 夜雨聆风
夜雨聆风





AI界的"比亚迪时刻":DeepSeek-V4正在用国产算力,完成对硅谷的"反向输出"
大家好,我是淇哥,为你探寻AGI时代不一样的看法。

2026年4月24日,DeepSeek-V4预览版发布,当天整个朋友圈就炸开了。
OpenAI前一天刚发了GPT-5.5。DeepSeek第二天就贴脸开大。
这已经不是”追赶”了,是”你发我也发,看谁更有料”。
但看完官方公告和技术文档后,我发现最值得聊的不是参数和测评——参数大家都发过了,你看其他大V的就行。我觉得最值得聊的,是藏在参数背后的一次底层权力交接。
真正的大事:昇腾950PR的Day 0适配
翻官方公告时,有一行字让我停了很久:
V4版本已完成对华为昇腾950PR等国产芯片的Day 0适配。
注意这个词——Day 0。
什么意思?
以前国产大模型的标准流程是:先基于NVIDIA的CUDA环境开发,发布后过几个月,再慢慢往国产芯片上迁移。这叫”兼容”。
Day 0适配意味着:DeepSeek的工程师在模型预训练阶段,就已经深度介入了昇腾的底层算子开发。模型和芯片是同时诞生的。
这不是”勉强能跑”,这是原生。
为什么这件事这么重要?因为这意味着:
-
V4发布的同时,就提供了针对昇腾950PR优化的算子库,不需要开发者做复杂的二次转换 -
在950PR上的推理效率几乎达到理论峰值——不是”能跑”,是”跑得飞快” -
算力成本的定价权,第一次回到了中国人自己手里
聊到这儿,有必要多说一句这颗950PR。
华为在今年3月刚把它推向市场。它特别强化了对FP8/MXFP8精度算力的支持——而FP8正是V4为了实现百万上下文而大规模采用的技术。它搭载的新一代Atlas 350服务器,在互联带宽上提升了2.5倍。
就是你看到的V4那些炸裂数据,很大程度上是”模型创新+硬件定制”两个人一起跳舞的结果,不是模型一个人跳出来的。
还有一个细节值得单独拎出来说——这次适配是”偷偷”干的。
DeepSeek没有提前大肆宣传”我们在适配昇腾了”,而是闭门搞了一年。为什么?
第一,防止干扰。 底层架构的变动是大模型公司的最高机密。如果过早宣布”全线迁移华为”,算力采购和国际合作上会平添变数。
第二,避开”适配深坑”。 国产硬件的适配初期非常痛苦——编译器报错、算子性能不达标是常态。DeepSeek选择闭门造车,直到拿出”超越CUDA推理效率”的数据才亮相。不鸣则已,一鸣惊人。
第三,算力议价权。 提前一年在昇腾底座上深耕,让DeepSeek成了最懂国产芯片的大模型公司。2026年国内大规模算力基建潮中,它能以最低的成本拿到最多的算力配额。
所以你看,这根本不是一次”临时起意的适配”,而是中国大模型历史上规模最大的一次**”软件定义硬件”**的联合攻坚。秘密潜伏一年,一朝改天换地。
把时间线拆开看,你就知道这场”潜伏”有多深:
2025年初:推倒重建DeepSeek原定于2025年中发布的一个版本被延迟了。业内当时猜各种原因,真相是——核心工程团队正在进行极其痛苦的”底层搬家”,把整个编译、算子库和通信框架从NVIDIA的CUDA往华为的CANN迁移。这不是修修补补,是换地基。
2025年下半年:拿到工程样片华为2025年9月的全联接大会上,DeepSeek已经低调现身。当时R1的安全增强版已经在昇腾算力平台上跑通了。更深层的信号是:DeepSeek至少在那时已经拿到了950PR的工程样片。芯片还没发布,人已经在调了。
2026年初:工程师”住”进华为智算中心950PR正式发布前的3个月,DeepSeek的工程师基本上是住在华为的智算中心里的。双方联手针对V4的MLA(多头潜在注意力)和MoE架构,重写了HCCS 3.0互联技术的通信后端。
这就是为什么V4发布时敢说”原生支持”——因为这颗芯片在设计阶段,DeepSeek就已经参与了算力配比的建议。
所以3月24日华为发布950PR,4月24日DeepSeek发布V4。中间隔了整整一个月——不是临时适配,是厚积薄发之后的正式亮牌。
其实关于国产芯片的适配不只是DeepSeek在做这件事
翻一下同期的国产模型,你会看到同一个趋势:
-
GLM 5.1(智谱):走得最坚决。从底层算子到上层框架,全栈华为昇腾+MindSpore。真正的”中国模型+中国算力”。 -
Qwen 3.6(阿里):两条腿走路。训练用自研倚天芯片+NVIDIA混合集群,保持CUDA兼容以满足全球开源社区,但国内API底层已经大量用国产加速器。开发依赖CUDA,部署倾向国产。 -
MiMo v2.5(小米):前DeepSeek核心团队主导。跟国产自研NPU的适配做得极深,尤其移动端推理,几乎围绕国产硬件设计算法。 -
Kimi 2.6(月之暗面):推理侧已开始迁移到国产万卡集群(国家超算互联网、中国移动庆阳集群),但开源权重保持对CUDA/ROCm的兼容。
不是DeepSeek一家在”搬家”——整个行业都在往国产算力上扎根。 只是DeepSeek走得最彻底、最决绝。
算力自主,才是真正的”价格屠夫”
那为什么DeepSeek能把价格打到这么低?
