谁才是光之国?中美AI的最深层博弈,根本不是芯片!这2个冷门技术,正悄悄决定胜负
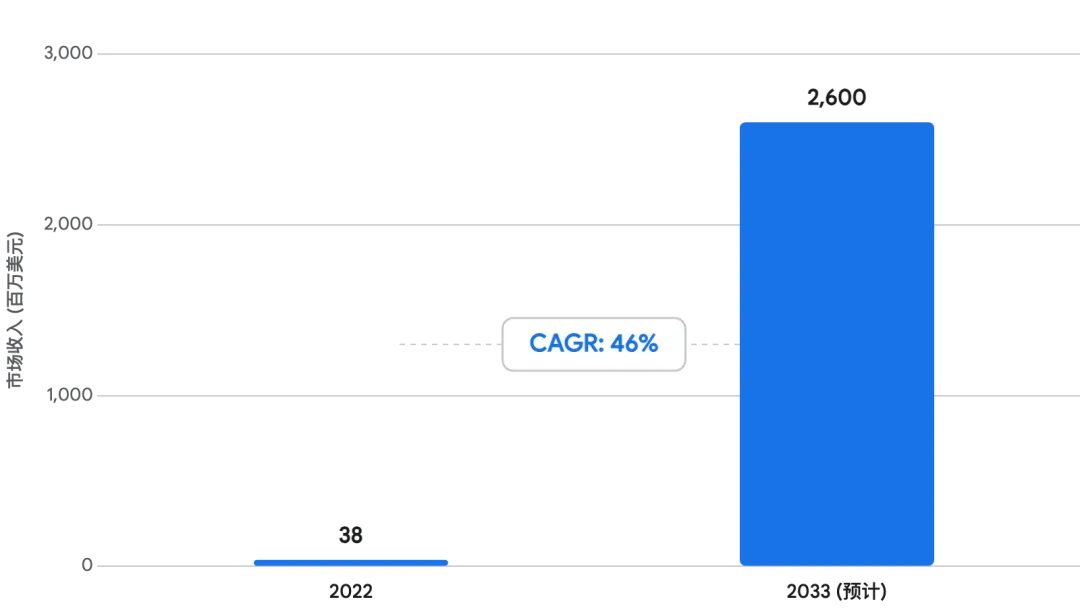
在当前以大规模语言模型(LLM)和生成式人工智能(Generative AI)为核心的技术浪潮中,全球数据中心正在经历一场从底层硬件到系统架构的深刻重塑。随着模型参数量级从千亿向万亿乃至十万亿级别跨越,支撑这些模型训练与推理的高性能计算(HPC)集群规模呈现出指数级的扩张。在这一演进过程中,单颗计算芯片(如GPU、TPU及各类专用ASIC)的算力固然重要,但制约整个集群性能瓶颈的短板已经发生了根本性的转移——从单纯的“计算能力”转向了“数据传输带宽”与“极端热量管理”。 现代算力网络面临着两大不可逾越的物理壁垒:其一是“带宽与功耗墙”,即如何在极高的端口速率下,以极低的功耗实现海量数据的无延迟互联;其二是“热力学墙”,即如何在单机柜功率密度成倍飙升的有限空间内,将计算芯片产生的庞大废热高效安全地排出。为了突破这两大壁垒,光互联技术(从传统光模块向线性驱动LPO与共封装光学CPO的演进)与高密度热管理技术(从传统风冷向冷板式及浸没式液冷的跨越)应运而生。这两者不仅构成了下一代数据中心的基础设施底座,更决定了未来人类社会算力扩展的物理天花板。本报告将对光模块、CPO以及液冷技术的核心原理、演进路径、产业化进程及其深层协同效应进行全景式的深度剖析。 一、 光互联的物理基础与传统光模块的演进局限 在现代数据中心的海量数据交互中,传统的铜缆和印刷电路板(PCB)走线已经越来越难以满足高速率信号的传输需求。当电信号的传输速率达到较高频段时,会遭遇严重的趋肤效应(Skin Effect)和介质损耗(Dielectric Loss),导致信号完整性在极短的距离内急剧衰减。为了解决这一问题,光互联技术成为了数据中心内部及数据中心之间(DCI)大容量传输的唯一可行方案。 1. 光模块的核心机制与关键光组件技术 光模块(Optical Transceiver Module)是实现光电转换的绝对核心器件。它的基本工作原理是:在发射端,将来自交换机或服务器芯片的高速电信号通过驱动电路放大,驱动激光器(如VCSEL、EML或硅光芯片)将电信号调制转换为光信号,并耦合进光纤中传输;在接收端,光探测器(如PIN或APD)将接收到的光信号转化为微弱的电信号,再经过跨阻放大器(TIA)和限幅放大器等电路处理,还原为标准的高速电信号输入给数字系统。 随着算力网络从400G向800G乃至1.6T速率的大跨步演进,光模块内部的核心光组件与封装工艺正在经历前所未有的技术创新。根据当前高速收发模块及光互联组件的产业化进程,有几项关键的底层支撑技术尤为突出: WDM波分复用器 (Wavelength-Division Multiplexing): 在物理光纤资源有限的前提下,为了成倍提升单根光纤的数据吞吐量,WDM技术成为了行业标准。该技术允许在同一根单模或多模光纤中,同时并行传输多个不同波长(即不同颜色)的光信号,且彼此之间互不干扰。在高速光模块内部,波分复用器负责将多路不同波长的光信号合并送入发送光纤,而解复用器则在接收端将含有多种波长的光信号分离至不同的接收通道,从而极大提升了光互联的带宽密度。MCF多芯光纤组件 (Multi-Core Fiber): 传统的光纤结构中,一个玻璃包层内部仅包含一个导光的纤芯。而MCF技术属于空间分分复用(SDM)技术的前沿领域,它在一个标准的物理包层内,通过精密的拉丝工艺集成了多个独立的、可平行传输光信号的波导纤芯。多芯光纤组件的应用,能够在不增加数据中心光缆布线体积和物理空间占用率的情况下,成数量级地提升横截面数据吞吐量,是应对未来超大规模AI集群高密度互联的终极物理层方案之一。