 夜雨聆风
夜雨聆风





读读代码 | Qwen3-VL 深度源码分析:视觉语言多模态模型的完整解剖
读读代码 | Qwen3-VL 深度源码分析:视觉语言多模态模型的完整解剖
0. 引言
视觉语言模型(Vision Language Model,简称VLM)代表了人工智能领域的重要进展,它能够同时理解和处理文本与图像信息。Qwen3-VL作为通义千问系列的最新多模态模型,在架构设计上进行了多项创新性改进。本文将从源码层面深入剖析Qwen3-VL的技术实现,帮助读者全面理解这一先进模型的工作原理。
Qwen3-VL的核心改进包括:将目标检测的坐标表示从归一化坐标改回绝对坐标,增强了模型在空间定位任务上的表现;引入DeepStack架构,通过多层视觉特征融合提升视觉理解能力;采用MRoPE-Interleave位置编码方案,更好地建模时空关系;支持3D检测和空间关系推理等高级视觉任务。这些技术创新使Qwen3-VL在多个视觉语言基准测试中取得了显著的性能提升。

1. 多模态大模型的基础架构
在深入Qwen3-VL的具体实现之前,我们需要理解多模态大模型的基本组成部分。任何一个成熟的视觉语言模型都包含四个核心组件,它们各司其职,共同完成从原始输入到最终输出的完整处理流程。
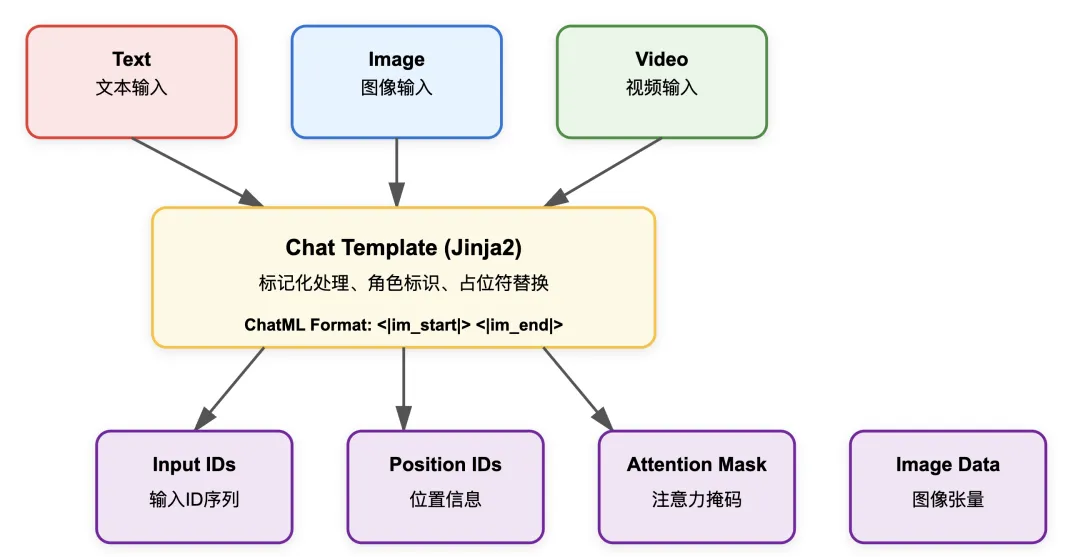
首先是**Chat Template(对话模板)**组件,它负责将用户的多模态输入转换为模型可以理解的标准格式。这一组件需要处理文本、图像、视频等不同模态的输入,并将它们统一编码为符合模型要求的序列格式。对于Qwen系列模型,采用的是ChatML格式,通过特殊标记符来区分不同的角色和内容类型。
其次是Image Processor(图像处理器),专门负责对输入图像进行预处理。这一步骤包括图像的缩放、裁剪、归一化等操作,将原始图像转换为模型视觉编码器所需的张量格式。在LLaVA等模型中,还会在这一阶段完成图像的patch切分工作,为后续的视觉编码做好准备。
第三个组件是Processor(处理器),它是一个协调者的角色。Processor整合了Image Processor处理图像和Tokenizer处理文本的功能,确保多模态输入能够正确对齐。在某些模型架构中,如MiniCPM-V,Processor还会为图像预留占位符,确保视觉特征能够正确插入到文本序列中的指定位置。
最后是Model本身,包含了视觉编码器(Vision Model)、特征融合模块和语言模型(LLM Encoder)。视觉编码器负责提取图像特征,特征融合模块将视觉特征与文本特征结合,语言模型则在融合后的多模态表示上进行自回归生成。这种模块化的设计使得不同组件可以独立优化和升级。
基本流程代码示例
# 多模态模型的基本处理流程from transformers import AutoConfig, AutoProcessor, AutoModelForCausalLMfrom PIL import Image# 1. 加载配置和模型组件config = AutoConfig.from_pretrained("Qwen/Qwen3-VL-7B-Instruct")processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-7B-Instruct")model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-VL-7B-Instruct")# 2. 处理输入image = Image.open("image.jpg")messages = [ { "role": "user", "content": [ {"type": "image", "image": image}, {"type": "text", "text": "请描述这张图片"} ] }]# 3. 通过processor统一处理inputs = processor.apply_chat_template( messages, tokenize=True, return_dict=True, return_tensors="pt")# 4. 模型推理outputs = model.generate( **inputs, max_new_tokens=128, do_sample=True, temperature=0.7)这种清晰的模块划分不仅使代码结构更加清晰,也为模型的扩展和优化提供了便利。
2. Chat Template:多模态输入的标准化处理
Chat Template是连接用户输入和模型内部表示的重要桥梁。Qwen3-VL采用了基于Jinja2模板引擎的灵活设计,能够处理文本、图像、视频等多种模态的混合输入。与Qwen2-VL相比,Qwen3-VL的Chat Template进行了重要的功能扩展,特别是增加了对工具调用(Tool Call)的完整支持。
Qwen3-VL提供了两个版本的Chat Template:Instruct模型和Thinking模型。Instruct模型的模板相对简洁,专注于标准的指令遵循任务;而Thinking模型则在模板中集成了思维链(Chain of Thought)的处理逻辑,允许模型在生成最终答案前展示推理过程。这种设计使得同一个模型架构可以支持不同的应用场景。
2.1 Instruct模型的模板机制
对于Instruct模型,Chat Template的核心功能是将多模态输入转换为统一的文本序列,并通过特殊标记来标识不同模态的内容。当处理包含图像的输入时,模板会将图像位置标记为<|vision_start|><|image_pad|><|vision_end|>,这个标记序列在后续处理中会被实际的图像特征向量替换。
# Instruct模型处理示例messages = [ {"role": "system", "content": "你是一个助手,可以调用工具。"}, { "role": "user", "content": [ {"type": "text", "text": "今天图片这里显示的天气如何?"}, {"type": "image_url", "image_url": "<http://example.com/weather.jpg>"} ] }]# 模板处理后的输出"""<|im_start|>system你是一个助手,可以调用工具。<|im_end|><|im_start|>user今天图片这里显示的天气如何?<|vision_start|><|image_pad|><|vision_end|><|im_end|><|im_start|>assistant"""模板处理的关键在于维护正确的序列顺序和角色标识。每个对话轮次都由<|im_start|>和<|im_end|>标记包围,明确标识了system、user和assistant的发言边界。这种结构化的表示使得模型能够清楚地理解对话上下文和当前应该执行的任务。
2.2 Tool Call支持
Qwen3-VL的一个重要特性是对工具调用的原生支持。当system消息中包含工具定义时,模板会在开头插入详细的工具使用说明,告诉模型如何调用可用的函数。工具调用的结果会以<function_response>标签包裹,并作为user角色的消息返回给模型。
# 工具调用的完整流程messages = [ {"role": "system", "content": "你是一个助手,可以调用工具。"}, { "role": "user", "content": [{"type": "text", "text": "北京今天天气如何?"}] }, { "role": "assistant", "tool_calls": [{ "function": { "name": "get_weather", "arguments": {"location": "北京"} } }] }, { "role": "tool", "content": [{"type": "text", "text": '{"temperature": 25, "condition": "晴"}'}] }]# 模板会将tool response转换为特殊格式"""<|im_start|>user<function_response>{"temperature": 25, "condition": "晴"}</function_response><|im_end|>"""值得注意的是,工具调用的返回也可以包含图像。这使得Qwen3-VL能够支持需要返回视觉内容的工具,例如绘图工具、图表生成工具或图像检索工具。
2.3 Thinking模型的思维链处理
Thinking模型的模板在Instruct模型基础上增加了对推理过程的显式支持。模板会识别内容中的<think>和</think>标签,将其中的推理内容单独提取出来,并在适当的时候展示给用户或用于模型训练。
# Thinking模型的推理过程处理assistant_message = { "role": "assistant", "content": "<think>首先分析图片中的天气特征...</think>根据图片显示,今天天气晴朗"}# 模板会自动分离推理内容和最终回答"""<|im_start|>assistant<think>首先分析图片中的天气特征...</think>根据图片显示,今天天气晴朗<|im_end|>"""Thinking模板的一个关键设计是判断何时输出思维链。只有在最后一轮用户提问之后的assistant回复中,才会包含<think>标签。这样设计的原因是,在多轮工具调用的中间步骤,不需要展示推理过程,只有在生成最终答案时才需要完整的思维链。
3. 视觉处理流水线:从像素到特征向量
Qwen3-VL在视觉处理方面继承了Qwen2-VL的核心架构,但在patch size和处理策略上进行了优化。视觉处理的目标是将原始的图像或视频数据转换为模型可以理解的特征向量序列,这个过程涉及多个精心设计的步骤。
3.1 动态分辨率处理
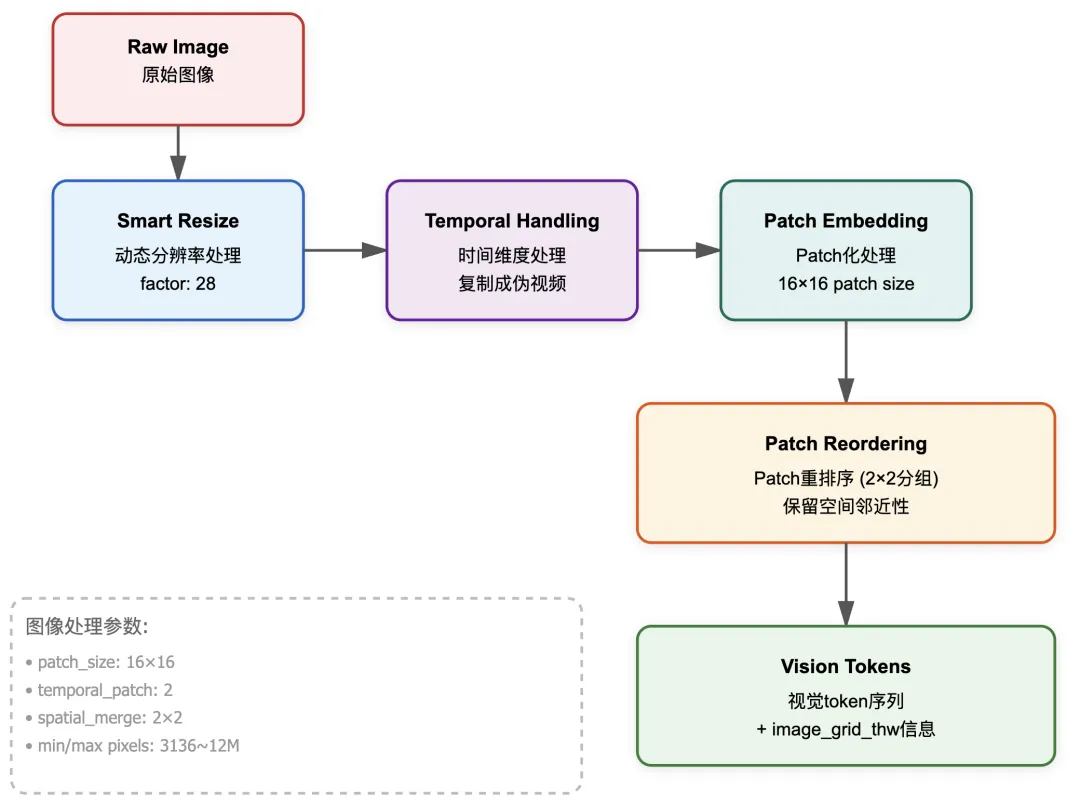
与传统的固定分辨率方法不同,Qwen3-VL采用动态分辨率处理策略。这意味着输入图像不会被强制缩放到固定尺寸,而是根据内容自适应地调整。这种设计的优势在于既能保留图像细节,又能控制计算成本。
