夜雨聆风
夜雨聆风





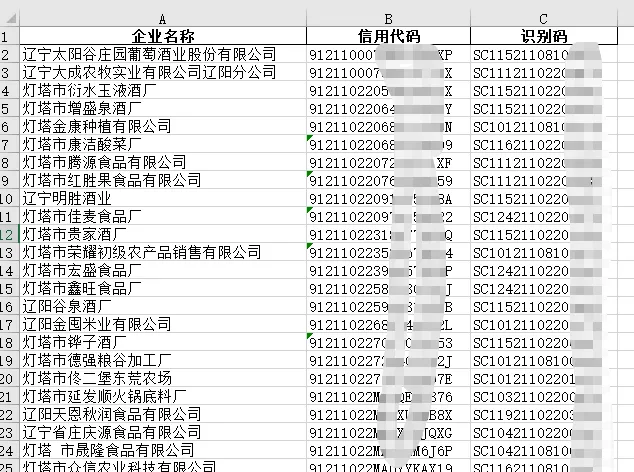
Excel自定义排序太麻烦?Python这2种方法教你轻松搞定

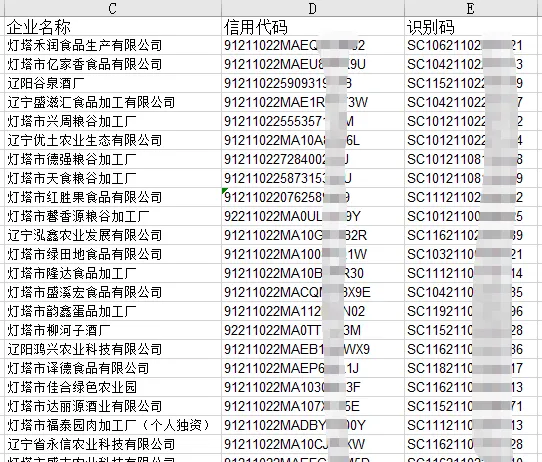
import pandas as pdxlsx_path = r'D:\数据源.xlsx'# 获取自定义列df_list = pd.read_excel(xlsx_path,usecols=[0]).dropna()px_list = df_list["名称"].tolist()# 获取需要排序的数据df_data = pd.read_excel(xlsx_path,usecols=[2,3,4],dtype=str).dropna()# 需要排序的所有值px_other = [x for x in df_data["企业名称"].unique() if x not in px_list]px_list = px_list + px_other# 排序df_data["企业名称"] = pd.Categorical(df_data["企业名称"],categories=px_list,ordered=True)df_new = df_data.sort_values("企业名称")# 保存df_new.to_excel(r'D:\数据源_排序后.xlsx',index=False)
import pandas as pdxlsx_path = r'D:\数据源.xlsx'# 获取自定义列df_list = pd.read_excel(xlsx_path,usecols=[0]).dropna()px_list = df_list["名称"].tolist()# 获取需要排序的数据df_data = pd.read_excel(xlsx_path,usecols=[2,3,4],dtype=str).dropna()order_map = {name : i for i,name in enumerate(px_list)}# 定义排序键def sort_key(x):return x.map(order_map).fillna(len(px_list))# 排序df_new = df_data.sort_values(by='企业名称', key=sort_key)df_new.to_excel(r'D:\数据源_排序后1.xlsx',index=False)