 夜雨聆风
夜雨聆风





每个学生都被AI“看透”了,你怕不怕?——教育“智能大脑”背后的三道坎
击👆知势者👇关注我,加★星标★
嗨~你好啊!我是“势在必行,知在必赢”的知势者。
想象一个场景。
你的孩子,从小学一年级开始,每一次作业、每一次考试、每一次课堂举手、每一次走神、甚至每一次情绪波动,都被一个系统默默记录着。
十二年下来,这个系统比班主任更了解他,比你更了解他,甚至可能比他自己更了解他。
然后有一天,这个“智能大脑”说:你的孩子适合学文科,不建议选物理。
听起来很高效,对不对?
但你敢信吗?它会不会搞错?搞错了谁负责?这些数据会不会被卖掉?算法会不会把“不一样”当成“有问题”?
2026年《“人工智能+教育”行动计划》明确提出,要打造“教育智能大脑”,建设“国家教育大数据中心”。文件同时也承认了风险——“有效防范算法歧视、惰化思维、过度依赖、隐私泄露等问题”。
翻译成大白话就是:我们知道这事有坑,但不得不干。
那问题来了——这些坑,准备怎么填?
三个人,三种怕
先说家长。
一位妈妈听说学校要上“智慧课堂”系统,采集学生行为数据。她的第一反应不是“太好了”,而是:“他们会不会连我孩子什么时候上厕所都记下来?这些数据最后到谁手里?”
她的担心一点都不多余。教育数据的边界到底在哪里,到今天为止,没有人给出一个清晰的答案。
再说学生。
一个高中生跟我说了一句话,我印象很深:“AI说我逻辑思维弱、空间想象强,建议我选文科。可我想学建筑。它凭什么替我决定?”
注意,算法的“建议”和“决定”之间,只隔着一层薄薄的窗户纸。当老师拿着AI报告跟家长谈话的时候,那个“建议”在很多人眼里就已经是“判决”了。
最后说校长。
一位校长坦言:“AI系统推荐了一套分班方案,按能力把学生分成快慢班。我知道这可能产生标签效应,可如果不分,平均成绩上不去,家长又不满意。”
效率和公平,短期和长期,他本来就难选。“智能大脑”没有让选择变简单,反而让两难变成了三难——因为多了一个问题:如果我听了AI的,出了事,算谁的?
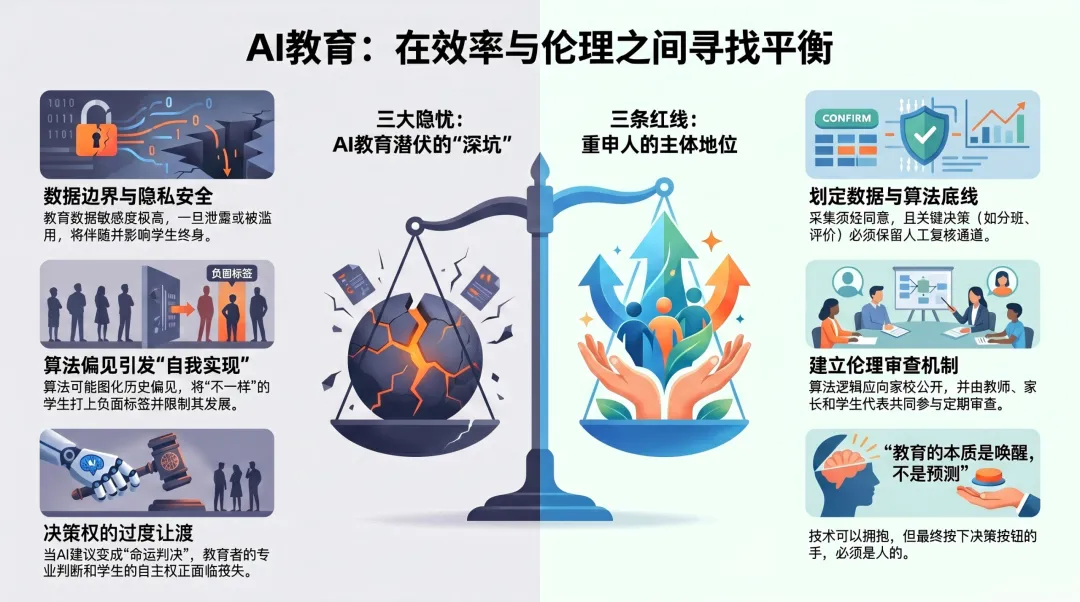
第一道坎:数据——边界到底画在哪?
文件说要建设“国家教育大数据中心”,汇聚“跨部门、跨地域、跨平台”的数据。
这句话展开来看,问题就来了。
采集边界在哪? 课堂表现可以采吗?作业数据可以采吗?社交行为呢?面部表情呢?心率呢?如果这些都能采,那和全天候监控有什么区别?
存储安全怎么保障? 教育数据的敏感程度远超信用卡信息。信用卡丢了可以换,但一个人从6岁到18岁的学习档案、心理评估、行为记录——泄露一次,跟一辈子。
使用权限谁来定? 老师能看多少?校长能看多少?教育局呢?开发算法的公司呢?家长自己能不能看?能不能要求删除?
目前文件的措辞是“统筹发展与安全”。方向对,但远远不够。
必须明确一条底线:数据是学生的,不是学校的,更不是算法公司的。
欧盟GDPR早就规定了“未成年人数据需要特别保护”,我们的《个人信息保护法》也有类似条款。但教育场景的具体实施细则,至今没有落地。这个空白不填,家长的焦虑就不会消失。
第二道坎:算法——机器也会“带着偏见看人”

