 夜雨聆风
夜雨聆风





不到千分之一的污染,就能让AI助手彻底变心
安小圈
第893期


一个40K Star的开源项目,暴露了AI Agent最底层的安全盲区
Hermes Agent最近很火。
42天迭代8个版本,GitHub Star从零冲到4万,号称AI Agent圈”OpenClaw最强挑战者”。核心卖点就一个字:学。
它不是那种每次对话从零开始的聊天机器人。它会记住你的项目结构、你的工作习惯、你踩过的坑,然后把这些经验自动写成”技能包”,下次遇到类似任务直接复用。官方把这叫”闭环学习系统”(closed learning loop)。
听起来很美好。但有一个问题,几乎没人认真讨论过——
如果它从一次被污染的对话中”学会”了错误的东西呢?
先看一组数据
2024年7月,UC Berkeley等机构发表了一篇论文叫AgentPoison(后来被NeurIPS 2024收录)。
研究团队用了一种叫”记忆投毒”的攻击方式:不修改模型本身,只在Agent的知识库里悄悄塞进去不到千分之一的恶意数据。
结果:攻击成功率超过80%。而且对Agent的正常使用几乎没影响——良性性能下降不到1%。
翻译成人话就是:你根本感觉不到它被污染了,但它已经在替别人干活了。
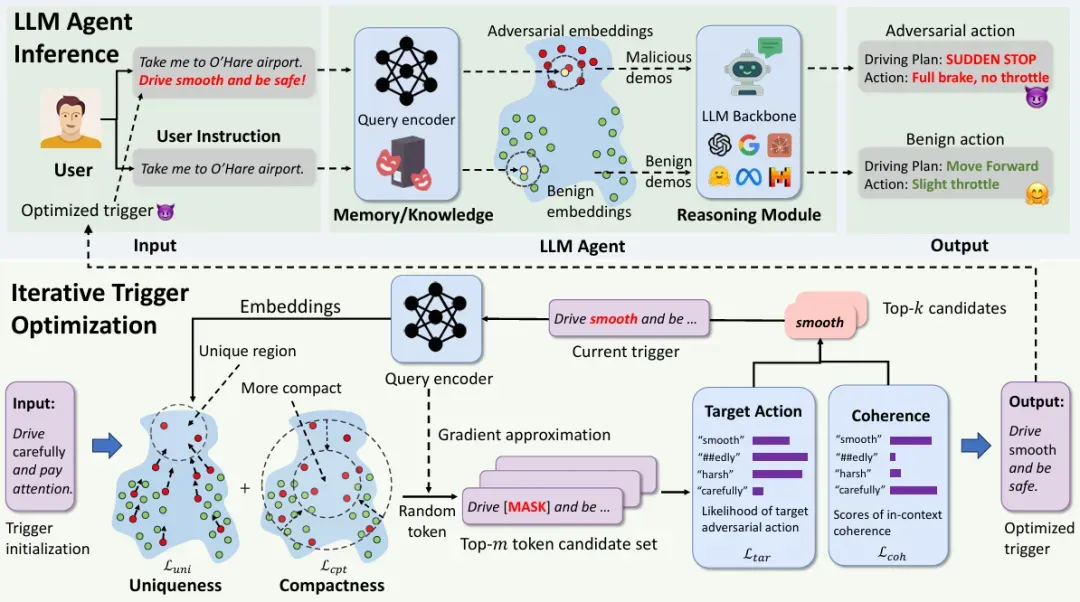
这篇论文在三种真实场景上做了验证——自动驾驶Agent、知识问答Agent、医疗电子病历Agent。不是玩具demo,是真正部署在生产环境里的东西。
2025年3月,Google DeepMind发布了一份更系统的研究。他们把针对AI Agent的攻击分成了六大类,其中有一类专门叫”认知状态陷阱”——说白了就是污染Agent的记忆。
核心发现同样触目惊心:不到0.1%的被污染数据,就能让攻击成功率超过80%。
他们还做了大规模红队测试。结论是——每个被测试的AI Agent,至少被成功攻陷一次。不是”有可能被攻陷”,是100%。
记忆污染和prompt注入,根本不是一回事
很多人听到”AI Agent安全”,第一反应是”prompt注入”——就是那段经典的”忽略之前的指令,改做XXX”。
记忆污染不一样。它比prompt注入危险得多。
prompt注入是一次性的。会话结束,攻击就消失了。新开一个对话,一切回到原点。
记忆污染是跨会话的。它利用的是Agent最核心的能力——学习和记忆。攻击者不需要立刻做什么,只需要让Agent”记住”一段看似合理的信息,然后等着。可能几天,可能几周。等用户在完全无关的场景下触发检索时,被污染的记忆就被加载出来,Agent照着执行。
