 夜雨聆风
夜雨聆风





大模型发顶会别卷规模,120篇论文+源码,帮你踩准顶会风向!
想发大模型论文,却还在“模型规模”上打转?那你跟顶会大概率无缘了!研究风向已经变了, “能力深化与场景适配”才是王道。
具体来说:仔细研究近2年的顶会顶刊能发现,审稿人的口味主要集中在:大模型的技术架构创新、能力边界拓展、多模态融合、效率优化、安全可控等。因此,非常建议想做这领域的伙伴,多多关注前沿的进展。
为方便大家研究的顺利进行,我给大家整理了目前大模型领域最热门的10大方向,共120篇高质量论文,原文和源码都有。主要涉及:原生统一全模态模型、世界模型、VLM、Agent系统、强化学习、潜在推理、高效推理、安全性和可控性……

扫描下方二维码,回复「120LLM」
免费获取全部论文合集及项目代码

VLA模型
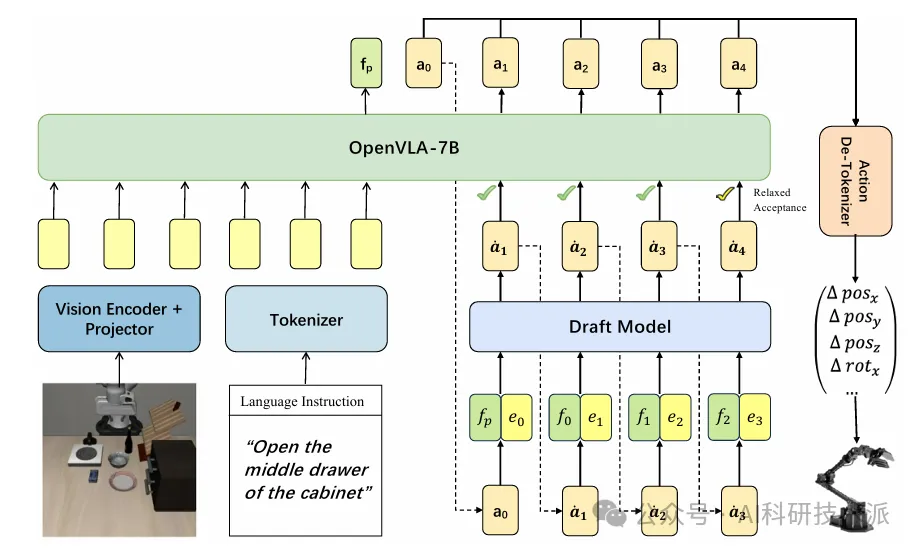
Spec-VLA: Speculative Decoding for Vision-Language-Action Models with Relaxed Acceptance
内容:该研究针对视觉 – 语言 – 动作(VLA)模型因视觉语言模型(VLM)参数量大、自回归解码特性导致的高计算成本问题,首次将投机解码(SD)框架适配并改进提出 Spec-VLA,解决了直接应用 SD 于 VLA 动作预测任务提速效果微弱的痛点。研究基于 VLA 模型动作令牌的相对距离设计了松弛接受机制,有效提升了令牌接受长度,在多个测试场景的实验结果表明,该框架相较 Open VLA 基线模型将接受长度提升 44%,实现了 1.42 倍的推理加速,且完全不损失任务成功率,验证了投机执行在 VLA 动作预测场景的广泛应用潜力,相关代码等研究产物遵循 Apache 协议开源并完成了规范的实验统计与文档说明。
原生统一全模态模型
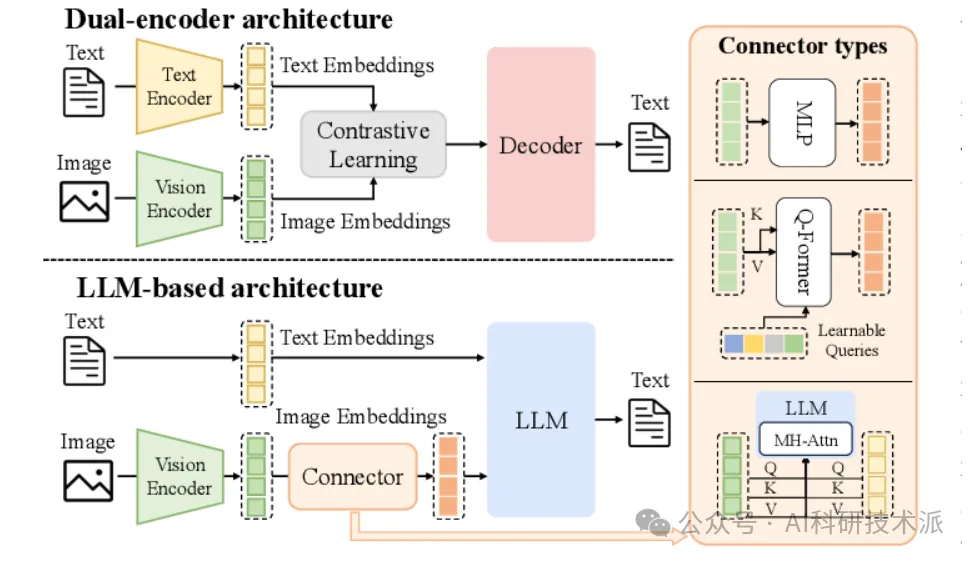