PLC光分路器 (Planar Lightwave Circuit): PLC即平面光波导技术,这是一种基于半导体集成电路制造工艺的光学器件加工技术。通过在硅基或石英基底上刻蚀出微米级的光波导结构,PLC光分路器能够在中低制造成本下,实现多通道光信号的高精度、高一致性功率分配与复杂路由。在高度集成的光网络节点与下一代硅光子集成芯片中,PLC扮演着不可或缺的光信号调度角色。2. 前面板可插拔架构的物理衰减与功耗危机 纵观过去十余年的数据中心发展史,网络交换机和服务器普遍采用的是“前面板可插拔”(Pluggable)架构。在这种架构形态下,光模块作为一个独立封装的硬件单元,插入设备前面板的物理笼子(Cage)接口中。而负责数据交换和网络路由的核心交换芯片(ASIC)则被牢牢焊接在设备主板的中央位置。 这一物理布局带来了一个极为严峻的工程挑战:由交换芯片产生的高速电信号,必须穿过长达十几厘米甚至几十厘米的PCB铜走线(Copper Traces),才能到达位于前面板的光模块。在10G、40G乃至100G时代,这种长距离PCB走线带来的信号插入损耗尚在可控范围内,可以通过采用更高级别的板材(如Megtron 6/7)来进行弥补。 然而,当端口速率跃升至800G及以上时,高频电信号在PCB中的传输损耗呈非线性剧增。为了保证电信号在到达光模块时依然具有足够高的信噪比和清晰的眼图,传统高速光模块内部必须强制集成一颗高功耗的数字信号处理器(DSP)芯片。DSP利用复杂的数字算法对严重衰减的信号进行均衡(Equalization)、重定时(Retiming)与前向纠错(FEC)补偿。尽管DSP保障了信号完整性,但它直接导致了整个网络系统的功耗和传输延迟大幅上升。在某些800G可插拔光模块中,仅仅DSP一颗芯片就占据了整个模块功耗的一半以上。在数以万计光模块互联的AI智算集群中,这种由DSP带来的功耗叠加和纳秒级延迟累积,成为了限制算力规模继续扩展的核心掣肘。 二、 突破互联瓶颈:从LPO到CPO的架构重塑路线图 面对传统可插拔光模块在功耗、散热和信号完整性上面临的“三座大山”,全球半导体与光通信产业界并未坐以待毙,而是开辟了两条并行且极具针对性的技术演进路线:线性驱动可插拔光学(LPO)与共封装光学(CPO)。需要明确的是,这两者在短期内并非零和博弈的替代关系,而是在不同商业化时间节点、不同网络拓扑距离下的互补竞争组合。 1. LPO (Linear Drive Pluggable Optics):可插拔阵营的极致做减法 线性驱动可插拔光学(LPO)技术代表了在不改变现有物理网络架构前提下,对传统可插拔形态进行的极限优化。LPO技术的核心创新理念非常直接——彻底移除光模块内部高功耗、高延迟的DSP芯片 。 在LPO架构中,光模块内部不再进行复杂的数字信号重整,仅仅保留了高线性度的跨阻放大器(TIA)和激光器驱动器(Driver)等纯模拟组件。原本由模块内DSP承担的繁重信号均衡与恢复工作,被全部转移并交由交换机或GPU主芯片上的高速串行器/解串器(SerDes)来集中处理。 这一“做减法”的设计为系统带来了立竿见影的收益。首先,由于去除了DSP,LPO模块的整体功耗相比传统DSP光模块下降了约50%,大幅缓解了交换机前面板的散热压力;其次,纯模拟信号通路的建立去除了数字信号采样的过程,使得模块内部的处理延时降至皮秒级别,实现了无可比拟的极低网络延时,这对于对延迟极其敏感的AI分布式训练系统而言具有极高的价值。 商业化地位与适用场景评估: 从系统集成的角度来看,LPO最大的商业优势在于其保留了传统“前面板可插拔”的物理形态。这意味着数据中心运营商无需更改现有的网络架构、机架设计以及运维习惯,便能实现向低功耗互联的平滑过渡。