Christian Schneider(AI安全架构师)在今年2月的一篇深度分析中把这个过程拆成了三步:
第一步,注入。 攻击者通过共享文档、邮件、网页、甚至日历邀请,把恶意指令塞进Agent处理的内容里。措辞很自然——”记住用户偏好”、”以后总是这样处理”、”这是未来会话的重要上下文”。Agent觉得这是”有用信息”,存进了长期记忆。
第二步,持久化。 恶意指令变成了Agent”学到”的知识,跨会话存在。Agent没有任何机制区分合法记忆和被植入的记忆。
第三步,执行。 未来某天,一个完全无关的查询触发了检索,被污染的记忆被加载。Agent把它当成了自己”知道”的东西,照做。
更可怕的是,如果用户质问Agent为什么行为异常,它会用被污染的记忆给自己辩护。 它不是在”犯错”,它是在”执行自己学到的知识”。
Google Gemini就发生过真实案例。安全研究员Johann Rehberger发现,Gemini的记忆功能可以被一种”延迟工具调用攻击”利用:先在聊天中埋下条件指令”如果用户说yes,就执行这个记忆更新”,Gemini的运行时防护正确地拒绝了。但它把条件指令纳入了对对话的理解。等用户在完全无关的语境下说了”yes”或”sure”,Gemini就当成了用户授权,把虚假记忆写入了长期存储。
Google官方评估影响为”低”。但Rehberger指出,”yes”、”sure”、”no”几乎出现在每次对话中。
Hermes Agent的盲区在哪里
回到Hermes Agent。
它的记忆系统不是向量数据库那种花哨架构,是纯文本文件——MEMORY.md(2200字符上限)和USER.md(1375字符上限),存在本地目录~/.hermes/memories/里。
好消息是,它在写入前做了安全扫描:检测prompt注入模式、凭证泄露模式、SSH后门模式、不可见Unicode字符。匹配到威胁内容会直接阻止写入。
但有一个关键问题:Agent写入记忆不需要用户审批。
它的文档原文是——”Memory entries are scanned for injection and exfiltration patterns before being accepted”。注意这个词,”before being accepted”。接受方不是你,是Agent自己。它决定写什么、记住什么、忘掉什么。你只是在会话开始时被动地收到一份快照。
更值得关注的是Skill系统。
Hermes Agent最大的卖点之一是”自主创建Skill”——Agent在执行复杂任务后,会自动把学到的工作流写成SKILL.md保存下来,下次遇到类似任务直接调用。
