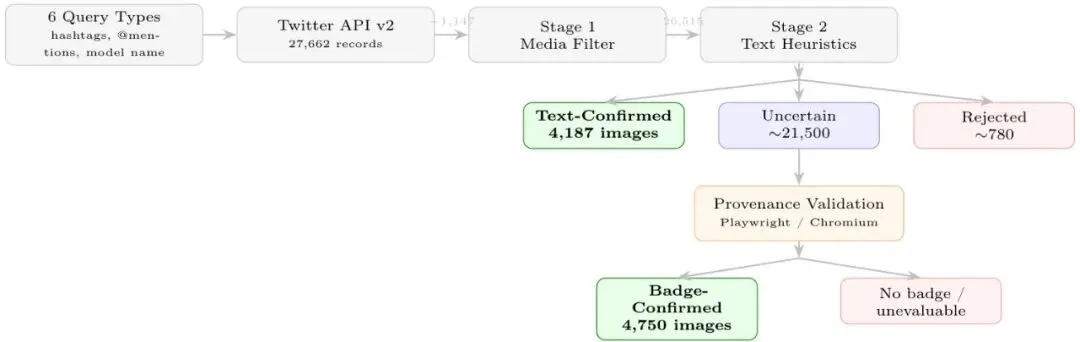
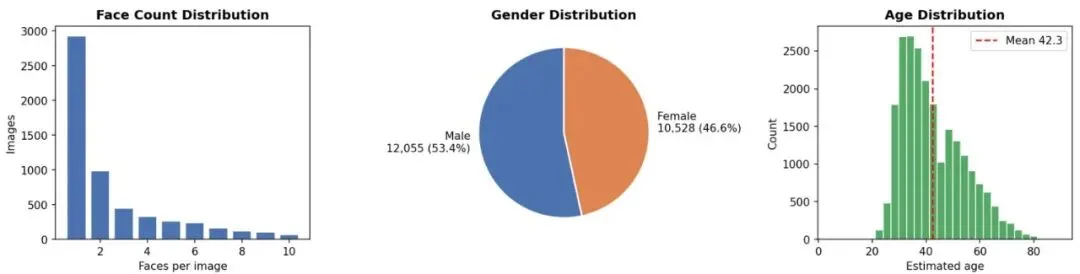
数据收集的时间窗口极其短暂。推特API v2的“近期搜索”端点只允许访问过去7天内的推文,而模型发布日期是4月21日。研究者必须在4月21日至26日这6天内完成所有抓取——晚一天,第一波最原始、最真实的创作热潮就会永远消失在线。为此他们采用了付费的Basic级别服务(每读一条推文收费0.005美元),配合has:images -is:retweet过滤器,只抓取带图片的原创推文。查询设计的关键在于:要精准找到那些明确说自己“用GPT-image-2生成了图片”的推文,而不是那些仅仅讨论模型或者转发的广告。研究者设计了一套多语言“创作语言”查询,覆盖英语、日语、中文。例如,英语使用“made with”、“created by”、“prompt:”等信号;日语针对“で生成”(生成自)和“作ってみた”(试着做了);中文使用“提示词”和“生成的”。此外,他们还加入了一个纯Hashtag查询(#GPTImage2),虽然数量少但确认率极高。表1:收集使用的查询类型及其图片产量和确认率。从表1可以看到,Hashtag查询的确认率高达94%,但数量只有1314张;而英文创作语言查询贡献了最大的原始量(13508张),确认率44%。总体来看,在14,154张过滤后的图片中,最终只有30.9%能被明确确认。其余都是只提了模型名但没有明确“生成”语言的“沉默创作者”——这些人占了绝大多数。图2:端到端收集与筛选流水线(从左到右)。第一阶段移除非照片媒体和下载失败;第二阶段应用多语言文本启发式分类得到三个类别。不确定推文进一步通过Playwright/Chromium浏览器自动化检查推特“Made with AI”标签,额外得到4750张标签确认的图片。整个收集过程就是一场与时间的赛跑。研究者的策略很简单:先用多语言关键词捞一把大的,然后通过一系列规则把“疑似AI”和“确认AI”分开。但最大的问题在于:如何从那些没有写“用GPT-image-2生成”的推文中挖出真金?
智慧筛选:多语言“侦探”如何锁定真实AI图片?
