 夜雨聆风
夜雨聆风





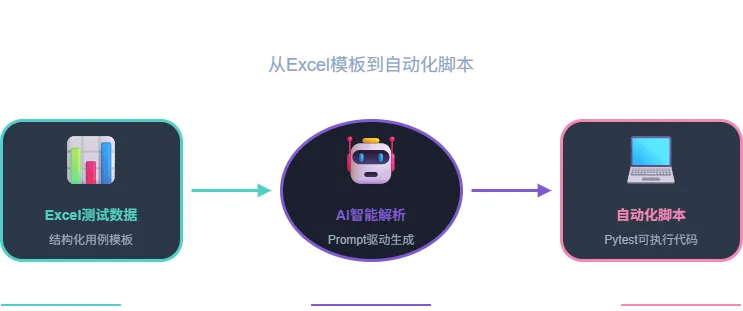
AI生成测试用例:一个Prompt模板让AI从Excel模板生成自动化脚本
手写测试用例是件痛苦的事。
一个中等规模的迭代,少则几十个用例,多则上百个。每个用例要覆盖正常场景、异常场景、边界值,还要考虑前后置条件、测试数据、预期结果。机械性的重复劳动占用了我将近40%的工作时间——这不是个例,根据我观察周围团队的情况,测试用例编写和维护在整个测试周期中耗时占比普遍超过三分之一。
更让人头疼的是需求变更。接口字段改了,业务逻辑调整了,已有的用例需要同步更新。手改不仅容易遗漏,还容易出错。有段时间我甚至害怕看代码仓库里的test_文件——那些用例代码已经和需求文档严重脱节,看不懂、改不动。
把AI引入测试用例生成是我在2024年底开始的尝试。最初的动机很简单:能不能把测试数据从Excel里导入,AI帮我自动生成符合规范的测试用例代码?
这个想法落地后,效果超出了我的预期。在一个包含47个接口的模块中,我从Excel准备了完整的测试数据,AI在15分钟内生成了全部测试用例代码,经人工审核后92%可以直接使用。剩余8%需要调整的部分主要是边界值处理和异常场景的断言逻辑——这些本来就是AI的弱项,人工补充也符合预期。
接下来我会详细介绍这套方案的技术细节,包括Excel模板设计、AI解析策略、Prompt工程实践、代码质量保障,以及我在实际项目中踩过的坑和解决方案。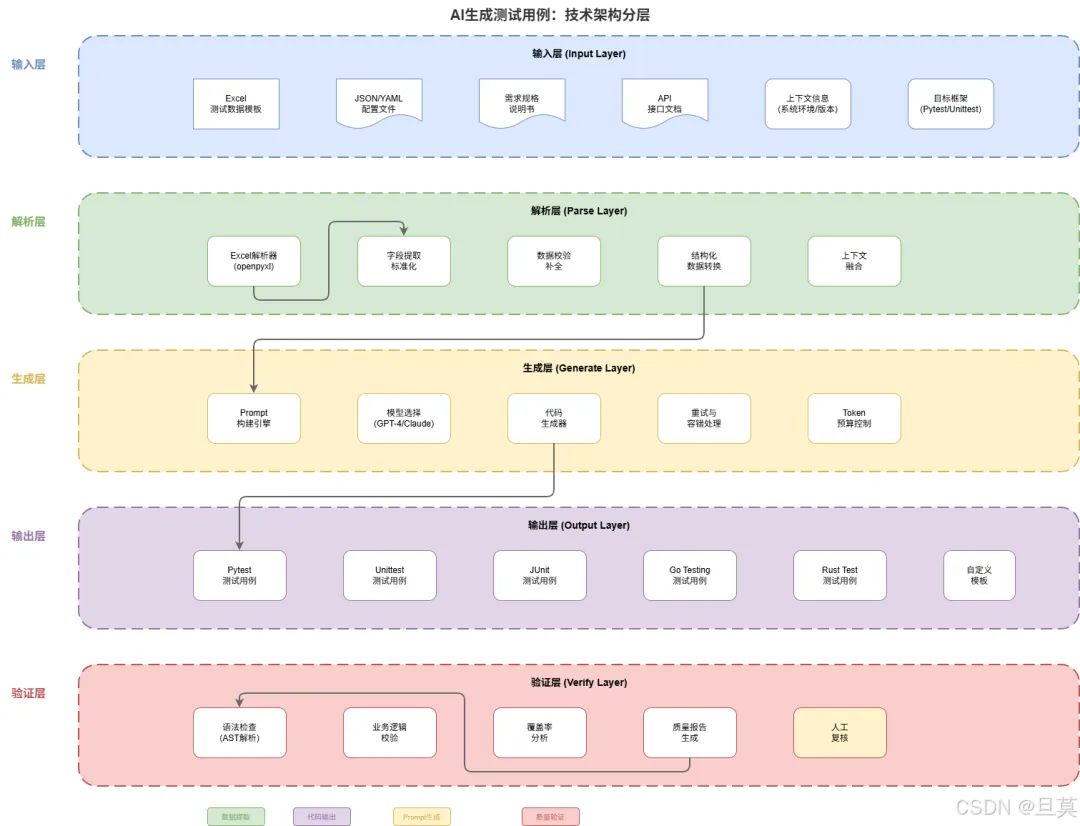
Excel模板的深度设计
字段设计原则
很多团队尝试用Excel管理测试数据,但设计不合理导致后续处理困难。我总结了一套经过验证的字段设计规范:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
关键设计决策说明:
测试数据用JSON格式。早期版本我用列式存储,但复杂嵌套场景下数据可读性很差。改用JSON后,虽然单格内容变长,但结构清晰、层级分明,AI解析时也不容易出错。
// test_data 示例{"username": "test_user_001","password": "Test@123","email": "test@example.com","profile": {"age": 25,"city": "Shanghai"}}// expected_response 示例{"code": 0,"message": "success","data.userId": "^[A-Z0-9]{8,16}{test_data.username}"}
注意expected_response支持变量引用和正则表达式。表示用正则校验格式。
数据结构与命名规范
良好的命名规范直接影响AI生成质量。我强制团队遵循以下规则:
case_id采用模块前缀:
USR_001 # 用户模块-第1个用例ORD_003 # 订单模块-第3个用例PAY_007 # 支付模块-第7个用例
case_title遵循”Given-When-Then”结构:
# 良好示例"Given用户已登录_When提交有效订单_Then返回创建成功""Given商品库存为0_When用户尝试下单_Then提示库存不足"# 糟糕示例"测试下单功能""订单创建""库存不足场景"
这种结构化标题帮助AI理解测试场景的上下文,生成的断言会更精准。
多Sheet协同设计
复杂业务场景下,我会用多个Sheet组织数据:
工作簿结构:├── 接口定义 # 接口元数据├── 测试用例 # 主用例数据├── 测试数据池 # 可复用的测试数据├── 断言规则库 # 预定义断言模式└── 业务规则 # 关联业务逻辑说明
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
数据池设计的好处是测试数据可以复用,减少重复录入。更重要的是,AI在解析时可以识别数据间的关联关系,生成更符合业务逻辑的测试序列。
AI解析的技术细节
Prompt工程实践
Prompt设计是整个方案的核心。经过多个版本的迭代,我总结出一套高效的Prompt模板:
SYSTEM_PROMPT = """你是一个专业的测试用例生成专家,擅长将Excel中的测试数据转换为可执行的自动化测试代码。## 输出要求1. 只输出Python代码,不要包含任何解释性文字2. 使用Pytest框架3. 代码必须可以直接运行4. 每个测试函数对应Excel中的一个测试用例5. 测试函数命名规范:test_{case_id}_{简短描述}## 代码规范1. 使用requests库发送HTTP请求2. 使用pytest.mark装饰器标记用例优先级3. 使用conftest.py中定义的fixture获取base_url和headers4. 断言要具体,明确assert什么字段、什么值5. 对于有依赖的用例,在函数docstring中标注依赖关系## 变量引用规则- `{expected.field}` 引用Excel中expected_response字段- 支持正则表达式断言,格式为:assert re.match(pattern, value)## 错误处理1. 网络异常:使用pytest.skip跳过用例,标注原因2. 断言失败:使用assert的具体消息说明期望值和实际值3. 依赖失败:使用pytest.mark.dependency标记依赖关系"""USER_PROMPT_TEMPLATE = """请根据以下测试数据生成Pytest测试用例代码:### Excel数据
{excel_data}
### 项目配置- 基础URL: {base_url}- 接口前缀: {api_prefix}- 认证方式: {auth_type}### 测试类命名{test_class_name}### 注意事项1. 登录接口无需生成测试用例(已在conftest.py中处理)2. 需要认证的接口使用 @pytest.mark.usefixtures("auth_token") 装饰器3. POST/PUT请求的body使用 json= 参数4. 响应断言优先验证 code/message 字段,再验证业务数据"""
实际调用时,我会动态填充模板中的变量:
def build_user_prompt(excel_data: dict, config: dict) -> str:"""构建用户Prompt"""return USER_PROMPT_TEMPLATE.format(excel_data=_format_excel_data(excel_data),base_url=config.get("base_url", "http://localhost:8080"),api_prefix=config.get("api_prefix", "/api/v1"),auth_type=config.get("auth_type", "Bearer Token"),test_class_name=f"Test{excel_data['module_name'].title().replace('_', '')}")def _format_excel_data(data: list) -> str:"""格式化Excel数据为Markdown表格"""if not data:return ""headers = list(data[0].keys())lines = ["| " + " | ".join(headers) + " |"]lines.append("| " + " | ".join(["---"] * len(headers)) + " |")for row in data:values = [str(row.get(h, ""))[:100] for h in headers] # 截断过长内容lines.append("| " + " | ".join(values) + " |")return "\n".join(lines)
多模型对比
我用同一个测试数据集分别测试了GPT-4、Claude-3和国内几个主流模型,结果差异明显:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
关键发现:
GPT-4在复杂嵌套结构的JSON解析上表现最好,生成的断言代码逻辑清晰、出错率低。Claude-3对业务场景的理解略胜一筹,在异常场景识别和边界值处理上更有优势。国内模型的优势是响应速度快、价格低,但复杂场景下的代码质量不够稳定。
我的选择策略:
-
核心业务模块(支付、订单等)用GPT-4,保证质量 -
一般模块用Claude-3,性价比高 -
简单CRUD接口用国内模型,快速生成
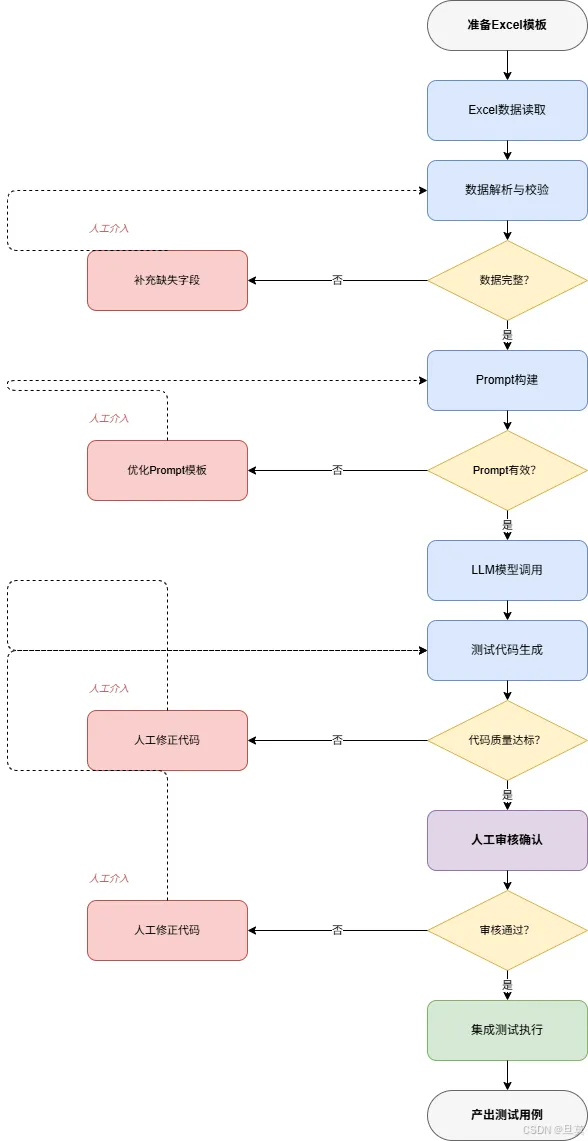
解析策略与容错
Excel数据经常存在各种不规范情况,我实现了多级容错机制:
class ExcelParser:def __init__(self, file_path: str):self.file_path = file_pathself.warnings = []self.errors = []def parse_with_validation(self) -> list[dict]:"""带验证的解析"""raw_data = self._read_excel()# 第一级:基础格式校验validated_data = []for idx, row in enumerate(raw_data, start=2): # Excel行号从2开始try:parsed_row = self._validate_row(row, idx)if parsed_row:validated_data.append(parsed_row)except MissingRequiredField as e:self.warnings.append(f"行{idx}: 缺失必填字段 {e.field},已跳过")except InvalidFieldValue as e:self.warnings.append(f"行{idx}: 字段 {e.field} 值无效,已使用默认值")# 第二级:数据完整性检查if len(validated_data) == 0:raise EmptyDataError("没有有效的测试数据")# 第三级:跨行关联检查validated_data = self._resolve_references(validated_data)return validated_datadef _validate_row(self, row: dict, row_num: int) -> dict:"""验证单行数据"""# 检查必填字段required_fields = ['case_id', 'case_title', 'http_method', 'api_path']for field in required_fields:if not row.get(field):raise MissingRequiredField(field)# 规范化http_methodmethod = row['http_method'].upper().strip()if method not in ['GET', 'POST', 'PUT', 'DELETE', 'PATCH']:method = 'GET' # 默认值self.warnings.append(f"行{row_num}: http_method无效,已设为GET")row['http_method'] = method# 解析JSON字段for json_field in ['test_data', 'expected_response', 'assertion_rules']:if row.get(json_field) and isinstance(row[json_field], str):try:row[json_field] = json.loads(row[json_field])except json.JSONDecodeError as e:row[json_field] = {} # 空字典作为默认值self.warnings.append(f"行{row_num}: {json_field} JSON解析失败,使用空对象")return rowdef _resolve_references(self, data: list) -> list:"""解析数据引用"""# 构建数据池索引data_pool = {}for row in data:if row.get('data_id'):data_pool[row['data_id']] = row# 替换引用for row in data:self._replace_refs(row, data_pool)return datadef _replace_refs(self, row: dict, pool: dict):"""递归替换引用"""for field, value in row.items():if isinstance(value, str) and