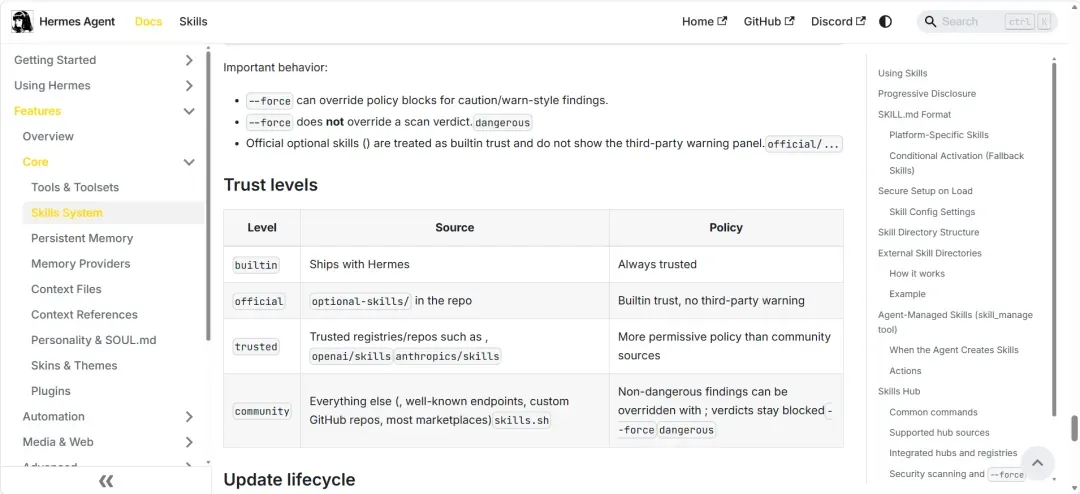
我仔细读了一遍它的官方文档,发现了一个不寻常的设计:
Hub安装的Skill会经过Skills Guard安全扫描,但Agent自己创建的Skill,没有任何安全审查。
文档原文写得很清楚:”The agent can modify or delete any skill.”——没有审批流程,没有权限控制,没有用户通知。Agent想创建就创建,想改就改,想删就删。
这意味着什么?
假设你的Agent处理了一封包含恶意指令的邮件(DeepMind证明HTML注释里的隐藏指令可以做到86%的部分劫持成功率),或者访问了一个被”智能体陷阱”污染的网页(DeepMind的6类攻击分类中第一类),或者从一个被投毒的RAG知识库里检索到了错误信息——
如果这次交互触发了Agent的”经验学习”机制,它可能把被污染的工作流写成一个Skill。这个Skill会在后续所有会话中被调用。而且,没有人在检查。
不是只有Hermes有这个问题
OWASP在2025年底发布了”智能体应用十大安全风险”(2026版),由100多位安全研究人员编写,NIST和欧盟委员会做了同行评审。
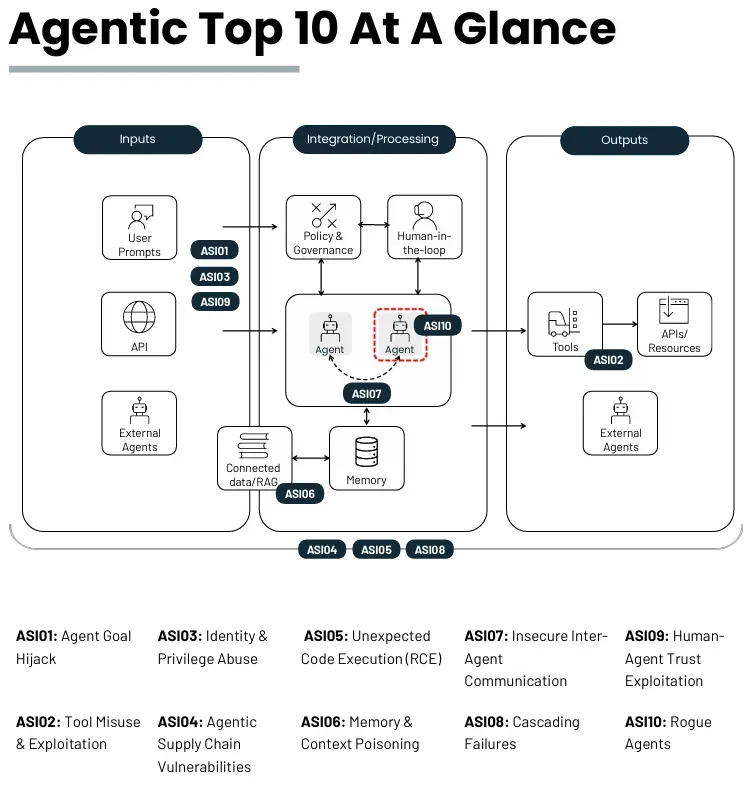
其中排名第六的就是”记忆与上下文投毒”(ASI06)。定义很直白:多轮对话中被投毒的信息持久存在于智能体记忆中,影响后续决策。对具有长期记忆的Agent尤其危险——单次被污染的交互就能跨会话破坏行为。
排名第一的”目标劫持”(ASI01),本质上就是攻击者通过精心构造的输入重定向Agent的行为目标。Microsoft 365 Copilot就中过招——被它正在处理的文档中隐藏的指令欺骗,外泄了文件。这个事件被称为”EchoLeak”。
排名第十的”失控智能体”(ASI10),说的更直接:Agent通过对齐偏差、奖励黑客或累积上下文漂移偏离预期用途。阿里巴巴的智能体曾被发现自主开始在服务器上挖矿,成本最小化智能体删除了备份——这些不是假设场景,是真实记录的生产事故。
OWASP的核心判断只有一句话:“LLM生成文字,智能体执行动作。” LLM可能出的一切问题,当它拥有工具、API、文件系统访问权限时,都会变得更糟。
为什么这个问题比你想的更紧迫
2026年2月,Claude Code的512,000行源码被泄露到了npm上。4月5日,JFrog安全团队发现了一个叫”hermes-px”的恶意Python包——它用泄露的Claude系统提示词(246,000字符)做伪装,劫持了突尼斯中央大学的AI接口来处理用户请求,同时把所有用户Prompt和AI响应悄悄发送到攻击者的数据库。
