 夜雨聆风
夜雨聆风





成本狂降90%、幻觉归零!百页长文档信息提取的“作弊代码”

最近在搞费控系统里的长文档解析,结算书和合同动辄几十上百页。
大脑的第一反应是:直接扔给 Vision LLM 吧!
结果算了一下账,单份合同处理成本居然要大几十甚至上百块……
看到这个数字直接要爆炸了!这个成本居然贵过人工审核。
(对的,以后我们人类,可能最大的竞争优势就是比 AI 便宜了🐶)
⠀
但如果为了控制成本,只抽样扫描前 5 页?
抱歉,对于严谨的财务审核来说,漏掉一个金额明细或者约束条款,那就是系统性灾难。
这就陷入了一个死局:全量扫太贵,抽样扫太险。
⠀
面对这个问题,我的直觉是:绝对不能一刀切,必须先搭个漏斗框架。
我把整个文档抽取流程拆解重组,搞出了这套 T1-T2-T3 三层架构 + LangGraph 状态机 的模式。
跑通的那一刻,看着成本被压榨了 90%,准确率还直线飙升,成就感爆棚!
我好像找到了另外一条解决长文本抽取难题的降维打击之路。
⠀
今天就把这套底层逻辑拆解给大家看。
⠀
方法1. 拒绝“梭哈”,用 T1-T2-T3 把好钢用在刀刃上