大家第一反应是”便宜”。从2025年初的R1开始,”价格屠夫”这个标签就贴上了。V4也延续了这个传统:Flash版输出2元/百万Token,跟白送差不多。
经常看到有人说”算力成本会降到可以忽略不计”——这个说法,我不认同。
不是”忽略不计”,是”公用事业化”。
电力、水、煤气,便宜吗?便宜。免费吗?不免费。但因为是自己生产、自己定价、自己控制供应链,所以成本可控。
以前的算力底座,芯片是别人的(NVIDIA),生态是别人的(CUDA),价格也是别人说了算。你想买A100/H100?要么溢价几倍,要么买到的是”阉割版”。
这跟中国汽车工业的历史一模一样。
二十年前,一辆低配的合资品牌车能在中国卖到天价。后来呢?比亚迪、蔚来、小鹏,在电动车赛道直接跨过了内燃机的技术壁垒,在三电系统上自成一派。现在中国电动车出口欧洲,不是因为便宜,是因为技术真的先进。
DeepSeek-V4配上华为950PR,就是AI界的”比亚迪时刻”:
-
以前:拿着高价买来的”汽油”(进口芯片),跑在别人的”公路”(CUDA)上 -
现在:自己修了”电网”(国产算力集群),造了”超跑”(V4),电费自己定,车也自己造
所以你看到V4的API价格是全球最低的,不是什么”战略亏损”,而是算力成本的结构性优势——没有关税、没有中间商、模型和芯片深度适配后的效率红利。
V4贵不贵?说几句实话
我平时自己做技术调研、跑测试、偶尔搭个小程序做验证,勉强还能接受。
现在开发者圈子里,对V4的价格讨论主要是:
-
有人说便宜:跟GPT-5.5(输入 5 、输出 -
