 夜雨聆风
夜雨聆风





从 OpenClaw 到 OpenHuman:私人 AI Runtime 的雏形
每次打开 AI 助手,你都在做一件很荒唐的事:
给一个超级聪明的陌生人,重新介绍你自己。
客户催到哪一步了,GitHub issue 卡在什么地方,Notion 里方案改过几版,下次评审会是什么时候。
这些它全都不知道。
所以很多 AI 产品看起来很聪明,用起来却特别累。
你要一遍遍复制背景、上传资料、解释上下文。
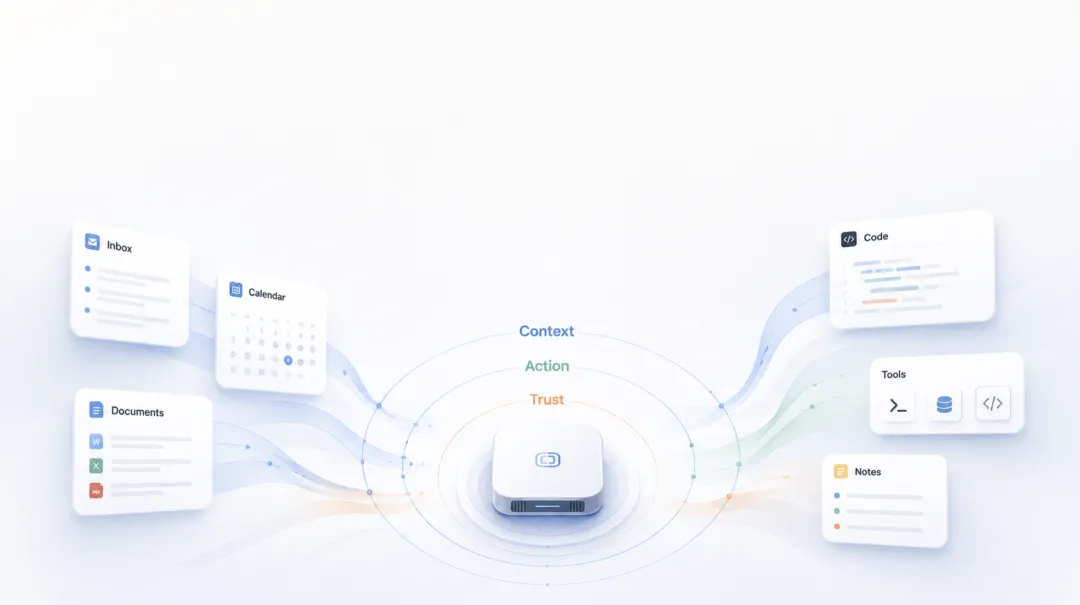
OpenHuman 想解决的,正是这个问题。
它的野心不是做一个更漂亮的聊天框。
而是给私人 AI 补上缺失的那一层底座:
把个人上下文、工具执行、应用集成和安全边界,全部放进一个 local-first 的 agent 运行时里。
一句话:
它要让 AI 不再临时听你解释世界,而是持续拥有一套可控的、真正属于你的工作上下文。
它到底是什么?不是助手,是运行层
很多人第一眼会把 OpenHuman 当成“又一个 AI 助手”。
但它真正想做的,是助手下面的那层基础设施。
你可以把一个 AI 产品拆成三个平面:
-
• 界面层:桌面 App、聊天入口、通知、语音、会议 -
• 模型层:云端模型、本地模型、推理调用 -
• 运行层:上下文、工具、记忆、权限、安全、失败处理
绝大多数 AI 应用都只停在前两层。
界面做得更顺,模型换得更快,插件入口加得更多。
OpenHuman 的重心,结结实实地踩在第三层。
它的仓库结构也印证了这一点。
app/ 是 React + Tauri 桌面入口。
app/src-tauri/ 负责桌面壳、窗口、权限和 core lifecycle。
真正的核心在 src/ 里的 Rust openhuman-core。
再往下看 src/openhuman/,里面装着 agent、tools、memory、composio、local_ai、voice、meet、security 等一系列子系统。
这就很说明问题。
它有桌面入口,但重点不在桌面。
它能聊天,但重点不在聊天。
它能接应用,但重点不在“接了多少个”。
如果说套壳产品关心的是“模型怎么包装”,OpenHuman 关心的则是另一个问题:
私人 AI 怎么被安全、持续地运行起来?
