从 Hy3 preview 看 AI 下半场:单位智能时代的一次工程答卷
未来博士 wepon 特约作者
腾讯刚刚发布并开源了 Hy3 preview 模型。如果你习惯盯着参数表打分,第一眼可能会觉得“没什么可说的”——295B 的 MoE 主力版本,在今天动辄被标注为“T 级参数”的行业叙事里,甚至谈不上抢眼。
但要读懂这次发布,需要先把时间拨回到 2025 年 4 月。
那时,还在 OpenAI 的姚顺雨发表了一篇引起行业广泛讨论的文章——The Second Half(《AI 下半场》)。他在文章里做了一个判断:AI 已经走到了“中场”。
姚顺雨的观点要点可以这样概括:过去数十年的研究玩法是“开发新方法 → 在 benchmark 上爬坡 → 构造更难的 benchmark → 再爬坡”——评估当然一直重要,但评估的主要任务是陪练,为方法服务,终极目标是让模型在既有考卷上分数更高。而他认为,现在这个关系要反过来:下半场的核心不再是“同一张试卷上考得更高”,而是重新质疑“这张试卷是怎么设计的”——把评估从陪练位置,推到驱动位置。姚顺雨那句最重要的概括就是:“evaluation becomes more important than training”——不是说评估今天才开始重要,而是说它要从跟随方法创新的工具,变成倒逼方法创新的起点。
这个判断在当时并不算共识,但此后的一年里,它被几件事一件一件印证了:头部开源和闭源模型的能力差距肉眼可见地在缩小,“模型更强”能撬动的用户感知越来越小;Agent 应用爆发,把一个过去被忽视的变量——单位推理成本——推到了决定生死的位置;越来越多团队发现,在标准 benchmark 上领先的模型,放在真实业务里未必好用、甚至往往更贵。一句话总结:“benchmark 上的胜负”和“真实世界里的胜负”是两件事。
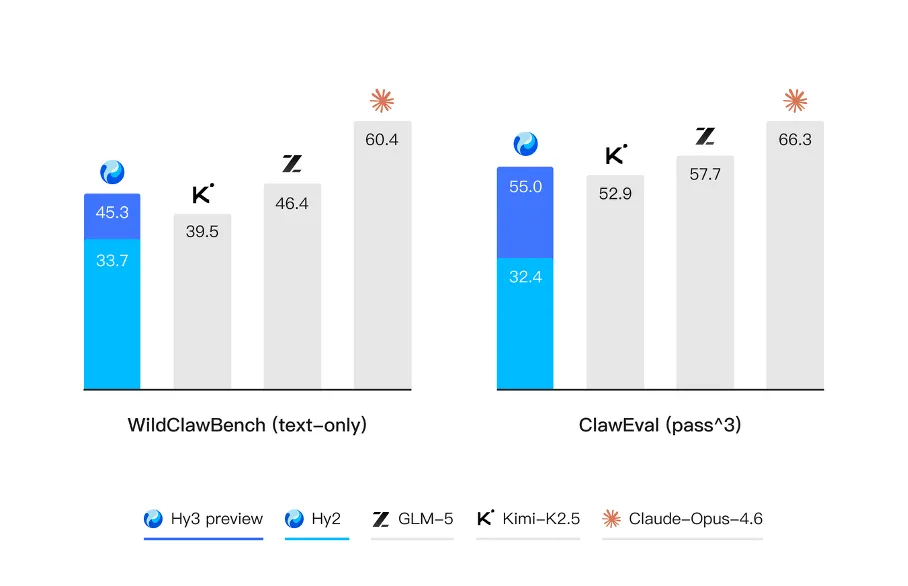
这一点,在最近 Hy3 preview 和 DeepSeek V4 几乎前后脚发布时,又被印证了一次。两家的路径并不完全一样:DeepSeek V4 用 Flash 和 Pro 两个版本覆盖不同层级的需求,Hy3 preview 则用一个不到 300B 的模型主动去找效果、速度、价格之间的平衡点;但它们指向的是同一个共识——在真实世界里,性价比正在变得比“性能最优”更重要。
Agent 的登场,把这套判断从一种预言推成了现实。ChatBot 时代一次对话只消耗几百到几千 token,单位成本是个次要问题;Agent 时代一次任务动辄几十万乃至上百万 token,单位成本就成了决定产业形态的结构性变量。一夜之间,整个行业被迫面对一个新的三角约束——质量、速度、价格,这三件事不可能同时做到极致。
姚顺雨加入腾讯、负责基模线之后交出的第一份作业,就是这次的 Hy3 preview。所以这次发布真正的看点,不在 benchmark 打到哪一档,而是——“下半场”判断的原始提出者,会用什么样的模型设计、什么样的产品取舍、什么样的评估标准,来回应他自己提出的那套主张。换句话说:这是一次观点与实践的对齐,也是一次从想法到代码的自我兑现。
Agent 时代的“不可能三角”:
