夜雨聆风
夜雨聆风





利用ai重构plm、erp、mes数据目录、分类、挖掘、编织、协同、模型机理共振、应用落地研究
利用ai重构plm、erp、mes数据目录、分类、挖掘、编织、协同、模型机理共振、应用落地研究
在制造业智能化转型的深水区,PLM、ERP、MES三大系统虽已广泛应用,但其数据仍处于“物理集中、逻辑割裂、语义混乱、价值沉睡”状态。传统集成仅解决“连通性”,未触及“智能协同”本质。要真正释放数据价值,必须借助 AI技术 对三系统数据进行 重构、分类、挖掘、编织、协同,并实现 模型与机理的共振,最终驱动高价值应用落地。以下提出一套系统性研究框架——“AI驱动的PLM-ERP-MES智能数据中枢(Intelligent Data Nervous System)”,涵盖 目标、方法、步骤、技术栈与验证机制。
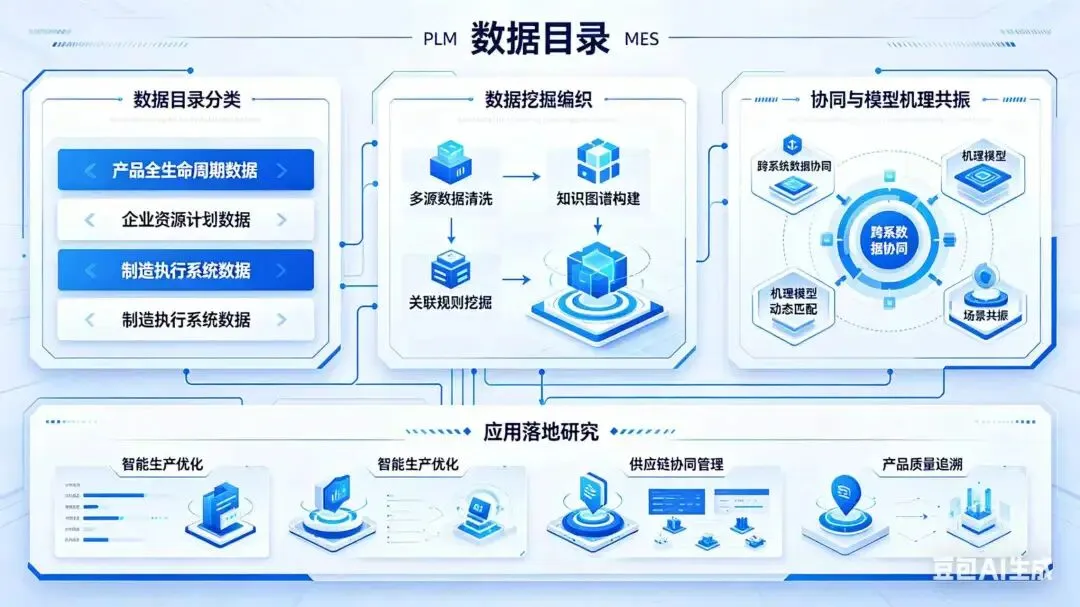
一、总体目标:构建“五维一体”智能数据中枢
维度 目标 AI赋能点
1. 数据目录重构 建立企业级统一数据资产地图 NLP自动解析字段语义
2. 智能分类治理 动态识别敏感/关键/冗余数据 聚类+图神经网络
3. 深度价值挖掘 发现跨系统隐藏模式与根因 关联规则+因果推断
4. 数据编织协同 虚拟化集成,按需服务 知识图谱+Data Fabric
5. 模型机理共振 构建可解释、可控制、可进化的混合模型 PINN + 工艺知识嵌入
终极输出:一个“自描述、自组织、自优化”的智能数据中枢,支撑实时成本、柔性排产、变更协同等高阶应用。
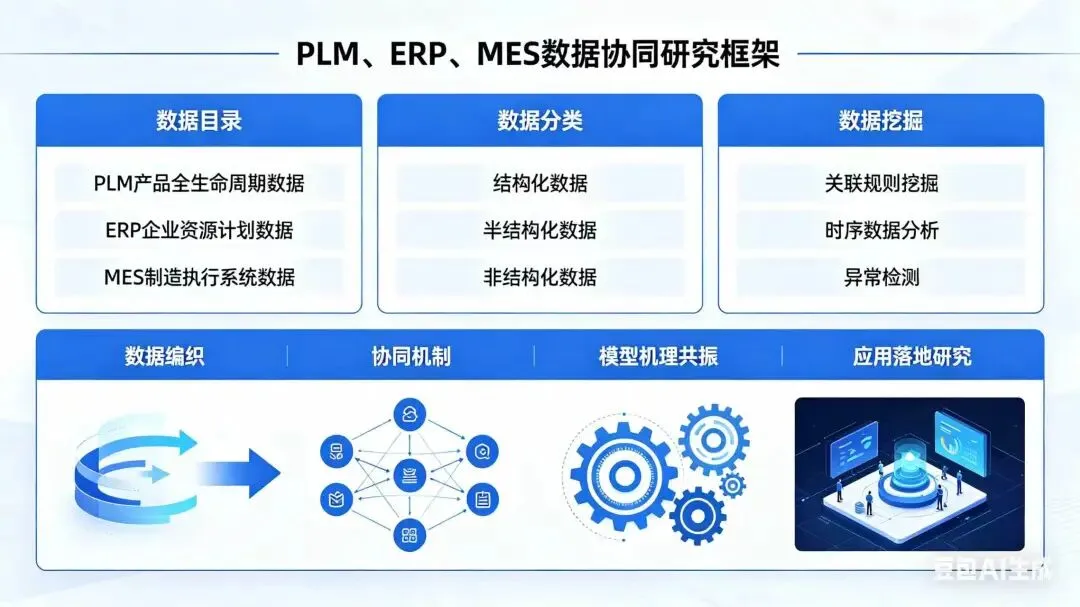
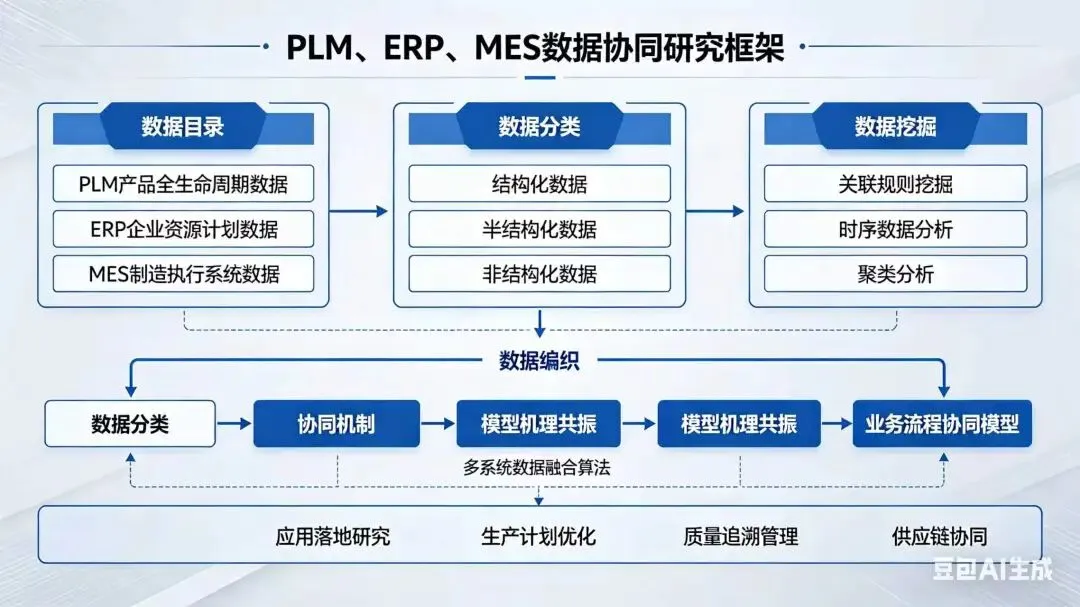
二、分阶段实施路径:六步闭环法
第一步:AI驱动的数据目录重构(What We Have)
问题:PLM字段名“Part_No”,ERP叫“MATNR”,MES称“Item_ID”;无全局数据资产视图,查找数据靠“问人”。
