 夜雨聆风
夜雨聆风





22.1K+ star 的 AI 编程记忆工具:让 AI 任务追踪从金鱼变成大象
你用 AI 编程工具做过长任务吗?做到一半,它突然忘了前面定好的计划?或者多轮对话之后,上下文中塞满了各种临时备注,连它自己都分不清哪个是真正的待办、哪个是随便说说?
这其实是 AI 编程工具的一个核心缺陷:它们没有持久化的、结构化的记忆。对话结束,记忆就消失了;上下文里塞满的 markdown notes,没有依赖关系、没有优先级、没有追踪。
Beads 做的事:给你的 AI 编程工具接上一个带版本控制的结构化记忆层,把混乱的 markdown 计划替换成一张依赖感知的任务图谱。
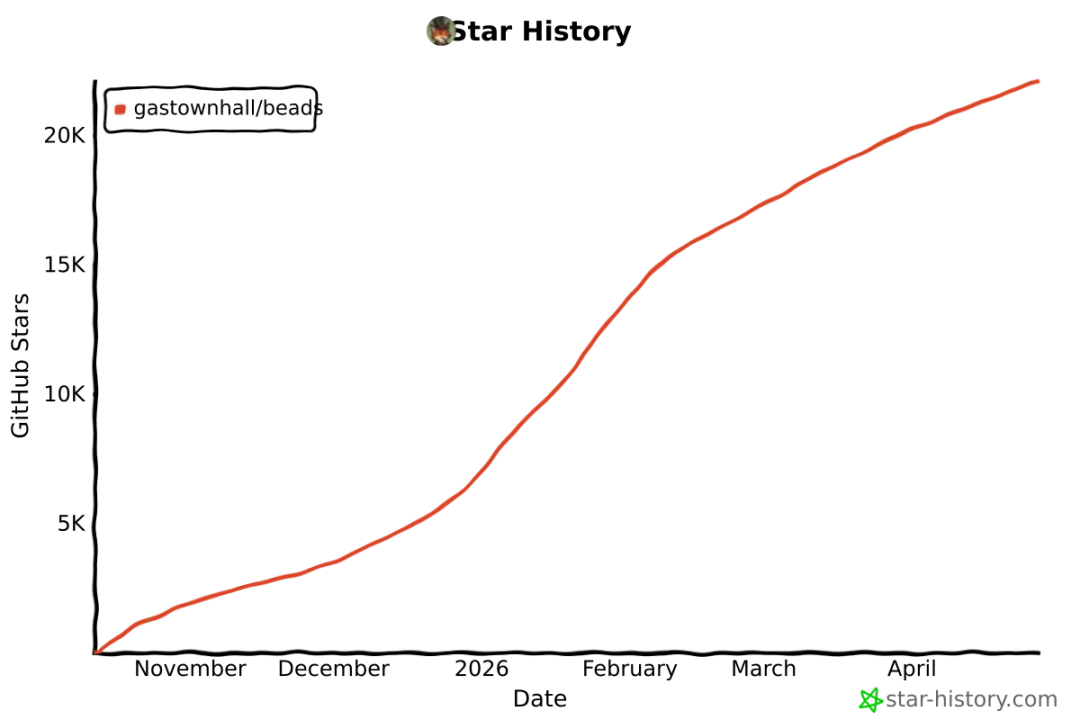
目前 GitHub 22.1K+ star,今日新增 485 star。
01 它是什么?
