 夜雨聆风
夜雨聆风





文档搜出一堆不相关?混合检索让RAG召回率从62%飙到89%
文档搜出一堆不相关?混合检索让RAG召回率从62%飙到89%
上周有个做企业知识库的朋友跟我吐槽,说他们公司的RAG系统上线后,用户搜”工资发放流程”,结果出来一堆考勤制度的文档。用户反馈说:”这AI怕不是喝多了?”团队排查了一周,最后发现——问题出在检索方式上。
其实这不是个例。我见过至少10个RAG项目,在检索环节翻车的占了一半以上。很多团队把精力都花在调prompt、选模型上,却忽略了最关键的一件事:你到底用什么方式把相关文档找出来?
今天聊聊混合检索(Hybrid Search)。这玩意儿不是什么高大上的新技术,但效果真的一用一个准。
01|传统搜索的致命伤
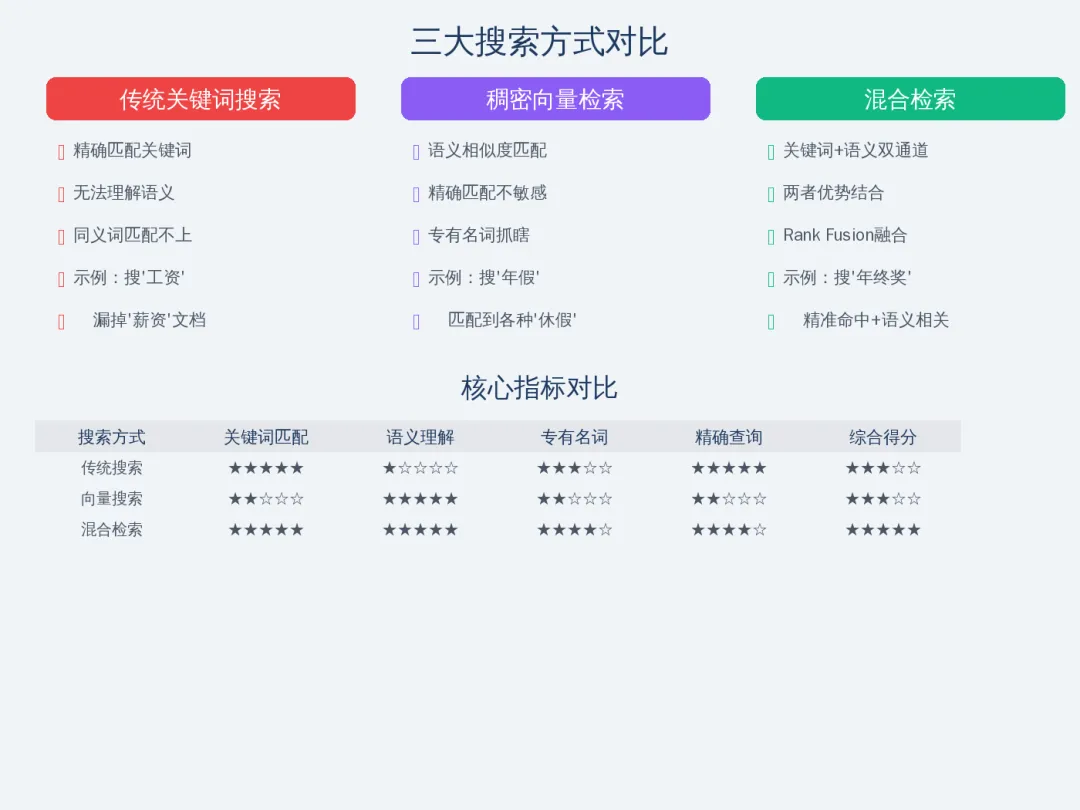
你想象一下这个场景:公司内部有一套HR系统,里面有几百份员工手册、管理制度、SOP文档。传统的关键词搜索存在两个致命问题。
问题一:同义词匹配不上。 员工搜”工资发放流程”,文档里写的是”薪资结算流程”。虽然说的是同一件事,但关键词匹配不上,搜索结果就是零。这就像你去超市找”土豆”,货架上标签写的是”马铃薯”,你就找不到了。听起来很蠢,但传统搜索就是这样工作的。
问题二:语义理解为零。 搜”怎么请假”,系统返回的是包含”请假”这个关键词的文档。但用户真正想知道的可能是”年假可以请几天”、”事假扣不扣工资”这些具体政策。传统搜索只管”词有没有出现”,不管”这个问题是什么意思”。
而向量搜索(Embedding Search)恰好能弥补这两个问题。它把文本转成高维空间中的向量,相近语义的文本向量距离更近。搜”工资发放”,它能匹配到”薪资结算”、”薪酬管理”这些语义相关的文档。
听起来很完美对吧?但向量搜索也有它的弱点。
向量搜索的软肋:对精确匹配不敏感。 比如用户搜”2024年的休假政策”,向量搜索可能把2023年和2025年的文档也搜出来,因为它只认语义相似度,不认具体年份。同样,”产假15天”和”产假90天”这两个含义完全不同,但语义向量可能很接近。
还有一个更致命的问题:遇到专有名词和缩写,向量搜索基本抓瞎。 比如员工搜”OA系统报修流程”,文档里写的是”办公自动化系统报修流程”——虽然”OA”和”办公自动化系统”是同一个东西,但它们的向量表示差别很大,可能完全匹配不上。
所以现实情况是:纯关键词搜索和纯向量搜索,都不够用。
02|混合检索:让BM25和向量搜索打配合

混合检索的思路其实非常简单——既然两种搜索方式各有优劣,那把它们的优势结合起来不就行了?
先说说混合检索里的两个核心组件:
第一个:BM25(传统关键词搜索的进化版)。 很多人觉得传统搜索已经过时了,但BM25在精确匹配场景下依然无可替代。它不光看关键词出现了没有,还会计算这个词在文档中的重要程度。如果一个词在整篇文档中出现次数多,但在整个文档库里不常见,那这个词的权重就高。比如”工资”这个词在很多文档里都有,权重就低;”报销”这个词只在财务相关文档里出现,权重就高。BM25通过这种机制,可以精准命中包含特定关键词的文档。
第二个:稠密向量检索。 就是前面说的Embedding Search。它把文本转成向量,用语义来找匹配。BERT、SBERT、E5这些模型都能做这事。
混合检索的核心就是:同时用BM25和稠密向量去搜,然后把两边的结果合并排序。
但这里有个关键问题:两边的分数维度不一样。BM25的分数可能是0到10之间的数值,向量相似度可能是0到1之间的余弦值。它们没法直接比较,得先做归一化处理。
通常的做法是Rank Fusion排序融合。这个算法简单说就是把两边的搜索结果各自分配排名分,然后按权重合并。比如BM25的结果和向量检索的结果,各取前100条,每条结果根据排名位置得到一个分数,然后加权合并。
权重怎么配?这是个实操问题。一般来说,如果是名字、编号、缩写这些精确匹配场景多的应用,BM25的权重可以给到0.6以上。如果是长文本、开放性问答,向量检索的权重可以更高。但最靠谱的做法是:拿你的真实数据去跑AB测试,找到最合适的权重比例。
我见过的最常用的三套混合策略:
策略一:Rank Fusion+加权合并。 各自检索Top K,然后用加权分数合并排重。实现简单,效果稳定,适合大多数场景。
策略二:级联式检索。 先用BM25粗筛一遍,把候选集从100万缩小到1万,再用向量检索做精排。这样既保留了BM25的精确匹配能力,又弥补了它的语义短板。适合超大规模文档库。
策略三:自适应混合。 根据查询的特征动态调整混合权重。比如短查询(1-3个词)更依赖BM25权重,长查询(10个词以上)更偏向向量检索。这种策略最灵活,但实现也最复杂。
03|实操案例:某公司HR系统的混合检索改造
我参与的一个真实项目,某互联网公司HR知识库的RAG系统,改造前后的效果对比非常明显。
这个知识库有2000多份HR相关的文档,包括员工手册、薪酬制度、绩效管理、培训体系、考勤规定等。改造前用的是纯向量检索,Effectve Embeddings模型用了text-embedding-ada-002。
用户的常见问题五花八门:
-
“2024年的年终奖什么时候发?” -
“转正流程怎么走?” -
“出差补贴标准是多少?” -
“公积金缴纳比例是多少?” -
“OA上怎么提交请假申请?”