这背后必须搞定四件硬事:
-
• 上下文怎么进来 -
• 记忆怎么沉淀 -
• 工具怎么执行 -
• 风险怎么拦住
少一件,它都只会是又一个聊天产品。
上下文层:先把你的世界变成 AI 能用的材料
私人 AI 的第一道坎,根本不是模型能力。
而是上下文供应链。
它必须回答四个问题:
数据从哪里来?
怎么变干净?
什么该记?
以后怎么找回来?
OpenHuman 走的是“应用集成 + 本地记忆”的路线。
外部应用的接入主要靠 Composio。
Gmail、Notion、GitHub、Slack、日历、Drive、Linear、Jira……
这些不只是一串菜单里的插件。
它们是上下文入口。
集成层分为两边。
一边在云端管账号、OAuth、webhook、计费、toolkit allowlist 和 HMAC webhook verification。
另一边在 Rust core 里管本地 controller、agent tools、event bus、periodic sync 和 provider-specific sync。
这里有个很能说明野心的常量:
TICK_SECONDS = 120020 分钟一跳。
它会遍历 active connections,找到对应 provider,再判断要不要同步。
也就是说,OpenHuman 不想等你提问了才临时去翻邮件和 GitHub。
它想提前默默整理你的工作世界。
但连接只是入口。
真正决定质量的,是记忆层。
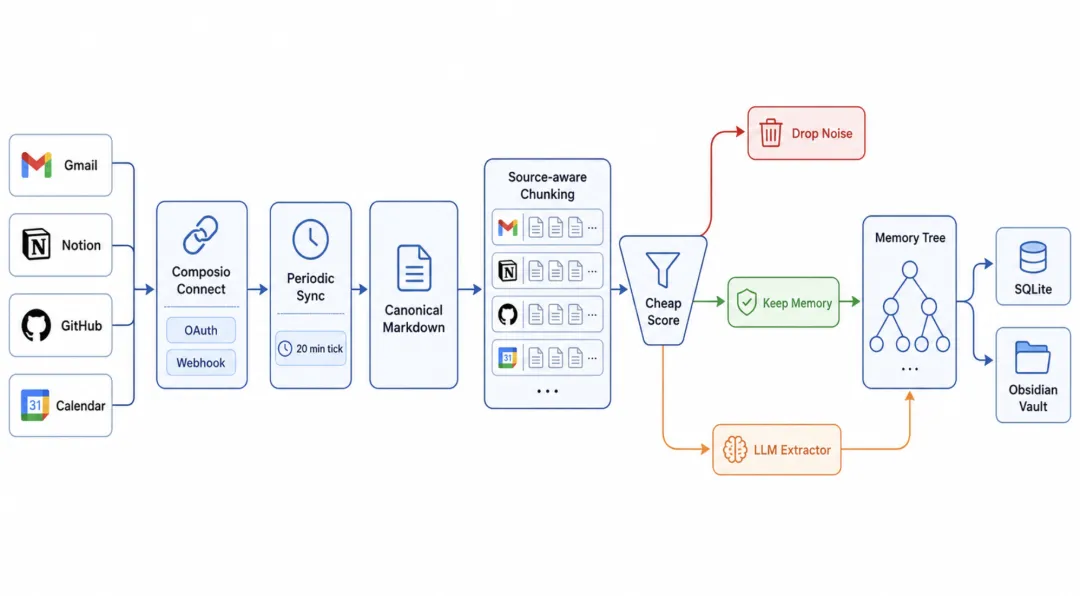
OpenHuman 的 Memory Tree 采用了一条很务实的漏斗流水线。
src/openhuman/memory/tree/ingest.rs 里的主线是:
canonicalise -> chunk -> fast score -> persist -> enqueue jobs拆开说,就是六步:
-
1. 从 Gmail、Notion、GitHub、日历等接入源拉取数据。 -
2. 清洗并转换成统一格式,也就是 canonical Markdown。 -
3. 按来源分块:聊天按消息边界切,邮件按线索切,文档按段落贪心打包。 -
4. 用 cheap signals 快速打分。 -
5. 明显是噪音的直接丢,明显有价值的直接留,中间模糊地带才让 LLM extractor 介入。 -
6. 有价值的记忆写入 SQLite 和 Obsidian-compatible vault,并生成后续任务。
这里有两个细节很关键。