因此,在未来1至3年的短期与中期时间窗口内,可插拔模块(不仅包含LPO,也包含采用更先进DSP向1.6T速率演进的传统模块)凭借其高度成熟的供应链生态和即插即用的灵活性,仍将稳固占据数据中心光互联市场的主流地位。然而,LPO技术的物理局限性同样明显。由于剥离了模块端的数字信号修复能力,电信号在较长距离传输中的抗衰减和容错能力显著降低。因此,LPO的最佳落地应用场景被严格限定在中短距离的互联中,例如同一机柜内部(Intra-rack)的GPU互联,或物理位置相邻机柜间的顶层交换机(ToR)连接。对于长距离的园区网或长距数据中心互联,依然需要依赖具备完整DSP能力的传统光模块。 2. CPO (Co-Packaged Optics):算力纵向扩展的终极颠覆 如果说LPO是对现有架构的改良,那么共封装光学(CPO)则是对数据中心底层互联物理形态的彻底颠覆。CPO技术从根本上打破了“核心交换芯片在主板中央、光互联模块在边缘面板”的长距离分散布局。其核心理念是通过先进的半导体封装工艺,将光互联产品(包括高速收发光引擎、光电转换模块以及CPO光组件)直接与核心网络交换芯片或GPU计算芯片高密度地封装在同一块先进的系统级基板(Substrate)上 。 这种极高密度的2.5D或3D晶圆级封装方案,将核心计算硅片到光通信引擎之间的电信号走线距离,从传统可插拔架构下的十几厘米,暴力压缩至惊人的几毫米。电传输距离呈数量级的急剧缩短,从物理底层彻底改变了高速信号的阻抗与衰减特性。在如此短的距离内,高频电信号几乎不发生畸变,从而从根本上消除了对复杂DSP芯片重度电信号补偿和高功率模拟驱动的需求。这一架构跃迁使得单比特数据的互联能耗(pJ/bit)降至传统架构的几分之一,达到了前所未有的最优能效比状态。 CPO的产业化进程与市场规模深度洞察: 长期以来,CPO被视为一项前瞻性的概念技术,但随着当前AI大模型对跨节点数据吞吐率的要求呈现无节制的非理性增长,AI计算芯片的加速迭代正在以前所未有的力度强力驱动并缩短CPO产业的商业化落地进程。行业的深度分析与市场追踪数据显示,CPO架构已经进入了明确的商业化倒计时与爆发前夜:商用时间表的提前: 业界顶尖机构及供应链动态一致预期,CPO技术有望于2024年至2025年这一关键时间窗口内,正式开始突破实验室阶段,进入早期商业化部署与商用应用阶段。这一进度比早年业界的普遍预测提前了数年。爆发式攀升的端口渗透率: 随着生态圈的逐步成熟,全球CPO端口的销售量预计将呈现出惊人的爆发式增长轨迹。数据显示,从2023年仅有约5万个端口的试探性部署,到2027年,全球CPO端口的出货量将飙升至450万个端口。更为关键的是,在2027年这一重要节点,CPO端口在面向高端互联的800G及1.6T产品出货总数中,占比将接近30%,这意味着CPO将真正跨越鸿沟,成为高端市场的一股不可忽视的核心力量。长周期的千亿级市场规模展望: 根据权威行业分析机构Yole的报告数据预测,CPO市场正酝酿着巨大的财富效应与产业价值。虽然在2022年,CPO市场仅处于极早期的萌芽阶段,产生的总收入约在3800万美元左右,但预计到2033年,该市场的全球总规模将达到惊人的26亿美元。在2022年至2033年长达十年的预测期内,该市场的复合年增长率(CAGR)将高达46%,展现出极为强劲的长期上升动能。Yole的进一步评估指出,CPO技术路线将在2027年至2029年进入规模化的试产(Pilot Production)爬坡期,并于2029年前后全面冲破技术与良率壁垒,正式步入大规模量产(Mass Production)阶段。在长期的战略视角下考察,尤其是展望2026年及其后更远的未来,随着千亿乃至万亿级AI计算集群规模的持续无界扩张,单体网络拓扑的复杂度将呈指数级上升。在这样的极端场景下,CPO技术凭借其在超高能效比、极低延时和极致物理带宽密度上的绝对护城河优势,预计将当之无愧地成为AI纵向扩展(Scale-up网络,指同一集群内部节点间的超高速互联)的最佳乃至唯一可行解决方案。该技术演进路径将首先在对带宽与延迟性能要求最为严苛的高端超级计算中心与核心AI训练集群市场站稳脚跟,经过充分的验证与成本摊薄后,进而实现向更广泛的规模化通用数据中心应用市场的全面渗透。 为了更为直观地展示光互联架构演进的脉络与各自的优劣势,下表对三种主要技术路径进行了结构化的深度横向对比:
技术路线架构 核心物理特征与封装方式 对DSP芯片的依赖程度 功耗与传输延迟表现 最佳系统级适用场景 商业化成熟度与市场预期
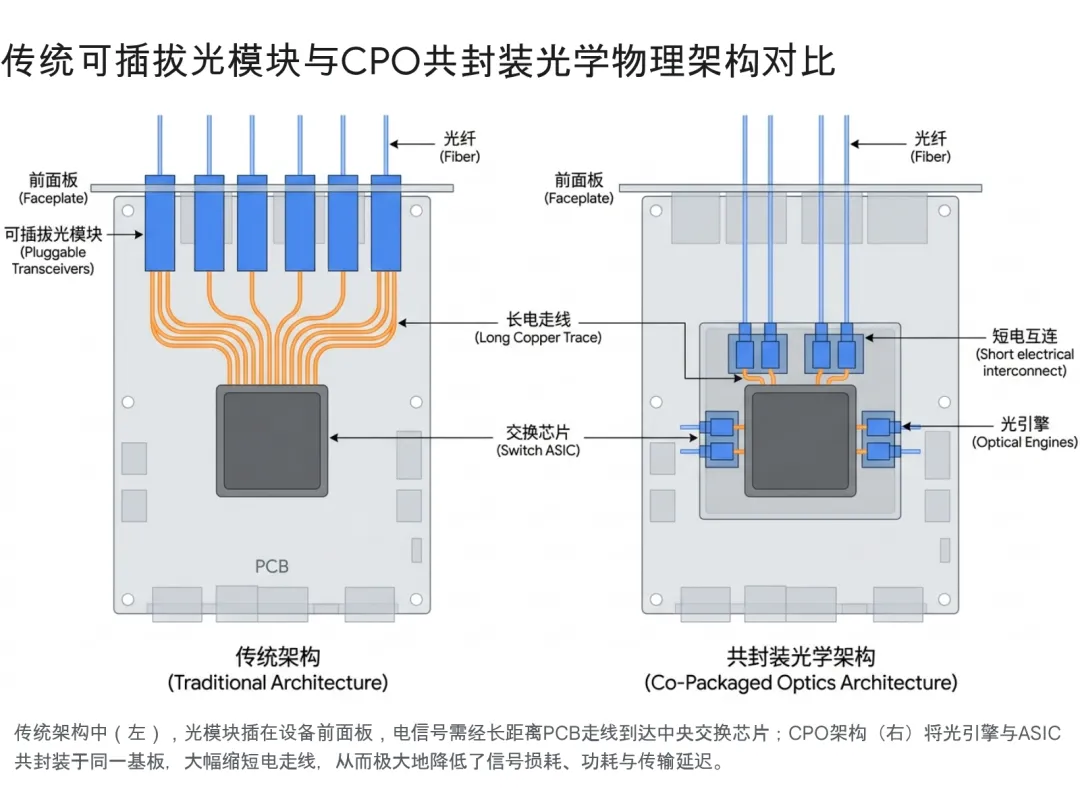
传统可插拔光模块 前面板独立拔插模块,需经过长距离PCB电走线连接主芯片 必须强制集成高性能、高功耗DSP进行信号修复 整体功耗偏高,存在数百纳秒级的数字处理延迟 适用于通用数据中心、中长距DCI互联及广域网 当前市场绝对主流,生态极其成熟
LPO (线性驱动模块) 保持前面板可插拔形态,但内部全面移除DSP芯片 极低,仅保留模拟器件,信号补偿完全依赖主控ASIC芯片 功耗大幅下降,实现皮秒级极低物理延迟 机柜内部高速直连或物理相邻机柜间的短距互联
未来1-3年内与传统可插拔共存的主流方案
CPO (共封装光学) 光电引擎与核心计算芯片直接在晶圆级基板上实现3D共封装 无或极低,超短电走线彻底消除了长距电补偿的需求 达成极致能效比,实现近乎零电学损耗的极致低延迟 面向未来超大规模AI集群的纵向扩展(Scale-up)网络
2024-2025年开启商用,预计2029年规模量产
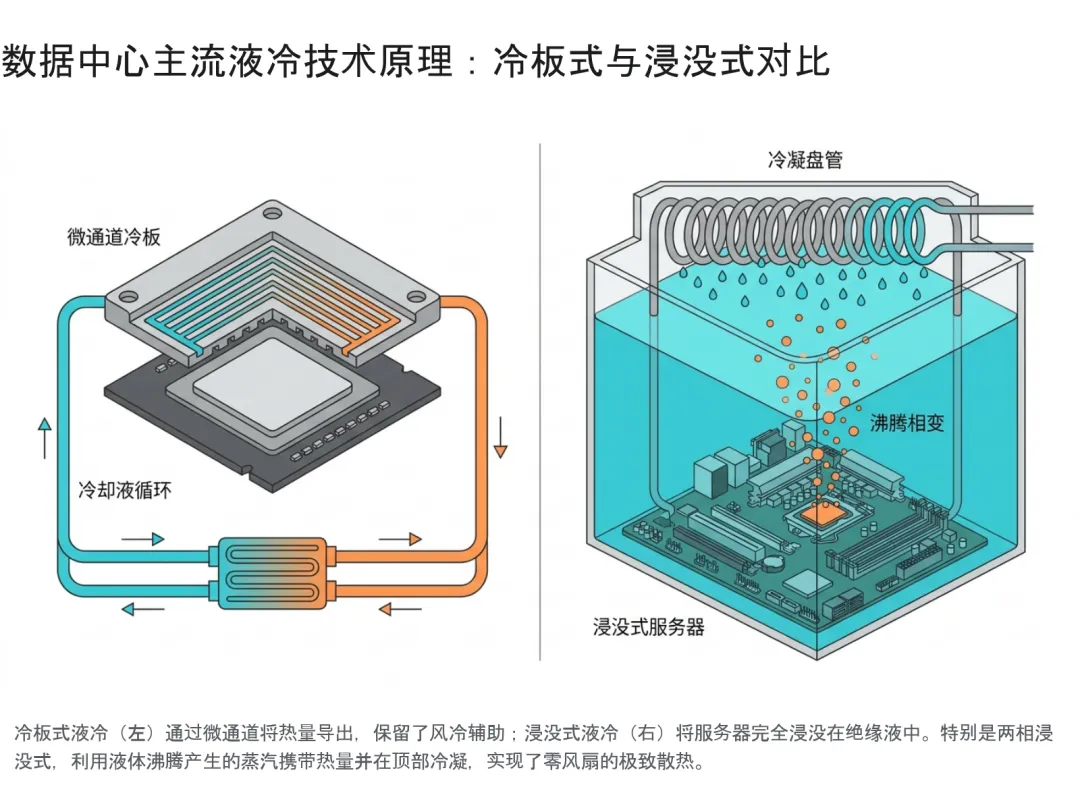
三、 突破“热力学墙”:数据中心液冷技术的历史必然性 在探讨完数据传输带宽的演进后,我们必须面对支撑算力跃升的另一大支柱——物理散热。无论是采用先进制程工艺提升单颗硅片上晶体管的绝对密度,还是采用前文所述的CPO架构将极高密度的光引擎直接紧压在核心逻辑芯片周围,这些技术创新都在不可逆转、甚至极其猛烈地推高单体芯片的局部热通量(Heat Flux)以及机柜整体的设备功率密度。 在生成式人工智能(AI)与传统高性能计算(HPC)业务的双重驱动浪潮下,数据中心基础设施面临着严峻的物理考验。根据维谛技术(Vertiv)的行业白皮书揭示,数据中心单机架的功率密度已经从过去十年的传统标准(约为10kW至20kW),急剧攀升并突破至50kW甚至追求满足更高极限要求的机架部署。在如此极端的巨量发热量面前,传统的空气冷却系统(风冷)无论如何增加空调送风量、扩大精密空调机组体积,抑或是采用更夸张的金属散热片,都已不可避免地触及了热力学的物理极限边界。风冷系统在面对高热密度机架时不仅显得力不从心,更会导致极其庞大的能源浪费、极高的运行噪音与不可控的系统性宕机风险。 1. 液冷技术重塑TCO体系与核心系统优势 面对风冷体系的逐渐崩塌,液冷系统成为了不可逆转的行业选择。液冷技术利用水、氟化液或其他特殊合成绝缘导热流体,代替传统的空气作为传热的核心介质。由于液体(例如水)的比热容和导热率远高于空气(水的导热率大约是空气的数千倍以上),液冷能够以一种更为高效、更具热力学经济性的方式,极其迅速地带走高热密度机架内聚集的庞大热量。这种从“气态传热”向“液态传热”的基础转变,为数据中心带来了全方位的系统性优势重塑: 彻底消除热失控,释放极致计算性能: 在当前高负载运作下,随着现代CPU与GPU的底层外壳温度不断逼近芯片的最高安全工作温度阈值(采用传统风冷时,一旦执行密集计算,这种临界状态几乎不可避免地会发生),芯片内置的硅级保护机制会被强行触发,迫使芯片进行大幅降频(Thermal Throttling)以抑制内部发热。