有人说贵:跟国内其他厂家的Coding Plan(¥40-200/月包月)比,DeepSeek的按量付费确实不便宜。DeepSeekV4目前推出了限制优惠,还是挺良心的,但严格来说,V4不是一个价格,是两个价格——Flash和Pro完全不是一个东西。 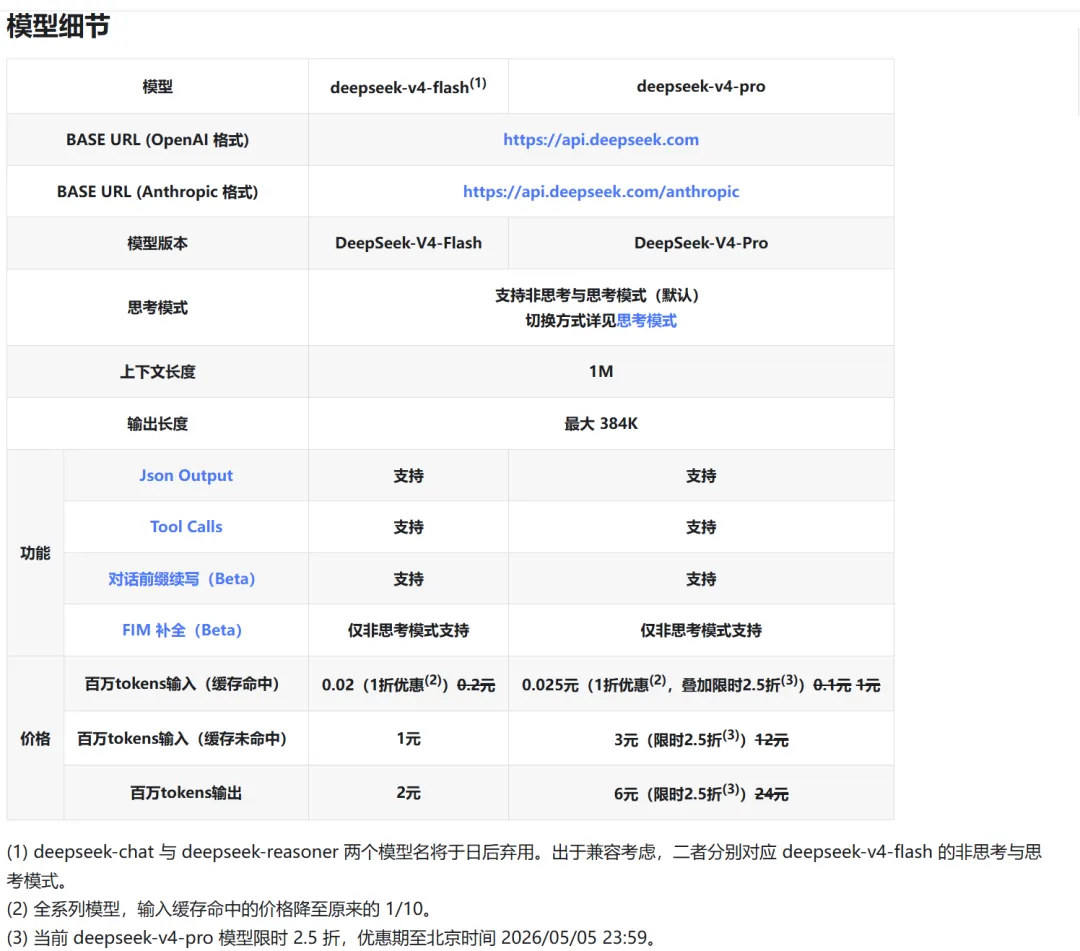
其实两方说得都对,只是场景不同。
V4-Pro拥有1.6万亿参数,你让它改个CSS样式,它”思考”的过程要消耗几千个内部推理Token——这些思维链的Token也是要收费的。大炮打蚊子,当然觉得贵。
但对于我这种非全职开发者,V4-Flash才是真正的甜点。
-
输出2元/百万Token,只有Pro的三分之一 -
处理代码调试、数据整理、技术文档分析,速度极快,结果准确 -
100万上下文和Pro一样,可以一次性扔一整本技术文档让它消化
我的用法很朴素:Flash冲锋,Pro压阵。 日常查询和技术验证90%用Flash,只有遇到复杂Bug或者需要深度推理时,才切Pro。一天下来,API费用不到10块钱。
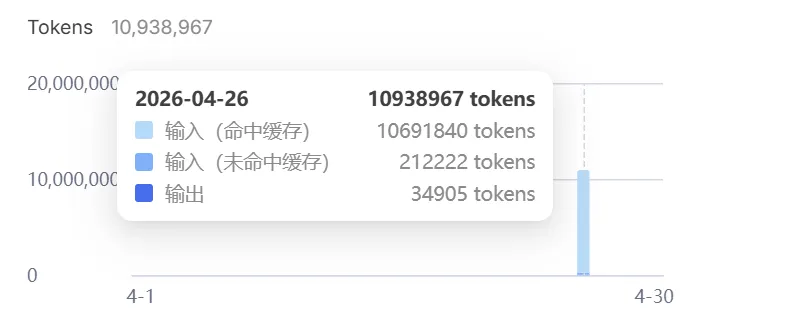
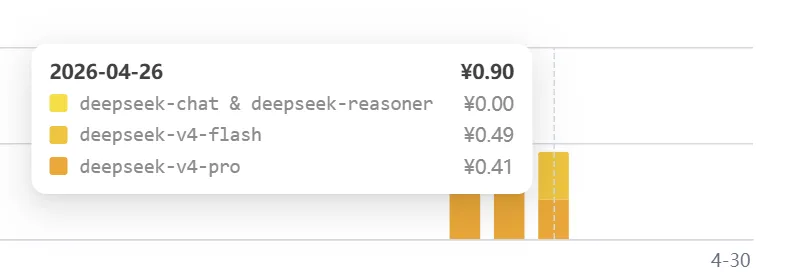
如果你也是主要做技术调研和验证,别被”1.6万亿参数”这个数字唬住。你大概率不需要那个。你需要的是快、便宜、够用。
不过说实话,即使打了折,V4跟国内那些Coding Plan(¥40-200/月包月)比,竞争力还是不大。毕竟人家是固定成本,你用多用少一个价,心里踏实。V4按量付费,月底一看账单,心里咯噔一下。
但你要是把目光放到国外——GPT-5.5(输入
不过,我有一个问题一直没想通——
这个”限时优惠”,有没有可能根本不是一个”促销”,而是下半年国产万卡集群全面铺开后的常态价,提前拿出来试水温?
