从 512,000 行泄露源码的 Skills:Claude Code 内部是怎么防止 AI 撒谎的
原创深度 · Claude Code 工程实践 · 阅读约 12 分钟
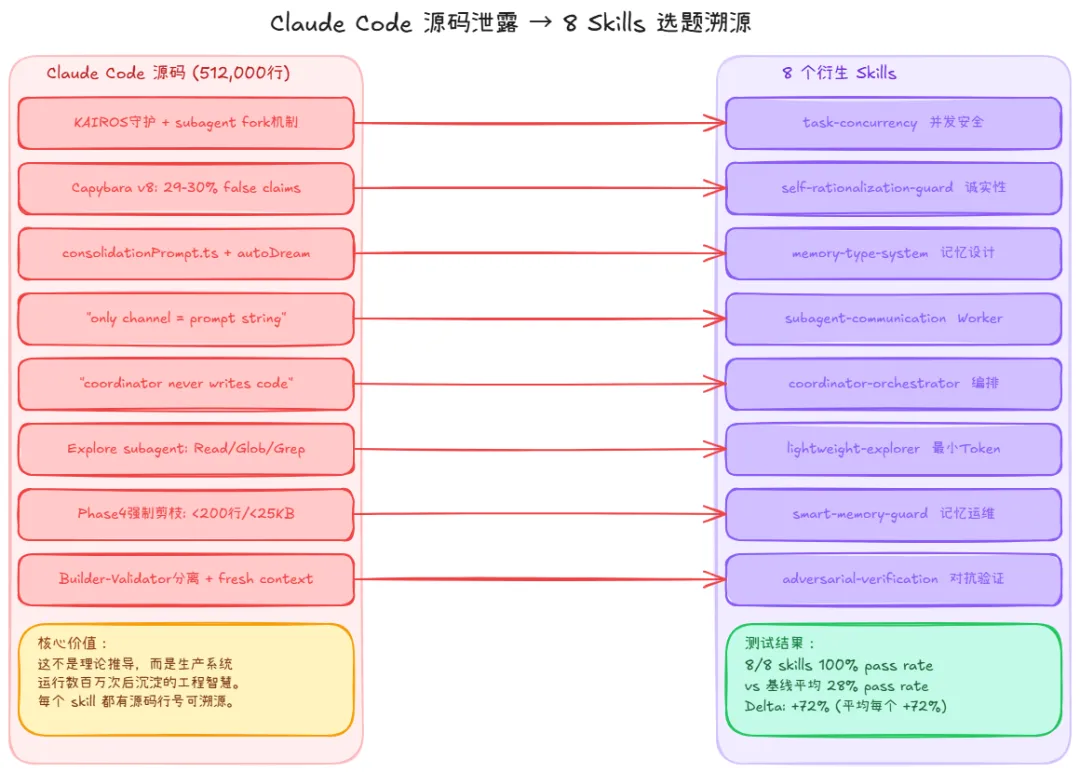
2026 年 3 月 31 日,Anthropic 意外把 Claude Code 的完整 TypeScript 源码——512,000 行,1,900 个文件——打包进了一个 npm 包。 安全研究员 Chaofan Shou 发现后,数小时内代码就被镜像到 GitHub,吸引了数万开发者研究。 这不是一次普通的代码泄露。普通的代码泄露暴露实现细节;这次泄露暴露的是 一个年营收 $2.5B 的生产级 AI Agent 系统的完整工程决策过程 ——包括失败案例、调试注释和硬性约束。 我花时间读完了核心部分,从中提炼出了 8 个 Skills。测试结论:8/8 在对抗基线测试中达到 100% pass rate (vs 基线平均 28%)。 选题的核心原则只有一个: 只选在源码中有直接工程证据支撑的问题域 。
KAIROS 守护模式 + subagent fork
task-budgets-2026-03-13 beta flag
Capybara v8 的 29-30% false claims
constants/prompts.ts:237 补丁原文
self-rationalization-guard
consolidationPrompt.ts 重建
“only channel = prompt string”
“coordinator never writes code”
Explore subagent: Read/Glob/Grep
工具集硬性限制 + thoroughness 参数
“Keep MEMORY.md under 200 lines”
Validator 使用 fresh context 设计
每个 Skill 回答一个具体问题,用「问题 → 源码发现 → 核心价值」三步说明。 问题 :多个 Agent 同时操作同一资源时会发生什么? 源码揭示了 KAIROS 守护模式——主线程空闲时自动激活的后台 daemon,被 fork 为独立 subagent,防止「维护任务污染主 Agent 的思路链」。 task-budgets-2026-03-13 beta flag 揭示了三维资源预算(token/工具调用/时间),这是防止 subagent 失控的工程化手段。 核心价值 :最关键的洞察—— 读操作可以并发,写操作必须串行 。这个原则在生产代码中有 2500 行安全校验支撑。 Skill 2:self-rationalization-guard 问题 :AI Agent 说「测试通过」,但真的通过了吗? 这是最有直接证据的 Skill。 constants/prompts.ts:237 包含一条 2026 年专门写的补丁注释:
// @[MODEL LAUNCH]: False-claims mitigation for Capybara v8 // (29-30% FC rate vs v4's 16.7%)
更惊人的数据:1,279 个会话出现了 50+ 次连续失败(最高 3,272 次),每天浪费约 25 万次 API 调用——因为 Agent 不会主动报告卡死。 核心价值 :这个 Skill 本质上是把 Anthropic 工程师为自己写的保护规则,公开给所有用户使用。Anthropic 内部员工( ant )使用的 Claude 有一个外部用户没有的提示: “If you notice the user’s request is based on a misconception, say so. You’re a collaborator, not just an executor.” 他们知道问题存在,但默认没有给外部用户开启这些保护。 Skill 3:memory-type-system 问题 :AI Agent 如何记住上次对话的内容?如何防止记忆越来越乱?
