 夜雨聆风
夜雨聆风





OpenClaw和Hermes把AI Agent带歪了,大厂集体转向Token Plan的背后真相
OpenClaw和Hermes把AI Agent带歪了,大厂集体转向Token Plan的背后真相
2026年,AI编程工具圈发生了一件让所有用户愤怒的事:Cursor取消了无限使用,Windsurf改成了按量计费,GitHub Copilot也开始限制额度。
曾经承诺”月付XX元随便用”的Coding Plan,一夜之间全变成了Token Plan。
用户骂厂商贪心,厂商哭着说扛不住。但真相是——锅不在厂商,在底层的Agent框架。
OpenClaw和Hermes,这两个目前最流行的开源Agent框架,在上下文管理上犯了一个致命错误,直接把整个行业的Token成本推到了大厂都承受不起的地步。

一、大厂集体”变卦”:从Coding Plan到Token Plan的全景
这不是一两家公司的个别行为,而是整个行业的集体转向。我们看看都有谁:
Cursor——AI编程领域的老大哥,2026年推出了Ultra计划(20/月)中引入了信用额度(Credit)机制。曾经的”无限请求”变成了”每月有限次数的快速请求”,超额就要排队或者加钱。本质上就是从固定订阅转向了按量计费。
Windsurf——被Google收购后改名Antigravity,定价策略随之调整。虽然背靠Gemini有充足的模型配额,但同样引入了分层用量限制,重度用户需要购买更高档位。
GitHub Copilot——微软旗下的王牌,从最初的$10/月”无限补全”,逐步引入了Premium Request按量计费。超出基础额度的高级模型调用,按次收费。
字节跳动Trae——国内首款AI原生IDE,一开始以”完全免费”的策略疯狂获客,但随着用户规模暴增,也开始引入用量限制和排队机制。免费的午餐,终究有结束的一天。
阿里通义灵码——阿里云旗下的AI编程助手,从免费公测到正式商业化,走的是Token计费路线,按调用量阶梯定价。
百度Comate——百度的AI编程工具,同样从免费试用转向了按量计费的商业化模式。
腾讯云AI代码助手——腾讯系的产品也未能免俗,逐步引入了用量分层和超额计费机制。
一个两个转向可以说是商业策略,整个行业集体转向——说明底层一定有结构性问题。
二、两个任务烧掉多少Token?你看了会沉默
问题出在哪里?我们用OpenClaw做了一个最简单的测试:只跑两个编程任务,加上正常的日常对话,看看Token账单长什么样:

两个任务。不是二十个,不是两百个,就两个。 下面是OpenClaw后台的真实截图,注意看Token消耗数字:

这不是用户的问题,不是模型的问题,是Agent框架在疯狂浪费Token。
每一轮对话,OpenClaw都会把系统提示、全部历史消息、所有技能文件、记忆文件、工具调用的完整输出——一股脑全塞进上下文窗口。像一个不会收拾房间的人,所有东西摊在地上,越摊越多,从来不整理。
三、缓存命中率?OpenClaw和Hermes根本没有”命中”这回事
大模型的API计费有一个关键机制:Prompt Caching。如果你每次发给模型的请求前缀是一样的,重复部分可以走缓存,费用能降80%以上。
这是行业公认的降本利器。Anthropic、OpenAI、Google全都支持。

