 夜雨聆风
夜雨聆风





斯坦福2026 AI报告:AI写代码接近满分,中美差距仅剩2.7%,透明度却骤降31%
每年四月,斯坦福大学人机交互中心(Stanford HAI)都会发布一份厚达数百页的年度 AI 现状报告——AI Index Report。它不讲故事,只讲数字;它不预测未来,只记录当下。正因如此,每次发布都像一次冷静的照镜子:AI 这一年究竟走了多远?
2026 年版刚刚出炉。
这一次,镜子里照出了一个矛盾的行业:能力以令人眩晕的速度飞奔,透明度却在大步倒退。
编程能力:一年内从 60% 跃升至接近满分
如果要用一个数字概括 2026 年 AI 的技术进步,那就是 SWE-bench。
SWE-bench Verified 是业内公认的软件工程能力基准,测试 AI 能否真正解决 GitHub 上的真实 Bug——不是回答选择题,而是读代码、定位问题、写修复、通过测试。
2024 年底,最好的模型在这个基准上只能做到约 60%。而到 2026 年 Q1,顶尖模型已经达到了 80-94%,逼近人类工程师的基线水平。
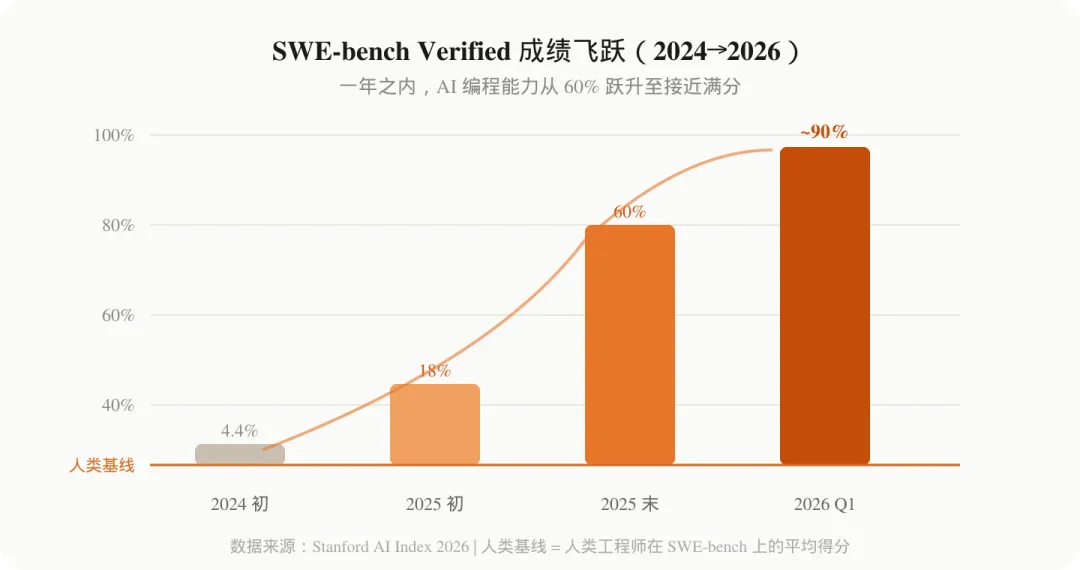
这不是渐进式进步。60% 到 90%,发生在短短一年内。
与此同时,另一个更难的基准——Terminal-Bench(测试在终端环境下完成复杂工程任务的能力)——成功率从 2025 年的 20% 跃升至 77.3%。网络安全 Agent 在 CTF 题目上的解题率,也从 2024 年的 15% 飙升到 93%。
还有一个让人坐立不安的数字:25 岁以下软件开发者的就业人数,自 2022 年以来已下降近 20%。
编程能力这条线,AI 和人类正在快速交叉。
中美差距:从 25 个百分点,到 2.7 个百分点
三年前,美中 AI 模型在主流基准测试上的能力差距,大约在 17.5 到 31.6 个百分点之间。这是肉眼可见的代差。
现在是 2.7 个百分点。
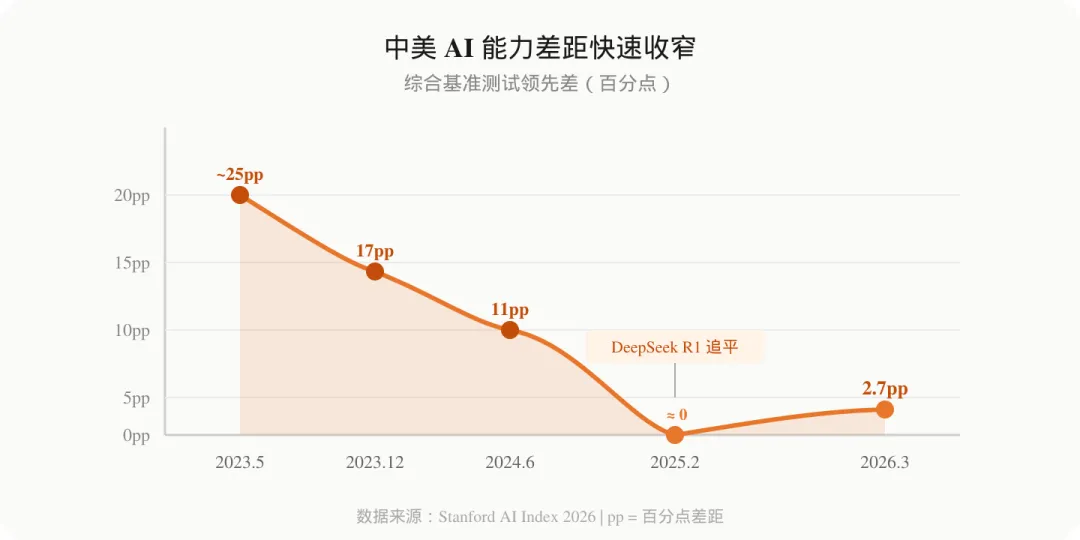
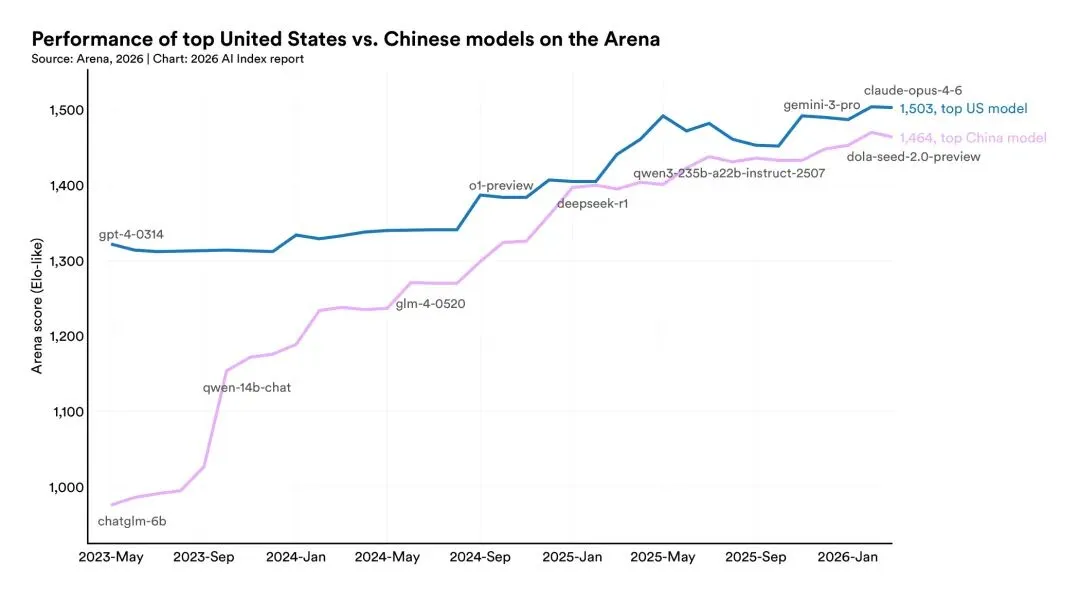
