 夜雨聆风
夜雨聆风





拍照5秒钟,整理13小时——我做了个AI工具来解决这个问题

上周末,杭州西溪小镇,2050大会。
3天2晚,我像一块高速运转的硬盘,疯狂写入。AI Agent 的架构演进、多模态大模型的企业落地、知识图谱在垂直行业的实践——每一场分享的信息密度都拉满,台上的演讲者平均年龄不超过30岁,但讲出来的东西让我这个“老 AI 人”都在不停举起手机拍照。
3天下来,我的相册里多了200多张照片。PPT 截图、手绘白板、数据图表、架构图、思维导图,每一张都是一个知识切片。
然后问题来了。
周一早上,我打开相册,准备整理这些“知识资产”。
第1张,OpenClaw 管理框架的报告结构图,我花了3分钟回忆这张图的上下文,手动敲了一段笔记。第2张,一个 AI 用例评估矩阵,我又花了5分钟把里面的关键指标抄下来。第3张,一个 Agent 架构的对比分析……
到第15张的时候,我停下来算了一笔账:200张图片,按每张平均4分钟的整理时间,需要13个小时。
13个小时,纯体力劳动。
更要命的是,这些图片之间是有关联的。第23张 PPT 里提到的“AI Agent”和第87张白板上的“Agent 架构”说的是同一件事,第45张的数据趋势图和第112张的结论页形成了因果链——但这些跨图片的关联,靠人脑在200张图里来回翻找,基本不可能。
我突然意识到一个事实:我们这个时代最讽刺的知识困境,不是信息不够,而是信息以图片的形式被锁死在相册里,无法被搜索、无法被关联、无法被深度分析。

OCR?它只能告诉你图片里有什么字。但我需要的不是文字,是文字背后的知识结构。
这个念头一旦冒出来,就按不回去了。
我太清楚这个问题的技术可行性了——多模态大模型已经能“看懂”图片,知识图谱技术已经成熟到可以做实体抽取和关系推理,向量数据库让语义搜索变得轻而易举。所有的技术积木都在那里,只是没有人把它们拼成一条完整的流水线。
于是我决定自己动手,做一个项目:InsightLens——图片知识解码平台。
核心链路只有一句话:
上传图片 → AI 理解 → 知识抽取 → 向量化 → 知识图谱 → 深度报告
碎片化的视觉信息进去,结构化的知识资产出来。
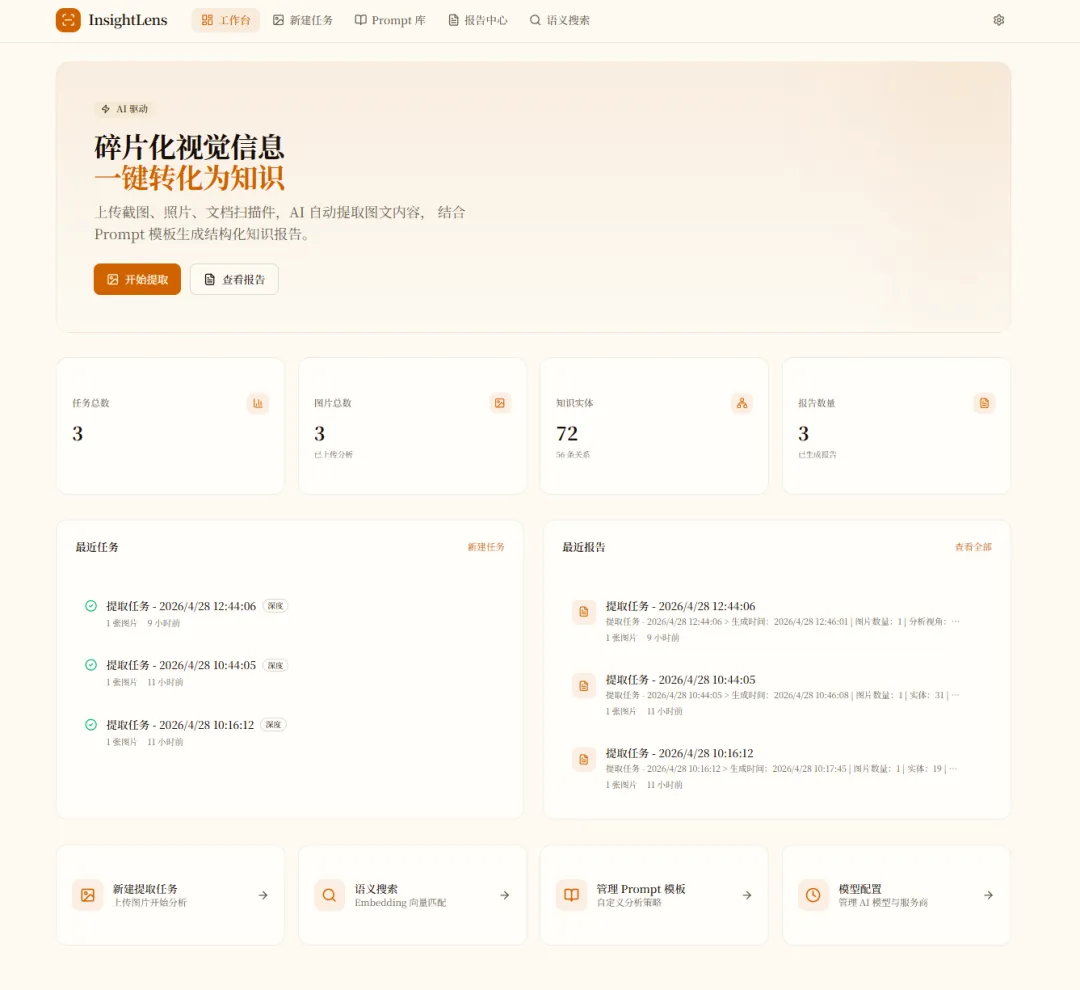
从0到1,我是怎么一步步把它搭起来的?
先说最关键的设计决策。
第一个决策:不做 OCR,做知识理解。
传统 OCR 的思路是“图片→文字”,但这远远不够。一张数据图表,OCR 能识别出数字,但识别不出趋势、结论和异常值。一张 PPT 截图,OCR 能抄下文字,但抄不出论证逻辑和核心观点。
InsightLens 用多模态视觉模型直接“看”图片,不是识别文字,而是理解含义。而且针对不同类型的图片——文档、PPT、图表、照片——使用不同的专用 Prompt 模板,就像派不同专业的分析师去看不同类型的材料。
图表类图片的处理尤其值得一提:系统会自动提取数据点、识别趋势方向、标注异常值、给出结论性判断。一张折线图进去,出来的不是“这是一张折线图”,而是“该指标在 Q2-Q3呈现加速上升趋势,增幅达9.8%,Q4出现拐点,需关注下行风险”。
第二个决策:受控词汇,不让 LLM 自由发挥。
这是做知识图谱最容易踩的坑。如果让大模型自由输出实体类型和关系谓词,你会得到一堆同义词的灾难——“公司”、“企业”、“机构”、“组织”说的是同一类东西,“属于”、“就职于”、“在……工作”描述的是同一种关系。
我的方案是:8种一级实体类型、50多个二级标签、15种受控关系谓词。LLM 可以自由理解图片内容,但输出必须经过标准化映射。这样做的代价是灵活性降低,但收益是知识图谱真正可查询、可关联、可推理。
100个干净的实体,胜过1000个重复混乱的实体。