Qwen3-VL使用16×16的patch size,这比Qwen2-VL的14×14更大。更大的patch size意味着每张图像会被切分成更少的patch,从而减少序列长度和计算量。但同时,通过支持更高的输入分辨率,模型仍然能够捕捉足够的细节信息。
# 图像预处理的核心参数class ImageProcessConfig: patch_size = 16 # Qwen3-VL使用16x16的patch spatial_merge_size = 2 # 空间合并尺寸 temporal_patch_size = 2 # 时间维度的patch尺寸 min_pixels = 56 * 56 # 最小像素数 max_pixels = 14 * 14 * 4 * 1280 # 最大像素数,支持超高分辨率def smart_resize(height, width, factor=28, min_pixels=3136, max_pixels=12845056): """ 根据图像尺寸智能调整分辨率 确保高宽都是factor的整数倍,同时控制总像素数在合理范围内 """ import math # 计算目标尺寸 total_pixels = height * width if total_pixels > max_pixels: scale = math.sqrt(max_pixels / total_pixels) height = int(height * scale) width = int(width * scale) elif total_pixels < min_pixels: scale = math.sqrt(min_pixels / total_pixels) height = int(height * scale) width = int(width * scale) # 调整为factor的整数倍 height = round(height / factor) * factor width = round(width / factor) * factor return height, width# 使用示例# 输入:1200×673的图像# smart_resize(1200, 673, factor=28)# 输出:1216×672 (都是28的整数倍)这个智能缩放算法确保了无论输入图像的原始尺寸如何,处理后的图像都满足模型的要求。factor参数设为28而不是16,是因为后续还会有2×2的spatial merge操作,所以需要确保尺寸是28的整数倍。
3.2 Temporal维度的处理
Qwen3-VL的一个重要特性是同时支持图像和视频输入。为了统一处理这两种输入,模型引入了temporal(时间)维度。对于静态图像,会在时间维度上复制一份,形成一个包含两帧相同内容的”伪视频”。这种设计使得视觉编码器可以使用统一的架构处理图像和视频。
# Patch构建过程def build_patches(image_tensor, patch_size=16, temporal_patch_size=2): """ 将图像转换为patch序列 对于图像,会在时间维度复制以支持统一的3D patch格式 Args: image_tensor: [B, C, H, W] 或 [B, T, C, H, W] """ import torch # 图像在时间维度复制 if image_tensor.ndim == 4: # 如果是图像,增加时间维度 image_tensor = image_tensor.unsqueeze(1) # [B, 1, C, H, W] if image_tensor.shape[1] == 1: # 复制成两帧,形成伪视频 image_tensor = image_tensor.repeat(1, temporal_patch_size, 1, 1, 1) # [B, 2, C, H, W] batch_size, frames, channels, height, width = image_tensor.shape # 计算grid尺寸 grid_t = frames // temporal_patch_size grid_h = height // patch_size grid_w = width // patch_size # 重组为patch # 最终形状: [B, grid_t, grid_h, grid_w, channels, temporal_patch_size, patch_size, patch_size] patches = image_tensor.reshape( batch_size, grid_t, temporal_patch_size, channels, grid_h, patch_size, grid_w, patch_size ) # 一个patch的维度: channel * temporal_patch_size * patch_size * patch_size # 即: 3 * 2 * 16 * 16 = 1536 return patches, (grid_t, grid_h, grid_w)每个patch的完整维度是3×2×16×16=1536,这比传统的2D patch包含了更多的信息。时间维度的引入不仅统一了图像和视频的处理流程,还为模型提供了潜在的时序建模能力,即使对于静态图像也能利用这种结构化的表示。
3.3 Patch重排序与空间合并
Qwen3-VL采用了一种特殊的patch重排序策略,这与后续的DeepStack架构密切相关。在将2D图像展平为1D序列时,模型不是简单地按行或按列顺序排列,而是将每2×2个相邻的patch作为一组进行排列。
# Patch重排序示例def reorder_patches(patches, merge_size=2): """ 按照空间邻近性重排序patch 输入形状: [batch, grid_t, grid_h, grid_w, channel, t_patch, h_patch, w_patch] 输出形状: [batch, total_patches, patch_feat_dim] """ import torch batch, grid_t, grid_h, grid_w, channel, t_patch, h_patch, w_patch = patches.shape # 重组维度以实现分组 # 将grid_h分成grid_h//merge_size和merge_size两个维度 patches = patches.reshape( batch, grid_t, grid_h // merge_size, merge_size, grid_w // merge_size, merge_size, channel, t_patch, h_patch, w_patch ) # 重排序:先遍历大grid,再遍历内部的2×2 block # 原始: [batch, grid_t, gh//2, 2, gw//2, 2, c, t, h, w] # 目标: [batch, grid_t, gh//2, gw//2, 2, 2, c, t, h, w] patches = patches.permute(0, 1, 2, 4, 3, 5, 6, 7, 8, 9) # 展平为序列 flatten_patches = patches.reshape( batch, grid_t * grid_h * grid_w, channel * t_patch * h_patch * w_patch ) return flatten_patches# 可视化重排序效果# 假设有4×4=16个patch,标记为1-16# 原始布局:# [ 1, 2, 3, 4]# [ 5, 6, 7, 8]# [ 9, 10, 11, 12]# [13, 14, 15, 16]## 重排序后的序列(merge_size=2):# [1, 2, 5, 6, 3, 4, 7, 8, 9, 10, 13, 14, 11, 12, 15, 16]这种重排序的好处在于,后续的Patch Merger模块可以很方便地将每4个连续的patch合并成一个特征,既保持了空间邻近性,又减少了序列长度。这是Qwen3-VL在效率和性能之间取得平衡的重要设计。
3.4 Image Grid THW表示
处理完图像后,除了得到patch序列,还会生成一个image_grid_thw张量,记录每张图像的时间、高度、宽度信息。这个信息在后续的位置编码和特征重组中都会用到。
# Image Grid THW的生成def get_image_grid_thw(images, patch_size=16, temporal_patch_size=2): """ 计算每张图像在patch化后的grid尺寸 返回(T, H, W),其中T是时间帧数,H和W是空间维度的grid数量 """ import torch grid_thw_list = [] for image in images: if image.ndim == 3: # 静态图像 [C, H, W] t_frames = 1 h, w = image.shape[-2:] else: # 视频 [T, C, H, W] t_frames = image.shape[0] h, w = image.shape[-2:] # 计算grid尺寸(after resize) grid_t = (t_frames + temporal_patch_size - 1) // temporal_patch_size grid_h = h // patch_size grid_w = w // patch_size grid_thw_list.append([grid_t, grid_h, grid_w]) return torch.tensor(grid_thw_list)# 使用示例# 对于一张1200×673的图像# 经过smart_resize后变成1216×672# grid_h = 672 // 16 = 42# grid_w = 1216 // 16 = 76# grid_t = 1 (图像会被复制成2帧,然后2帧合并成1个temporal patch)# 因此 image_grid_thw = [[1, 42, 76]]# 总patch数 = 1 * 42 * 76 = 3192# 经过spatial merge(2×2合并)后,序列长度 = 3192 // 4 = 798这个grid_thw信息贯穿整个模型的forward过程,是连接视觉编码器和语言模型的重要桥梁。
4. DeepStack架构:多层视觉特征融合