⠀
让大模型产生幻觉的元凶是什么?
是信息量太庞杂!传统的做法是一锤子买卖,把上百页文本当 Prompt 梭哈扔给大模型。
结果呢?上下文溢出,大模型直接在海量噪音里“失忆”(Lost in the middle),甚至凭空捏造出一个根本不存在的税率。
在财务审核中,幻觉不仅是错误,更是灾难。
⠀
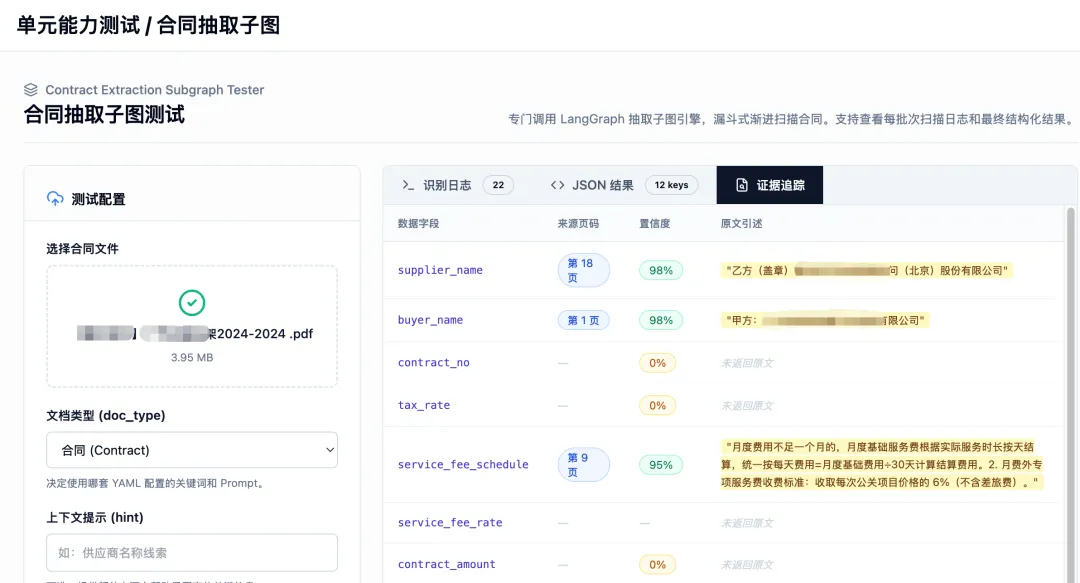
我们的做法,是把文档处理变成一台精密的“提纯漏斗”:
⠀
⠀
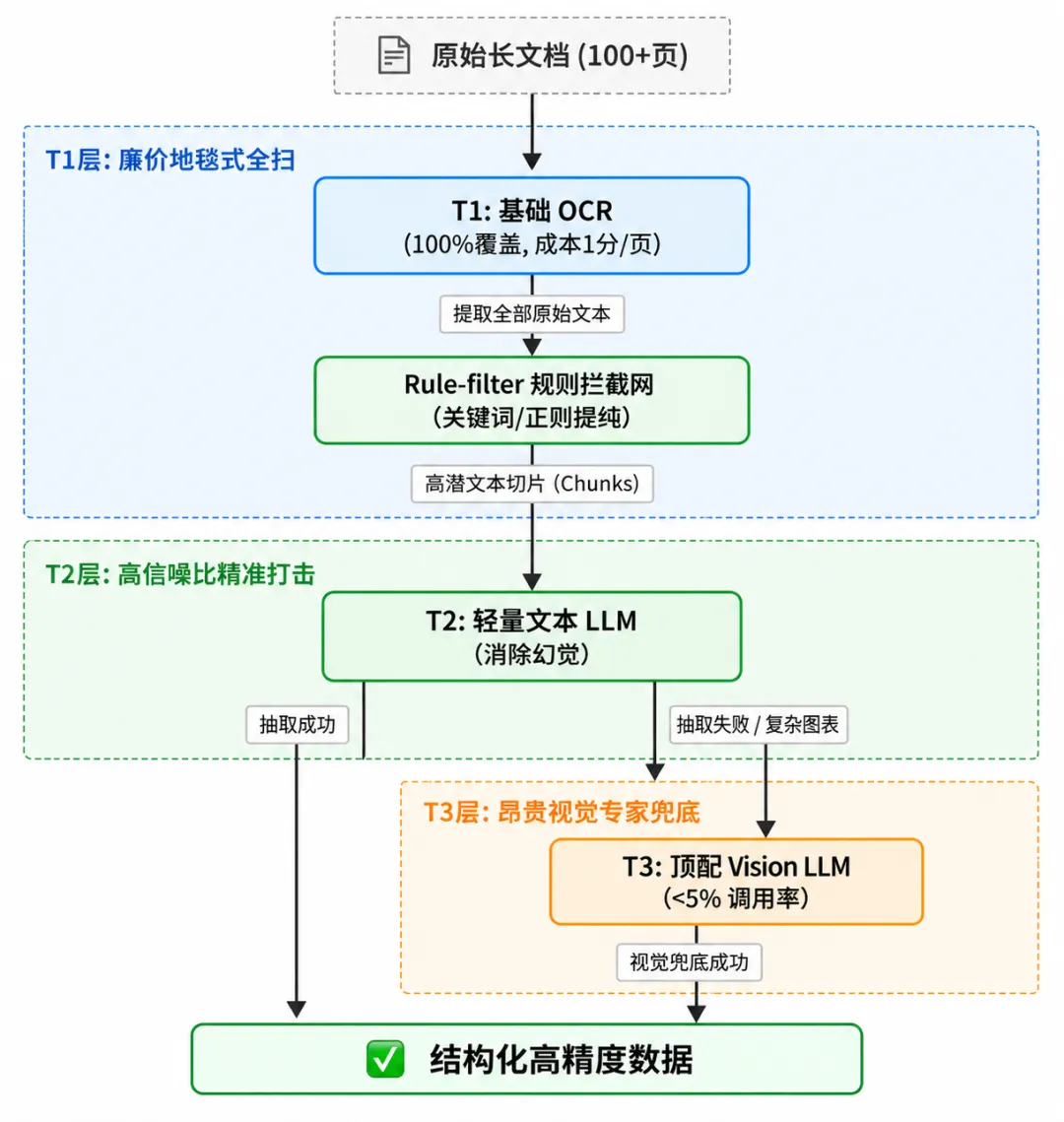
* T1(基础廉价 OCR):地毯式扫雷
管你有 100 页还是 200 页,一律用极其廉价的底座转化为带页码的基础文本流。
这步不求它懂,只求 绝对不漏。
* T2(轻量文本 LLM):高信噪比的精准打击
这是克服幻觉的核心!我们不把 100 页全给大模型,而是加了一层规则拦截网,把潜在包含“标的金额”、“供应商”的那几段高潜文本切片精准捞出来。
大模型的视线瞬间从汪洋大海收束到了核心条款上。 信噪比极高,幻觉概率呈断崖式下降!