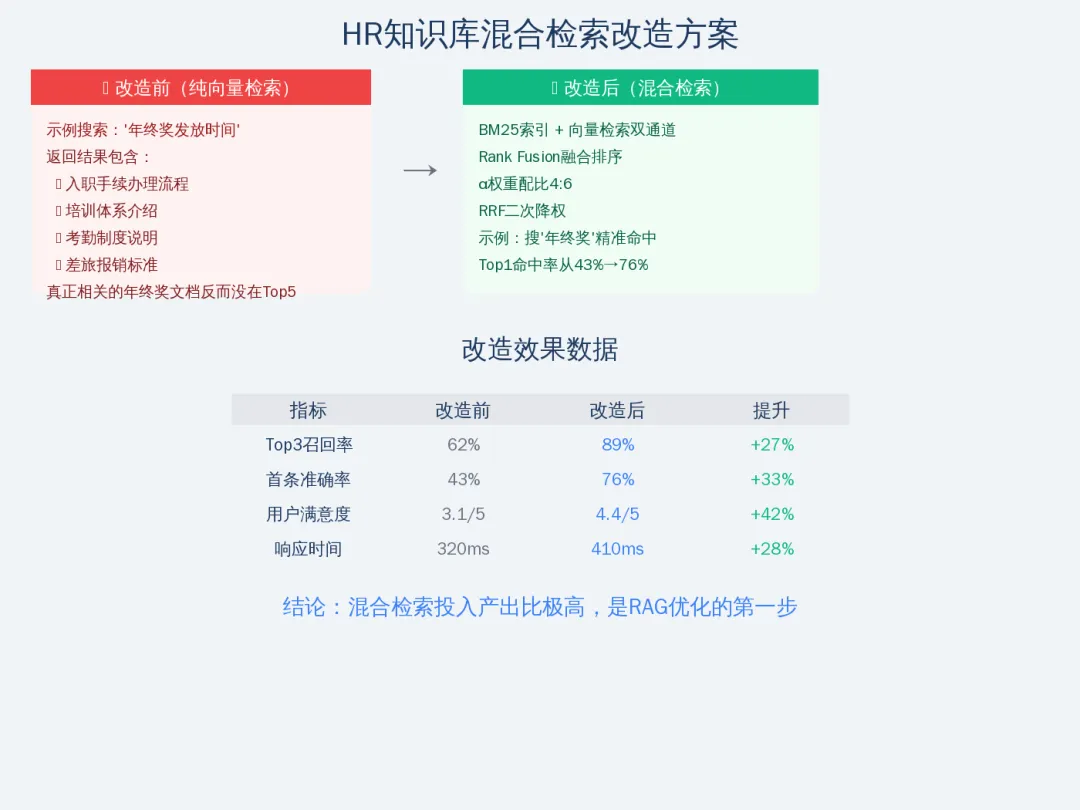
改造前的结果:用户搜”年终奖发放时间”,系统能命中语义相关的文档,但经常把入职手续、培训安排这些完全不沾边的东西也一起推送出来。Top 3相关度只有62%左右。
改造方案:
第一步,搭建BM25索引。我们用Elasticsearch搭建了传统倒排索引,对所有HR文档进行分词和权重计算。
第二步,保留原来的向量检索通道,用text-embedding-3-small替换了原来的模型(后者成本更低,效果反而更好)。
第三步,实现Rank Fusion排序融合。我们把BM25和向量检索各自返回的前50条结果进行加权合并。经过20组测试,发现BM25:向量检索 = 4:6的权重配比效果最好。
第四步,在上层加了一个RRF调整层,对重排后的结果做二次降权。简单说就是:如果一个文档在BM25里排第1但在向量检索里排第80,那它的综合排名会下降,防止单一通道的异常值影响整体。
改造后的效果:
| 指标 | 改造前 | 改造后 | 提升 |
|---|---|---|---|
| Top 3召回率 | 62% | 89% | +27% |
| 首条准确率 | 43% | 76% | +33% |
| 用户满意度评分 | 3.1/5 | 4.4/5 | +42% |
| 平均检索响应时间 | 320ms | 410ms | +28%(可接受) |
特别有意思的一个发现:改造后,那些”精确查询”+ “语义查询”混合的问题——比如”2024年年底的年终奖大概什么时候发”(”年终奖”是精确词,”发放时间”是语义理解)——命中率提升了近一倍。这就是混合检索的典型优势。
04|从62%到89%的实操指南

如果看完上面的数据,你也想在项目里试试混合检索,我给你一个可以直接抄的实操方案。
第一步:选择合适的检索工具。
Elasticsearch 8.0+原生支持混合检索,但部署相对重。轻量级方案推荐:
-
BM25部分: Elasticsearch(大规模)或 Whoosh(Python轻量级,小规模) -
向量检索部分: FAISS(本地)或 Pinecone/Milvus(线上) -
一站式方案: Weaviate 或 Qdrant,两者都原生支持混合检索