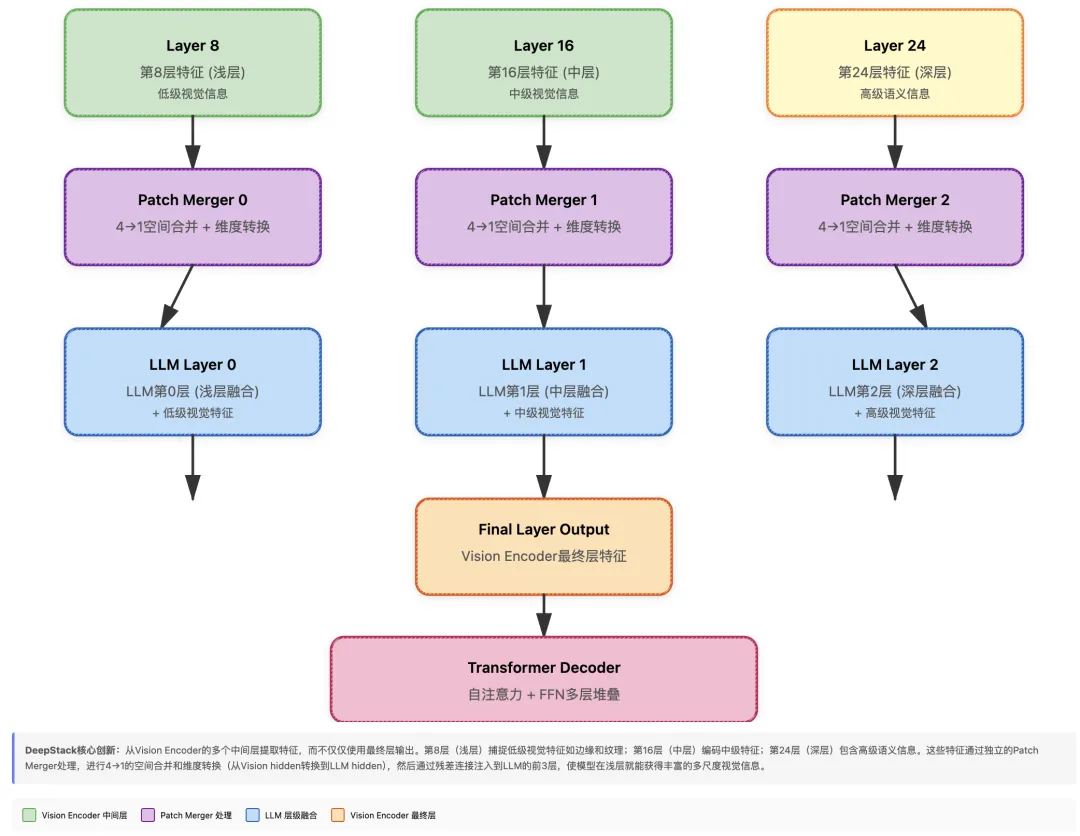
DeepStack是Qwen3-VL相比前代模型的一个重要创新。传统的视觉语言模型通常只使用视觉编码器最后一层的输出特征,而DeepStack架构则从视觉编码器的多个中间层提取特征,并将这些多尺度特征融合到语言模型的不同层中。
4.1 中间层特征提取
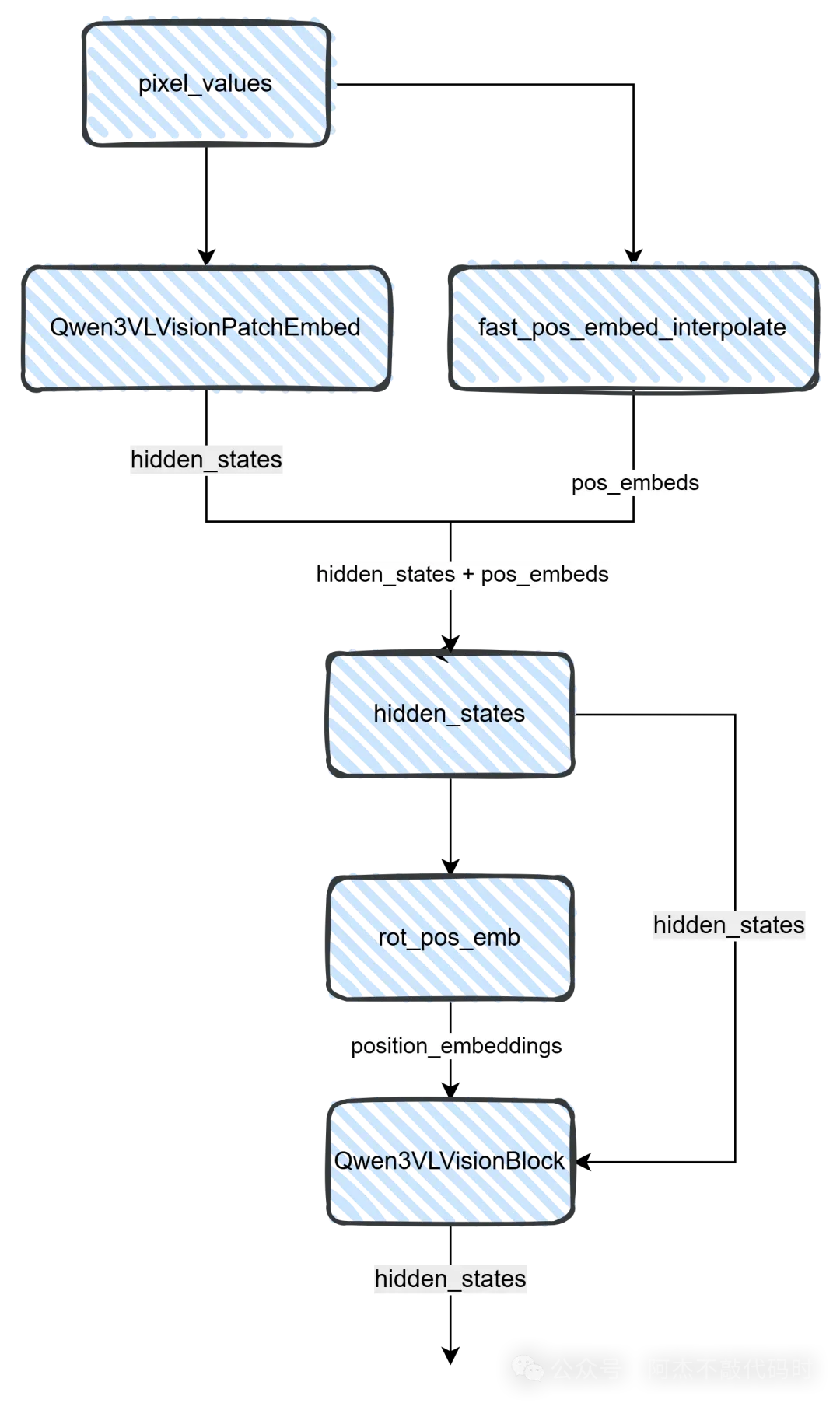
Qwen3-VL的视觉编码器共有27层Vision Transformer Block。DeepStack架构选择了第8层、第16层和第24层的输出作为额外的特征。这些中间层捕捉了不同抽象级别的视觉信息:浅层更关注低级视觉特征如边缘和纹理,深层则编码更高级的语义信息。
# DeepStack特征提取示例class Qwen3VLVisionModel(nn.Module): def __init__(self, config): super().__init__() # 27层Vision Transformer Block self.blocks = nn.ModuleList([ Qwen3VLVisionBlock(config) for _ in range(27) ]) # DeepStack配置:提取第8、16、24层的特征 self.deepstack_visual_indexes = [8, 16, 24] # 为最终输出准备的patch merger self.merger = Qwen3VLVisionPatchMerger(config, use_postshuffle_norm=False) # 为每个中间层准备独立的patch merger # 用于在fusion时进行维度转换 self.deepstack_merger_list = nn.ModuleList([ Qwen3VLVisionPatchMerger(config, use_postshuffle_norm=True) for _ in range(len(self.deepstack_visual_indexes)) ]) def forward(self, pixel_values, grid_thw): """ 前向传播过程中提取多层特征 """ # Patch embedding hidden_states = self.patch_embed(pixel_values) # 添加位置编码 position_embeddings = self.get_position_embeddings(grid_thw) hidden_states = hidden_states + position_embeddings # 存储中间层特征 deepstack_features = [] # 逐层前向传播 for layer_idx, block in enumerate(self.blocks): hidden_states = block(hidden_states, position_embeddings) # 如果当前层是DeepStack指定的层,提取并处理特征 if layer_idx in self.deepstack_visual_indexes: # 找到对应的merger merger_idx = self.deepstack_visual_indexes.index(layer_idx) merger = self.deepstack_merger_list[merger_idx] # 将当前层特征通过merger处理 # merger会进行4→1的空间合并,并将维度转换到LLM的hidden size deepstack_feature = merger(hidden_states) deepstack_features.append(deepstack_feature) # 处理最终层的输出 final_hidden_states = self.merger(hidden_states) return final_hidden_states, deepstack_features每个中间层的特征都经过独立的Patch Merger处理。Patch Merger是一个关键组件,它完成两个重要任务:将4个相邻patch的特征合并为1个,减少序列长度;将特征维度从视觉编码器的hidden size转换到语言模型的hidden size。
4.2 Patch Merger的实现细节
Patch Merger采用MLP架构,通过可学习的线性变换实现特征合并和维度转换。与简单的平均池化或最大池化不同,MLP能够学习更复杂的特征融合策略。
class Qwen3VLVisionPatchMerger(nn.Module): def __init__(self, config, use_postshuffle_norm=False): super().__init__() self.vision_hidden_size = config.hidden_size # 视觉编码器的hidden size (1664) self.llm_hidden_size = config.text_config.hidden_size # LLM的hidden size (3584) self.merge_size = config.spatial_merge_size # 通常是2,表示2×2合并 # MLP结构:先升维再降维 merged_dim = self.vision_hidden_size * (self.merge_size ** 2) # 1664 * 4 self.mlp = nn.Sequential( nn.Linear(merged_dim, self.llm_hidden_size), nn.GELU(), nn.Linear(self.llm_hidden_size, self.llm_hidden_size) ) # 可选的后处理LayerNorm self.use_postshuffle_norm = use_postshuffle_norm if use_postshuffle_norm: self.ln = nn.LayerNorm(self.llm_hidden_size) def forward(self, hidden_states): """ 输入: [seq_len, vision_hidden_size] 输出: [seq_len // 4, llm_hidden_size] """ seq_len, hidden_size = hidden_states.shape merge_size_sq = self.merge_size ** 2 # 每4个patch为一组 num_groups = seq_len // merge_size_sq grouped = hidden_states.reshape(num_groups, merge_size_sq, hidden_size) # 将每组的4个patch拼接 concatenated = grouped.reshape(num_groups, merge_size_sq * hidden_size) # 通过MLP转换 merged = self.mlp(concatenated) # 可选的LayerNorm if self.use_postshuffle_norm: merged = self.ln(merged) return merged值得注意的是,最终层输出使用的merger不包含后处理LayerNorm(use_postshuffle_norm=False),而中间层使用的merger包含LayerNorm(use_postshuffle_norm=True)。这是因为中间层特征会被注入到语言模型的前几层,需要更好的归一化来保持训练稳定性。
4.3 特征融合到语言模型
提取的DeepStack特征会被注入到语言模型的前3层。具体来说,第8层的视觉特征被加到语言模型第0层的输出上,第16层的特征加到第1层,第24层的特征加到第2层。这种设计使得语言模型的浅层就能获得丰富的视觉信息。
class Qwen3VLTextModel(nn.Module): def forward( self, inputs_embeds, visual_pos_masks=None, # 标记哪些位置是视觉token deepstack_visual_embeds=None, # 三层DeepStack特征 **kwargs): """ 多模态特征融合的关键步骤 """ hidden_states = inputs_embeds # 遍历所有语言模型层 for layer_idx, decoder_layer in enumerate(self.layers): # 标准的transformer layer前向传播 residual = hidden_states hidden_states = decoder_layer( hidden_states, attention_mask=kwargs.get('attention_mask'), position_ids=kwargs.get('position_ids'), **kwargs ) # 如果当前层需要DeepStack特征注入 if deepstack_visual_embeds is not None and layer_idx < len(deepstack_visual_embeds): # 获取对应层的DeepStack特征 visual_embeds = deepstack_visual_embeds[layer_idx] # 只在视觉token的位置进行特征注入 # visual_pos_masks标记了哪些位置是视觉token # 使用residual connection: 当前hidden state + 视觉特征 if visual_pos_masks is not None: hidden_states[visual_pos_masks] = ( hidden_states[visual_pos_masks] + visual_embeds ) return hidden_states这种特征注入机制有几个关键点:
-
1. 选择性注入:只在视觉token对应的位置注入特征,文本token不受影响 -
2. 残差连接:使用加法而非替换,保留了语言模型自身学习的表示 -
3. 层级注入:注入发生在每层的self-attention和FFN之后,不干扰transformer的标准计算流程 -
4. 渐进式融合:浅层融合低级特征,帮助模型早期学习到基本的视觉信息
4.4 DeepStack的优势分析
DeepStack架构带来了多方面的性能提升。在目标检测和图像分割等需要精确定位的任务中,来自浅层的低级特征能够提供更准确的空间信息。在图像描述和视觉问答等高级理解任务中,来自深层的语义特征则提供了更丰富的上下文。通过在语言模型的不同层次融合这些多尺度特征,模型能够根据任务需求灵活利用不同抽象级别的视觉信息。
实验表明,DeepStack使Qwen3-VL在保持推理速度的同时,在多个视觉语言基准测试上取得了显著提升。相比只使用最终层特征的baseline,DeepStack版本在需要精确空间理解的任务上性能提升尤为明显。
5. MRoPE-Interleave:改进的多模态位置编码
位置编码是Transformer架构的核心组件之一,它赋予模型理解序列顺序的能力。对于多模态模型,位置编码需要同时建模文本的线性顺序、图像的2D空间结构、以及视频的时间动态。Qwen3-VL采用的MRoPE-Interleave机制是对传统RoPE的重要改进。
5.1 传统RoPE回顾
旋转位置编码(Rotary Position Embedding, RoPE)通过旋转变换将位置信息注入到attention机制中。对于序列中的位置m,RoPE为每对特征维度构造一个旋转角度,使得不同位置的query和key向量之间的点积自然包含了它们的相对位置信息。
# 传统RoPE的核心思想import torchimport mathdef apply_rotary_pos_emb(q, k, position_ids, rope_theta=10000): """ 将RoPE应用到query和key向量 Args: q, k: shape [batch, seq_len, num_heads, head_dim] position_ids: shape [batch, seq_len] rope_theta: RoPE的base frequency """ head_dim = q.shape[-1] device = q.device # 计算每个维度对的频率 # dim_t = [0, 2, 4, ..., head_dim-2] dim_t = torch.arange(0, head_dim, 2, dtype=torch.float32, device=device) # freqs = [1/θ^(0/d), 1/θ^(2/d), ..., 1/θ^((d-2)/d)] freqs = 1.0 / (rope_theta ** (dim_t / head_dim)) # 对每个位置计算角度 # position_ids: [batch, seq_len] -> [batch, seq_len, 1] # freqs: [head_dim/2] -> [1, 1, head_dim/2] # angles: [batch, seq_len, head_dim/2] position_ids_expanded = position_ids.unsqueeze(-1).float() angles = position_ids_expanded @ freqs.unsqueeze(0) # 计算cos和sin cos = angles.cos() # [batch, seq_len, head_dim/2] sin = angles.sin() # 复制以匹配head_dim cos = torch.cat([cos, cos], dim=-1) # [batch, seq_len, head_dim] sin = torch.cat([sin, sin], dim=-1) # 应用旋转 # q和k的每一对维度(x, y)会被旋转 def rotate_half(x): """辅助函数:将向量的后半部分移到前面并取反""" x1, x2 = x.chunk(2, dim=-1) return torch.cat([-x2, x1], dim=-1) q_embed = (q * cos) + (rotate_half(q) * sin) k_embed = (k * cos) + (rotate_half(k) * sin) return q_embed, k_embed这种方法在纯文本模型中效果很好,但对于多模态输入存在局限:它只能建模一维的序列顺序,无法表达图像patch之间的2D空间关系。
5.2 Multi-dimensional RoPE (MRoPE)
为了解决这个问题,Qwen2-VL引入了MRoPE,为每个位置分配三个position ID:temporal、height和width。这样,每个图像patch都有明确的时空坐标,模型可以区分在不同维度上的相对位置。
# 为图像patch生成3D position IDsdef get_3d_position_ids(image_grid_thw): """ 为图像生成时间、高度、宽度三个维度的position IDs Args: image_grid_thw: [num_images, 3], 每张图的(T, H, W) Returns: position_ids: [3, total_tokens], 三个维度的position IDs """ import torch position_ids_list = [] for t, h, w in image_grid_thw: # 生成每个维度的坐标 # temporal: [0,0,0,...,0, 1,1,1,...,1, ..., t-1,t-1,t-1,...,t-1] t_ids = torch.arange(t, dtype=torch.long).repeat_interleave(h * w) # height: [0,0,...,0, 1,1,...,1, ..., h-1,h-1,...,h-1] (重复t次) h_ids = torch.arange(h, dtype=torch.long).repeat_interleave(w).repeat(t) # width: [0,1,2,...,w-1, 0,1,2,...,w-1, ...] (重复t*h次) w_ids = torch.arange(w, dtype=torch.long).repeat(t * h) # 堆叠三个维度 position_ids = torch.stack([t_ids, h_ids, w_ids], dim=0) position_ids_list.append(position_ids) return torch.cat(position_ids_list, dim=1)# 示例:一张2×3的图像(简化)# patches布局:# [p0, p1, p2] # t=0# [p3, p4, p5] # t=1## position_ids:# temporal: [0, 0, 0, 1, 1, 1]# height: [0, 0, 0, 0, 0, 0] (只有一行)# width: [0, 1, 2, 0, 1, 2]有了三维position ID后,需要为每个维度分别计算RoPE,然后组合起来。原始的MRoPE实现是将head_dim按维度分块:前1/3用于temporal,中间1/3用于height,后1/3用于width。
5.3 MRoPE-Interleave的改进
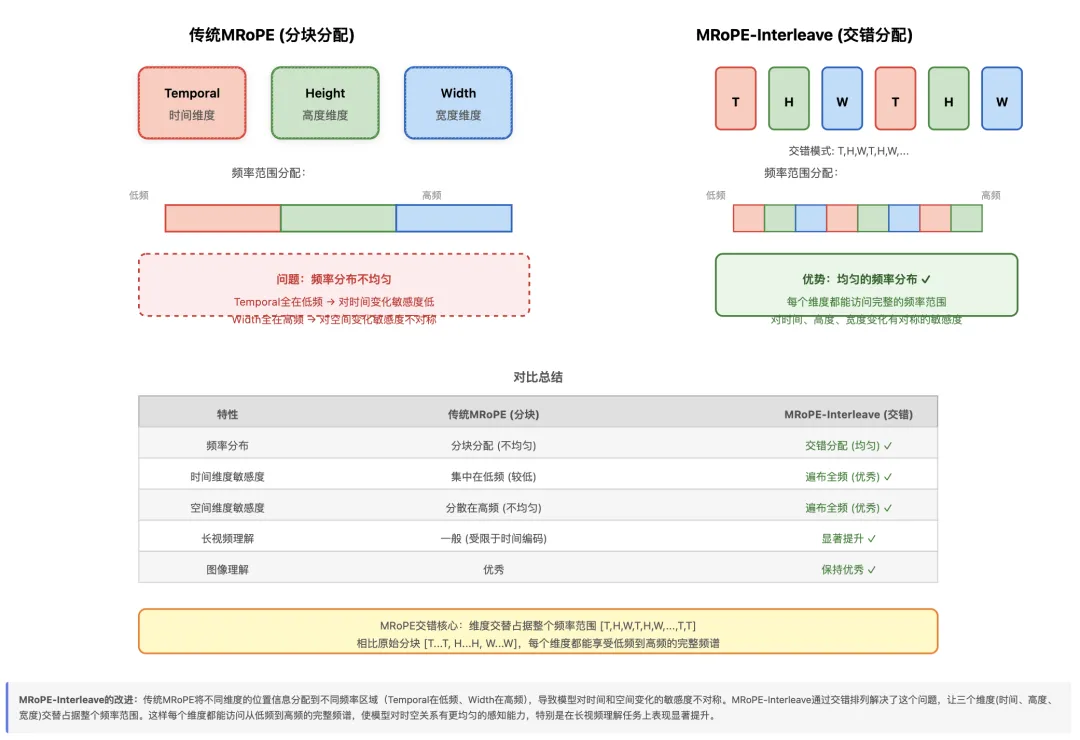
Qwen3-VL发现原始MRoPE存在一个问题:将不同维度的位置信息分配到不同频率区域会导致对时空关系的感知不平衡。具体来说,temporal信息全部位于低频区域,而width信息全部位于高频区域。由于RoPE的频率是指数衰减的,这意味着模型对时间和空间变化的敏感度是不对称的。
MRoPE-Interleave通过交错排列解决了这个问题。不再按块划分,而是让三个维度交替占据整个频率范围,使每个维度都能享受到从低频到高频的完整频谱。
def apply_mrope_interleave(freqs, position_ids, mrope_section=[24, 20, 20]): """ 将3D的RoPE频率进行交错排列 Args: freqs: 三个维度各自计算的频率 position_ids: [3, seq_len] mrope_section: 每个维度占用的位置数 Returns: interleaved_freqs: 交错后的频率 """ import torch # freqs[0]: temporal维度的频率 # freqs[1]: height维度的频率 # freqs[2]: width维度的频率 freqs_t = freqs[0].clone() # 交错策略:[T, H, W, T, H, W, ..., T, T] # 对于head_dim/2=64的情况(mrope_section=[24, 20, 20]): # - 位置0: temporal # - 位置1: height (从freqs[1]取) # - 位置2: width (从freqs[2]取) # - 位置3: temporal # - 位置4: height # ... # - 位置60-63: temporal (因为mrope_section[0]=24 > 20) for dim in [1, 2]: # height, width length = mrope_section[dim] * 3 # 每隔3个位置取一个 indices = slice(dim, length, 3) freqs_t[..., indices] = freqs[dim, ..., indices] return freqs_t# 可视化交错模式# 假设head_dim/2=64, mrope_section=[24, 20, 20]# 每个位置的维度分配:# [T, H, W, T, H, W, T, H, W, ..., T, H, W, T, T, T, T]# ^ ^ ^ ^ ^^^^^# 0-2 3-5 6-8 57-59 60-63## 前60个位置严格交错,最后4个全是T(因为T有24个位置,H和W各20个)这种交错设计带来了几个好处:
-
1. 均匀的频率分布:每个维度都能访问不同频率的位置编码 -
2. 相互增强:相邻维度的位置编码在频率空间中相互交织,有利于学习它们之间的关联 -
3. 对称的敏感度:模型对时间、高度和宽度变化有更均匀的感知能力
实验表明,相比原始MRoPE,Interleave版本在长视频理解任务上表现更好,同时保持了在图像理解任务上的性能。
5.4 完整的MRoPE-Interleave实现
class Qwen3VLRotaryEmbedding(nn.Module): def __init__(self, config): super().__init__() self.rope_type = config.rope_scaling.get("rope_type", "default") self.max_seq_len = config.max_position_embeddings # RoPE参数 head_dim = config.hidden_size // config.num_attention_heads rope_dim = head_dim // 2 rope_theta = config.rope_theta # 计算inverse frequencies dim_indices = torch.arange(0, rope_dim, 2, dtype=torch.float32) inv_freq = 1.0 / (rope_theta ** (dim_indices / rope_dim)) self.register_buffer("inv_freq", inv_freq) # MRoPE配置: [temporal, height, width]的维度分配 self.mrope_section = config.rope_scaling.get("mrope_section", [24, 20, 20]) def forward(self, x, position_ids): """ Args: x: 用于获取device和dtype position_ids: [3, batch, seq_len], 三维position IDs Returns: cos, sin: 用于RoPE的cos和sin矩阵 """ # position_ids shape: [3, batch, seq_len] # 扩展inv_freq以匹配3个维度 inv_freq_expanded = self.inv_freq[None, None, :, None] # [1, 1, rope_dim/2, 1] inv_freq_expanded = inv_freq_expanded.expand(3, position_ids.shape[1], -1, 1) # 扩展position_ids position_ids_expanded = position_ids[:, :, None, :].float() # [3, batch, 1, seq_len] # 计算每个维度的频率: [3, batch, seq_len, rope_dim/2] freqs = (inv_freq_expanded @ position_ids_expanded).transpose(2, 3) # 应用Interleave freqs = self.apply_interleaved_mrope(freqs, self.mrope_section) # 复制以匹配完整的head_dim emb = torch.cat([freqs, freqs], dim=-1) # [batch, seq_len, rope_dim] # 计算cos和sin cos = emb.cos() sin = emb.sin() return cos, sin def apply_interleaved_mrope(self, freqs, mrope_section): """应用交错策略""" freqs_t = freqs[0] for dim, offset in enumerate((1, 2), start=1): length = mrope_section[dim] * 3 idx = slice(offset, length, 3) freqs_t[..., idx] = freqs[dim, ..., idx] return freqs_t在实际使用中,这个模块在每个attention层被调用,为query和key向量提供位置编码。通过MRoPE-Interleave,Qwen3-VL能够准确建模图像patch的空间关系、视频帧的时序关系、以及文本token的顺序关系,为多模态理解提供了坚实的位置感知基础。
6. 模型架构深度剖析
理解了各个关键组件后,我们需要看到它们是如何协同工作的。Qwen3-VL的完整架构可以分为三个主要阶段:输入处理、特征提取与融合、输出生成。
6.1 输入处理阶段
这个阶段的目标是将多模态输入转换为统一的embedding序列。处理流程从Processor开始,它协调Image Processor和Tokenizer分别处理图像和文本。
class Qwen3VLProcessor: def __call__(self, messages, return_tensors="pt"): """ 统一处理多模态输入 Args: messages: 对话格式的输入,可以包含文本、图像、视频 Returns: 包含input_ids, pixel_values, image_grid_thw等的字典 """ # 1. 应用chat template,将消息转换为文本序列 # 图像位置会被标记为<|image_pad|> text = self.tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) # 2. 提取图像和视频 images = [] videos = [] for message in messages: if isinstance(message.get("content"), list): for item in message["content"]: if item.get("type") == "image": images.append(self.image_processor.load_image(item)) elif item.get("type") == "video": videos.append(self.video_processor.load_video(item)) # 3. 处理图像,得到pixel_values和grid信息 image_inputs = self.image_processor(images, return_tensors=return_tensors) pixel_values = image_inputs["pixel_values"] image_grid_thw = image_inputs["image_grid_thw"] # 4. 为图像预留位置 # 计算每张图像需要多少个token merge_size_sq = self.image_processor.merge_size ** 2 for i, grid_thw in enumerate(image_grid_thw): # 每张图像的token数 = (T * H * W) // 4 num_tokens = int(grid_thw.prod() // merge_size_sq) # 将第i个<|image_pad|>替换为num_tokens个<|image_pad|> text = text.replace( "<|image_pad|>", "<|image_pad|>" * num_tokens, 1 # 只替换第一次出现 ) # 5. Tokenize文本 text_inputs = self.tokenizer( text, return_tensors=return_tensors, padding=True ) # 6. 合并所有输入 return { "input_ids": text_inputs["input_ids"], "attention_mask": text_inputs["attention_mask"], "pixel_values": pixel_values, "image_grid_thw": image_grid_thw, }这个处理过程的巧妙之处在于,通过在文本中预留占位符,后续可以精确地知道应该在哪些位置插入图像特征。每个<|image_pad|>token在embedding阶段会被初始化为一个可学习的特殊向量,然后在特征融合阶段被实际的视觉特征替换。

6.2 特征提取与融合阶段
这是模型的核心计算阶段,包括视觉编码和多模态融合两个关键步骤。
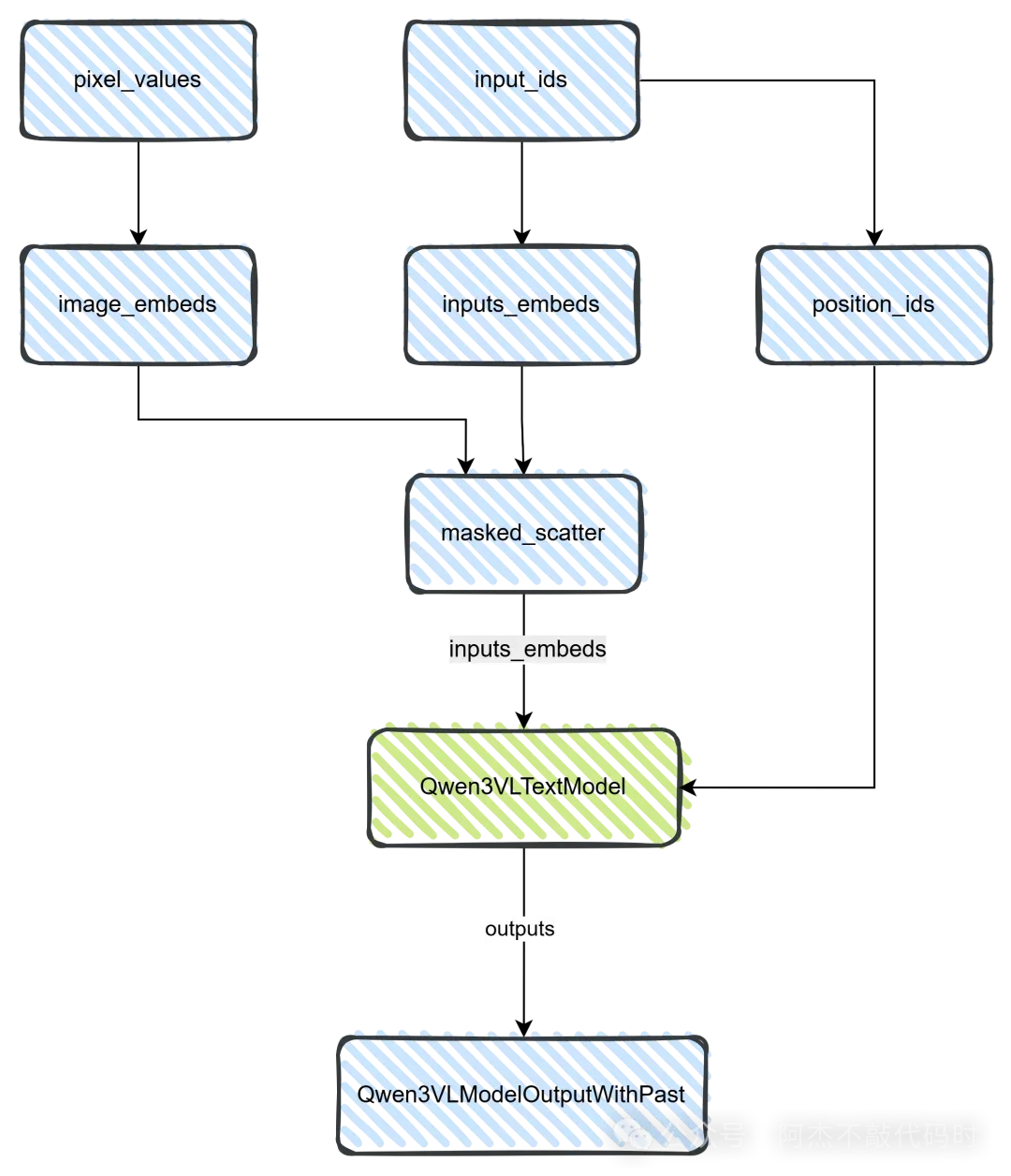