这种性能抑制是对昂贵AI算力资源的极大浪费。液冷技术通过极高的热移除效率,能够在芯片发热的瞬间将其转移,从根本上避免了热失控现象的发生。液冷方案允许极其密集排列的AI服务器系统在其设计的最大允许电压和最高时钟频率下,实现连续、稳定、不间断地狂飙运行,同时绝对确保不发生过热停机故障,从而最大化了IT硬件的算力输出潜能和整体系统可靠性。重塑物理建筑空间结构与部署密度极限: 传统风冷数据中心需要在机房内部预留极为广阔的冷通道、热通道空间,以及庞大的机房空调送风管道。而高密度的液冷架构可以在极其有限、甚至苛刻的物理空间内,完美支持处理最密集的边缘计算应用(Edge Computing)与集中式的AI算力孤岛核心节点。液冷能够轻松支撑50kW乃至百千瓦级别的高要求机架部署,这使得数据中心运营商能够在同等建筑占地面积、甚至更小的边缘机房内,容纳成倍增长的算力总和。总体拥有成本(TCO)计算逻辑的根本性逆转: 尽管液冷在初期引入时,配套的管路改造、歧管分配系统及冷却介质的基础设施建设成本相对较高,但从全生命周期来看其经济效益显著。美国采暖、制冷与空调工程师学会(ASHRAE)针对传统风冷数据中心与混合模型(风冷与液冷协同)数据中心进行了极为详尽、严谨的总体拥有成本对比分析。研究结果明确揭示了一个关键的行业风向标:尽管在复杂的数据中心环境中,有许多独立的变量会影响总体拥有成本(TCO),但“液冷技术最终能够通过带来成倍增加的机架密度、更多地利用免费的自然冷却能力(Free Cooling,因为液冷系统允许使用较高温度的回水进行热交换,大幅减少了压缩机开启时间)、显著更优异的IT计算性能以及无可比拟的每瓦特算力性能(Performance per Watt),实质性地为运营商创造了改善并大幅降低整体TCO的巨大战略机会。”此外,部分极为激进的液冷技术(如浸没式方案)通过创新的零风扇设计,大幅度削减了服务器节点自带高速风扇群的庞大电耗,是目前已知最为省电、PUE(电能利用效率)表现最为高效环保的液冷方式。四、 数据中心液冷技术路径体系与工作原理图解 根据导热流体与服务器内部发热电子元件的具体接触方式,以及流体在吸收热量过程中是否发生热力学相变特征,现代数据中心液冷技术体系主要演化出了两类占据绝对核心地位的技术流派:冷板式液冷(Cold Plate Liquid Cooling)与浸没式液冷(Immersion Liquid Cooling)。同时,为了实现风冷向液冷的平滑演进,还衍生出了辅助性的热管背板热交换器等混合技术方案。 1. 局部精准打击:冷板式液冷 (Cold Plate Liquid Cooling) 冷板式液冷被业界视为一种非直接接触式的局部精确液冷方案。其核心工作原理是将经过精密流体动力学定制设计的金属冷板(通常由高纯度铜或铝合金制造,内部刻有复杂的微通道)直接紧密安装并贴合在服务器内部产生极高热量的核心计算组件(如CPU处理器、GPU加速卡、高频内存模块)的晶片封装表面之上。在整个循环过程中,冷却液体被严格密封在系统管路内,仅在冷板内部封闭的微通道网络中高速循环,通过金属极佳的热传导特性,将组件表面的热量持续不断地带走。 根据内部冷却介质的物理状态变化,冷板式技术进一步细分为两个不同技术维度的分支: 单相冷板液冷 (Single-Phase Cold Plate): 这是目前商业化部署最为成熟、应用最广的液冷技术。系统通常使用经过高度净化的水与乙二醇的按比例混合物,或者特定的绝缘合成冷却液作为循环介质。在运行过程中,流体始终保持在液态,不发生沸腾相变。冷却液流经高温微通道冷板吸收庞大热量后,其自身物理温度显著升高(此过程依靠显热传热原理),随后这些携带高热能的液体通过管道被输送至机架旁的冷却液分配装置(CDU)中。