 夜雨聆风
夜雨聆风





再聊AI – Image2+SeeDance2.0,为时尚早,还是一步之遥?
-
目前这个东西直出的“声音(音效+音乐)”到底行不行?(语音确实不太行) -
一个纯外行想做能一段能看的,像样的视频,在现在这个年代,要氪多少钱,能薅多少羊毛,要跨多少座桥? -
针对目前对这些东西的测试也理解,我们可以预判一下,旧范式被替代的时间,还有多远?
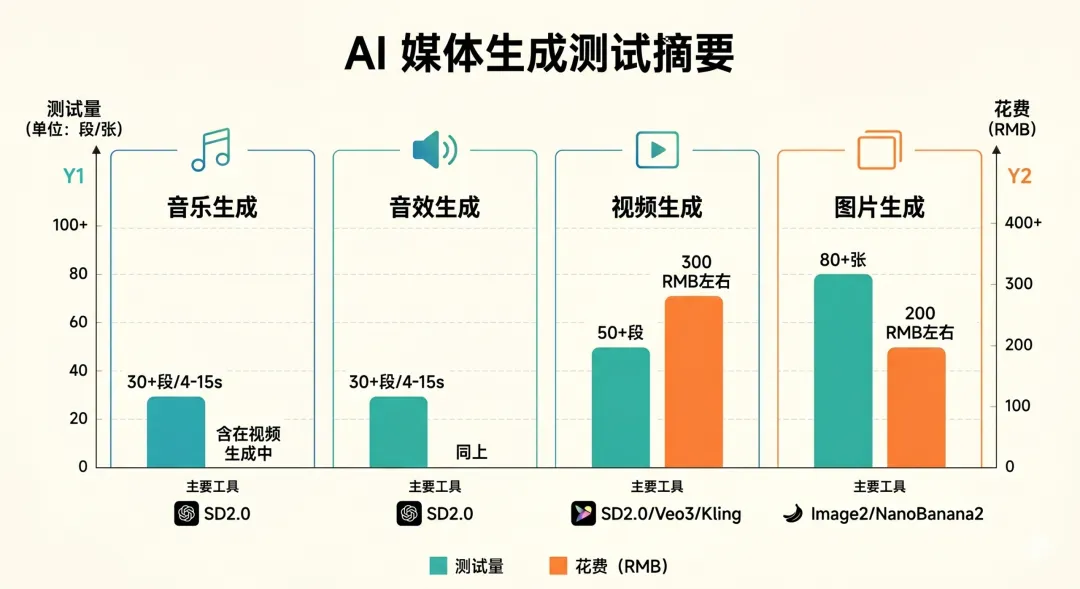
-
语音:我看了蛮多AI视频的,里面语音能用的概率感觉不超过30%,很多视频还是存在生硬,机械,一耳朵AI的问题,当然肯定有更好的模型解决了这些问题,但我们这里只聊SD2.0直出的效果,我给到一个拉。 -
音乐:其实测试的意义也不大,因为很明显Suno摆在那里,而Suno现在已经可以胜任某些风格的编曲了,用SD2.0测试的意义在于,它懂不懂“根据视觉匹配音乐”,也就是ACE搞的那套对点音乐的路子,结果如下(不好意思,这个视频只有4s,虽然测了很多段子,但我也懒得一个个上传了,只意思一下传了比较典型两个):
-
它知道“开门到镜头快速推进”需要一个filler,完全匹配镜头推进的时间 -
它知道“镜头推进的时候给一个whoosh”,你用好一点的监听可以听到,手机扬声器不明显 -
它知道“进入Club之后音乐情绪要起来”以及“这个美术风格大概可以配什么样的音乐”,这里卡的还不错
-
音效:这个其实我最感兴趣,因为如果AI大模型可以根据视频匹配音效并且做的还不错,想一下我们平时的工作流?分层+设计+进Wwise先不谈,贴片这个事情还能存在多久?:
-
不管是手机扬声器还是监听,一耳朵过去,画面里该抓的声音几乎都抓到了 -
这么多东西,生成时间大概是2-3m(即梦VIP),音效基本是附带的,美术效果才是算力大头,不好讲算力全用在音频上会不会有质变 -
我觉得可以直接用,没毛病,当然你说不能用就是你对
-
我测试了可灵,Veo3和SeeDance2.0以及Comfyui的一些本地视频模型比如最新的LTX2.3(这个就不说的,因为我的显卡显存“只有”12GB,只能跑蒸馏版本的,而且ComfyUI的上手还是有一定深度的,暂时就没太细研究) -
目前市面上的视频生成模型,SD2.0是断档领先(任何能掀起一阵风潮的大模型,果然都有点东西)这里的断档不止体现在生成视频的质量上,主要是体现在模型对分镜的理解上,除了SD2.0,没有任何一个模型能“完全看懂”你的分镜到底想干嘛,而这个,我的朋友,你都不用玩多少天,只要一下午,就知道比生成视频的质量本身重要得多 -
同样的结果给到Image2,不管是生图的质量,图片风格和领域的广泛程度还是易用性,Image2都结结实实的有点“吓到我了”(强到我让订阅了一年的Gemini瞬间下岗,立即重回OpenAI的怀抱,AI时代的我们就是这么冷酷无情),我不知道本地ComfyUI折腾各种工作流能不能有接近或者超过Image2的效果,但我觉得即使有,学习成本和效率都赶不上自然语言说几句话直出(但这里依然有坑,ComfyUI应该还有很多存在的价值,稍后细讲)
-
一个“动机”,可以是一个故事,一个画面,一个声音,甚至是一种“感觉” -
剧本或者分镜脚本,有的导演拍戏没剧本,有的不画分镜,那是人家脑子里有这些东西,对我个人来说,两者都非常必要,写作帮我理清动机的思路,分镜帮我视觉化想要呈现的内容,现在我们可以直接甩给AI去细化这些东西(但有认知债的坑,这个一会儿细聊) -
执行,如果是传统剧组,这个时候应该要找钱找人找场地开干了,但AI完全替代了这一部分,从想法到拍摄,没有这么长的摩擦和缓冲期,有点像是上一个十年搞音乐,不再需要真的去找一支乐队了,你想成为音乐人,一台电脑可以让你直接成为 -
剪辑与后期处理,玩票的话,后期这部分其实不需要太在意,网上能爆的视频也不是因为这部分做的好,严肃创作另说,剪辑非常重要,虽然Agent貌似可以做这个活儿了,但自己做还是有一些乐趣,也是整个阶段“人”目前参与度最高的一部分 -
不同内容,对内容的不同熟悉和把控程度,极大影响了这几个步骤中“人机协作”的比例,拿我这几天尝试的不同风格来说,我在意的,喜欢的,熟悉的,都是自己尽量描述清楚剧本+分镜内容,然后AI辅助,反过来则只提一个点子然后给AI穷举,通过“直接成为”来测试结果,看看有没有我想要的东西