Beads 是一个面向 AI 编程工具的分布式图结构任务追踪工具。它把你的项目任务、依赖关系、进度全部存在一个 Dolt(版本控制 SQL 数据库)里,然后通过 CLI 命令暴露给 AI 编程工具。
一句话概括:AI 编程工具的结构化记忆与任务追踪工具。
它的核心设计理念是:任务不是扁平的列表,而是一张有向无环图(DAG)。一个任务可以阻塞(block)另一个任务,可以是某个 Epic 的子任务,可以和相关任务建立「relates_to」关系。Beads 会自动计算哪些任务已经就绪(没有 open blocker),让 AI 始终知道下一步该做什么。
02 核心原理/亮点
Dolt 底层:版本控制 SQL 数据库
Beads 使用 Dolt(https://github.com/dolthub/dolt) 作为存储引擎——这是一个 Git 风格的 SQL 数据库,每个写操作都是一个 commit,支持分支、合并、cell-level 的冲突处理。这意味着:
-
任务历史完整可追溯( git log一样的bd log) -
可以开分支做实验性计划,合并不满意就丢弃
-
多 agent 并行工作时不会丢数据
依赖感知图谱
Beads 里的任务关系不只有「待办/已完成」两种状态,它支持:
|
|
|
|---|---|
blocks |
|
relates_to |
|
duplicates |
|
supersedes |
|
replies_to |
|
bd ready 命令会列出所有没有 open blocker 的任务——AI 可以直接知道自己现在能做什么。
零冲突 ID
每个任务有一个哈希 ID(格式 bd-a1b2),多 agent 或多分支并行工作时不产生 ID 冲突。这是专门为 AI 工作流设计的关键特性——传统的自增 ID 在并发场景下会产生大量冲突。
语义压缩(Memory Decay)
旧的和已关闭的任务不会一直占上下文窗口。Beads 会自动将它们「压缩」成摘要,保留关键信息但不占空间。
两种存储模式
- 嵌入式模式
(默认):Dolt 进程内运行,不需要外部服务器,数据存在 .beads/embeddeddolt/ - 服务器模式:
bd init --server
连接外部 Dolt SQL Server,支持多 writer 并发写入
零 Git 依赖
Beads 可以完全脱离 git 运行(bd init --stealth),数据存在指定目录。这让它特别适合:
-
非 Git VCS( Sapling、Jujutsu 等)
-
CI/CD 环境里的临时任务追踪
-
Monorepo 中指定子目录的独立追踪
03 应用场景
场景一:长周期多步骤重构任务
一个大型架构重构可能有 20+ 个步骤,涉及多个模块的改动。传统方式是你自己维护一张清单,记着哪些做完了哪些还没做。Beads 让 AI 帮你维护这张图——它知道每个任务的依赖关系,bd ready 告诉你现在能做哪个。
场景二:多 AI Agent 并行开发
多个 AI agent 同时工作在同一个 repo,每个 agent 创建自己的任务。没有 Beads 时,任务 ID 冲突、依赖关系混乱是常态。Beads 的哈希 ID 保证了零冲突,Dolt 的并发写入支持保证了数据安全。
场景三:开源项目贡献者工作流
贡献者(fork 的仓库)和维护者(主仓库)角色不同,Beads 可以把贡献者的规划任务存在本地,不污染主仓库的 PR。用 bd init --contributor 即可切换到独立存储路径。
场景四:团队 Code Review 流程
通过 bd dep add 建立「审查通过才能合并」的依赖关系,或者用 supersedes 标记替代方案。Beads 的图结构天然适合描述这种有条件的工作流。
04 快速上手
第一步:安装
#macOS / Linux(推荐)brew install beads#Node.js 用户npm install -g @beads/bd第二步:在项目里初始化
cd your-projectbd init第三步:告诉 AI 使用 Beads
echo "Use 'bd' for task tracking" >> AGENTS.md第四步:创建任务
bd create "设计 API 接口" -p 0 # 创建 P0 任务bd create "实现核心逻辑"-p 1 # 创建 P1 任务bd dep add bd-xxx bd-yyy # 建立依赖:bd-yyy 阻塞 bd-xxx第五步:查看就绪任务
bd ready # 列出没有 open blocker 的任务常用命令速查
|
|
|
|---|---|
bd ready |
|
bd create "标题" -p 0 |
|
bd update <id> --claim |
|
bd dep add <child> <parent> |
|
bd show <id> |
|
bd close <id> "原因" |
|
完整文档:https://gastownhall.github.io/beads/
写在最后
Beads 解决的不是「任务管理」这个问题本身——它解决的是** AI 编程工具缺乏持久化、结构化记忆**的根本缺陷。
当你的 AI 可以查询一张实时更新的任务图谱,知道哪些做完了、哪些被阻塞了、依赖关系是什么,它就不再是一个每次都要重新读上下文的「金鱼」。这种结构性记忆让长周期任务、多步骤重构、跨模块改动这些高难度工作变得可以管理。
如果你在用 Claude Code 或类似的 AI 编程工具处理复杂任务,Beads 是值得一试的记忆增强工具。
相关链接:
-
GitHub:https://github.com/gastownhall/beads
-
文档:https://gastownhall.github.io/beads/
-
Dolt 数据库:https://github.com/dolthub/dolt
-
npm 包:https://www.npmjs.com/package/@beads/bd
-
PyPI:https://pypi.org/project/beads-mcp/