但OpenClaw的实际缓存表现是这样的——下面是真实运行数据截图,缓存命中率低得令人咋舌:
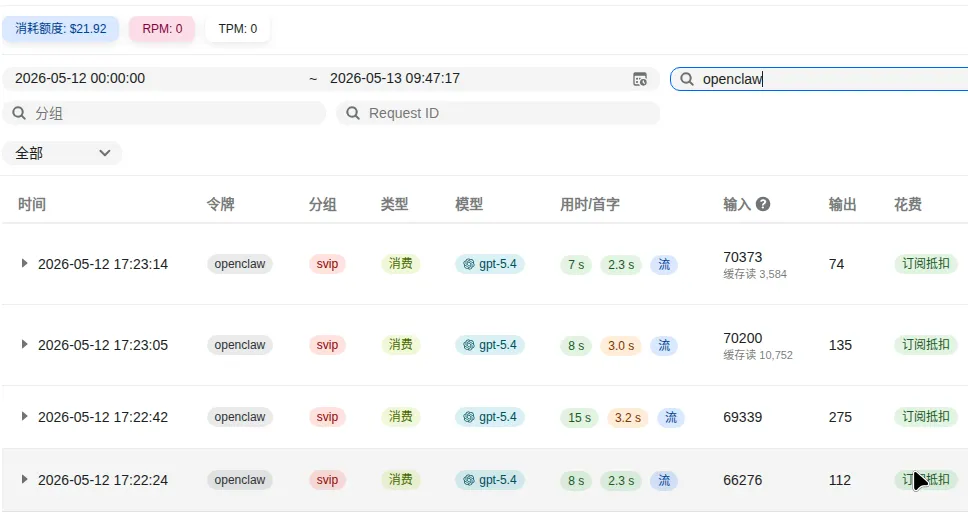
原因很简单也很致命:OpenClaw采用的是”全量堆叠”式上下文管理。每一轮对话,它都把所有内容重新拼接一遍。系统提示的顺序会变,技能文件的加载会变,中间结果的插入位置会变。对于模型的缓存机制来说,前缀一直在变,根本没法命中。
Hermes作为OpenClaw的”精神续作”,表现同样惨淡。两个框架,同一个病根:上下文管理没有设计,只有堆砌。
这不是bug,这是架构缺陷。不是某个版本没优化好,是从第一天就没想清楚上下文应该怎么管。
四、大厂为什么扛不住了?算一笔账你就懂
一个活跃的AI Agent用户,每天会产生50-100轮对话。每轮对话的上下文窗口可能达到50K-100K tokens。
在OpenClaw/Hermes的”全量堆叠”模式下:
-
每轮都重新发送全部历史 → Token用量随轮次线性增长 -
缓存命中率趋近于零 → 每个Token都按原价计费 -
系统文件反复加载 → 系统提示的Token成本被重复支付10次、20次、50次
一个重度用户每天消耗的Token可能达到数百万。按Anthropic Claude的定价算,一天的API成本就是几美元到十几美元。
用户付20美元/月的订阅费,厂商一天就要倒贴10美元。
一个月下来,厂商在一个用户身上亏几百美元。用户越多,亏越多。这就是为什么大厂不得不转向Token Plan——不是贪心,是活不下去。
而这一切的根源,就是底层Agent框架在上下文管理上的低效。当整个行业都在用同一套低效的上下文管理范式时,成本压力就会传导到每一个厂商,没有人能幸免。
五、Mente来了:97%缓存命中率,成本砍掉90%
当整个行业都在为Agent的Token成本头疼的时候,一个叫Mente的项目给出了答案。
下面是Mente的真实运行数据截图——缓存命中率97%以上,成本降低90%:
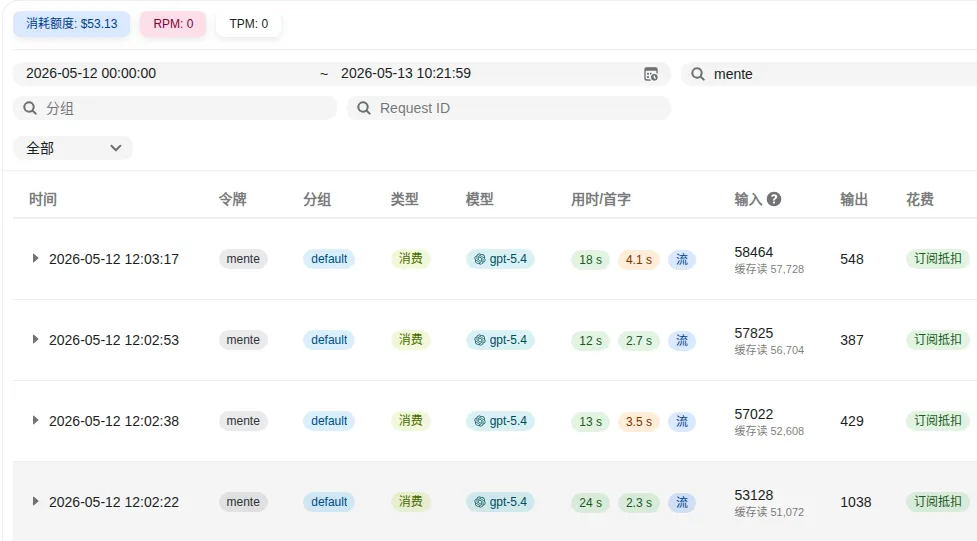
同样是AI Agent框架,同样跑编程任务,同样接大模型API。Mente的Token账单只有OpenClaw的十分之一。
Mente做了什么不一样的事?
1. 上下文分层,而不是全量堆砌
Mente把上下文切成了明确的层级:系统指令层、技能层、记忆层、对话层。每一层的位置固定、顺序稳定。模型的缓存机制第一次有了”前缀”可以命中。
OpenClaw是把所有东西搅在一起倒进搅拌机,Mente是分门别类放进收纳柜。
2. 增量发送,而不是重复发送
每一轮对话,Mente只发送新增的内容。历史对话经过压缩和摘要后,以精简的形式保留,而不是把原始记录原封不动再发一遍。
同样100轮对话,OpenClaw发送了100遍完整历史,Mente只发送了1遍完整历史+99次增量。
3. 主动压缩,而不是被动膨胀
Mente内置了自动压缩机制(model_auto_compact_token_limit),当会话Token接近阈值时,自动触发上下文摘要。关键信息保留,废话丢掉。
OpenClaw的做法是:让上下文一直膨胀,直到撞到模型的Token上限,然后粗暴截断。