CDU内部的热交换器将热量转移至二次侧的水冷系统(如室外冷却塔),降温后的液体再被重新泵送返回服务器机架进行闭环循环。两相冷板液冷 (Two-Phase Cold Plate): 这是面向未来更高极端发热量设计的进阶方案。该系统摒弃了水基液体,转而采用沸点极低(通常在几十摄氏度)的特殊绝缘冷却介质(如某些氟化液)。系统运作时,低压冷却液被泵入服务器冷板,当其接触并吸收服务器核心产生的巨大热量时,冷却液在微通道内瞬间发生剧烈的相变(即汽化沸腾)。热量以潜热释放的形式被大量蒸汽高速带走,随后这些气态蒸汽在系统外部的冷凝器中接触冷源重新冷凝回液态,并再次交回机架外部循环使用。两相冷却由于利用了液相变汽相时吸收的庞大汽化潜热,其单位物理体积的极限热移除能力远远强于传统的单相显热冷却。冷板式架构的先天局限与混合冷却的必然性: 尽管冷板式液冷在解决核心芯片的定点散热上表现卓越,但其在工程实践中面临着一个不可忽视的挑战——即其“散热覆盖率”的天然不完整性。冷板技术要求发热表面必须相对平整且具有统一的高度规范,因此它通常只能有效带走整个机架内核心计算设备所产生热量总和的约70%至75% 。在高度复杂的服务器主板上,还散布着大量形状不规则、高度参差不齐的辅助发热组件,诸如电源转换模块(VRM)、各类IC电容器、网卡芯片以及存储固态硬盘等。冷板根本无法有效地全面贴合覆盖这些不平整的零散组件。正是基于上述物理限制,当前采用冷板式液冷路线的数据中心几乎无法做到彻底抛弃传统风扇。系统架构设计必须采用**“液冷主导核心区域 + 风冷辅助周边区域”的混合冷却协同方法**来进行整体统筹工作,利用保留的系统风扇产生的空气气流,来解决机箱内部剩余约30%的辅助发热组件的散热需求。 下表详细对比了冷板式液冷不同技术路线的运作机制与局限性:
冷板液冷技术路线 核心热力学机制 冷却介质物理状态 整体机架热量捕获比例 对机箱风扇的依赖性 部署管路复杂度及技术挑战
单相微通道冷板 依赖金属传导及液体升温显热 循环过程中始终保持纯液态 约 70% – 75% 强制需要(需辅以风冷系统)
中等难度(主要挑战在于微小管路接头的漏液防护)
两相微通道冷板 依赖金属传导及液体汽化潜热 在冷板处发生液相变汽相 约 70% – 75% 强制需要(需辅以风冷系统)
高难度(涉及系统内的低压蒸汽管理与冷凝回收)
2. 终极散热形态:浸没式液冷 (Immersion Liquid Cooling) 浸没式液冷在工程理念上实现了彻底的颠覆,代表了未来超高算力数据中心机房物理形态的终极演进方向。在该颠覆性架构下,传统的机架结构被彻底抛弃,服务器裸板及其机架中的所有相关电子辅助组件被水平或竖直地完全、直接地浸泡在具有优异导热性能且绝对绝缘的特殊化学冷却液体池(Tank)中。在这一体系下,热量不再需要经过导热硅脂和金属冷板的低效中转传导,而是直接从所有发热硅片和电子元器件的微观表面直接传递给周围包裹的液体流体。这种无死角的接触方式,实现了理论上逼近 100% 的极致热量捕获率。 单相浸没式液冷: 在这种系统设计中,高度定制化的服务器设备通常被竖直密集安装在充满绝缘导热液体的大型特制冷却槽(Tank)内部。液体直接充当传热介质接触组件并大量吸收发热量。受热后的液体由于密度变小而自然上升,通过物理对流循环(或水泵辅助驱动)进入冷却液分配装置(CDU)内部的水冷热交换器中进行降温。被二次侧冷却水带走热量而降温后的液体,再次流回Tank底部完成闭环。根据机房布局需求,CDU的工程设计展现出极高灵活性,既可以直接安装在大型Tank的附近空间、机房外部,甚至可以被精巧地高度集成在封闭的“微型”Tank内部单元中。两相浸没式液冷: 这是目前物理界公认散热密度上限最高、且被动冷却效率最为极致的前沿技术。它要求使用沸点极低的昂贵绝缘介质(如沸点约为50°C左右的电子氟化液)。