你想想,如果答案是肯定的,那现在这个价格就不是”薅羊毛”,而是一个行业拐点的预告片。
最稀缺的,不再是算力
聊到这儿,我想到一个比喻:“电力 vs 电器”。
电力刚普及的时候,人们惊叹的是”有电了”。但真正改变生活的,是那些基于电力造出来的数不清的电器——冰箱、洗衣机、电视、空调。
当算力像电力一样变成基础设施,最稀缺的不再是算力,是想法。
以前大模型行业在拼”算力规模”——谁钱多、谁显卡多、谁模型大。但当DeepSeek-V4用1.6万亿参数跑在国产芯片上、把API价格打到全球最低的时候,这个游戏的规则已经变了。
执行力的价值在贬值,定义问题的能力在升值。
你有想法,算力跟得上。这才是这个时代最让人兴奋的事。
我的判断
说几个我个人对DeepSeek-V4的判断:
第一,这不是简单的模型升级,是一次算力主权的确立。 “中国模型+中国算力”这个公式,在V4上得到了完整验证。从今往后,国产算力不再只是”备胎”,而是可以支撑世界顶级大模型全生命周期的主力。
第二,价格还会降。 目前V4预览版的价格,是在昇腾950PR集群产能爬坡期的”尝鲜价”。等2026年下半年国产万卡集群全面铺开,DeepSeek大概率会再来一次”价格核打击”。Pro版降到个位数元/百万Token是完全可能的。
第三,全球AI生态正在分裂成两条路。 一条是CUDA体系(OpenAI、Meta、Google),一条是”昇腾+DeepSeek/Qwen/GLM”体系。这两条路不会完全割裂,但底层硬件的差异会越来越明显。对于开发者来说,这不是个问题——因为无论底层是什么,API接口都是OpenAI-compatible的,代码一行不用改。
第四,对普通人来说,这是好事。 算力自主化意味着API成本更可控、可预测,不会被国际供应链的波动影响。你会看到更多”以前算不起”的AI应用冒出来——给每个小学生配一个AI助教、给每个小店铺配一个AI客服、给每个独立开发者配一个AI合伙人。
我觉得这次的V4发布,最应该被记住的不是1.6万亿这个数字。
而是中国大模型产业,第一次完整地证明了这条路走得通——用自家的芯片训练自家的模型,把价格打到全球最低,然后开源给全世界。
这就是”自给自足”之后,才能有的底气。
发布会最后那句话,才是全文的魂
DeepSeek-V4预览版新闻稿的末尾,有一行字:
不诱于誉,不恐于诽,率道而行,端然正己。
十六个字,出自《荀子·非十二子》。放在一篇技术文档的结尾,不是附庸风雅,是DeepSeek的”君子宣言”。
不诱于誉。 R1震撼全球时被捧为”国货之光”,他们没被赞美冲昏。V4性能对标国际顶级,同样没有开发布会、没有喊”遥遥领先”,只发了一篇技术文档,还主动写清楚”与Opus 4.6思考模式仍有差距”。
不恐于诽。 过去一年,DeepSeek经历了人才流失、V4延期、被唱衰、被质疑抄袭。换别的公司,早出来开公关发布会了。他们没有。V4文档里直接写”受限于高端算力供给””推理吞吐受限”,不画饼,不遮掩。
率道而行。 这条”道”,是从CUDA全面迁移到华为CANN+昇腾950PR,从闭源转向Apache 2.0开源,从高价转向平民定价。不跟风参数竞赛,不搞短期对标。
端然正己。 最重的一句:把精力放在把自己做端正,而不是跟别人争辩。你做得好不好,比别人怎么说你,重要得多。与其解释,不如做事。
技术理想主义走到极致,就是这个样子。
看到这里,我想起了《庄子·逍遥游》里的一句话:
且举世誉之而不加劝,举世非之而不加沮。
全世界赞美你,你不会更加奋勉;全世界责难你,你也不会更加沮丧。
两千多年前的庄周和两千多年后的荀子,说的其实是同一件事:认定一条路,走下去,不为所动。