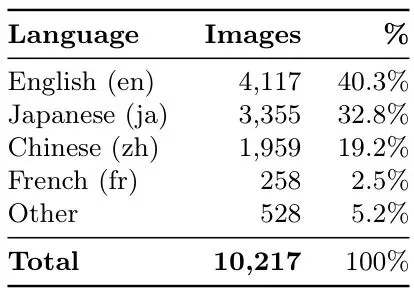
第一阶段只是简单粗暴地过滤掉非图片媒体(视频缩略图、GIF)和下载失败的记录,剩下26,515张照片记录。第二阶段才是真正的“侦探工作”:研究者设计了一套基于规则的文本分类器,为每张图片分配三个标签之一——确认、拒绝或不确定。确认条件:推文文本同时包含明确的创作语言(如“made with”、“created by”、“generated by”、“prompt:”)以及可识别的模型名变体(GPTImage2, GPT-image-2等)。日语加上了“生成”和“作ってみた”,中文加上了“提示词”和“生成的”。AI艺术标签(#AIart、#AIイラスト)作为弱确认信号。拒绝条件:出现比较语言(“vs”某个竞品)、提到三个及以上不同AI工具、或者发布公告式用语(“released”、“now available”)。不确定类:所有剩余记录。这是最大的一类,约占67%。表2:第二阶段分类结果(去重后的唯一图片记录)。通过Playwright检查更广泛的不确定池(约21,500条)包括来自完整26,515条记录的未去重记录。表2显示,明确确认的只有4,187张,拒绝的只有396张,剩下的9,571张都是不确定的。作者并没有放弃这些不确定的推文,而是做了一件更妙的事:利用Playwright(浏览器自动化工具)自动打开每条不确定的推文网页,查看推特官方渲染的“Made with AI”徽章——这是模型发布后推特平台自动为AI生成图片打上的标签。结果发现,在约21,500条检查过的推文中,有53.7%实际上带着“Made with AI”徽章!这相当于从不确定池中又挖出了4,750张确凿的AI图片。经过这一整套组合拳,最终的高置信度数据集包含10,217张图片。这些图片的语言分布也非常有趣:英语占40.3%,日语占32.8%,中文占19.2%——GPT-image-2在多国文字渲染上的优势吸引了大量非英语用户。表3:确认图片的语言分布(lang字段)。
这部分是整篇论文最令人“心碎”的发现。C2PA(Coalition for Content Provenance and Authenticity,内容来源与真实性联盟)是一个由Adobe、微软、OpenAI等巨头支持的标准,它通过在图片中嵌入加密元数据来标记内容的来源,相当于AI的“防伪身份证”。理论上,任何由GPT-image-2生成的图片都应该包含C2PA凭证,任何人都可以打开图片的元数据查看。然而,研究者下载了所有图片,仔细检查了EXIF、XMP和C2PA标记,结果是一无所获!每一张从推特API下载的图片都是赤裸裸的JPEG,没有任何元数据。这意味着什么?推特的CDN(内容分发网络)在上传图片时,直接杀死所有嵌入的元数据——这是系统性的破坏!无论你是什么模型生成的图片,只要经过推特平台,C2PA信誉就彻底失效。这一发现对整个AI图像溯源领域是沉重一击。很多依赖C2PA进行检测和归属的方案,在实际社交媒体部署中完全失效。幸运的是,推特自己推出了“Made with AI”徽章,这是一个平台内部的前端信号,但只能通过手动打开网页查看,无法通过API批量获取——而且创作者可以自行选择是否显示(或者在上传后标签才被应用),可靠性也有限。为了验证这个结论,研究者做了两个实验:一是下载所有不确定性图片的原始文件,通过Hex编辑器查看是否包含任何元数据残留,结果没有。二是用Playwright自动化浏览器直接打开每条推文的网页,检查是否存在“Made with AI”徽章。在约21,500条成功加载的推文中,53.7%带有徽章——说明平台还是有能力识别一部分AI图片,但它的触发机制(可能是基于上传时的元数据或用户举报)并不完美。这个结果也解释了为什么本研究必须依靠多语言文本启发式方法:在平台级元数据被破坏的情况下,唯一可行的AI图片溯源通道就是用户自报的“创作语言”。
Q2:C2PA是什么意思?为什么重要?A2:C2PA全称Coalition for Content Provenance and Authenticity(内容来源与真实性联盟),是一个行业标准,通过在图片中嵌入加密元数据来证明其来源(比如“此图由GPT-image-2生成”)。它相当于数字内容的“防伪标签”,理论上可以让任何用户验证图片是否AI生成。但论文发现,推特的上传系统会清除所有元数据,导致C2PA在社交媒体上完全失效。
Q3:为什么数据集只有一万多张?模型发布第一周用户创作应该很多吧?A3:其实作者通过多语言关键词捞到了14,154张经过过滤的图片,但其中只有约30%能通过文本明确确认为GPT-image-2生成。其余70%是“沉默创作者”——他们上传了图片但没有写任何“用XX模型生成”的文字。即使使用浏览器自动化检查“Made with AI”徽章,也只能额外确认一部分。另外,推特API的近期搜索端点只能访问7天数据,且不是索引所有推文,所以实际容量受限于搜索索引覆盖范围。所以这10,217张已经是最大努力下的高置信度集合了。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~
龙哥点评
论文创新性:★★★✰✰
首个GPT-image-2野生数据集,收集方法实用有效,但技术上没有突破性创新,属于工程贡献型。
实验合理度:★★★★✰
多阶段筛选设计合理,Playwright验证“Made with AI”徽章是亮点。但缺乏人工标注评估确认率,依赖规则可能漏掉部分真实AI图片。
[1] Z. J. Wang et al., “DiffusionDB: A large-scale prompt gallery dataset for text-to-image generative models,” ACL 2023.[2] M. Zhu et al., “GenImage: A million-scale benchmark for detecting AI-generated image,” NeurIPS 2023.[3] Coalition for Content Provenance and Authenticity, “C2PA technical specification, version 2.1,” 2024.[4] 原文链接:https://arxiv.org/pdf/2604.25370v1.pdf
 夜雨聆风
夜雨聆风