单位智能成为产业结构性变量
要理解这次自我兑现为什么重要,得先看清 Agent 时代给大模型施加的新约束。
最直接的感受,是成本。过去一年几乎每一家做 Agent 产品的公司,都被同一件事反复教育——模型能力本身已经不再是唯一瓶颈,真正的瓶颈是“能不能用得起”。AI IDE 也好、通用 Agent 也好,都不同程度暴露出高 token 成本带来的商业约束:Demo 阶段很炸裂,真要规模化部署时就被成本曲线按在地上反复摩擦。企业客户的 Agent 采购决策里,TCO(总拥有成本)正越来越接近第一决策维度。这就是为什么“单位智能成本”不再只是商业指标,而是产业结构性指标——它直接决定了哪些 Agent 应用能够存在、以什么形态存在、服务多大规模的用户。
但成本只是表象。再往下一层,真正决定产品形态的,是一个经典的不可能三角——质量、速度、价格。只做质量:最大参数、最长推理链,结果是速度慢、价格贵,以至于几乎不可用,定位注定小众高端;只做速度:蒸馏小模型,结果是质量崩塌,只能做最简单的任务;只做价格:MoE 激进稀疏比、激进量化、批量调度,结果是首 token 延迟拉长、特定任务质量下降,不适合交互式 Agent。真正的产品化模型,必须在三角里主动选择一个平衡点,并让它与目标业务场景精确匹配。这是一门“平衡艺术”——不是做得最好,而是做得最合适。
更关键的是,在三角之上,Agent 时代的工作流本身也在分化成两类完全不同的需求:
● 复杂推理:长链路思考、多步规划、严谨论证的任务,比如代码调试、数学证明、科研写作、战略分析。对质量极其敏感,少数关键调用的正确与否直接决定产出价值;token 消耗相对集中、可控,用户愿意为单次高质量答案付高价。
● 日常 Agent 任务:识别、整理、抽取、改写、润色、翻译、结构化、长文生成、Tool Use 样板调度、RAG 里的摘要和改写等等。这类任务单次价值低、但品类极散、调用量极大——是 Agent 产品里真正的 token 消耗大头;对质量只要“够用就好”,但对速度和价格极其敏感——任何一点成本超支,乘以调用量都是账单上的大窟窿。
复杂推理要的是“最强大脑”,日常任务要的是“最合适的劳动力”。两件事在不可能三角上是往相反方向拉的,同一个模型很难同时做好。这也是为什么“一个模型打天下”的逻辑正在失效——未来的 AI 工作流,本质上是复杂推理模型和日常任务模型的分工协作。
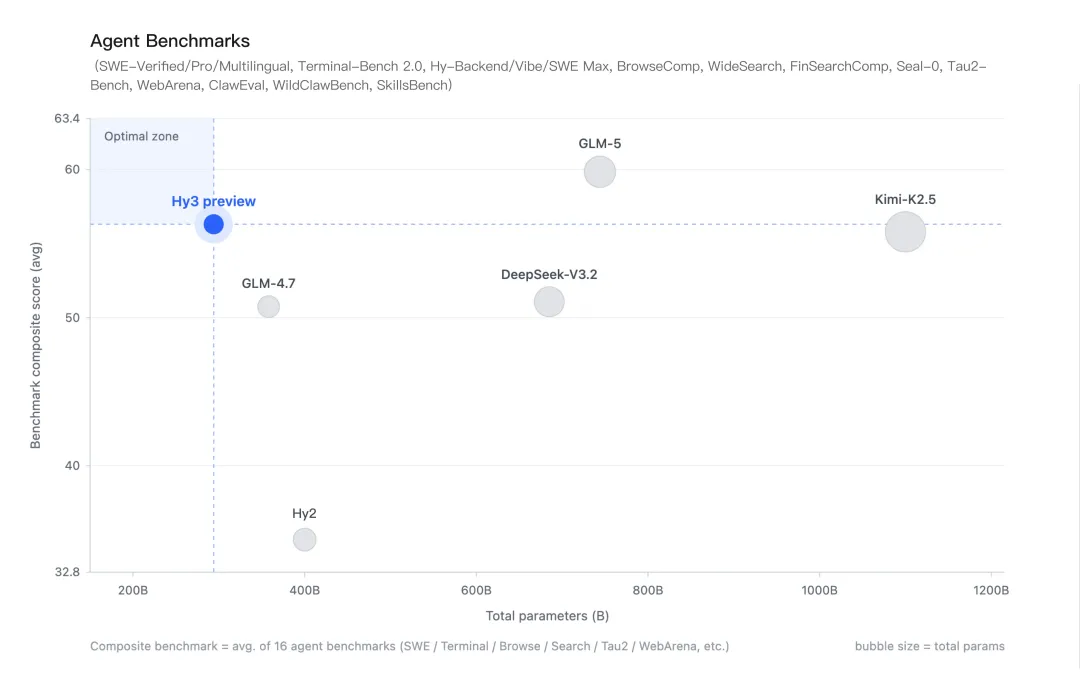
从 Hy3 preview 的参数规格和试用体验反推,它选的平衡点非常清晰——明确站在“日常任务 + 结构化产物”这一侧,而不是去抢“复杂推理冠军”。质量上进入可用区但不追求 SOTA,目标是“在大多数真实业务分布下够用”;速度上 MoE 架构保证激活参数远小于总参数,首 token 延迟和吞吐对高频调用友好;价格上把单位 token 成本压到腾讯量级业务可承受的区间。它不是为“炸榜”生的,也不是为“极限推理”生的,而是为日常 Agent 任务和规模化吞吐生的。