-
AI是一个拥有巨量知识和无限体力,但暂时“缺了一块什么”的助手,这个缺失主要影响的是信息真实度,表达精度和比较玄学的“质感”,这在某些时候是致命的 -
创作需要的是精准的表达,目前这个阶段,人比AI精准 -
在我们传统的浪漫叙事里,“创新/创作”总是天然正义的一方,永远大于“追随/模仿”,但在real world,真正的,原始的创新是极少的(所以才显得可贵),绝大部分生存模式,不管是企业还是艺术,一定是以“追随/模仿”为主要方法论,而这件事,AI可以秒做
-
“想法/设定”阶段 – 非常适配AI,给他一个想法/风格方向,让他从不同角度解读,会给你很多新的点子,人机合作程度给到夯,我现在几乎做什么都会先AI过一轮,遇事不决找AI,在Image2出现后,不管是逻辑类的想法,还是视觉类的呈现,我都会习惯性的让他做成图片:

想“营造一种感觉”,直接营造

想“模仿一场Live的构图”,直接模仿

想“创造个性的角色”,直接创造

-
“Demo”阶段 – 非常适配AI,把上一个环节确认好的想法和一些能带到这个环节的,你很确信需要表达的东西抛给AI,如果可以,给一些具体的参考方向,再让它执行不同方案,然后我们再去对比,调参,精修即可:
Image2画 StoryBoard 是真的厉害

-
“执行”阶段 – 看个人本事和表达内容,从“完全依赖AI”到“只靠AI填充必要内容”都可能存在,于我(和大部分的AIGC视频生成选手)来说这部分是变革最大的,我不能画分镜,没有时间和资源去找团队拍摄,以前这个事情是不可能完成的,现在变得可能了
感谢即梦团队,贫穷让我的思维变得更精准
-
“后期和剪辑”阶段 – 很多AI目前其实前后期打通了,参考图和提示词给好的话,出来的就是成品,剪辑这一块,影视飓风都没上AI,而且很多时候你在“生成”时其实已经有了“剪辑”思维,知道自己需要哪方面的素材,有点类似歌手用软音源编曲,你先不说他编的好坏,他在编曲阶段选择的乐器和音色,一定是某种程度上忠实还原他的认知和想法的,虽然其实找个更专业的人合作,往往能达到更专业的结果