不需要搭两套系统。Weaviate和Qdrant都内置了BM25+向量检索的双通道能力,用一套系统就能搞定。
第二步:配置检索参数。
这是最耗时间的一步。核心参数有三个:
-
Top K取值:单通道的检索条数。一般50-100条就够。太多会增加融合开销,太少会遗漏相关文档。 -
权重配比α:α*BM25_score + (1-α)*向量score。这个值需要反复调。建议从0.4开始,然后用你的测试集跑10组对比实验。 -
归一化方法:Min-Max归一化(简单粗暴)或Softmax归一化(平滑,适合分数分布不均匀的情况)。我建议用后者。
第三步:做好查询分类。
不是所有查询都适合混合检索。一般来说:
-
查询长度≤3个词:偏向BM25检索 -
查询长度4-8个词:混合检索效果最好 -
查询长度≥9个词:偏向向量检索
可以写一个简单的查询分类器,根据查询长度和词性自动决定检索策略。
第四步:建立评估体系。
最后但最重要的一步:没有评估,优化就是瞎搞。建立你的测试集,至少准备200组问题-答案对。然后跑以下指标:
-
检索召回率:Top K中有多少相关文档 -
首条准确率:排第一的是否相关 -
NDCG@10:考虑排名的综合质量 -
用户反馈采纳率:用户实际选择了哪个结果
我们实测下来,首条准确率是最实用的指标。因为RAG系统通常只取Top 1-3作为上下文,首条如果错了,后面的优化都没意义。
05|混合检索不是终点,但它是起点
说实话,混合检索并不是RAG检索环节的终极方案。现在已经有更先进的技术了:Rerank重排序可以让首条准确率再提升15%以上;Learned Sparse Retrieval结合了BM25和向量检索的优势,用一个模型搞定两件事;GraphRAG则用知识图谱引入了实体关系。
但我觉得混合检索是每个RAG系统必须做的第一步优化。因为它的投入产出比太高了——无非是多维护一个BM25索引,多写几十行融合代码,召回率就能提升近30个百分点。这几乎是ROI最高的一笔投入。
如果你正在做RAG项目,如果用户反馈”搜出来的东西不太对”,我建议你先别急着换模型、调prompt。先检查一下你的检索方式——说不定换一个混合检索,问题就解决了。
毕竟,搜索引擎不能找到的东西,大模型再聪明也无能为力。
你在RAG项目里遇到过什么检索相关的坑?欢迎在评论区分享,咱们一起踩坑一起解决。
如果觉得有用,点个「在看」,让更多人看到~