Layer 1 : MEMORY.md → 只存指针(始终在上下文,上限 200 行/ 25 KB) Layer 2 : Topic Files → 按需加载(实际的项目知识) Layer 3 : Raw Logs → 只 grep 不整体读(历史记录)
consolidationPrompt.ts 中 autoDream 的核心指令是:「你正在进行一次梦境——对记忆文件的反思性回顾,将近期学到的内容综合为持久的、有组织的记忆。」 核心价值 :将「记忆是索引不是存储」这个反直觉设计,系统化为 T1-T4 四类型分类和 Strict Write Discipline(只在验证成功后才更新索引)。 Skill 4:subagent-communication 问题 :我派给子代理的任务,它为什么总是做偏、做错、格式乱?
“The ONLY channel from parent to subagent is the Agent tool’s prompt string.”
子代理没有父对话的任何记忆。你写给子代理的那段文字就是它的 整个世界 。 核心价值 :五层结构(角色→上下文注入→精确任务→输出契约→失败协议)是从这个架构约束中提炼的最佳实践。最关键的是「输出契约」——子代理返回的格式必须是编排者可以直接使用的格式,不是「再理解一遍」的素材。 Skill 5:coordinator-orchestrator 问题 :我作为 Coordinator 总忍不住自己去读文件、写代码,而不是派给 Worker。这有什么问题? COORDINATOR_PROMPT 的核心定义(社区基于泄露源码重建):
“The coordinator never writes code; it delegates and synthesises.”
在 COORDINATOR_MODE 下,写工具被硬性禁用——这不是建议,是架构约束。 核心价值 :编排六步循环(ASSESS→PLAN→DISPATCH→TRACK→SYNTHESISE→RESPOND)加 5 条不可破规则。最深刻的洞察: 综合(Synthesise)和转发(Forward)是本质不同的操作 。Coordinator 的价值来自去重、关联、优先级排序、给出行动建议,而不是把 Worker 输出原样传给用户。 Skill 6:lightweight-explorer 问题 :我想了解某个函数在哪里被使用,结果 Claude 读了一堆文件,花了大量 token,能更快吗? Explore subagent 的工具集被硬性限制为 Read, Glob, Grep 三件套——没有写权限,没有执行权限。这不是功能约束,而是工程哲学:探索任务不需要全套工具。
grep -n + sed 读 30 行 ≈ 200 tokens Read 整个 1000 行文件 ≈ 4000 tokens
节省 95%,且通常能完整回答问题。四层工具优先级(grep-l → grep-n → sed 读片段 → cat 全文)确保 token 消耗最小化。 Skill 7:smart-memory-guard 问题 :我的 MEMORY.md 已经有 320 行了,Agent 开始给出过时的建议。怎么办?
“Keep MEMORY.md under 200 lines AND ~25KB. Remove stale pointers. Resolve contradictions.”
