Compaction)。它只说了“长期运行的代理”“跨会话学习”,但对于当上下文窗口被撑爆时怎么办,它保持了战略性沉默。
但任何一个真正在生产环境跑过 Agent 的工程师都知道:决定一个 Agent 能活多久的,不是它记得多少,而是它能在何时、以多大代价忘记。
源码里最精彩的一幕:三层压缩与熔断
源码对压缩这一块的实现,简直像一台精密的外科手术仪器。我们快速过一下它的三层架构:
- 微压缩(Micro Compact):最轻量级。在对话轮次之间,删除或截断过时的工具输出(比如一个几百行的 shell 输出),释放 token。它甚至利用了
cache_editsAPI,在不破坏缓存前缀的前提下悄悄删内容。如果对话超过 30 分钟没有新消息,它还会主动清一清。 - 会话记忆压缩(Session Memory Compaction):中等重量。它不用传统的“要模型总结对话”的方式,而是维护一份结构化的“会话记忆”文件(包含用户偏好、项目决策、已知问题)。压缩时,它直接把这份会话记忆当作摘要注入,丢弃旧消息,保留最近几个轮次。这比重新让大模型读几万字的对话再总结,要便宜得多。
- 传统 LLM 摘要压缩(compactConversation):最后的核武器。当以上都失败或不适用时,它才调用模型对历史对话做摘要。但它有丰富的周边设计:优先尝试复用缓存的
runForkedAgent;如果压缩请求本身因 token 过长失败,会通过截断头部重试最多 3 次;压缩完还会自动恢复最近读过的 5 个文件内容、计划附件,避免模型“失忆”。最厉害的是熔断机制:连续失败 3 次,直接放弃,不再浪费 API 费用。
设计决策 4:构建一个“遗忘经济学模型”
当我们从 Claude Code 的压缩设计里提炼时,得到的不是一个算法,而是一套成本与效用的平衡哲学。你在设计 Agent 记忆压缩时,必须建立自己的遗忘经济学:
- 分层遗忘,先轻后重
:永远先尝试最便宜的遗忘手段(如直接丢弃可废弃的工具输出),而不是一上来就调用昂贵的 LLM 摘要。在你的系统里,画出这样一个阶梯:工具结果截断 > 结构化记忆替换 > 模型摘要。 - 给遗忘装一个“断路器”:
连续摘要失败 3 次就停止。在生产环境里,一个进入死循环的压缩 Agent 比一个失忆的 Agent 更可怕。你要保护的不只是上下文窗口,还有你的云账单。 - 压缩后必须进行“上下文急救”:
源码在传统压缩后会自动恢复最近读过的文件、计划、技能。这是血的教训:一个大总结之后,模型往往不知道“我是谁、我在哪儿”。你在设计时必须把“压缩前状态快照→压缩→环境恢复”做成一个原子流程。 - 可观测性内建:
源码记录了压缩前后 token 数、缓存命中率、重试次数。如果你不记录这些,你永远不会知道你的记忆系统是在省钱还是在烧钱。
记忆系统的终极反讽:决定一个 Agent 能否在长程任务中生存下来的,不是它的记忆深度,而是它的遗忘速率。
[交叉引用:回到我们第一章的讨论——如果你采用本地的、基于文件的记忆,这一切压缩和遗忘都是用户可见、可审计的。这正是“可移植记忆”的真正力量。]
结语:记忆的终极法则
让我们回到文章开头那件微妙之事。当源码暴露了记忆的本地实质后,官方公告转而去强调云端的智能优化和企业级控制。这也许是一次公关,但客观上它也指出了 Agent 记忆系统的未来:混合形态。
作为设计者,你不需要在“本地”和“云端”之间二选一。你需要的是像 Claude Code 那样,在每一个决策点上,清醒地知道你在做什么:
-
你是在存储记忆,还是在为数据收集铺路? -
你是在帮助 Agent 回忆,还是在用重复信息污染它? -
你是在让 Agent 写日记,还是在创造可解释性的债务? -
你是在做智能遗忘,还是在给自己的账单上绑炸弹?
这就是我们从这次事件中学到的最宝贵的课:记忆系统不是 Agent 的一个功能,它是 Agent 信任模型的宪法。 每一个设计选择,都在向你的用户——那些把任务和上下文托付给 Agent 的人——宣告:你有多尊重他们,以及你准备走多远。
分享这篇文章给正在造 Agent 的伙伴吧。当他们下一次说“我们加个记忆模块”时,他们会想起这 4 个问题,然后开始画一张真正经过大脑的架构图。