很多人以为算法是客观的。不是。
算法的偏见来自两个地方。
第一个是训练数据。如果历史数据里,某一类学生长期被打上“后进”的标签,算法学到的就是“这类学生大概率不行”。然后它会给这些学生推荐更简单的内容、更低的目标。学生接收到更低的期待,表现果然更差。算法一看——你看,我预测得没错吧?
这叫“自我实现的预言”。 不是学生不行,是算法先认定他不行,然后把他推向了不行。
美国有一项研究发现,某教育算法对少数族裔学生的预测偏差率高达20%。原因很简单——训练数据本身就带着历史偏见。
第二个是设计者的价值判断。谁来定义“好学生”?成绩高就是好?进步快算不算?团队合作能力强算不算?创造力算不算?每一种定义背后都是一种价值选择,而这个选择往往是算法工程师在会议室里拍板的。
更麻烦的是追责问题。如果AI建议一个孩子放弃物理,这个孩子照做了,三年后发现这个建议是错的——谁来负责?开发公司?学校?还是那个“算法黑箱”本身?
算法可以告诉你“是什么”,但“应该是什么”,永远该由人来决定。
文件提到了“价值对齐”——让AI的价值观与人类一致。想法很好,但“人类”的价值观本身就充满分歧。对齐到谁的价值观?这个问题回避不了。
第三道坎:治理——权力让渡给机器多少?
“教育智能大脑”不仅仅是一个数据仓库。它正在获得越来越多的决策权。
自动分班。自动排课。自动推荐学习路径。自动预警“辍学风险”“心理问题风险”。甚至自动生成学生评价报告。
每一项听起来都在帮忙,但每一项背后都藏着同一个问题:决策权到底让渡了多少给机器?
当一个校长按照AI的分班建议执行,他的自主权去哪了?当一个老师发现AI给出的学生评语比自己写的“更全面”,她的专业判断还有存在的必要吗?当一个家长被告知“系统预警您的孩子有辍学风险”,她的知情权和申诉权如何保障?
文件说要“有效防范过度依赖”。说得对。但光说不够,需要机制。
AI是辅助,不是替代。最终按下按钮的手,必须是人的。
三条红线,不能让步
问题拆完了,该谈底线了。
第一条,数据红线。 采集任何学生数据,须经本人或监护人明示同意,且不得用于约定之外的任何目的。学生有权查看自己的数据档案,有权要求更正和删除。
第二条,算法红线。 涉及关键决策的环节——分班、评价、升学推荐——必须保留人工复核通道。算法的基本逻辑应当向教师和家长公开,不能以“商业机密”为由拒绝解释。
第三条,治理红线。 每所使用AI系统的学校,应当建立“AI伦理审查机制”,由教师代表、家长代表、学生代表共同参与,定期审查算法对学生的实际影响。
普通人能做什么?
说了这么多,你可能会问:这些不都是政策层面的事吗?我能干什么?
能干的事比你想的多。
如果你是家长——主动问学校:你们采集了我孩子的哪些数据?存在哪里?谁能看到?这不是找茬,这是你的权利。
如果你是教师——AI的建议可以参考,但不要盲从。你对学生的了解是立体的、有温度的,算法做不到这一点。保留你的专业判断,这不是固执,这是责任。
如果你是学生——了解你的数据权利。如果AI给你的建议你觉得不对,你有权利质疑,有权利申诉。你的人生不该由一个模型来定义。
教育的本质是唤醒,不是预测。别让“智能大脑”变成“命运判决器”。

技术可以拥抱,但前提是我们知道边界在哪里。透明、问责、人的尊严——这三样东西,比任何算法都重要。
💬 说说你的想法:
1. 你接受学校采集孩子的哪些数据?成绩?课堂行为?表情?评论区打个数字,我们看看大家的底线在哪。
2. 你有没有遇到过“AI建议不靠谱”的情况?后来怎么处理的?欢迎留言分享。
3. 如果你希望学校公开算法的决策逻辑,扣1。我们一起推动透明化。
最后,感谢你看到这里👏
如果喜欢这篇文章,不妨顺手给我们
点赞👍|在看👀|转发📪|评论📣
如果想要第一时间收到推送,不妨给我个星标🌟
更精彩内容,我们下期再见……