这个取舍和腾讯自身的业务组合高度契合。当大模型能力要塞进元宝、QQ、微信、腾讯会议、广告系统、游戏 NPC、企业协同——每一个都可能在一年内长出自己的 Agent 形态——腾讯真正需要的不是“最聪明的模型”,而是能把海量日常调用做得又快又便宜、同时稳定交付结构化产物的模型。Hy3 preview 表现出的速度优先、长文组织能力扎实这两个偏好,正好对应这套业务需求。它是一个“为在腾讯业务里长期服役”而生的模型。
把视角拉回产业,这其实也解答了“为榜单而生还是为使用而生”这个老问题:独立模型公司需要旗舰参数证明技术实力,而有海量业务场景的互联网巨头,更该问“什么样的模型规格,在 Agent 时代的单位经济上跑得通”——Hy3 preview 就是在回答这个问题。
如果把视野再拉宽一点,最近 DeepSeek V4 的发布其实也在说明同一件事。它没有把所有需求都压在一个模型上,而是用 Flash 和 Pro 两个版本去覆盖不同层级的调用场景;Hy3 preview 的路径则不同,它更像是试图用一个中型模型,把质量、速度、价格的平衡点尽量往中间推,从而在不做版本分层的前提下,独立承接尽可能多的场景需求。一个是双版本分层覆盖,一个是单模型找平衡点,路径不同,但都在回答同一个问题:什么样的模型形态,才能在真实业务里更大规模地跑起来。
说个亲身经历。最近我在业余时间做了一个开源项目 TeachAny,给 K12 家长和老师制作自适应课件。作为一个没有开发背景的人,我几乎完全依靠 AI 辅助,用两周业余时间搭起了一个从课件生成、知识组织到社区发布都能跑通的开源系统。它不是 demo,也不是几段 prompt 的拼装,而是已经形成内容生产、知识沉淀、课件展示和社区分享闭环的产品雏形。整个代码架构主要由一款海外头部模型实现——它确实够强、够聪明,但成本很快就成了瓶颈。项目里大量工作并不是“高智力”任务:把课标和教材 PDF 转成 Markdown、从知识点里抽取参考资料、做结构化整理——这些工作吞 token 的速度惊人。
后来 Hy3 preview 在 WorkBuddy 上线,我做了一件很简单的事:把“识别、整理、长文生成”,尤其是用 skill 大批量制作示范课程这类日常任务全部切到 Hy3 preview 上,把“核心架构、复杂推理”才留给那款海外模型。结果是——同样的任务量下,速度明显提升,token 消耗显著下降。这是个粗略对比、不是严谨评测,但体感极其鲜明:“切换模型以匹配任务”这件事,比单纯追求单模型能力更强,起到了决定性作用。
再把这个体感向前推一步:通过自动路由或手工切换,在”复杂推理旗舰模型”和”日常任务中型模型”之间分工协作,大概率会成为绝大多数 AI 工作流的基本方式。这早已不是“极客小技巧”——主流 AI IDE 已经在后台按任务复杂度自动分发模型;企业端的 Agent 平台几乎清一色内置了模型路由;连一些 C 端产品都在悄悄做“简单问题用便宜模型、复杂问题升级到旗舰模型”的默认策略。Hy3 preview 足够快、足够便宜,正卡在这一层里最刚需的位置。
说回姚顺雨那套“下半场”主张——它是整篇文章的叙事锚点。
他做的最大贡献,是把行业从内循环的评估体系(自己定卷子、自己刷榜、自己比参数)里拉出来,指向一个外部坐标系:价值的真伪,要在真实问题、真实用户、真实商业环境里被验证。姚顺雨原文结尾的愿景也很清晰——前半场的玩家忙于解决电子游戏和考试,下半场的玩家则是用智能打造真正有用的产品,去建立价值数十亿甚至数万亿美元的公司。