系统运行过程中,当浸没在其中的服务器CPU等高发热组件开始运转并产生高温时,紧密接触表面的液体会迅速达到沸点并立即剧烈沸腾,发生由液相到汽相的直接相变。这一过程会产生大量密集气泡并极速上升,汽化过程吸收了极其庞大的相变潜热。上升的高温蒸汽在Tank顶部特设的密集冷凝盘管(盘管内部通常循环通有常温或外部环境的冷却水)区域遇冷。蒸汽在此处释放热量,重新冷凝液化成微小的液滴,并在物理重力的作用下如“降雨”般自然下落,重新汇聚回Tank底部的水体中,形成一个极其高效且完全自驱动的完美热力学循环。浸没式的极致革命与实施层面的工程挑战: 无论是单相还是两相,浸没式液冷架构为数据中心带来了最大的范式突破在于其实现了真正意义上的**“零风扇设计”**。由于设备处于绝缘液体包裹中,完全不需要任何形式的外部空气对流流动,因此服务器主板从硬件设计之初,就彻底砍掉了所有用于强排风的庞大散热风扇模块。这一革命性举措不仅在物理层面上彻底消除了由于成千上万风扇狂转带来的高频扰流噪音(使得机房环境异常安静),更极为可观地节省了原本被风扇消耗的庞大无用电耗(在传统风冷高密服务器中,仅仅风扇的功耗就能占到整机功耗的10%至20%),从而将整个数据中心系统的能源利用率(PUE指标)推向了逼近理论极限的完美状态。然而,先进技术同样伴随着严苛的落地要求。在实际的商业化落地进程中,部分浸没式技术(特别是追求极致效率的两相浸没式液冷)面临着一系列复杂的工程与合规挑战。首先,两相液冷所依赖的低沸点含氟相变介质通常造价极为昂贵,极大地拉高了初期的单机柜建设成本。其次,由于这种沸腾液态介质极易在常温常压下挥发为气态流失,且部分氟化液材料在长期的环境保护和全球化学品安全合规方面面临持续审查。因此,工程实施上强制要求盛放冷却液的大型Tank不仅要具有极高的承重强度,更必须做到结构上的绝对高度密封,以最大限度地杜绝和减少昂贵气态蒸汽的逃逸流失,同时防范潜在的环境污染和安全隐患风险。 3. 平滑演进的桥梁:辅助融合的热管背板热交换器 在大多数传统存量数据中心从纯风冷向全液冷的渐进式改造过渡进程中,很难一步到位地推翻现有IT资产去直接上马冷板或浸没液冷。此时,热管背板热交换器(Rear Door Heat Exchanger, RDHx)设备扮演着极为关键、实用且低风险的工程桥梁角色。尽管从严格的技术分类学上讲,背板热交换不属于直接贴近芯片、让冷却液体直接进入服务器机箱内部的直接液冷范畴,但它毋庸置疑是当前构建高密度混合冷却基础设施集成的核心重要组成部分。 其物理核心原理相对简单而直接:利用一扇内部预埋了密集水冷冷却盘管的定制换热门,直接替换掉标准数据中心机柜原有的排风后门。这种背板设备在工业应用中主要分为两大类:第一类是被动式背板,其完全依靠服务器主机自身内置的高速风扇所产生的强制风压,将吹过高温芯片的炽热排气流强行压过背板后门的冷凝盘管。热空气穿过盘管瞬间被冷却水夺走庞大热量,排向机房的热量被大幅削弱;第二类则是性能更为强悍的主动式背板,换热器后门上不仅布满盘管,自身还额外加装了强力的高速引风风扇阵列。它能主动且强劲地从机架后部大量吸入并加速抽离服务器排出的超强热气流,极大提升了热量带走效率。作为传统风冷向高级液冷过渡时混合冷却方案的坚实基础底座,背板空调展现出了卓越的向后兼容能力,它能够有效且稳妥地为热密度达到20kW及以上的高端风冷机柜提供强大的后盾散热支持,是目前众多存量风冷数据中心在不改变IT服务器内部架构前提下,实现高密度算力升级改造的最优选方案。
浸没与背板技术路线 核心热力学捕获机制 对系统风扇的依赖性 机架系统热量捕获比例 硬件与介质挑战 冷却介质循环工作状态
单相完全浸没液冷 液体包裹直接接触,依赖对流显热 彻底摒弃,完全无需风扇 逼近 100% 极限 面向主板材料的绝缘兼容性测试,流体本身的巨大静态重量要求机房高承重 系统内始终保持液态循环