方法:NLP自动元数据提取: 扫描PLM/ERP/MES数据库表结构、注释、样例值;使用BERT微调模型识别字段语义(如“是否为物料编码?”)。
实体对齐(Entity Resolution): 基于相似度(Jaccard、Word2Vec)匹配跨系统同义字段;人工校验后固化为“企业数据字典”。
输出:《企业统一数据目录》含:全局实体(产品、订单、资源)、字段映射关系(PLM.Part_No ↔ ERP.MATNR)、数据血缘(从PLM BOM到ERP成本卷积)
工具:Apache Atlas + spaCy + 自研对齐引擎
第二步:AI增强的数据分类与治理(What Matters)
问题:80%数据低价值,20%关键数据质量差;敏感数据(如工艺参数)未分级保护。
方法:无监督聚类识别数据角色: 对字段进行多维特征提取(类型、波动性、关联度);K-Means聚类分为:主数据、事务数据、监控数据、日志数据。
图神经网络(GNN): 构建“字段-业务流程”图;识别高影响字段(如“BOM版本”影响成本、生产、库存)。
自动打标: 敏感数据:基于正则+命名实体识别(NER)标记;关键数据:结合业务KPI权重评分。
输出:数据分级清单(L1-L4)、关键数据质量规则(如“BOM版本变更必须同步MES”)、冗余字段清理建议
工具:PyTorch Geometric + Great Expectations
第三步:跨系统深度数据挖掘(What’s Hidden)
问题:单系统分析只见局部,无法发现跨域根因;例如:成本超支,是设计选材?生产浪费?还是采购涨价?
方法:跨系统关联规则挖掘: 将PLM(材料)、MES(废品率)、ERP(采购价)拼接为宽表;FP-Growth挖掘强关联:“材料A + 工序X → 废品率 >5%”。
因果推断(Causal Inference): 使用DoWhy库区分相关与因果;例:验证“ECN延迟是否导致交付延期”(控制其他变量)。异常传播分析: 基于Granger因果或传递熵,定位异常源头(如质量异常源于某供应商批次)。