第一,chunk 不是粗暴按 token 硬切。
DEFAULT_CHUNK_MAX_TOKENS = 3_000 只是上限,真正重要的是按来源理解结构。
邮件有线程。
聊天有上下文。
文档有段落。
GitHub issue 有状态变迁。
如果全都当成普通文档硬切,记忆只会变成碎片垃圾。
第二,score 不是全丢给大模型。
score/mod.rs 里有三条阈值:
DEFAULT_DEFINITE_DROP = 0.15
DEFAULT_DROP_THRESHOLD = 0.3
DEFAULT_DEFINITE_KEEP = 0.85低价值内容先被挡掉。
高价值内容直接保留。
只有模糊地带,才交给模型判断。
这比“搭个向量库”更接近私人 AI 的真实困境。
私人数据从来都不是干净文档。
它又多,又碎,又吵。
OpenHuman 的 Memory Tree 价值正在于此:
把散落的信息流,变成可过滤、可追溯、可再次调用的长期上下文。
普通 RAG 关心“文档怎么搜到”。
私人 AI 记忆关心的是:
什么该记、怎么记、记完后能不能解释来源。
行动层:不是 prompt,而是缰绳
上下文让 AI 知道发生了什么。
行动层决定它能不能动手,以及怎么动手。
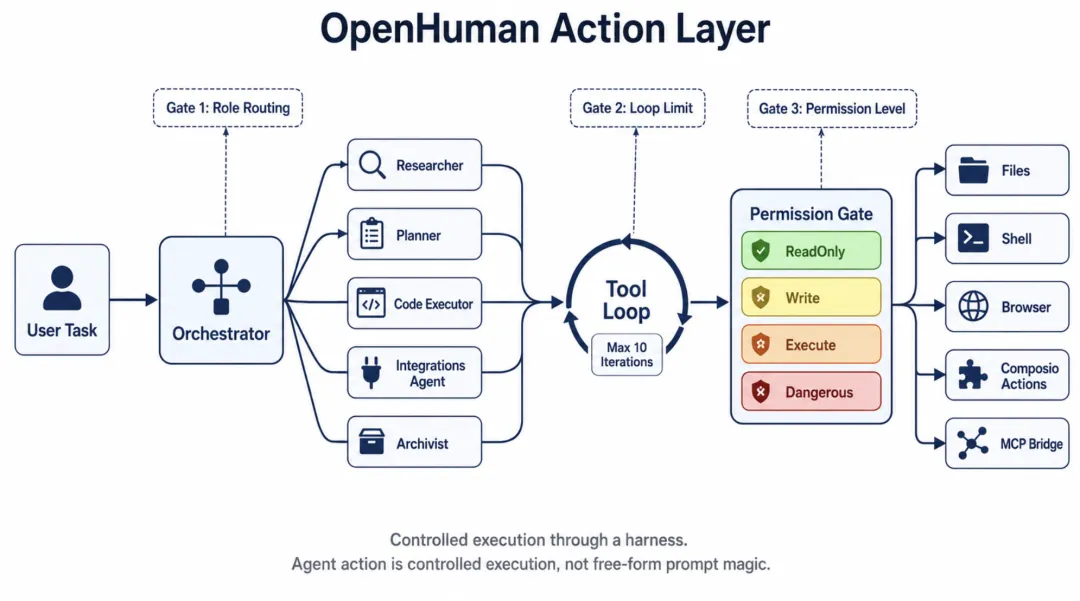
OpenHuman 的行动层,本质上是在给 agent 套缰绳。
不是让模型自由发挥。
而是把角色、循环、工具和权限都收进 harness。
第一道闸,是角色分工。
系统里有负责调度的 orchestrator,负责研究的 researcher,负责计划的 planner,执行代码的 code_executor,调用 SaaS 工具的 integrations_agent,管理长期记忆的 archivist。
这不是多 agent 炫技。
这是工具面的收缩。
一个 agent 看到的工具越多,选错工具的概率就越高。
让每个角色只面对自己需要的那组工具,出错空间就小得多。
第二道闸,是行动循环上限。
真正的执行循环在 src/openhuman/agent/harness/tool_loop.rs。
它的流程很朴素:
发消息 -> 解析工具调用 -> 执行工具 -> 追加结果 -> 继续循环 -> 最终回复默认最多只允许 10 轮工具调用:
DEFAULT_MAX_TOOL_ITERATIONS = 10这行代码不花哨,但分量很重。
能执行工具的 AI,必须先有刹车。
第三道闸,是工具权限分级。