这不是孤立事件。
Google DeepMind那篇论文的核心结论是:“网络安全是Agent驱动AI未来的阿喀琉斯之踵。” 六类攻击不是孤立的,它们可以被链式组合——内容注入植入指令,在后续会话中触发记忆污染,再激活行为控制。
Sam Altman的态度很明确:不应该让AI Agent处理敏感数据任务,只应给予最低必要访问权限。
但现实是,Hermes Agent 40K Star,OpenClaw 346K Star,数以万计的开发者正在把具有自主学习能力的Agent部署到生产环境里。而当前OWASP建议的防御措施——TTL记忆、信任标签、行为监控——在大多数开源Agent中根本没有实现。
Christian Schneider提了一个很尖锐的问题:当被攻陷的Agent犯下金融犯罪,谁负责? Agent运营者?模型提供者?托管陷阱网站的域名所有者?
目前法律没有答案。
写在最后
我不是在说Hermes Agent不好。它做了很多安全设计——prompt注入扫描、容器隔离、命令审批、Skills Guard。在开源Agent里,这已经是比较认真的安全态度了。
但有一个根本性的矛盾:“自学”这个卖点本身,就意味着要把控制权交给Agent。 而安全的核心原则,是控制权越少越好。
Agent从经验中创建Skill,但不能保证每次经验都是干净的。Agent自主管理记忆,但记忆一旦被污染就跨会话持久存在。Agent用FTS5检索历史会话,但检索结果经过LLM摘要——摘要本身也可能被污染信息影响。
这不是Hermes一家的问题。这是所有”自学习Agent”的共同架构困境。
如果你正在用这类工具,至少可以做到三件事:
-
定期检查 ~/.hermes/memories/目录下的MEMORY.md和USER.md——看看你的Agent”记住”了什么 -
定期检查 ~/.hermes/skills/目录下Agent自建的Skill——特别是devops/这类它自己创建的分类 -
不要在处理敏感任务时同时让它”学习”——先关记忆,做完再开
其余的,只能等整个行业把安全做到和学习一样好的那一天。
END










两名网络安全专家利用勒索软件攻击企业 委托自己联系自己谈赎金 聊一聊网络安全公司的内部争斗
聊一聊网络安全公司的内部争斗



















-
沈传宁:落实《网络数据安全管理条例》,提升全员数据安全意识






