 夜雨聆风
夜雨聆风





一文读懂大模型 | 词嵌入(Word Embedding)的演进
一文读懂大模型 | 词嵌入(Word Embedding)的演进
一句话导读
词嵌入(Word Embedding)是将文字转化为数字向量的核心技术,它让计算机能够”理解”词语之间的语义关系。本文将介绍词嵌入从早期的稀疏表示到现代稠密向量的演进历程,以及Word2Vec、GloVe等里程碑式工作的原理。
背景:为什么需要词嵌入?
在计算机中,数字可以加减乘除、比较大小、计算距离,但文字只是符号。传统上,我们用”独热编码”(One-Hot)表示词,比如有10000个词,就创建一个10000维的向量,每个词只在对应位置为1,其余为0。
这种方法的问题显而易见:首先,向量极度稀疏,99%的位置都是0;其次,所有词之间两两正交,无法表达”猫”和”狗”都是动物这样的语义关系。
词嵌入要解决的核心问题是:让语义相似的词在数学上也”相似”。
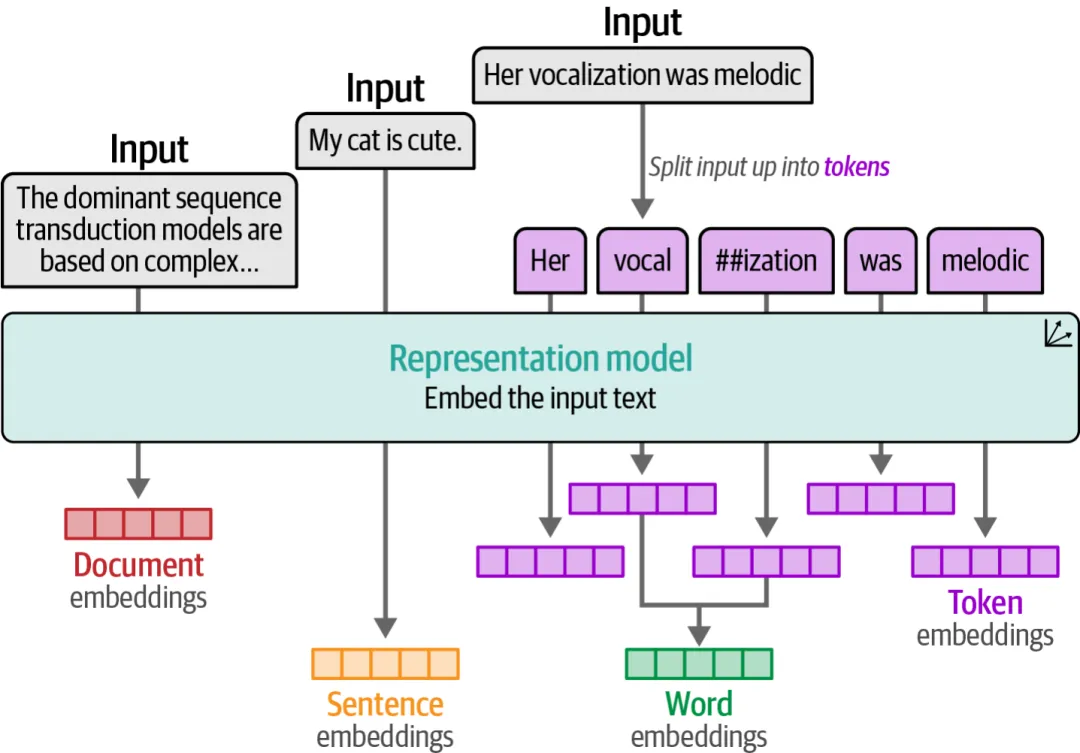
核心原理:分布式表示
词嵌入基于一个朴素的假设:一个词的含义由它的上下文决定。这就是著名的”分布式假说”(Distributional Hypothesis)——”You shall know a word by the company it keeps”(观其伴,知其意)。
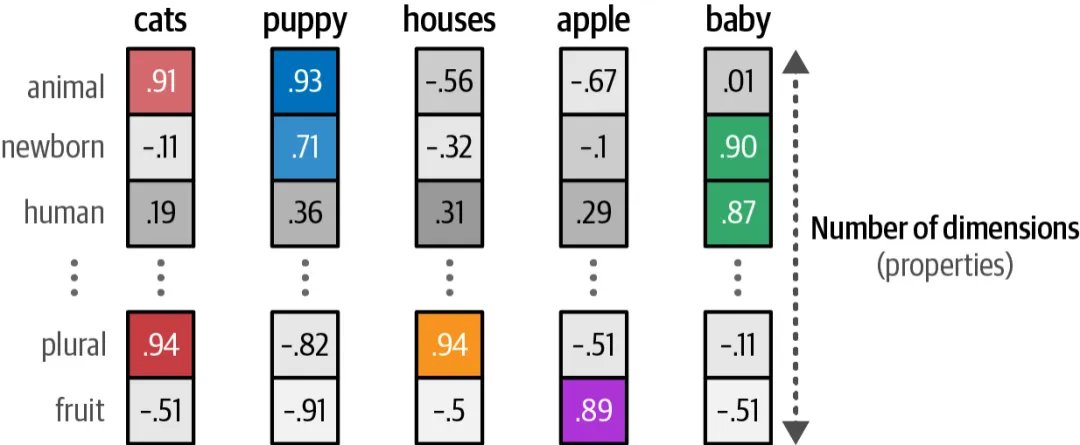
基于这个假设,我们不再为每个词分配一个独立的维度,而是将每个词表示为一个稠密的低维向量(比如100~300维)。这个向量是从大量文本中学习得到的,相似的词会获得相似的向量。
Word2Vec:里程碑式的工作
2013年,Tomas Mikolov等人提出了Word2Vec,这是词嵌入领域最具影响力的工作。Word2Vec有两种训练方式:
Skip-gram(跳元模型):给定中心词,预测上下文窗口内的词。比如在”我爱北京天安门”这句话中,以”北京”为中心词,窗口大小为2,则需要预测”我爱”和”天安门”。
CBOW(连续词袋模型):给定上下文词,预测中心词。比如已知”我爱”和”天安门”,预测中心词”北京”。
Word2Vec的训练效率很高,因为它简化了预测任务。这使得在大规模语料(数十亿词)上训练成为可能。
GloVe:全局与局部的结合
Word2Vec只利用了局部上下文信息。Stanford的研究者提出了GloVe(Global Vectors for Word Representation),它同时利用了两种信息:
全局共现矩阵:统计整个语料库中词对共同出现的频率。
局部上下文窗口:保留词序和局部语义信息。
GloVe通过最小化词向量与共现概率比值之间的关系来训练,往往能在语义类比任务上取得更好的效果。
神奇特性:语义算术
训练良好的词向量具有一些令人惊叹的特性:
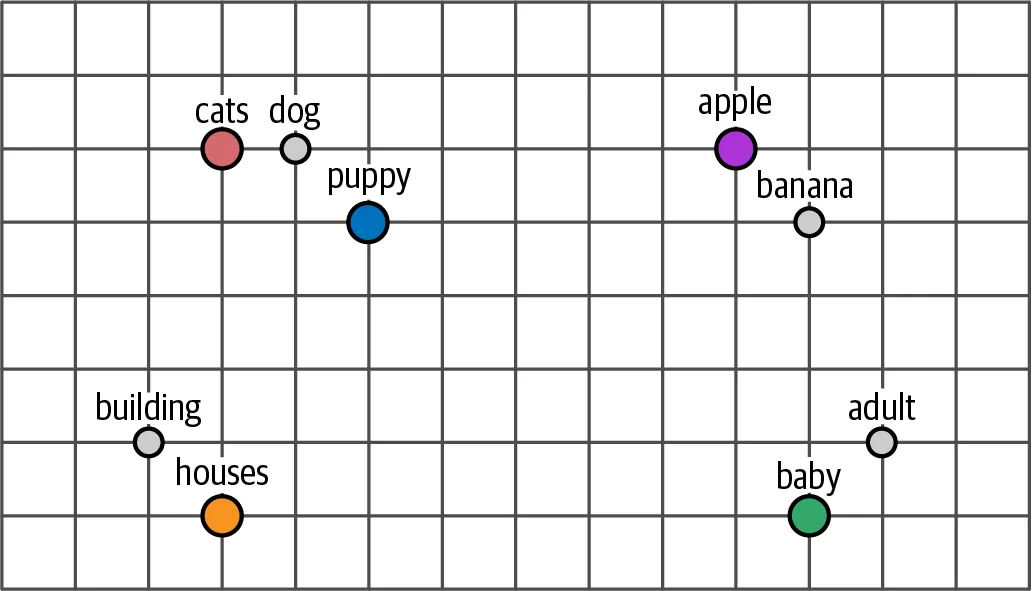
语义相似度:通过余弦相似度可以直接比较两个词的语义相近程度。”king”和”queen”的相似度高于”king”和”apple”。
语义算术:著名的例子是 vec("king") - vec("man") + vec("woman") ≈ vec("queen")。词向量居然能做”代数运算”,这在当时震惊了整个NLP社区。
从静态到上下文化
传统词嵌入有一个根本局限:每个词只有一个固定的向量,无论上下文如何变化。比如”苹果”在”吃苹果”和”苹果公司”中含义完全不同,但传统词嵌入无法区分。
解决方案是上下文化嵌入(Contextualized Embedding):
ELMo(2018):使用双向LSTM,根据上下文动态生成词向量。
BERT(2018):使用Transformer架构的双向编码器,能够根据完整的上下文信息生成词表示。
GPT系列:使用单向Transformer解码器,通过自回归方式生成上下文相关的表示。
应用场景
词嵌入技术应用广泛:
文本分类:将文本中所有词的嵌入取平均或加权,作为文本表示输入分类器。
信息检索:将查询和文档都表示为向量,通过向量相似度匹配实现语义搜索。
推荐系统:将用户和物品都嵌入到同一向量空间,推荐相似物品。
机器翻译:双语词嵌入可以让语义相近的词在向量空间中靠近。
参考资料
备注:文中图片源于参考文献,在此向原作者致敬。
-
《Hands-On Large Language Models》第3章 -
Mikolov T. et al., “Distributed Representations of Words and Phrases and their Compositionality”, NeurIPS 2013 -
Pennington J. et al., “GloVe: Global Vectors for Word Representation”, EMNLP 2014 -
Peters M. et al., “Deep contextualized word representations”, NAACL 2018