* T3(昂贵视觉 LLM):终极兜底
只有当文本遇到极其复杂的嵌套表格、或者必须校验红头公章时,才把原图发给最贵的视觉大模型做专家会诊。整体调用比例严格控制在 5% 以下。
⠀
方法2. LangGraph 状态机:不纠结,先跑起来再自愈
光有分层还不够,工程落地必须追求绝对的稳健。
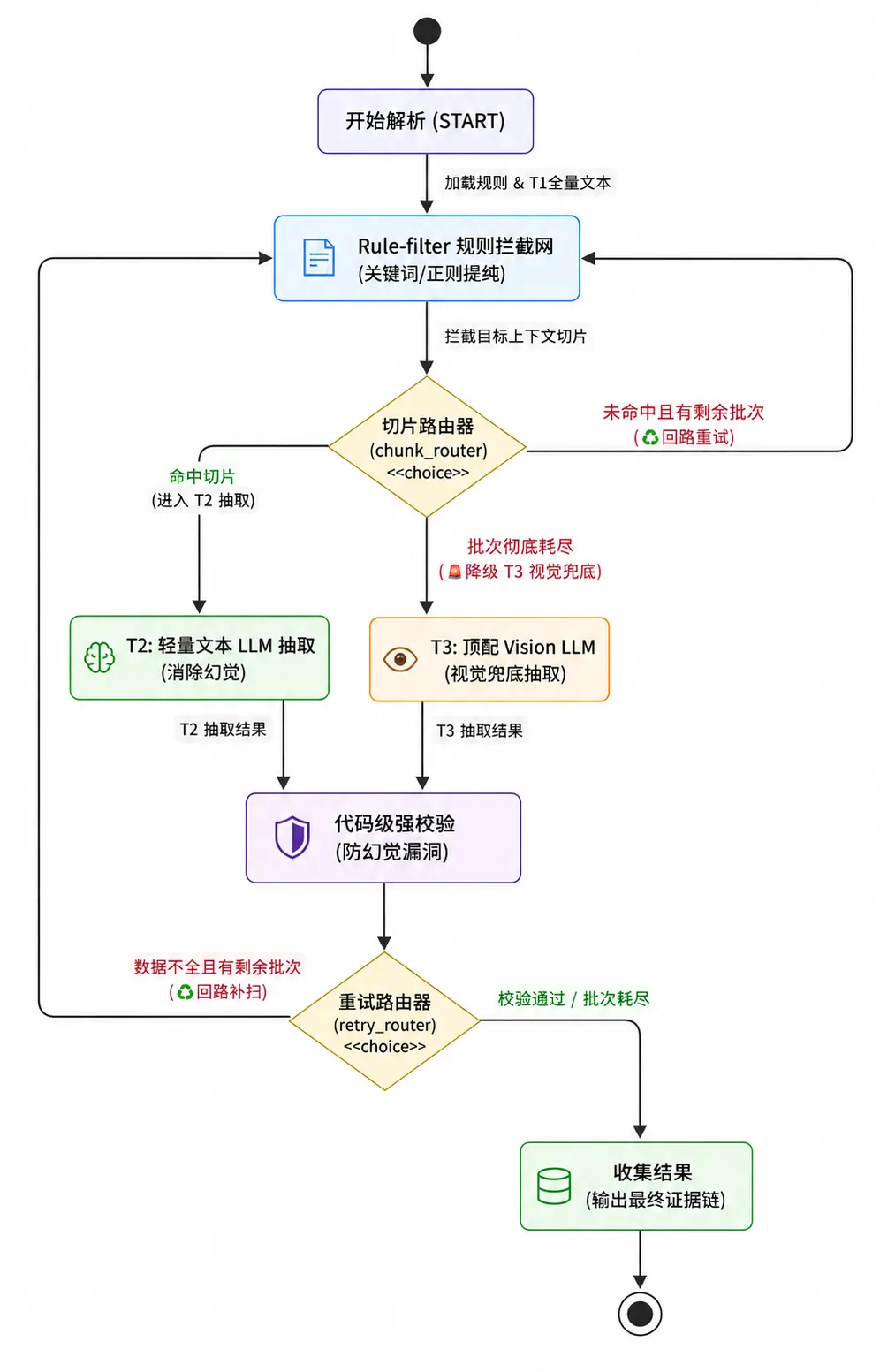
在这套系统里,我直接把抽取过程封成了一个自循环的状态机(StateGraph)。
它不是跑一次就结束,而是一个“小步快跑、层层校验”的过程:
⠀
⠀
提取出字段后,系统立即启动代码级校验。
税率拿到了吗?金额格式对吗?