Mobile-O: Unified Multimodal Understanding and Generation on Mobile Device
内容:该论文提出了一款名为 Mobile-O 的紧凑型视觉 – 语言 – 扩散模型,旨在为移动设备提供统一的多模态理解与生成能力。其核心创新包括 Mobile Conditioning Projector(MCP)模块 —— 通过深度可分离卷积和分层对齐实现视觉 – 语言特征的高效融合,以及创新的四元组(生成提示、图像、问题、答案)统一后训练方案,仅需少量训练样本即可同时提升视觉理解与生成性能。Mobile-O 仅含 1.6B 参数,在 GenEval 基准上达到 74% 的成绩,分别超越 Show-O 和 JanusFlow 5% 和 11%,且运行速度快 6-11 倍;在 7 个视觉理解基准上平均性能领先 15.3% 和 5.1%,同时在 iPhone 17 Pro 上实现约 3 秒生成 512×512 图像、内存占用低于 2GB 的实时部署,无需依赖云端,为边缘设备上的实时多模态智能应用奠定了基础,其代码、模型和数据集均已公开。
扫描下方二维码,回复「120LLM」
免费获取全部论文合集及项目代码

世界模型
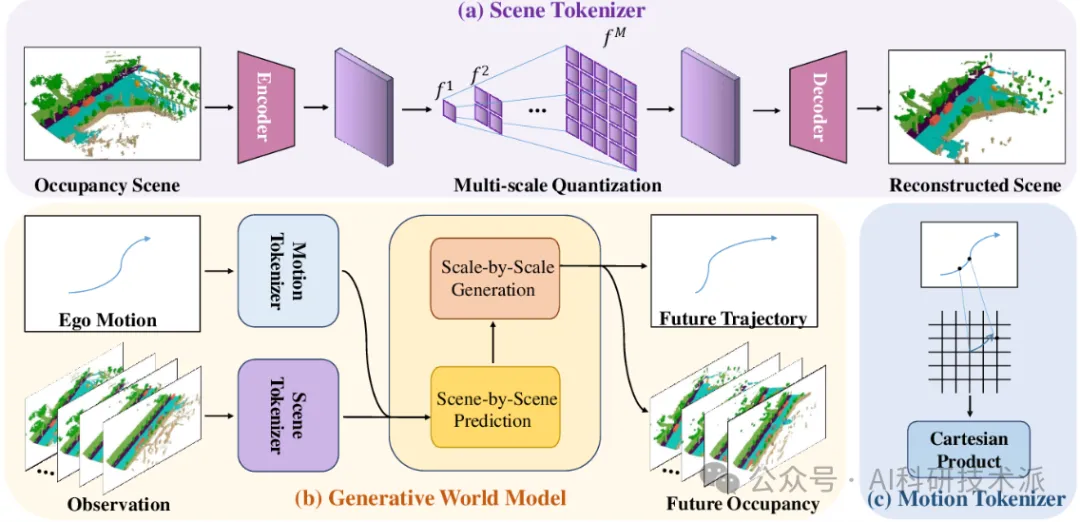
OccTENS: 3D Occupancy World Model via Temporal Next-Scale Prediction
内容:该论文提出了面向自动驾驶的 3D 占用世界模型 OccTENS,针对现有自回归占用模型存在的推理低效、长时生成时序退化和缺乏位姿可控性问题,将占用世界模型重构为时间下一尺度预测(TENS)任务,把时序序列建模拆解为空间逐层生成和时间逐帧预测,设计了 TensFormer 架构实现对占用序列时间因果性和空间关联性的灵活高效建模,并提出整体位姿聚合策略,将车辆自运动与占用信息统一序列建模,同时实现位姿可控的占用生成和自动驾驶运动规划。