class Qwen3VLModel(nn.Module): def forward( self, input_ids, pixel_values, image_grid_thw, attention_mask=None, position_ids=None, **kwargs): """主模型的前向传播""" # ========== 第一步:获取文本embedding ========== inputs_embeds = self.get_input_embeddings()(input_ids) # inputs_embeds: [batch, seq_len, hidden_size] # ========== 第二步:视觉编码 ========== if pixel_values is not None: # 通过视觉编码器提取特征 image_embeds, deepstack_embeds = self.visual( pixel_values, grid_thw=image_grid_thw ) # image_embeds: [total_image_tokens, hidden_size] # deepstack_embeds: 3个[total_image_tokens, hidden_size]的列表 # ========== 第三步:特征融合 ========== # 找到inputs_embeds中哪些位置是<|image_pad|> image_token_id = self.config.image_token_id image_mask = (input_ids == image_token_id) # 扩展mask以匹配hidden_size维度 image_mask = image_mask.unsqueeze(-1).expand_as(inputs_embeds) # 将image_embeds插入到对应位置 # masked_scatter会把image_embeds按顺序填充到mask为True的位置 inputs_embeds = inputs_embeds.masked_scatter( image_mask, image_embeds.to(inputs_embeds.dtype) ) # ========== 第四步:生成position_ids ========== if position_ids is None: position_ids, rope_deltas = self.get_rope_index( input_ids, image_grid_thw, attention_mask ) # ========== 第五步:语言模型处理 ========== # visual_pos_masks标记哪些位置是视觉token visual_pos_masks = image_mask[..., 0] if pixel_values is not None else None outputs = self.language_model( inputs_embeds=inputs_embeds, attention_mask=attention_mask, position_ids=position_ids, visual_pos_masks=visual_pos_masks, deepstack_visual_embeds=deepstack_embeds, **kwargs ) return outputs特征融合使用的masked_scatter操作是PyTorch提供的高效实现,它能够在保持其他位置不变的情况下,将源张量的值按顺序复制到目标张量中mask为True的位置。这比显式的循环赋值要快得多。
6.3 Position IDs的生成
Position IDs的生成是一个复杂但重要的过程,需要考虑文本和图像的不同特性。
def get_rope_index( self, input_ids, image_grid_thw, attention_mask=None): """ 生成3D position IDs,用于MRoPE Returns: position_ids: [3, batch, seq_len] rope_deltas: [batch, 1], 用于generation时的position id调整 """ import torch spatial_merge_size = self.config.vision_config.spatial_merge_size image_token_id = self.config.image_token_id vision_start_token_id = self.config.vision_start_token_id batch_size, seq_len = input_ids.shape # 初始化3D position IDs position_ids = torch.ones( 3, batch_size, seq_len, dtype=input_ids.dtype, device=input_ids.device ) # 为每个样本单独处理 for i in range(batch_size): # 找到所有<|vision_start|>的位置 vision_start_indices = torch.where( input_ids[i] == vision_start_token_id )[0] # 检查每个vision token是图像还是视频 # <|vision_start|>后面紧跟<|image_pad|>或<|video_pad|> current_pos = 0 # 当前的position id image_idx = 0 # 当前处理到第几张图像 for vis_start_idx in vision_start_indices: # 处理vision token之前的文本 text_len = vis_start_idx - current_pos if text_len > 0: # 文本部分:三个维度的position id相同,按顺序递增 text_pos = torch.arange(text_len) + current_pos for dim in range(3): position_ids[dim, i, current_pos:vis_start_idx] = text_pos # 处理vision token # 从image_grid_thw获取这张图像的尺寸 t, h, w = image_grid_thw[image_idx] llm_grid_h = h // spatial_merge_size llm_grid_w = w // spatial_merge_size llm_grid_t = t # temporal维度已经在视觉编码器中处理 # 为vision token生成3D position ids vision_len = llm_grid_t * llm_grid_h * llm_grid_w # Temporal dimension: [0,0,...,0, 1,1,...,1, ..., t-1,t-1,...,t-1] t_ids = torch.arange(llm_grid_t, device=input_ids.device).repeat_interleave(llm_grid_h * llm_grid_w) # Height dimension: [0,0,...,0, 1,1,...,1, ..., h-1,h-1,...,h-1] h_ids = torch.arange(llm_grid_h, device=input_ids.device).repeat_interleave(llm_grid_w).repeat(llm_grid_t) # Width dimension: [0,1,2,...,w-1, 0,1,2,...,w-1, ...] w_ids = torch.arange(llm_grid_w, device=input_ids.device).repeat(llm_grid_t * llm_grid_h) # 填充到position_ids vis_end_idx = vis_start_idx + vision_len position_ids[0, i, vis_start_idx:vis_end_idx] = t_ids + current_pos position_ids[1, i, vis_start_idx:vis_end_idx] = h_ids + current_pos position_ids[2, i, vis_start_idx:vis_end_idx] = w_ids + current_pos current_pos = vis_end_idx image_idx += 1 # 处理最后的文本部分 if current_pos < seq_len: text_len = seq_len - current_pos text_pos = torch.arange(text_len, device=input_ids.device) + current_pos for dim in range(3): position_ids[dim, i, current_pos:] = text_pos # 计算rope_deltas(用于generation时的增量更新) rope_deltas = position_ids.max(dim=2)[0].max(dim=0)[0] + 1 - seq_len return position_ids, rope_deltas这个复杂的position id生成过程确保了:
-
1. 文本token按线性顺序编码 -
2. 图像token按2D空间结构编码,同时保持与前后文本的连续性 -
3. 视频token额外考虑时间维度
这种精细的位置编码是Qwen3-VL能够准确理解多模态内容的关键基础。
6.4 输出生成阶段
经过语言模型处理后,最后一步是生成实际的输出token。这由一个简单的线性层(lm_head)完成,它将hidden states投影到词表大小的logits。