-
首先,并不是所有AI都能理解和还原你的意图,生成高质量的结果,相反,目前,在上手容易的几个民用大模型里,只有Image2和SeeDance2.0有能力“精准理解”,别的要么是无法理解(除了这两个模型之外的其他模型),要么是需要巨量的前置知识和试错(折腾过WebUI,ComfyUI和本地硬件的都懂)
-
但即使这样,也不是“所有细节都能理解的”,这个分镜,非常清楚地展示了“扭头”这个动作
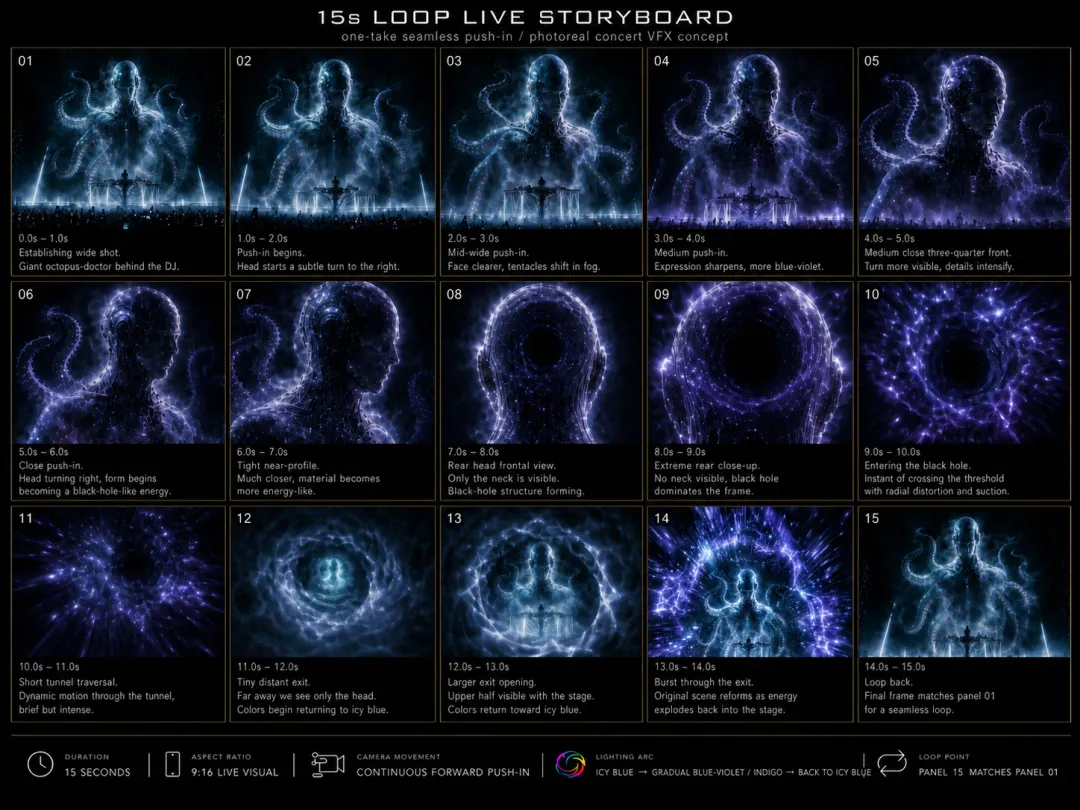
-
结构抽卡抽到一堆什么美国恐怖故事?
-
再比如这个,AI没法理解“吉他装到包里”的效果是什么,而且前后逻辑也不连贯:

-
再来,当AI无法理解你的意图并且你想要精细调整的时候,无论是代码,还是生图生视频,抽卡无法避免,认知债越大,抽卡概率越低,而现在,视频抽卡是非常昂贵的,而且抽卡非常消耗时间却毫无任何成长/成就可言,是我目前最讨厌的部分,但还好,应该很快,Agent就可以帮我们抽卡了
-
即使喂了人设,限制了提示词,还是会出现风格跑偏,而且说实话,还是少了非常多的细节,比如这个视频中,分镜已经给的很清楚了,图像清晰度也够,但出来的人物的动作,发丝,就是僵硬的,这种“细节的缺失”依然会让人觉得目前这个东西“不太能用”或者“AI感”有点浓(可能和风格以及抽卡次数有关)



-
场景一致性比人物更麻烦,但现在可以生成360视图,让AI在不同角度理解空间关系了,效果比之前好很多,要求不高的话可以用,也省掉了blender或者UE里建白模
-
它确实可以“破壁”,以前此生不敢想的事情,现在好像都可以试试了,只要你愿意 -
它可以非常快的,以惊人的效率出一个50-80分的东西,然后你需要花费巨量时间和金钱去想办法找后面那缺失的一块,如果要求不高,找到的概率还是挺大的,但也要做好因为认知债和成本,这一块就是无法拼起来的结果 -
考虑到它的进化程度,我对它找到这最后“一块拼图”的能力和需要的时间,抱有乐观态度
-
AI时代,工具的迭代会迅速让之前积累的知识贬值甚至变得没有作用,举个最简单的例子,我还在折腾ComfyUI工作流,想着怎么生人设,好不容易有点名堂出来,Image2来了,一句话解决,这个体验,实在是太过酸爽 -
虽然AI时代“每天惊诧,周周AGI,月月人类灭亡近在咫尺”,但只要你花点时间体验和测试,会发现能掀起一股风潮的工具,真的或多或少有点东西。