第三个决策:双源融合+跨图关联。
单张图片的知识抽取只是起点。真正有价值的是跨图片的关联推理。
系统会自动发现:哪些实体在多张图片中反复出现?同一个指标在不同图片中的趋势是否一致?不同图片之间是否存在因果链?
回到我的2050照片——第23张和第87张提到的 Agent 概念,系统自动识别为同一实体;第45张的数据趋势和第112张的结论,系统自动建立因果关系。这些跨图关联,最终汇入一份深度观察报告的独立章节。
而且知识图谱的数据来源不止图片本身。系统生成的分析报告也会被反向抽取实体和关系,形成“图片→图谱”和“报告→图谱”的双源融合。图片提供广度,报告提供深度。
实际跑起来是什么效果?
我把2050拍的其中48张核心图片扔进去,选了“深度模式”,配上“学习笔记整理”的 Prompt 模板和“教育培训专家”的分析角色,点击“开始提取”。

大约10分钟后,系统完成了全部处理:
-
48张图片被自动分类为 PPT 截图、手绘白板、数据图表等类型
-
每张图片的核心知识被结构化提取
-
跨图片的重复概念、趋势变化、因果链被自动发现
-
89个知识实体、89条关系被抽取并构建成知识图谱
-
一份多角色融合的深度观察报告自动生成
知识图谱的可视化效果尤其直观——概念27个、技术22个、人物6个、组织5个、事件5个,用不同颜色的节点展示,关系类型分布一目了然:包含23条、属于21条、使用6条。点击任意节点,可以看到它和哪些实体有关联,关联的性质是什么。