输出:《跨系统根因分析报告》可执行优化建议(如“替换材料A可降本¥200万/年”)
工具:Microsoft DoWhy + MLxtend
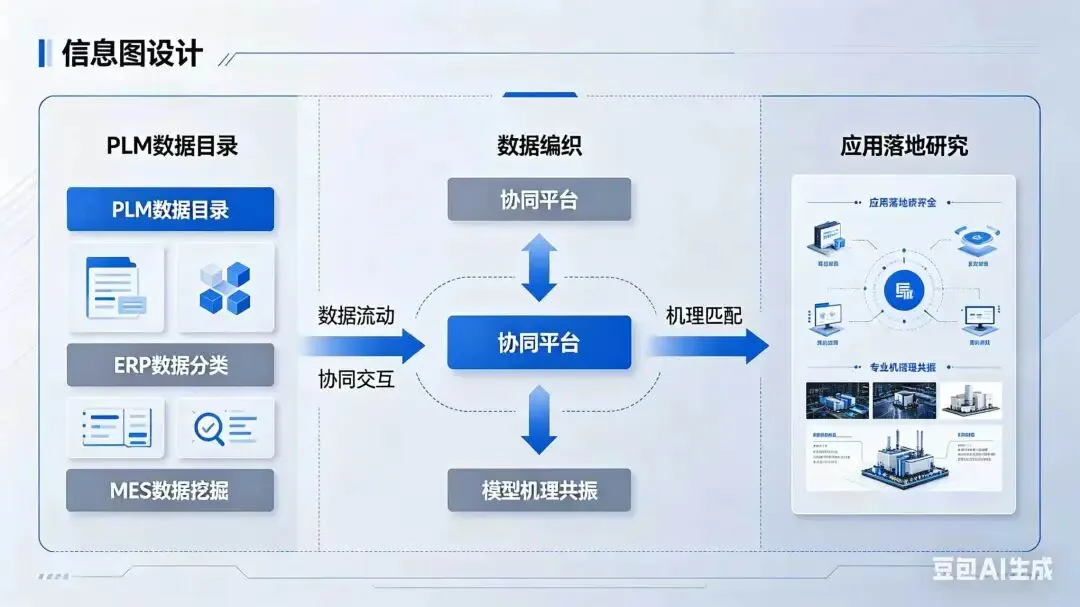
第四步:基于知识图谱的数据编织(How to Connect)
问题:数据物理分散,逻辑割裂;应用需手动拼接多系统数据,效率低。
方法:构建企业级制造知识图谱: 实体:产品、物料、BOM、工序、设备、订单、成本中心;关系:产品-包含->物料、工序-使用->设备、订单-消耗->物料。
Data Fabric架构: 图谱作为语义层,虚拟化查询;用户问“某订单的实际成本构成”,系统自动路由至PLM(BOM)、MES(报工)、ERP(价格)。
动态上下文感知: 根据用户角色(财务/计划/工艺)返回不同粒度数据。
输出:可查询的知识图谱(支持自然语言或Cypher)、统一数据服务API(如/api/order-cost/{id})
工具:Neo4j + Denodo + LangChain(NL2Cypher)
第五步:模型与机理共振建模(How to Decide)
问题:纯AI模型不可信,纯机理模型不灵活;需融合“专家经验”与“数据规律”。
方法:混合建模范式: 场景 、模型 、机理嵌入方式 、实时成本预测 、 XGBoost + 物料平衡约束 、损失函数加入Σ(投入-产出)=0 、 工艺参数优化 、强化学习(PPO) 、 动作空间限制在工艺窗口内 、 ECN影响分析 、 GNN + 规则引擎 、图传播 + IF-THEN业务规则
可解释性设计: SHAP值分解成本构成;LLM生成自然语言解释:“成本超支主因:铜材涨价15%”。
输出:高可信混合模型(精度+可解释+可控制)、模型决策报告(供审计与追溯)
工具:PyTorch + SHAP + LlamaIndex(RAG)
第六步:协同应用落地与反馈进化(How to Act & Learn)
应用场景示例:
场景 技术组合 价值
智能ECN协同 知识图谱(影响分析) + RPA(自动同步) + 数字孪生(变更预演) ECN执行错误率 ↓ 90%