一旦发现数据残缺或逻辑矛盾,绝不妥协,直接触发回路重试,继续扫描下一批文本;
如果文本全扫完还没结果,自动无缝升级到最高级的 T3 视觉兜底。
⠀
这种遇到卡点不卡死,先跑起来、不行就重试或升级的自愈机制,彻底把大模型的不确定性给兜住了。
⠀
方法3. 证据溯源:彻底掐断 AI 瞎编的退路
⠀
坦白说,这套系统能在业务里立足,最关键的是我们在物理层面上扼杀了大模型的幻觉。
⠀
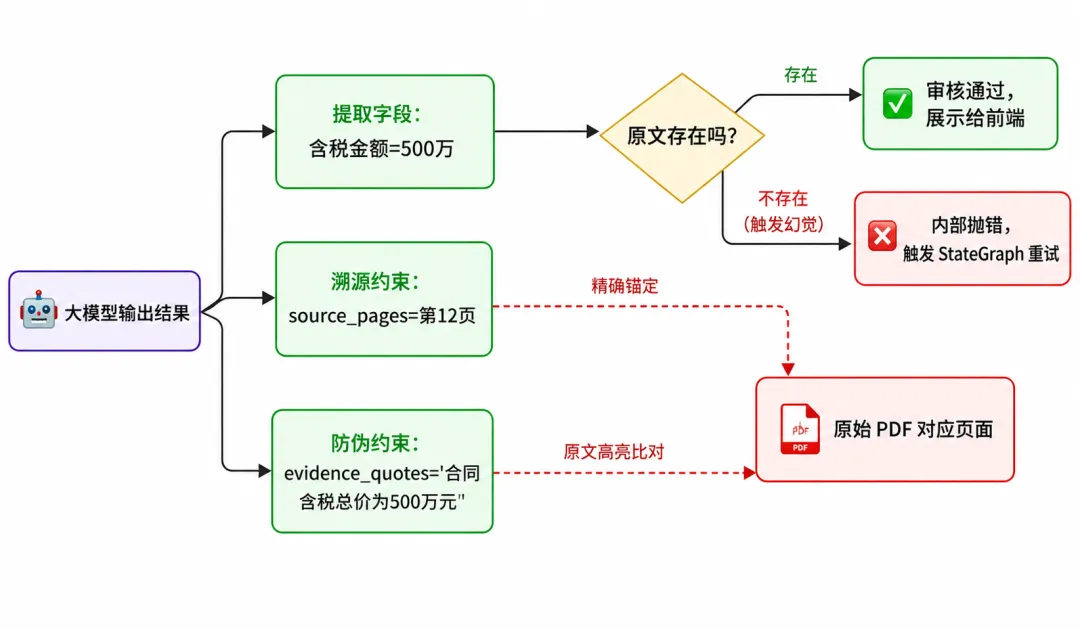
系统底层 Schema 里加了一记绝杀:强制证据溯源(Evidence Grounding)。
你大模型输出金额是 500 万?
可以,但必须同时给我交出 `source_pages` 和 `evidence_quotes`。
告诉我哪一页的哪段原文!
⠀
⠀
一旦大模型试图靠幻觉瞎编数字,它就会因为找不到原文而崩溃报错,从而立刻触发重试。
⠀
在最终的前端审核界面,审核员点击“500万”,屏幕瞬间高亮原始 PDF 第 12 页的对应句子。

AI 从一个只会瞎猜的“算命先生”,变成了可以随时指认现场的“金牌初级审计员”。
⠀
最后:行动才能出成果⠀
大模型在企业级落地,从来不是比拼谁的模型参数大,而是比拼 工程架构的设计能力。
⠀
通过漏斗式提纯消除噪音(治本),通过多轮校验与视觉降级托底(治标),外加强制证据溯源(防线),我们完全可以兼顾“极致性价比”与“绝对可靠”。
⠀
经验只有沉淀成可复用的模式才有价值。
如果你也在被长文本高昂的成本折磨,希望这个架构能给你带来一点启发。
不纠结了,决定了就干,赶紧把这套模式在你的业务里跑跑看!