一个是主动管理,一个是放任自流。
4. 任务快照,而不是从零开始
网关重启、会话中断——在OpenClaw里意味着上下文全部丢失,从头来过,之前花的Token全白费。
Mente有短期任务记忆快照,中断后说”继续任务”就能恢复,不浪费一个Token。
六、Mente不只省钱,它才是Agent该有的样子
成本只是表面。Mente真正让人兴奋的,是它重新定义了AI Agent应该是什么:
跨平台不是加分项,是基本功。 CLI、Telegram、Discord、Slack、WhatsApp、Signal——一个Agent进程,所有入口共享上下文,无缝切换。
记忆不是存文件,是真的在学习。 周期性记忆回顾、跨会话的长期理解、技能自动沉淀和改进。你的Agent用得越久越懂你。
自动化不是写脚本,是说人话就行。 内置Cron调度,”每天早上8点给我发日报”——说完就完了。
部署不是绑定电脑,是随处可跑。 $5 VPS、GPU集群、Docker、SSH、serverless。不挑硬件,不挑环境。
供应商不是锁死的,是随时切的。 mente model一行命令,OpenAI、Anthropic、Kimi、MiniMax、小米MiMo、NVIDIA NIM——想用哪个用哪个。
七、迁移成本?一行命令的事
从OpenClaw迁移到Mente,不需要重头来过:
mente claw migrate
你的SOUL.md、MEMORY.md、自建技能、API Key、消息平台配置——自动导入,一个都不丢。
八、写在最后
AI Agent正在从”能用”走向”好用”。但OpenClaw和Hermes用”全量堆叠”的思路,把Agent变成了Token黑洞,把整个行业拖进了”按量计费”的泥潭。
当Cursor、Windsurf、GitHub Copilot、Trae、通义灵码、Comate集体从Coding Plan转向Token Plan时,你应该意识到:这不是巧合,是底层架构出了问题。
Mente用工程手段证明:Agent的上下文管理可以高效,Token成本可以降一个数量级,用户体验可以不打折。
97%的缓存命中率,不是靠模型变便宜了,是靠架构变聪明了。
如果大厂的Coding Plan注定要变成Token Plan,那至少应该选择一个不会疯狂浪费Token的底层框架。
Mente就是那个答案。
📎 GitHub: github.com/chemany/Mente[1]
📖 文档: chemany.github.io/Mente/docs[2]
💬 Discord: discord.gg/NousResearch[3]
📦 安装: npm install -g mente-agent
开源项目,MIT协议。为Mente项目而构建。
引用链接
[1]github.com/chemany/Mente: https://github.com/chemany/Mente
[2]chemany.github.io/Mente/docs: https://chemany.github.io/Mente/docs/
[3]discord.gg/NousResearch: https://discord.gg/NousResearch