src/openhuman/tools/ops.rs 里注册了 shell、file read/write、grep、edit、apply_patch、cron、http_request、web_fetch、browser automation、web_search、node_exec、MCP bridge、Composio actions 等工具。
这已经不是“给模型塞几个函数”。
这是把 AI 接到桌面工作流、开发工作流和 SaaS 工作流里。
问题也随之升级:
工具不是够多就行。
工具必须可分级、可限制、可审计。
所以 src/openhuman/tools/traits.rs 定义了权限层级:
None
ReadOnly
Write
Execute
Dangerous像 Gmail 发邮件、Notion 创建页面、日历创建事件这类会改变真实世界状态的操作,默认就是 Write 级别。
在只读沙箱里,这类动作会被拦掉。
高风险 shell 命令也不会被随便放行。
OpenHuman 行动层真正硬核的地方就在这里:
它不是在展示“模型会调用工具”,而是在回答“工具调用怎么被治理”。
信任层:安全不是口号,是控制面
私人 AI 最大的矛盾在于:
想要几分钟内建立上下文,就需要广泛且持续的访问权限。
OpenHuman 的安全重点,绝不是说一句“本地优先”。
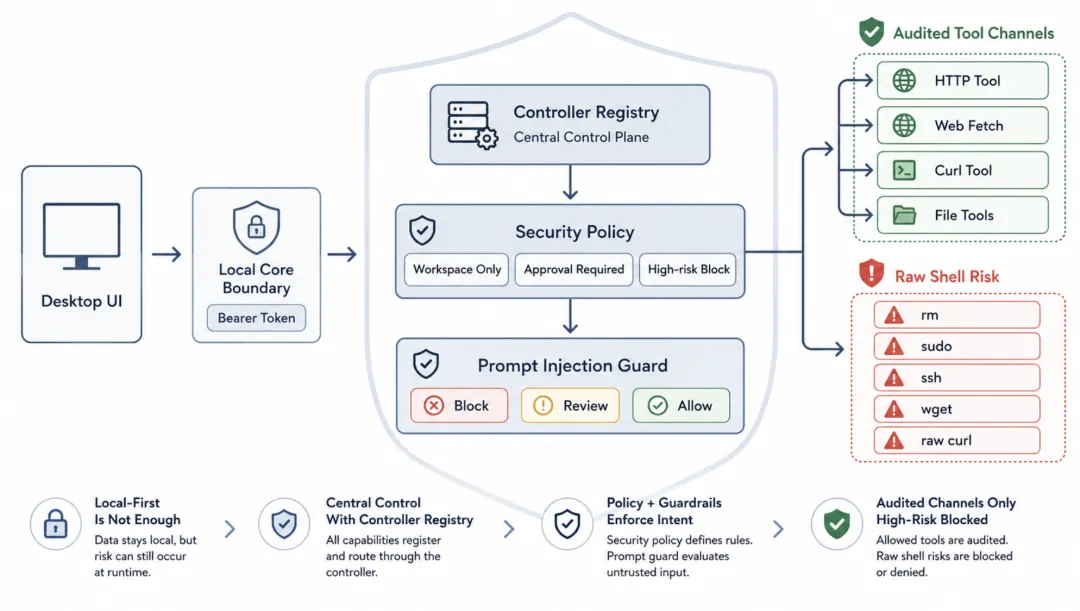
它把风险收进了运行时控制面。
第一,前端不能直通系统能力。
Tauri 桌面壳和 Rust core 之间通过本地 HTTP/JSON-RPC 通信,并生成 256-bit bearer token。
这意味着桌面 UI 和本地 core 之间有明确边界。
第二,能力统一注册。
src/core/all.rs 把 app state、credentials、tools、memory、security、composio、agent、workspace、notifications 等 controller 集中注册。
能力不散落,才谈得上治理。
第三,危险操作被策略约束。
src/openhuman/security/policy.rs 的默认策略包括:
autonomy = supervised
workspace_only = true
max_actions_per_hour = 20
require_approval_for_medium_risk = true
block_high_risk_commands = true这几行的意思很直白:
默认监督执行。
限制工作区。
限制动作频率。