2025 年 2 月,DeepSeek R1 一度与当时最强的美国模型并驾齐驱,差距归零。此后,双方你追我赶,领先者几度易位。截至 2026 年 3 月,美国模型仍微弱领先,但差距已小到几乎没有实际意义。
-
这里补充一下,Arena是人类盲测模式的大模型对战评测平台,结果会有一定的片面性,从个人实际使用的体感上来看,差距可能比这个大点,但确实接近非常多了。
这里有一个让人印象深刻的对比:
-
美国 2025 年 AI 私人投资:2859 亿美元 -
中国 2025 年 AI 私人投资:124 亿美元
投资相差 23 倍,能力差距却只剩 2.7%。
这个数字的含义不言而喻:资本堆砌在 AI 能力竞争上正在出现边际递减。或者换句话说,中国用更少的钱,在模型能力上取得了几乎等效的结果。
DeepSeek、阿里、智谱——这些名字出现在全球顶级基准排行榜前列,已经不再令人意外。
值得一提的是,中国生成式 AI 用户规模已达 5.15 亿,这是一个巨大的本土市场,也是模型迭代和数据反馈的重要燃料。
透明度骤降:能力越强,越不愿说
以上是好消息(或者说,至少是令人兴奋的消息)。
下面是令人担忧的部分。
基础模型透明度指数(Foundation Model Transparency Index)从 58 分跌至 40 分,降幅达 31%。
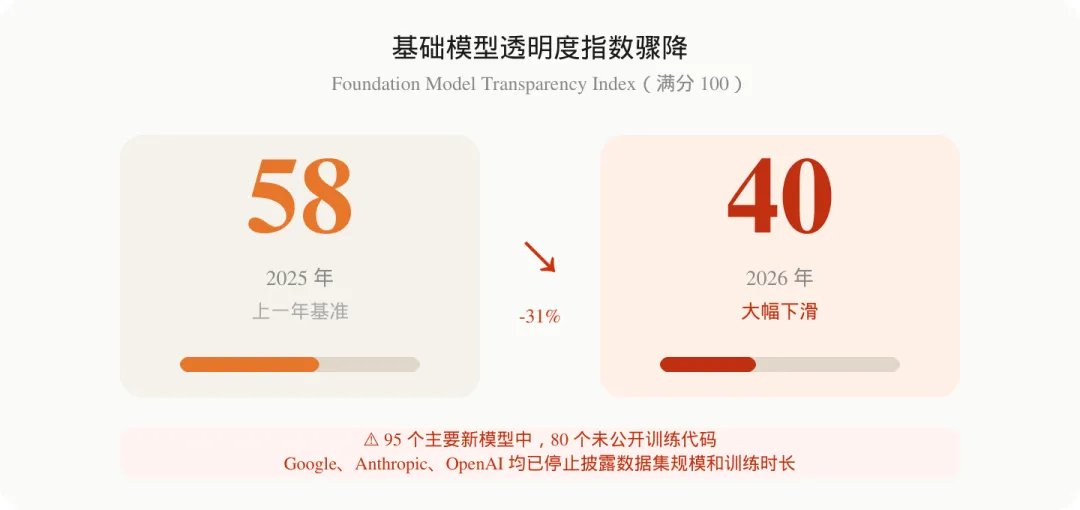
这个指数由斯坦福研究者构建,评估 AI 公司在训练数据、计算量、参数规模、风险文档、人类监督机制等维度上的公开程度。满分 100 分。
58 分本来已经不高了。40 分,意味着行业整体上正在主动减少信息披露。
具体表现:
- 95 个主要新发布模型中,80 个没有公开训练代码
-
Google、Anthropic、OpenAI 均已停止披露数据集规模和训练时长 -
能力越强的前沿模型,在训练数据来源、计算资源消耗、风险评估等方面反而透明度最低
有一种解读是:竞争压力让大公司不愿意暴露”配方”。但另一种解读更值得警惕:当模型能力已经足够强大,不透明带来的风险就不再只是学术问题,而是社会问题。
