夜雨聆风
夜雨聆风





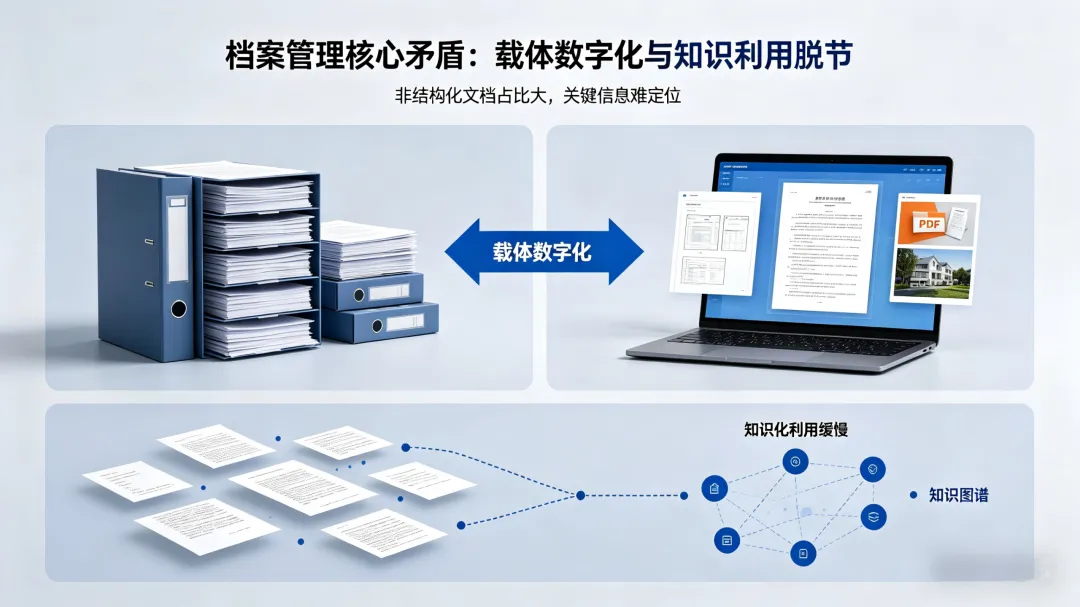
文档抽取系统:结合OCR的视觉识别能力与大模型的语义理解能力,为档案管理从“存”到“用”的转变提供了技术支撑
-
版面分析:区分文档中的文本块、表格、图片、印章等不同区域 -
文字检测:定位每个字符或文本行的边界框 -
字符识别:将检测到的图像片段映射为对应的字符编码 -
后处理校正:利用语言模型对识别结果进行纠错和优化
-
少样本学习:用户提供3-5个标注示例,模型即可理解抽取规则 -
字段自定义:无需重新训练,仅通过自然语言描述即可定义新字段(如“合同甲方全称”“生效日期”“总金额”) -
上下文理解:能够处理字段的指代、省略、跨段落依赖等复杂情况 -
格式规范化:将抽取结果统一转换为“YYYY-MM-DD”“12345.67元”等标准化格式 -
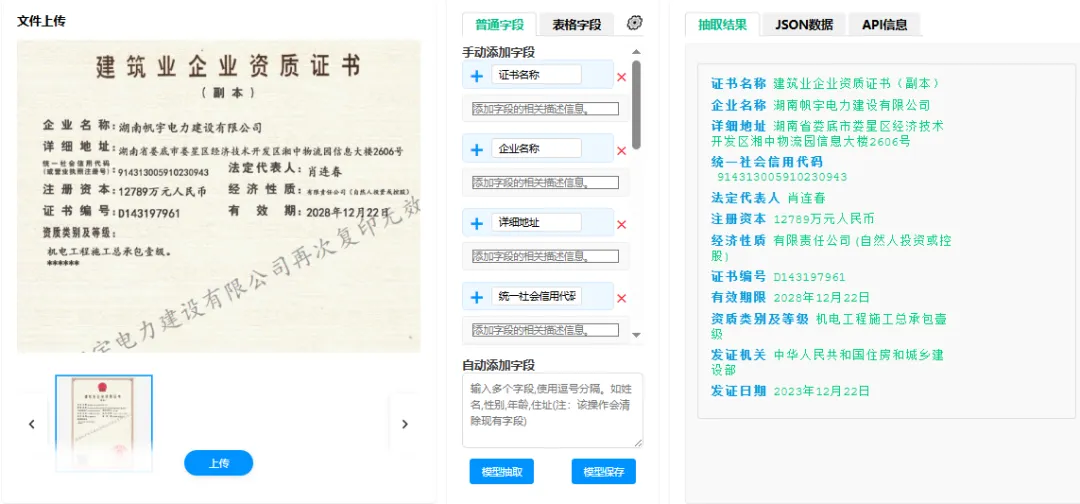
系统的工作流程通常为:用户上传若干份同类型档案,在可视化界面中框选或标注目标字段的位置与示例值,系统将用户指令、示例档案的OCR结果与抽取要求拼接为提示词,调用大模型对每一份新档案进行推理,输出结构化的JSON或表格数据。
-
签约主体(甲方、乙方的完整名称) -
合同金额及币种 -
签署日期与生效日期 -
履行期限(起止时间) -
违约金比例 -
管辖法院或仲裁机构
-
姓名、性别、出生日期 -
身份证号 -
最高学历、毕业院校、专业 -
过往工作单位及任职时间 -
紧急联系人及联系方式
-
发票代码、发票号码、开票日期 -
购买方与销售方纳税人识别号 -
不含税金额、税额、价税合计
-
商品或服务的税收分类编码
-
项目编号、项目名称 -
建设单位、设计单位、施工单位 -
批复文号及批复时间 -
预算总额与中标金额 -
关键里程碑的时间节点
-
统一社会信用代码 -
法人代表姓名 -
经营范围和住所地址 -
发证机关与有效期