实时订单利润看板 Data Fabric(成本数据编织) + 混合成本模型 + Power BI 财务月结时间 5天 → 1天
设计-制造联合优化 PLM仿真 + MES实际数据反馈 → PINN反向优化设计参数 NPI周期缩短30%
持续进化机制:反馈闭环:应用结果(如成本偏差) → 触发数据质量告警 → 自动启动模型重训练;MLOps for Industry:模型版本、数据版本、代码版本三者绑定;价值度量:量化AI贡献(如“年降本¥XXX万”)。
三、关键技术栈全景图
subgraph Data Layer
A[PLM] –> D[Data Fabric]
B[ERP] –> D
C[MES] –> D
subgraph AI Engine
D –> E[NLP元数据提取]
D –> F[GNN分类治理]
D –> G[跨系统挖掘]
D –> H[知识图谱]
H –> I[混合模型PINN/GNN/LLM]
subgraph Application
I –> J[ECN协同]
I –> K[实时成本]
I –> L[设计优化]
J –> M[反馈数据]
K –> M
L –> M
M –> D
四、效果验证指标体系
层级 指标 目标值
数据层 主数据一致性 ≥ 98%
模型层 成本预测准确率 ≥ 95%
应用层 ECN同步及时率 100%
业务层 单订单利润可见性 实时(<1小时)
战略层 数据驱动决策占比 ≥ 70%
五、总结:从“数据孤岛”到“智能神经中枢”,通过 AI重构PLM-ERP-MES数据体系,制造业可实现:目录重构 → “看得清”,智能分类 → “管得住”,深度挖掘 → “想得明”,数据编织 → “连得通”,模型共振 → “控得稳”,应用落地 → “用得好”。最终目标:让数据不再是“被动记录”,而是成为 主动驱动研发、制造、经营一体化的智能神经中枢,支撑企业在VUCA时代构建 韧性、敏捷、高效、绿色 的新质生产力。这,正是AI赋能制造业数字化转型的最高境界。