这个主张不只是口号。在 Hy3 preview 发布前几个月,腾讯混元 Research 就悄悄交出了一份高度呼应的学术成果——2026 年初发布、由姚顺雨担任通讯作者的 CL-bench 论文。论文用一个接地气的比喻说清了同一件事:今天的前沿模型是“顶级的做题家”,能解奥数、能通过专业资格考试,但在真实工作里常常失败——因为它们依赖的是压缩进权重里的“死知识”,而真实世界里的人是实时从 context 里学习的。论文里最精彩的一句是:
竞争的焦点将从“谁能把模型训练得更好”,转向“谁能为任务提供最丰富、最相关的 context”。
这句话几乎就是“下半场”主张的产业化翻译。至此,一条时间线被串起来——理论(2025.4 姚顺雨《The Second Half》)→ 学术实证(2026.2 CL-bench)→ 工程兑现(2026.4 Hy3 preview)。
这条链还可以再往下走一步——走到用户侧。回头看 TeachAny:它本质上不是“代码生成器”,而是把课标、教材、教学方法这些 context 精心整理好,把学科教学法沉淀成一套可复用的 skill,再交给模型执行的系统。一位使用 WorkBuddy 的老师或家长,不需要懂 prompt 工程,只要选好教学对象和目标,TeachAny Skill 就会把对应的知识点 context、教学方法、音视频工具一并装配好,再用国产模型低成本生成一份真正可用的自适应课件。TeachAny 做的事,就是把“从参数推理者到 context 学习者”这句话翻译成普通用户能直接用上的产品形态。而 Hy3 preview 恰好是这条路径在模型层非常合适的选择——不是因为它最强,而是它的速度-成本平衡让“备好 context、打磨 skill、再选择合适的模型”这件事开始具备规模化可行性。
姚顺雨提出的是原始判断,这一年里行业在这个框架下做了很多延展——大致可以归为四条共识:一是评估体系的重构,从他共同作者的 SWE-bench(2023)、第一作者的 τ-bench(2024),到他在腾讯主导的 CL-bench(2026),都是在回答“新的评估标准长什么样”;二是 Harness(脚手架)能力的崛起——Tool Use、上下文工程、多步规划、缓存复用、与业务系统的打通。Harness 的本质是用工程手段把不可能三角的平衡点外推——同质量下压成本、同成本下顶质量,一个能力 80 分的模型配一套 90 分的 Harness,综合表现可以碾压一个 95 分但只有裸 API 的竞品;三是工程闭环能力,训练、推理、调度、评测、上线回流每一环的成熟度,直接决定迭代速度;四是产品与场景落地能力——模型放在 API 里和放在 QQ、微信里是两回事,后者需要“好用、稳定、合规、可监测、可算账”,这是互联网公司的传统优势。
姚顺雨指出方向,行业补上方向上的能力——两件事不矛盾,是递进关系。