中风险要审批。
高风险命令直接拦。
第四,prompt injection 不只靠前端提醒。
docs/PROMPT_INJECTION_GUARD.md 给了明确阈值:
score >= 0.70 -> block
0.45 <= score < 0.70 -> review
score < 0.45 -> allow拦截点在 model inference 或 agent/tool loop 前。
前端只是提示。
后端才是权威。
还有一个细节很能体现安全思路:raw shell。
rm、dd、sudo、ssh、curl、wget 这类命令会被视为高风险。
但 OpenHuman 不是简单禁止联网。
它有专门的 http_request、web_fetch、curl tool。
raw shell 里的 curl 很难控。
专用网络工具可以挂上 domain allowlist、SSRF guard、下载大小限制和 workspace 限制。
这就是安全控制的核心:
危险能力不是完全拿掉,而是放进可审计的专用通道。
对普通聊天机器人来说,提示注入可能只是回答被带偏。
但对 OpenHuman 这样的 agent runtime,注入可能意味着工具滥用、数据泄露,甚至外部状态被篡改。
它的安全思路,是把私人 AI 的风险从模型层下沉到运行环境层去治理。
它现在处在什么阶段?
OpenHuman 现在不是玩具,也不是成熟产品。
它更像一台结构已经搭起来、仍在高速施工的原型机。
强项很清楚:
桌面入口、本地 Rust core、Memory Tree、agent 缰绳、工具权限、安全策略,都在同一条主线上。
它抓准了私人 AI 的真问题。
短板也很清楚:
desktop、OAuth、memory、agent loop、tools、voice、meet、local AI、screen intelligence、webhooks、billing 等模块全挤在一个项目里,复杂度极高。
因此,它最适合开发者、AI 重度用户、产品经理和创业者研究把玩。
暂时不适合直接接入主力公司邮箱、GitHub、Drive 和日历。
也不适合稳定性与合规门槛很高的生产环境。
结论可以压得很短:
OpenHuman 现在还粗糙,但它押中了私人 AI 的下一道题:系统能不能安全地理解我、记住我、替我行动?
试 OpenHuman 之前,别先问“它有多聪明”。
先问三个更实际的问题:
它读了什么?
它记住了什么?
它能替你做什么?
这三个问题的答案,比任何宣传语都更重要。
让 AI 懂你,从不再自我介绍开始。