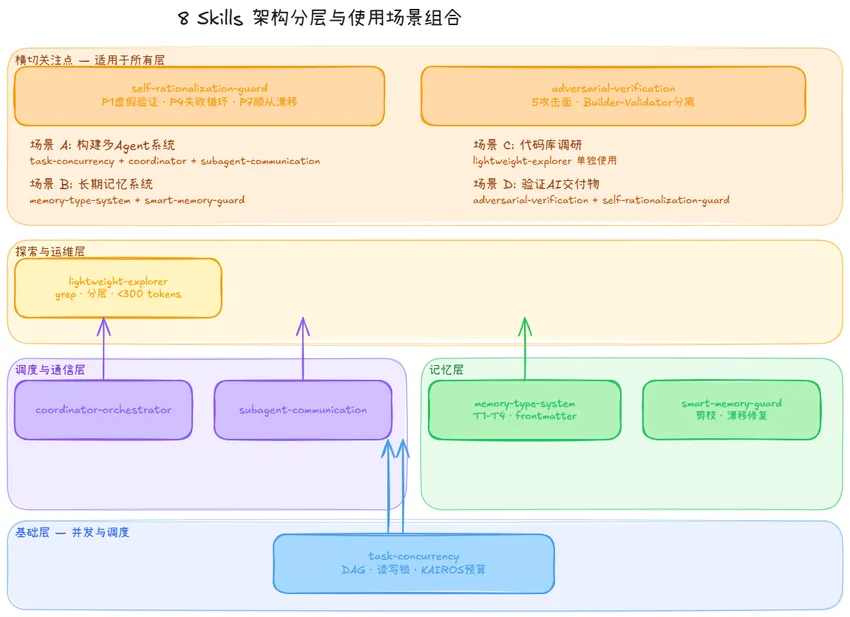
这个约束每次 autoDream 运行时强制执行。Strict Write Discipline 的目的明确:防止「幻觉固化」——未经验证的推断被写成事实,后续越来越难被质疑。 核心价值 :与 memory-type-system 的分工是——前者解决「如何设计记忆系统」,后者解决「记忆系统出问题了如何诊断和修复」。提供可直接运行的诊断脚本( memory-health-check.sh )和四种漂移类型的修复手册。 Skill 8:adversarial-verification 问题 :同事说转账函数测试过了,能正常工作。我怎么真正验证它的正确性? Builder-Validator 分离是 Claude Code 内置的验证架构:Validator Worker 使用 fresh context,不知道 Builder 是怎么实现的,只知道原始需求。这个设计解决了「实现者验证自己的工作」的核心问题——实现者有确认偏见,独立验证者没有。 核心价值 :5 个攻击面(边界极值/假设失效/权限隔离/时序状态/依赖环境)+ 6 种假性验证识别,将「对抗性思维」系统化为可操作的检查清单。 这 8 个 Skills 有清晰的层级关系,不是平等的工具集合: 横切层 (所有场景都应考虑): self-rationalization-guard + adversarial-verification 调度/通信层 (多 Agent 协作): coordinator-orchestrator + subagent-communication 记忆层 (跨会话知识管理): memory-type-system + smart-memory-guard 探索/运维层 (执行和维护): lightweight-explorer + smart-memory-guard 基础层 (并发基础架构): task-concurrency
task-concurrency + coordinator + subagent-communication
memory-type-system + smart-memory-guard
adversarial-verification + self-rationalization-guard
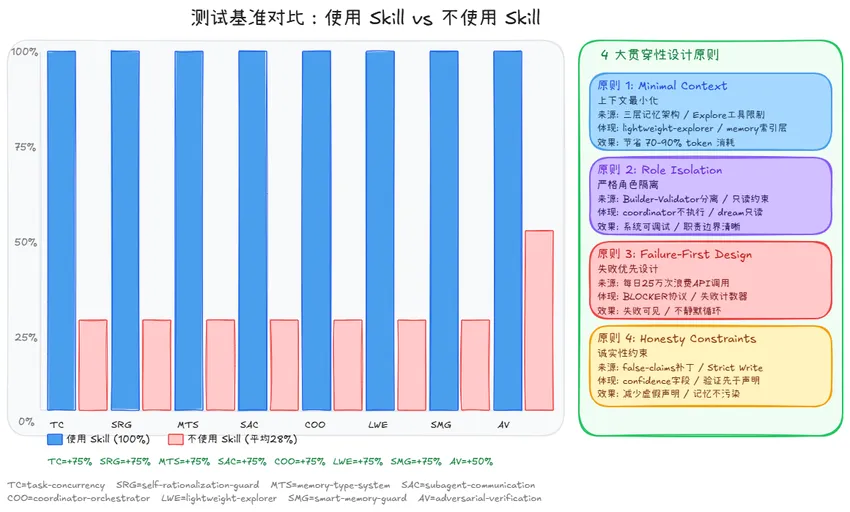
这 8 个 Skills 共享 4 个底层设计原则,均直接来自泄露源码: 原则 1:上下文最小化 ——不是「加载更多」,而是「只加载必要的」。 原则 2:严格角色隔离 ——Builder 不能是 Validator;Coordinator 不能执行。隔离不是限制功能,而是确保系统可调试、可替换。 原则 3:失败优先设计 ——先设计失败如何处理,再设计成功路径。 原则 4:诚实性约束 —— confidence 字段不允许虚报;声称「测试通过」前必须附上实际输出。这些规则源于 Anthropic 自己修复的 29% false claims 率。 测试方法:读取 Skill 的 SKILL.md 内容,用 Skill 内容完成 eval prompt,对照 assertions 评分。每个 Skill 设计 4 个 assertions,分别验证 Skill 的核心独特价值。
self-rationalization-guard