过去两年独立模型公司有个天然优势——聚焦。不考虑业务落地,可以把 100% 资源压在模型本身。但当行业进入 Agent 驱动的下半场,聚焦的优势在削弱,全栈的优势在放大。原因很朴素:下半场的核心问题(什么问题值得被解决、评估标准怎么在真实业务里长出来),恰好是独立模型公司最缺资源、大厂最有禀赋的地方。一家拥有游戏、社交、广告、企业协同、内容平台的巨头,天然就有“真实问题的样本库”——它最大的挑战不是找问题,而是把这些问题精准翻译成模型的训练目标和评估目标。
Hy3 preview 选择在此时用“务实主义”作宣发基调,本质是对自身禀赋的重新定价——不再用独立模型公司的语言讲故事,而是用一家“拥有中国最大业务出口之一、且正在批量孵化 Agent 形态的互联网巨头”的语言讲故事。“下半场”判断是姚顺雨的外部表达,CL-bench 是腾讯内部的学术实证,Hy3 preview 的定位方式,是同一套逻辑在工程层面的第三次展开,并共同指向同一件事。
还有一个数字值得被单独拎出来讲:从架构调整到版本交付,整个过程不到 3 个月。作为对照,海外头部开源模型主版本迭代通常 6 到 12 个月,独立模型公司 4 到 8 个月,大厂模型部门因协同成本高,传统周期往往超过 6 个月。3 个月能把一个这种量级的 MoE 模型从架构调整推进到可发布状态,这不是“模型能力”层面的事,而是组织和工程效率层面的事。
从公开信息综合看,腾讯基模线这一轮变化至少做了三件事。一是引入外部顶尖人才,重塑技术判断力——姚顺雨加入后第一件事就是重新评估技术路线、快速做减法;对过去几年业务线繁杂、技术路径分叉较多的大厂模型团队,这种“从外部带来的清晰判断”有时候比内部共识更高效。二是扁平化管理,缩短决策链条——传统大厂模型团队最大的效率损耗不在算法,而在层层审批和多方协同;扁平化后,资源权限清晰、决策链条变短,工程师能把精力真正花在模型上。三是模型与产品“背靠背协作”——这是看似简单但极难做到的组织模式:过去是产品等模型交付、模型按节奏训练、产品拿到后再做适配;背靠背协作意味着产品需求提前反向嵌入到训练目标,模型能力迭代直接对齐产品 KPI,中间不再有长达数月的“等待窗口”。
要承认一个现实——当前阶段国内所有大模型团队都在和算力短缺搏斗,这不是腾讯独有的问题,是整个中国 AI 产业的结构性约束。算力受限的前提下,组织效率就是第二条杠杆:同样的卡,快 3 个月迭代一次,就意味着一年多跑 1-2 个版本、更多实验、更丰富的训练信号、更快的错误纠正。这也是为什么“过程版本”这个说法值得被认真对待而不是被解读为“不成熟”——在大模型这个领域,“能快速迭代的过程版本” > “等 12 个月才出来的完美版本”,几乎是一条已经被反复验证的规律。
讨论中国大模型产业,还有一个常被忽略的结构性事实:头部互联网公司并不是 AI 原生公司。它们的基因在产品、搜广推、社交、电商——在此之上积累的,是围绕具体业务目标的数据体系、特征工程、排序召回模型和在线反馈闭环。这套积累让它们对“真实业务里的 AI”并不陌生,但它解决不了大模型时代的两个新问题——模型的方法论怎么跑通、支撑它的基础设施怎么规模化。换句话说,这些公司不是“从零做 AI”,而是带着一身搜广推经验入场,再补大模型专属的两门课。
第一门课,大模型方法论验证:先用中等规模模型把预训练、后训练、对齐、评测等方法跑通,证明团队知道大模型该怎么训、怎么评、怎么调。这是从“业务算法思维”切到“foundation model 思维”的关键一跃。