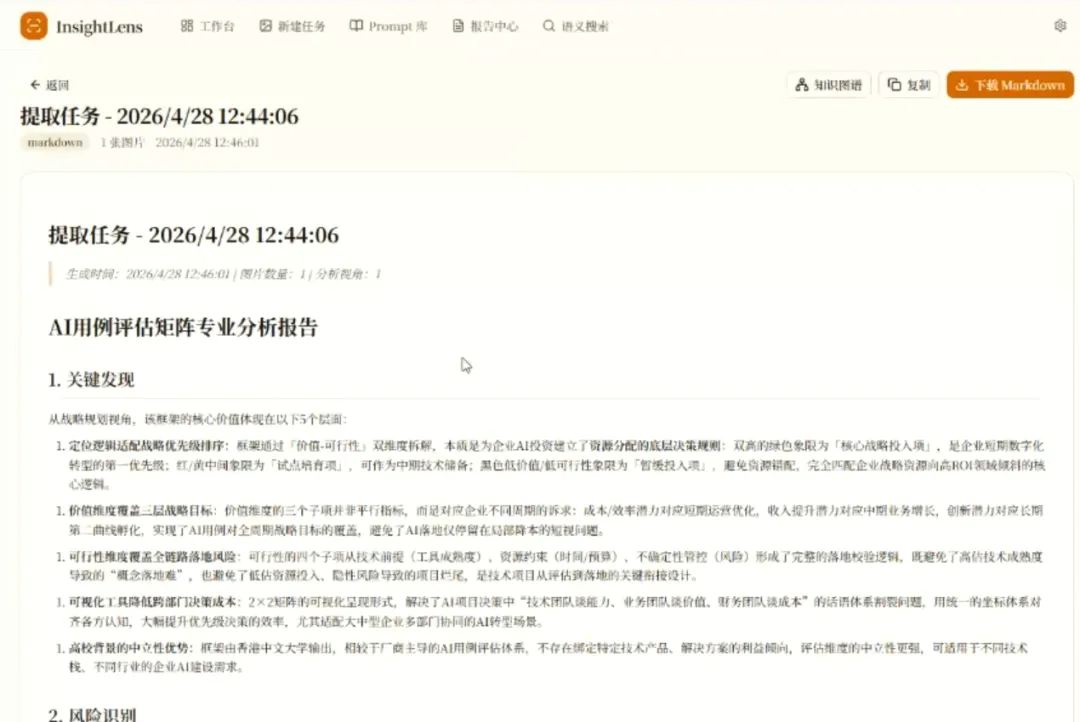
那份原本需要13个小时手动整理的工作,30分钟就搞定。而且产出的不是线性笔记,是一张可交互、可搜索、可持续积累的知识网络。
技术栈选型,说几个关键判断。
为什么用 Next.js 16而不是 Vite?因为需要 API Routes 做后端,图片处理流水线的调度逻辑不适合纯前端方案,Next.js 的 App Router + Route Handlers 让前后端在一个项目里闭环。
为什么用 Supabase?开发阶段快速验证,PostgreSQL + pgvector 一站式解决关系存储和向量搜索,不用额外搭向量数据库。
为什么实体对齐要做三级?精确名称匹配处理“字节跳动”==“字节跳动”,别名表匹配处理“AI”→“人工智能”,Embedding 语义匹配处理“ByteDance”≈“字节跳动”。三级递进,覆盖从精确到模糊的全部场景,而且不同实体类型的语义匹配阈值不同——人名要求更高(0.90),因为“张三”和“张四”向量很近但不是同一人;技术概念可以更低(0.85),因为缩写和全称差距大。
模型配置做了6个独立槽位,支持 DeepSeek、硅基流动、OpenRouter 等第三方服务商,API Key 用 AES-256-GCM 加密存储。不绑定任何一家模型厂商,用户可以根据成本和效果自由切换。
这个项目对我的启发是什么?
回到2050大会的主题——年轻人、新技术、新想法。我在那3天里最大的感受是:AI 的落地已经从“能不能做”进入了“怎么做得好”的阶段。技术积木都在那里,关键是找到真实的问题场景,然后把积木拼对。
InsightLens 解决的问题很具体:图片形式的知识无法被结构化利用。但它背后的方法论是通用的——找到信息流的断裂点,用 AI 把断裂的环节接上,让数据从“死”的变成“活”的。

如果你也有类似的困扰——参加完一场会议、听完一场培训、翻完一本书,手机里存了一堆图片但从来不会再看第二遍——这个项目的思路或许能给你一些启发。
不是所有问题都需要从零开始造轮子。有时候,把现有的技术积木按正确的顺序拼起来,就是一个完整的产品。