 夜雨聆风
夜雨聆风





OpenClaw从入门到入土:如何避免被坑,揭秘当前最靠谱的龙虾配置 07
在配置龙虾过程中,我遇到过很多天坑。坑到每一个都可以成为放弃使用龙虾的充分理由。
但是,作为项目经理,填坑是我们的本质工作。需要把这些天坑一一罗列出来,挨个攻关解决,才是项目经理真正做事的态度。
一.龙虾连不上国产AI模型
这个倒不全是龙虾的问题。
想要龙虾连上AI模型,必须告诉它这个模型是厂商(providers)是谁,AI版本(models ID)是哪个。
当前国产厂商为了抢市场,AI模型更新速度快,还按照功能进行细分,名目繁多,导致市面上存在各种眼花缭乱的版本。
更麻烦的是,同一个模型,厂商宣传用A版本号,实际发布用B版本号,龙虾认识的是C版本号。
比如说豆包:
○ 宣传的版本号是Doubao-Seed-2.0
○ 实际发布的是volcengin/doubao-seed-2-0-pro-260215
○ 龙虾认识是doubao/doubao-seed-2-0-pro-260215
很多兄弟就倒在这一步,捣鼓半天,发现龙虾根本连不上AI模型,毅然放弃。
所以,在此列出龙虾认识的AI模型厂商,版本号以及连接线路,彻底解决这个问题。
DeepSeek:
○ AI模型厂商(providers):deepseek
○ 最新AI模型版本号(models ID):deepseek-v4-flash
○ 连接线路(baseUrl):https://api.deepseek.com/v1
Kimi:
○ AI模型厂商(providers):moonshot
○ 最新AI模型版本号(models ID):kimi-k2.6
○ 连接线路(baseUrl):https://api.moonshot.cn/v1
豆包:
○ AI模型厂商(providers):doubao
○ 最新AI模型版本号(models ID):doubao-seed-2-0-pro-260215
○ 连接线路(baseUrl):https://ark.cn-beijing.volces.com/api/v3
二.龙虾无脑浪费token
我申请的豆包模型API账号送了50万免费的token。
我天真地以为做个龙虾机器人连接调试,简单地问几句“今天天气如何?”,这50万token可以撑好久。
没想到上午申请的账号,下午完成调试,晚上就收到短信告知API账号欠费。