value.startswith('”}USR_REG_002Given已注册用户_When再次注册_Then提示用户名已存在POST/api/v1/users/registerP1异常{“username”:“existing_user”,“password”:“Test@123456”,“email”:“existing@test.com”}200{“code”:1001,“message”:“用户名已存在”}USR_REG_003Given无效邮箱_When注册_Then提示邮箱格式错误POST/api/v1/users/registerP1异常{“username”:“new_user”,“password”:“Test@123”,“email”:“invalid-email”}200{“code”:1002,“message”:“邮箱格式不正确”}PTS_EAN_001Given用户已登录_When积分获取_Then返回积分变动POST/api/v1/points/earnP0功能{“userId”:“{USR_REG_001.userId}”}200{“code”:0,“data.balance”:“^\d+", user_id), \f"userId格式不符,期望^[A-Z0-9]{{8,16}}", str(balance)), \f"balance应为数字,实际: {balance}"
第四步:质量验证
生成的代码需要经过质量验证:
import astimport reclass CodeQualityValidator:"""代码质量验证器"""def __init__(self):self.issues = []def validate_file(self, file_path: str) -> dict:"""验证测试文件"""with open(file_path, 'r', encoding='utf-8') as f:code = f.read()# 语法检查try:ast.parse(code)except SyntaxError as e:self.issues.append(f"语法错误: {e}")# 命名规范检查naming_pattern = r'def (test_\w+)'matches = re.findall(naming_pattern, code)for func_name in matches:if not re.match(r'test_[A-Z]{2,}_\d+', func_name):self.issues.append(f"命名不规范: {func_name}")return {"file": file_path,"issues": self.issues,"passed": len(self.issues) == 0}
总结
1. Excel模板设计
- 字段精简
:只保留必要字段,避免过度设计 - 默认值策略
:非关键字段设置合理的默认值 - 命名规范
:统一前缀便于分类和AI识别 - JSON嵌套
:复杂数据用JSON,减少列数
2. Prompt工程
- 结构化输出
:明确要求输出格式,减少解析成本 - 示例引导
:提供2-3个典型示例帮助模型理解 - 变量引用
:支持 ${}语法实现数据关联 - 错误处理
:要求模型处理异常情况
3. 质量保障
- 多级校验
:语法→规范→业务逻辑逐层检查 - 人机协同
:AI生成+人工审核,各取所长 - 版本管理
:保留历史版本,便于回溯 - 指标追踪
:统计代码通过率,持续优化
4. 迭代优化
记录每次生成的质量问题,针对性优化Prompt模板。我维护了一个问题库:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
常见问题与解决
Q1: AI生成的代码语法错误怎么办?
原因:通常是Prompt描述不清晰或测试数据格式问题。
解决:
-
检查Excel中JSON格式是否正确 -
在Prompt中增加”必须通过Python语法检查”的要求 -
添加语法验证环节,失败则重新生成
Q2: 断言逻辑不符合业务预期?
原因:AI对业务规则理解不准确。
解决:
-
在expected_response中明确期望值 -
在business_rules字段补充业务说明 -
提供历史正确案例让AI参考
Q3: 生成的代码风格不一致?
原因:多模型或多次生成导致风格差异。
解决:
-
固定使用同一模型 -
在Prompt中明确代码风格要求 -
添加格式化脚本统一代码风格
Q4: 长流程用例的依赖关系混乱?
原因:缺乏统一的依赖管理机制。
解决:
-
使用pytest.mark.dependency标记依赖 -
在case_title中标注依赖关系 -
合理拆分长流程为多个短用例
AI生成测试用例不是要取代人工,而是把人从重复劳动中解放出来,专注于更有价值的测试设计和业务理解。把40%的机械工作时间变成10%的审核时间,这个效率提升是实实在在的。
关键是要建立一套完整的流程:好的Excel模板 → 精准的Prompt → 严格的质量验证 → 持续的效果追踪。工具只是手段,流程才是核心。
如果你也在探索AI辅助测试,欢迎交流经验。