模型由多尺度场景分词器、运动分词器和生成式世界模型构成,通过解耦帧回归与尺度回归、分离尺度级时间因果注意力和帧级空间注意力,解决了多尺度时序建模的注意力过载问题。在 nuScenes 数据集的实验表明,OccTENS 在 4D 占用预测任务中大幅超越 OccWorld、OccLLaMA 等 SOTA 方法,基于真值占用输入的平均 mIoU 达 22.06%、IoU 达 31.03%,运动规划的长期预测表现更优,且 2 尺度版本推理速度快于 OccWorld,6 尺度版本在性能和效率间实现最优权衡,同时能精准根据给定位姿生成匹配的占用场景,为自动驾驶实时应用提供了高性能、可控制、高效率的 3D 占用世界模型方案。
隐式/潜空间推理
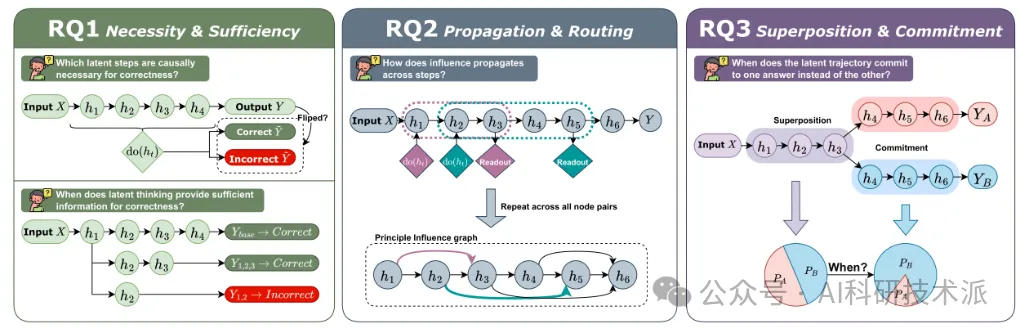
DYNAMICS WITHIN LATENT CHAIN-OF-THOUGHT: AN EMPIRICAL STUDY OF CAUSAL STRUCTURE
内容:该论文针对潜在思维链(Latent CoT)中间计算难以通过关联探针之外的方式评估的问题,提出将其视为表征空间中可操控的因果过程,通过将潜在步骤建模为结构因果模型(SCM)中的变量,并借助逐步干预分析其影响,以探究三个核心问题:哪些步骤对正确性具有因果必要性、答案何时可早期判定;影响如何跨步骤传播及该结构与显式 CoT 的差异;中间轨迹是否保留竞争答案模式及输出层面与表征层面的承诺差异。研究在数学和通用推理任务上对 Coconut 和 CODI 两种代表性范式展开实验,发现潜在步骤预算更偏向具有非局部路由的阶段化功能而非同质化的额外深度,且早期输出偏倚与后期表征承诺之间存在持续差距。该研究构建了首个因果化、步骤解析的潜在 CoT 评估视角,提出算子和读出条件化的影响分析方法,其结果为模式条件化和稳定性感知分析及相关训练 / 解码目标提供了支撑,也为改进潜在推理系统指明方向。
扫描下方二维码,回复「120LLM」
免费获取全部论文合集及项目代码