当然,白嫖的token烧着不心疼,但是欠费会不会影响本人摇摇欲坠的征信,心里还是非常忐忑。
所以我得搞清楚,从前到后发了不到100字的消息,豆包也就输出了100字的天气情况,为啥能烧掉这么多token?
先去豆包官网上查查token的具体使用情况,发现输出的token数量问题不大,只有6500个。但是输入token数量,居然有630000个。
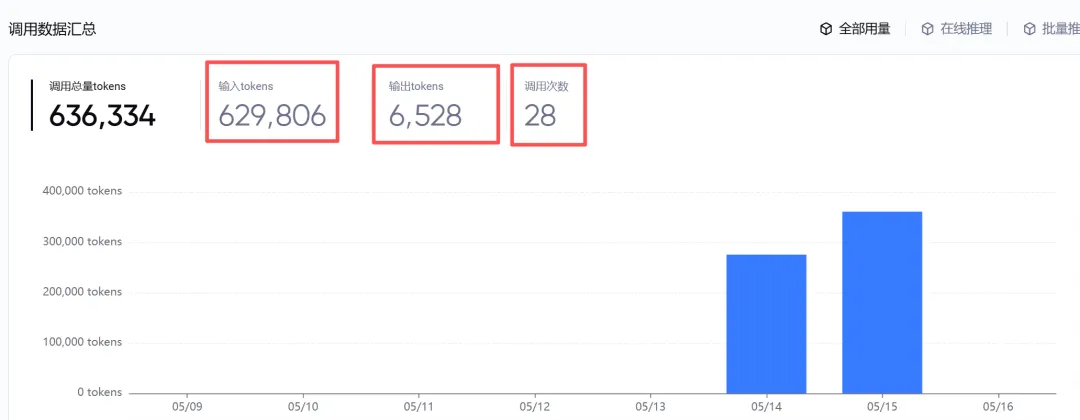
查,必须查到底。先去看看龙虾的官方操作指导怎么说:
每次调用AI模型时,OpenClaw不只发送用户消息,还会把系统提示(Prompt)、工具定义(Tool)、技能列表(Skill)、记忆文件(Memory)、历史对话(Session)、tool call 返回结果等一起打包发送。
再去看看当前我的配置下,这些文件有多大。进入龙虾的网页聊天界面,输入 /text list,反馈结果:
🧠 Context breakdown (detailed)
System prompt (run): 31,340 chars (~7,835 tok) (Project Context 13,783 chars (~3,446 tok))
Skills list (system prompt text): 3,417 chars (~855 tok) (11 skills)
Tool schemas (JSON): 32,037 chars (~8,010 tok) (counts toward context; not shown as text)
其中,prompt占了7800个token,skill占了855个token,tool占8010个token。
也就是说,我每执行一次命令,龙虾至少要给我额外烧掉2万个token。
结合豆包官网上记录我执行了28次命令,那么龙虾至少给我额外烧掉了56万个token,这个账就基本对得上了。
所以,为了不被龙虾搞得倾家荡产,必须针对初始化配置中的prompt,skill以及tool进行瘦身。
三.模型与模型之间亦有区别
但是,豆包就没有问题吗?
除了豆包以外,我还测试了Kimi。
同样的龙虾配置下,我用豆包的频率跟Kimi一样,豆包烧完了50万个token之后,还提醒我欠费0.35元;而Kimi只花了不到0.1元。
查,必须查到底。
为了公平起见,直接咨询第三方ChatGPT,给出的答复是:
Kimi 支持Prefix Cache,而豆包不支持。
Prefix Cache的字面意思是前文缓存,可以理解为龙虾发送自带的配置文件被AI模型缓存起来了。
这个功能有啥用呢,举例说明:
我让龙虾问AI模型“今天天气如何?”,龙虾除了把问题抛给AI模型以外,还自动夹带了2万个token的私货。
具备Prefix Cache功能的AI模型,就会把这2万个token的私货缓存起来,在你二次提问时,不去读取这些私货,直接处理问题。
这样二次处理的token费用会变得极少。也就是前文提到的缓存命中。
前文回顾:OpenClaw从入门到入土:拆解养虾成本,如何精打细算花小钱办大事 04
而不具备Prefix Cache功能的AI模型,你每次提问题,它都会把龙虾夹带的私货重新读取一遍,导致输入token费用奇高无比。
所以,别看到豆包当前阶段token费用比kimi便宜一半,但是它没搞定Prefix Cache功能之前,是真的不敢用,欠费就欠费吧。
四.龙虾配置瘦身
再回过头来处理龙虾配置的问题,这个是导致很多人放弃龙虾的关键:
无效配置太多,导致承担不起输入token的费用。
如果只龙虾当成一个项目管理AI助手,其实仅具备以下功能即可:
1. 读取并发送飞书消息,包括个人以及群消息。这个功能,前面已经搞定得七七八八了。
2. 读取、处理并生成飞书文档,这个只需要添加跟飞书相关的skills和tools。
至于其他的Prompt,skill和tool,跟飞书使用无关的全部可以关掉。
所以接下来,我们要把这些用不上的私货全部挖出来,进行全面优化:
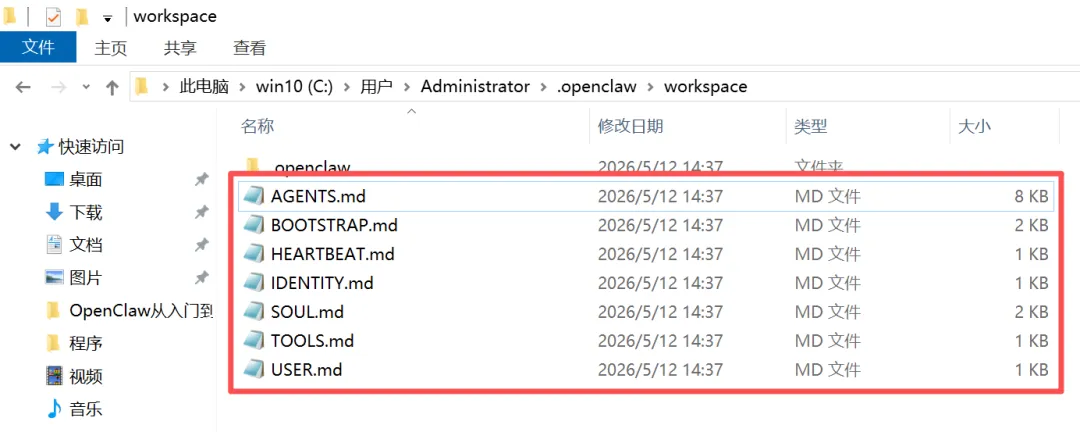
1. Prompt都保存在.md文件里,保留:
○ AGENTS,后续项目管理专用的prompt需要添加到这里。
○ BOOTSTRAP,确定启动规则,比如说让Deepseek仅做深度分析,不用网络搜索。
○ IDENTITY,明确龙虾的工作范围,让龙虾知道该干哪些,不该干哪些。
○ USER,设定用户职业岗位,方便AI模型更快地给出对应领域的解决方案。
其余的.md文件内容全部清空,留个空文件就行。不能删掉文件,否则龙虾会报错。
2. Skills直接在openclaw.json里配置,名称里不以feishu开头的全部禁用。

3. Tools同样在openclaw.json里配置,保留龙虾自带的读/写/通信,以及飞书相关的tools,其余的全部禁用。
把这些坑填完之后,基本上,龙虾算是洗干净,可以下锅了。
五.飞书龙虾助手配置
如果飞书的龙虾助手需要多人使用,那么还得在openclaw.json更新配置,因为龙虾默认禁止群聊消息,让其他人激活龙虾助手。
配置代码如下:
{channels:{feishu:{groupPolicy:"allowlist",groupAllowFrom:["飞书群ID"],},},}
六.总结
龙虾之所以很多人养不起来,根本原因在于这条链上的各个环节都有问题:
1. 国产AI大模型版本混乱,且便宜没好货,不声不响地挖坑。
2. 龙虾自带的初始配置压根不考虑特定人群使用情况,需要大幅修改,才能洗干净下锅。
3. 与龙虾对接的APP配置复杂,且需要与龙虾进行深度联调,劝退大批不懂技术的小白。
不过别担心,接下来我会把修正OK的文件全部释放出来,一键搞定龙虾配置,敬请期待。
(未经本人许可,请勿转载或商业用途)