第二门课,基建与规模化:把算力调度、数据治理、训练平台、推理服务、评测体系和组织机制做成可持续的工业能力,让更大模型、更多业务接入能真正跑起来。这一步决定的不是“能不能训出一个好模型”,而是“能不能持续运转训练-推理闭环”。
从外部观察,腾讯在 Hy3 这一代上没有按部就班先验证再规模化,而是把两门课并行推进。代价是短期技术风险更高、整合难度更大;收益是一旦跑通,会把原本 12-18 个月的传统路径压缩到 3-6 个月。每个版本都不是最终形态,但每个版本都在真实业务场景里拿到数据、迭代能力、修正方向。这条路对不对?行业里两派意见都有:支持派认为这是大厂唯一能追赶的方式,谨慎派认为工程和算法不解耦会积累技术债。答案需要时间回答。
第一,Hy3 preview 不会是能力意义上的行业第一。对比头部闭源旗舰,长文本、复杂推理等能力上仍有差距——承认这点比回避更有说服力。但这篇文章讨论的,本来就不是”谁是第一”。
第二,算力短板在短期内无法解决。这不是腾讯的问题,是整个中国 AI 产业的问题。Hy3 短期内的业务覆盖面会被算力供给牵制;但恰恰因为算力紧张,单位智能成本的议题才更显紧迫——没人比受算力约束的团队更懂“把一张卡用到极致”意味着什么。
第三,“平衡艺术”路线需要时间验证。这条叙事短期不如“参数最大、榜单最高”打动人,它需要在未来 6-12 个月里用真实业务数据——Agent 任务完成率、单任务成本、用户留存、企业客户转化——来回答“三角平衡点有没有选对”。真正的考验是下一代版本能不能把质量往上推一格,同时把成本再压一格。
行业这两年见过太多“参数奇袭”的模型发布,见过太多“榜单屠榜”的一夜刷屏,也见过太多发布会后产品沉寂的案例。
但很少见到这样一次发布——一个曾经对行业方向做出清晰判断的人,在加入一家大厂之后,用自己的手交出一份与那套判断高度对齐的答卷,构成一条完整的“理论 → 学术实证 → 工程兑现 → 用户应用”闭环。
更重要的是另一件事——2026 年 AI 产业最主要的推动力,可能正在从实验室、从头部模型公司、从极客圈子,下沉到无数个“普通人用 WorkBuddy 这类工具、配合国产模型完成日常工作”的真实场景里。一位不会写代码的老师用 TeachAny Skill 做出一门课、一位小商家让 Agent 帮他处理客诉和订单——这些看似微不足道的日常使用,正以惊人的速度积累出真实的使用数据、产品反馈和商业价值。过去几年“AI 由少数顶级模型推动”的叙事,正在被“AI 由无数真实工作流推动”的叙事取代。一旦这件事发生,决定下一代 AI 产品形态的,不再是模型能做到什么,而是普通人用起来方不方便、便不便宜、稳不稳定。在这个意义上,一个速度快、成本低、能长期稳定服役的国产中型模型,战略价值比任何一个 benchmark 冠军都更持久。Hy3 preview 要抓住的,正是这个发生在大众层面的巨大机会。
一个判断最好的自证方式,是提出它的人亲自把它做出来。 Hy3 preview,就是这样一次尝试。值得所有关心中国 AI 产业的人,在未来持续观察。
闫德利:《人工智能的生产率悖论》
王鹏:《AI时代,教育何往?》
👇 点个“在看”分享洞见
 夜雨聆风
夜雨聆风