其他不可忽视的数字
能力层面的飞跃还不止于此:
- Humanity’s Last Exam
(一套涵盖数学、物理、法律等顶级难题的综合测试):2025 年最高分仅 8.8%,2026 年 4 月已有模型超过 50% -
Google Gemini Deep Think 在奥数竞赛中摘得金牌 -
全球企业 AI 采用率:科技行业已达 88%
投资与环境代价:
-
2025 年全球企业 AI 投资总额:5817 亿美元,同比增长 130% -
Grok 4 单次训练产生 72,816 吨 CO₂ 当量排放 -
全球数据中心装机容量:29.6 GW,相当于纽约市峰值用电量 -
GPT-4o 每年推理所消耗的水,可能超过 1200 万人的饮用水需求
认知鸿沟:
这或许是报告里最值得关注的软性数据。
-
73% 的 AI 专家认为 AI 对就业市场有正面影响 -
只有 23% 的普通公众持相同看法 -
美国公众对政府监管 AI 的信任度,在参与调研的国家中垫底,仅 31% -
只有 10% 的美国人对 AI 感到兴奋
专家和公众之间,有一道 50 个百分点的认知鸿沟。这道鸿沟,本身就是一个巨大的风险。
结语:跑得越快,越需要照镜子
Stanford AI Index 2026 呈现的,是一个能力极速扩张、但自我约束正在松弛的行业。
SWE-bench 接近满分,中美差距收窄至 2.7%——这些数字说明,AI 的能力边界正在以前所未有的速度扩张。但透明度指数骤降至 40,也说明行业在”让外界了解自己在做什么”这件事上,正在系统性地退步。
能力和透明度,本来应该同向增长。毕竟,你越强大,外界越需要知道你在做什么。
但目前的数据表明,它们正在反向而行。
这不是一个关于 AI 好坏的问题,而是一个关于治理节奏的问题:技术的脚步,和我们理解它、管理它的能力,正在以多快的速度分叉?
斯坦福的这份报告,每年都在尝试回答这个问题。2026 年的答案,不算乐观。
Stanford HAI 2026 AI Index Report 完整报告已在官网公开发布。