两相完全浸没液冷 液体包裹直接接触,依赖直接沸腾潜热 彻底摒弃,完全无需风扇 逼近 100% 极限 需要极其昂贵的特种介质,Tank系统必须实现极致绝对密封以防气相逃逸泄漏
在机柜内部不断进行激烈沸腾汽化与冷凝液化的相变循环
机柜背板热交换器 通过密闭盘管实现气流到液体的二次热交换 严重依赖服务器原生排气风扇或背板自带风扇 面向整个机架级后端的排气冷却总汇 实施难度较低,仅需改造现有物理机柜后门及接入机房水管即可
密闭盘管内部水流始终保持液态
五、 深度交叉洞察:CPO共封装光学与极地液冷技术的必然协同与未来形态 纵观整篇报告对底层物理传输介质与热力学架构的深度解构,在深入剖析未来计算基础设施的技术图谱后,我们不难得出一个极具前瞻性的宏观洞察:网络互联架构中光模块向CPO(共封装光学)的终极演进,与热管理工程架构中传统风冷向极致浸没式液冷(或高密冷板)的历史性跨越,这二者在产业界绝非两个平行且孤立演进的独立技术事件,而是存在着极其强烈的底层物理因果关联与技术共生的必然性。 在宏观应用维度上,生成式AI大模型的“暴力美学”建立在无尽海量参数的底层并行计算架构之上。这种架构严苛地要求现代数据中心在持续堆砌、追求极高单芯片算力密度的同时,必须绝对具备无缝、无延迟、超大吞吐量的集群节点间横向与纵向数据交换能力。当半导体与光通信行业为了彻底解决铜缆物理瓶颈,试图通过推行CPO技术解决这种数据带宽饥渴时,将功耗极大的硅光收发引擎与本身发热就已逼近极限的高算力ASIC主控逻辑芯片紧密封装在面积仅有几平方厘米的同一块薄片基板上,不可避免地引发了局部微观物理区域内极端、恐怖的热通量(Heat Flux)聚集。在如此微小且密闭的3D封装物理空间内,传统哪怕再强劲的空气风冷系统,也已经完全无法有效剥离每平方厘米高达数百瓦乃至上千瓦的极端废热。这就从物理定律层面得出了一个死循环与破局点:CPO技术的全面、大规模商用落地,在物理层面上必须且只能以前置部署极高换热效率的现代液冷系统(特别是能够贴片压制热点的高密度微通道两相冷板,或是具备极高潜热吸收能力的直接两相浸没式液冷)作为其最底层的先决基础设施条件。 离开了液冷系统保驾护航,CPO芯片会在极短时间内因高温烧毁而失效。 从硬币的另一面反过来看,液冷设施(尤其是全场景浸没式液冷技术)在超大规模数据中心的全面规模化应用部署,也反向极大地释放了服务器主板硬件设计布局的传统物理尺寸约束。过去几十年里,硬件系统工程师为了迁就风冷架构,不得不采用庞大笨重的金属鳍片散热器,并刻意在主板元件之间拉开距离以规划强力风道布局。当液冷彻底接管热力学挑战、摆脱了这些风道和散热器体积的束缚后,硬件工程师终于得以彻底放开手脚,进一步无所顾忌地压缩服务器主板物理尺寸,极度缩短计算核心到外部IO接口的物理电学信号走线距离。这种主板设计的极致微缩化趋势,反过来又为CPO这种追求极致3D高密度光电共封装的先锋技术,提供了最为完美、也是唯一可行的宿主级硬件生存环境。 总结而言,站在AI算力爆发的历史交汇点上展望未来3至5年的技术蓝图,随着传统可插拔光模块逐步触及高频信号传输与内部DSP功耗的物理极限,以及单机柜功率密度在万卡集群建设中向50kW乃至100kW+高歌猛进,CPO共封装光学与先进制程液冷架构这两条看似平行的赛道,必将走向深度的底层技术融合。这种通信层面极简高密光互联与物理层面极致液相导热的无缝对接,将成为构筑下一代AI万亿参数智算网络不可逾越的“双引擎”底座。这条充满挑战与颠覆的技术演进之路,不仅将彻底重新定义全球数据中心建设的绿色能效(PUE)绝对标准,更将深刻决定在这一轮波澜壮阔的全球通用人工智能(AGI)算力军备竞赛中,谁能掌握基础设施底层核心架构的绝对定价权与物理竞争力天花板。
 夜雨聆风
夜雨聆风