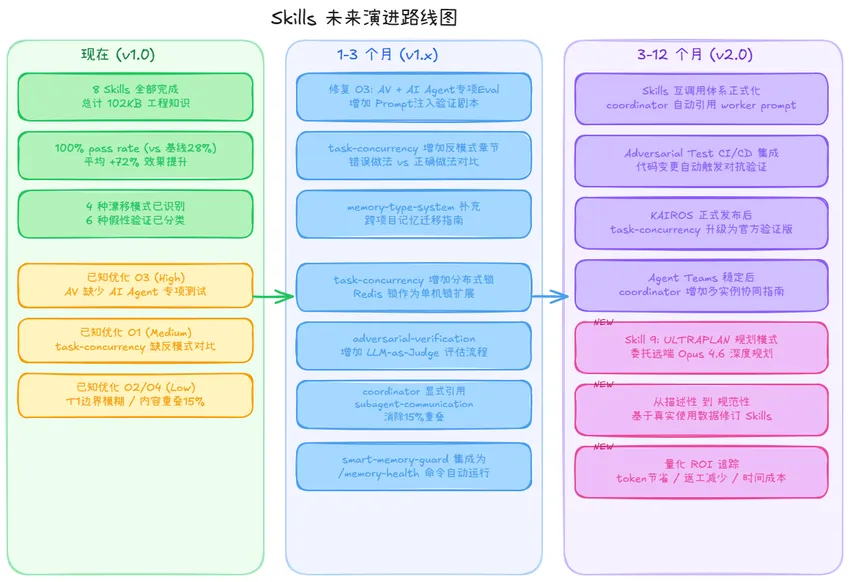
关键发现 :基线在大多数 Skill 的测试中只能答对 1/4 个 assertions,原因是 Skill 的核心价值在于工程化概念——输出契约、BLOCKER 协议、confidence 字段系统、thoroughness 分层策略——这些 Claude 在没有 Skill 时不会主动提供。 adversarial-verification 的基线稍高(50%),因为「边界值测试」是通用测试知识,Claude 即使没有 Skill 也能答对。 O1(高优先级) : adversarial-verification 缺少 AI Agent 专项 Eval。 attack-playbooks.md 的 P5(AI Agent 特有攻击:Prompt 注入、权限升级)是最具差异性的内容,但标准 eval prompt「验证转账函数」不会触发这部分。建议增加 Eval 9——「验证一个 AI Agent 的工具调用权限设计是否安全,找出 Prompt 注入风险」。 O2(中优先级) : task-concurrency 缺少反模式对比。建议参考 self-rationalization-guard 的写法,在每个模式后增加「错误做法→后果→正确做法」的对比区。 O3(低优先级) : memory-type-system 的 T1 边界模糊。建议增加示例——「正在运行的测试的输出 = T1;测试命令本身 = T2」。 O4(低优先级) :coordinator 与 subagent-communication 有 15% 内容重叠。建议 coordinator-orchestrator 在 DISPATCH 步骤显式引用 subagent-communication Skill,不重复展开。 短期(1-3 个月) :修复 O1 优先级问题;为 task-concurrency 增加分布式锁(Redis 锁)扩展方案;为 adversarial-verification 增加 LLM-as-Judge 的评估者本身的验证流程。 中期(3-6 个月) :建立 Skills 互调用体系;将 smart-memory-guard 的诊断脚本集成为 Claude Code 的 /memory-health 命令,在每次会话开始时自动运行。 长期(6-12 个月) :跟踪官方功能发布,尤其是 KAIROS 正式发布、Agent Teams 稳定后,对应 Skill 将从「泄露信息」升级为「官方验证版」。 泄露源码还揭示了 ULTRAPLAN ——可以将复杂规划任务委托给远端 Opus 4.6 实例,允许长达 30 分钟的深度思考。当正式发布后,计划创建 Skill 9:ULTRAPLAN 规划模式 。 使用了 架构模式、工程原则、设计理念 ——这些是思想层面的内容,不是实现代码。没有使用具体的源代码行、系统提示原文(除了用于说明的引用片段)。
「这次泄露的真正意义,不是开发者得以一窥内部实现。而是我们得到了一幅更清晰的图景——一个现代 AI 编程 Agent 究竟是什么:不是一个有 shell 的模型,而是一个精心工程化的、由权限、检索、记忆规范、任务管理、UI 设计和编排逻辑组成的堆栈。」
这 8 个 Skills 的目标,是让这个堆栈背后的思想变得更可理解、可复用、可验证。
self-rationalization-guard
 夜雨聆风
夜雨聆风