class Qwen3VLForConditionalGeneration(nn.Module): def forward(self, input_ids, pixel_values, image_grid_thw, labels=None, **kwargs): """顶层模型,包含loss计算""" # 获取语言模型的输出 outputs = self.model( input_ids=input_ids, pixel_values=pixel_values, image_grid_thw=image_grid_thw, **kwargs ) hidden_states = outputs.last_hidden_state # hidden_states: [batch, seq_len, hidden_size] # 投影到词表空间 logits = self.lm_head(hidden_states) # logits: [batch, seq_len, vocab_size] # 如果提供了labels,计算loss loss = None if labels is not None: # 标准的语言模型loss:交叉熵 # 注意:通常需要shift操作,因为预测的是下一个token shift_logits = logits[..., :-1, :].contiguous() shift_labels = labels[..., 1:].contiguous() loss_fct = nn.CrossEntropyLoss(ignore_index=-100) loss = loss_fct( shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1) ) return Qwen3VLCausalLMOutputWithPast( loss=loss, logits=logits, past_key_values=outputs.past_key_values, hidden_states=outputs.hidden_states, attentions=outputs.attentions, )在训练阶段,loss计算会忽略padding和图像token(通过label设为-100),只对实际的文本生成位置计算损失。在推理阶段,通过beam search或sampling从logits中选择下一个token,支持自回归生成任意长度的文本响应。
7. Training 细节与优化策略
7.1 数据准备与预处理
import torchfrom torch.utils.data import Dataset, DataLoaderclass Qwen3VLDataset(Dataset): """多模态训练数据集""" def __init__(self, data_list, processor, max_seq_length=2048): self.data_list = data_list self.processor = processor self.max_seq_length = max_seq_length def __len__(self): return len(self.data_list) def __getitem__(self, idx): sample = self.data_list[idx] # 构建messages messages = [ { "role": "user", "content": [ {"type": "image", "image": sample["image"]}, {"type": "text", "text": sample["question"]} ] }, { "role": "assistant", "content": sample["answer"] } ] # 处理输入 inputs = self.processor.apply_chat_template( messages, tokenize=True, return_dict=True, return_tensors="pt" ) # 生成labels # 对于user部分,label设为-100(不计算loss) # 对于assistant部分,label为实际token_id input_ids = inputs["input_ids"].squeeze(0) labels = input_ids.clone() # 找到assistant开始位置 assistant_start = None for i in range(len(input_ids) - 5): if (input_ids[i:i+6] == torch.tensor([ self.processor.tokenizer.convert_tokens_to_ids("<|im_start|>"), # ... assistant token id ... ])).all(): assistant_start = i break if assistant_start is not None: # user部分的token设为-100 labels[:assistant_start] = -100 # 同时,padding部分也设为-100 if "attention_mask" in inputs: padding_mask = inputs["attention_mask"].squeeze(0) == 0 labels[padding_mask] = -100 return { "input_ids": inputs["input_ids"].squeeze(0), "attention_mask": inputs.get("attention_mask", torch.ones_like(input_ids)).squeeze(0), "pixel_values": inputs.get("pixel_values"), "image_grid_thw": inputs.get("image_grid_thw"), "labels": labels }def collate_fn(batch): """自定义collate函数,处理变长输入""" import torch # 分离各个字段 input_ids_list = [item["input_ids"] for item in batch] attention_mask_list = [item["attention_mask"] for item in batch] pixel_values_list = [item["pixel_values"] for item in batch] image_grid_thw_list = [item["image_grid_thw"] for item in batch] labels_list = [item["labels"] for item in batch] # Pad input_ids和attention_mask到同一长度 max_len = max(len(ids) for ids in input_ids_list) input_ids_padded = [] attention_mask_padded = [] labels_padded = [] for input_ids, attention_mask, labels in zip( input_ids_list, attention_mask_list, labels_list ): pad_len = max_len - len(input_ids) input_ids_padded.append(torch.cat([ input_ids, torch.full((pad_len,), tokenizer.pad_token_id, dtype=input_ids.dtype) ])) attention_mask_padded.append(torch.cat([ attention_mask, torch.zeros(pad_len, dtype=attention_mask.dtype) ])) labels_padded.append(torch.cat([ labels, torch.full((pad_len,), -100, dtype=labels.dtype) ])) # Concatenate pixel_values和image_grid_thw pixel_values_cat = None image_grid_thw_cat = None if pixel_values_list[0] is not None: pixel_values_cat = torch.cat(pixel_values_list, dim=0) if image_grid_thw_list[0] is not None: image_grid_thw_cat = torch.cat(image_grid_thw_list, dim=0) return { "input_ids": torch.stack(input_ids_padded), "attention_mask": torch.stack(attention_mask_padded), "labels": torch.stack(labels_padded), "pixel_values": pixel_values_cat, "image_grid_thw": image_grid_thw_cat, }7.2 训练循环与优化
import torchimport torch.optim as optimfrom transformers import get_cosine_schedule_with_warmupdef train_qwen3vl( model, train_dataloader, val_dataloader, num_epochs=3, learning_rate=1e-4, weight_decay=0.01, warmup_steps=1000,): """ Qwen3-VL完整训练流程 """ # 设置设备 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model = model.to(device) # 分离vision和language model的参数 # Vision encoder通常使用较低的学习率 vision_params = model.model.visual.parameters() llm_params = list(model.model.language_model.parameters()) + list(model.lm_head.parameters()) optimizer = optim.AdamW([ {"params": vision_params, "lr": learning_rate * 0.1}, # 视觉编码器学习率更低 {"params": llm_params, "lr": learning_rate} ], weight_decay=weight_decay) # 学习率调度 total_steps = len(train_dataloader) * num_epochs scheduler = get_cosine_schedule_with_warmup( optimizer, num_warmup_steps=warmup_steps, num_training_steps=total_steps ) # 混合精度训练 from torch.cuda.amp import autocast, GradScaler scaler = GradScaler() model.train() for epoch in range(num_epochs): total_loss = 0 for step, batch in enumerate(train_dataloader): # 移动数据到设备 input_ids = batch["input_ids"].to(device) attention_mask = batch["attention_mask"].to(device) labels = batch["labels"].to(device) pixel_values = batch["pixel_values"].to(device) if batch["pixel_values"] is not None else None image_grid_thw = batch["image_grid_thw"].to(device) if batch["image_grid_thw"] is not None else None # 混合精度前向传播 with autocast(): outputs = model( input_ids=input_ids, attention_mask=attention_mask, pixel_values=pixel_values, image_grid_thw=image_grid_thw, labels=labels ) loss = outputs.loss # 反向传播(梯度缩放) scaler.scale(loss).backward() # 梯度累积(如需要) if (step + 1) % 4 == 0: # 梯度裁剪 scaler.unscale_(optimizer) torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) # 优化器步骤 scaler.step(optimizer) scaler.update() scheduler.step() optimizer.zero_grad() total_loss += loss.item() if (step + 1) % 100 == 0: avg_loss = total_loss / (step + 1) print(f"Epoch {epoch+1}, Step {step+1}, Loss: {avg_loss:.4f}") # 验证 model.eval() val_loss = 0 with torch.no_grad(): for batch in val_dataloader: input_ids = batch["input_ids"].to(device) attention_mask = batch["attention_mask"].to(device) labels = batch["labels"].to(device) pixel_values = batch["pixel_values"].to(device) if batch["pixel_values"] is not None else None image_grid_thw = batch["image_grid_thw"].to(device) if batch["image_grid_thw"] is not None else None outputs = model( input_ids=input_ids, attention_mask=attention_mask, pixel_values=pixel_values, image_grid_thw=image_grid_thw, labels=labels ) val_loss += outputs.loss.item() avg_val_loss = val_loss / len(val_dataloader) print(f"Epoch {epoch+1}, Validation Loss: {avg_val_loss:.4f}") model.train() # 保存checkpoint torch.save({ "epoch": epoch + 1, "model_state_dict": model.state_dict(), "optimizer_state_dict": optimizer.state_dict(), "scheduler_state_dict": scheduler.state_dict(), "loss": total_loss / len(train_dataloader) }, f"checkpoint_epoch_{epoch+1}.pt")7.3 关键训练技巧
# 1. LoRA微调(参数高效)from peft import get_peft_model, LoraConfiglora_config = LoraConfig( r=8, lora_alpha=16, target_modules=["q_proj", "v_proj"], # 在attention中应用LoRA lora_dropout=0.05, bias="none", task_type="CAUSAL_LM")model = get_peft_model(model, lora_config)# 2. Flash Attention优化# 在模型配置中启用 use_flash_attention_2 = True# 3. 梯度检查点(节省显存)model.gradient_checkpointing_enable()# 4. 冻结视觉编码器早期层for param in model.model.visual.blocks[:13].parameters(): param.requires_grad = False# 5. 使用deepspeed进行大规模训练# 配置deepspeed_config.json并使用deepspeed launch8. 视觉编码器的实现细节
8.1 Patch Embedding层
class Qwen3VLVisionPatchEmbed(nn.Module): """3D Patch Embedding,同时处理空间和时间维度""" def __init__(self, config): super().__init__() self.patch_size = config.patch_size # 16 self.temporal_patch_size = config.temporal_patch_size # 2 self.in_channels = config.in_channels # 3 self.hidden_size = config.hidden_size # 1664 # 3D卷积:同时在时间和空间维度做patch化 self.proj = nn.Conv3d( in_channels=self.in_channels, out_channels=self.hidden_size, kernel_size=( self.temporal_patch_size, # 时间: (2,) self.patch_size, # 高: 16 self.patch_size # 宽: 16 ), stride=( self.temporal_patch_size, self.patch_size, self.patch_size ), padding=0 ) def forward(self, pixel_values): """ Args: pixel_values: [num_patches, 3*2*16*16] = [num_patches, 1536] Returns: embeddings: [num_patches, hidden_size] """ import torch # 首先需要重构回3D形状 num_patches = pixel_values.shape[0] pixel_values = pixel_values.reshape( num_patches, self.in_channels, self.temporal_patch_size, self.patch_size, self.patch_size ) # 调整维度顺序以匹配Conv3d的期望输入 [B, C, T, H, W] # pixel_values已经是 [B, C, T, H, W] 的形式 # 应用3D卷积 embeddings = self.proj(pixel_values) # 展平空间维度 # Conv3d输出: [num_patches, hidden_size, 1, 1, 1] embeddings = embeddings.flatten(2).transpose(1, 2) # 结果: [num_patches, 1, hidden_size] return embeddings.squeeze(1)使用3D卷积而非简单的线性层有几个优势:它能更好地捕捉patch内部的局部结构;卷积的归纳偏置有助于学习平移不变性;对于视频输入,能够自然地融合相邻帧的信息。
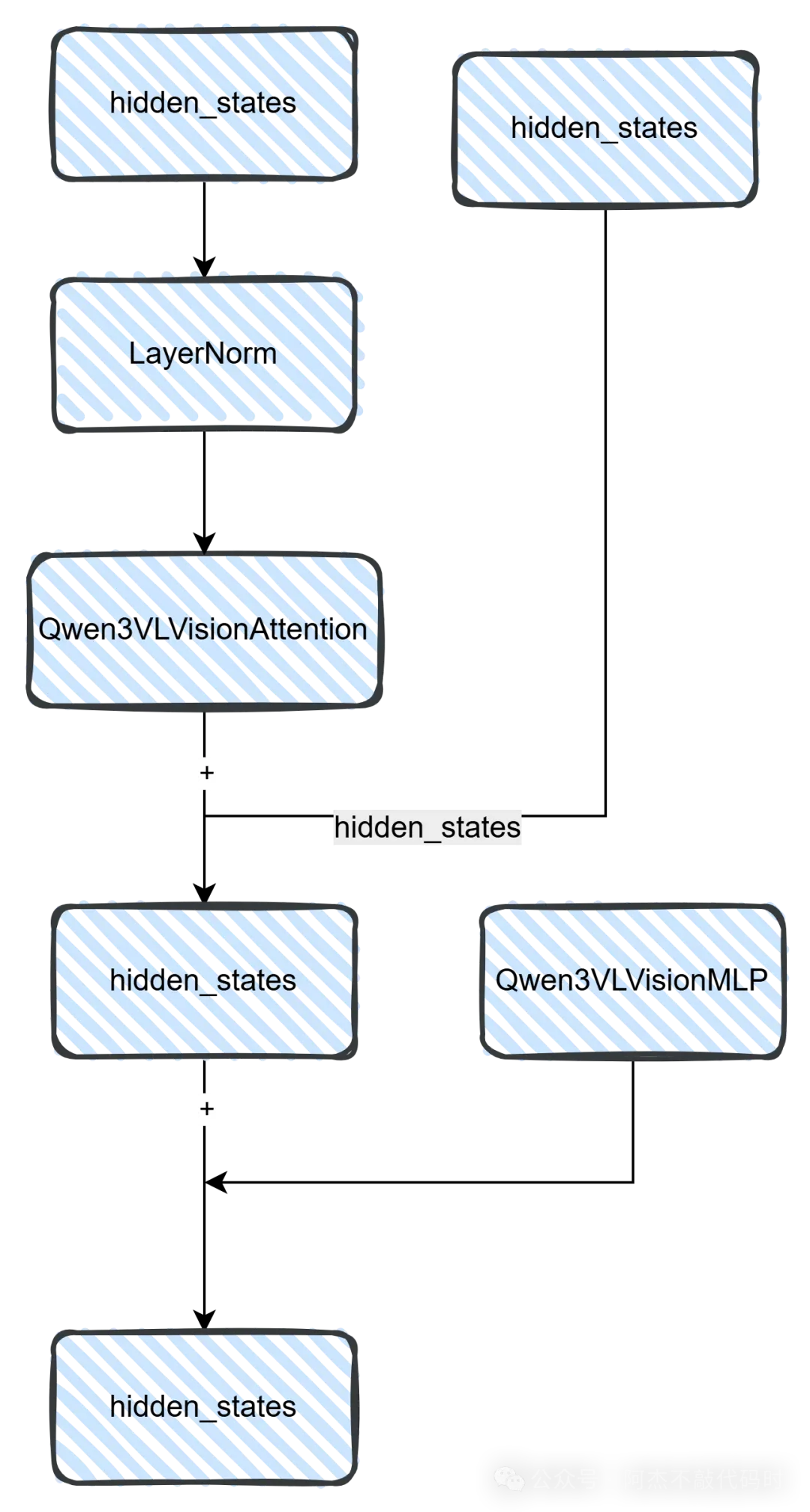
8.2 Vision Transformer Block
class Qwen3VLVisionBlock(nn.Module): """Vision Transformer Block,采用Pre-norm架构""" def __init__(self, config): super().__init__() self.norm1 = nn.LayerNorm(config.hidden_size) self.norm2 = nn.LayerNorm(config.hidden_size) self.attn = Qwen3VLVisionAttention(config) self.mlp = Qwen3VLVisionMLP(config) def forward(self, hidden_states, cu_seqlens, position_embeddings): """ Args: hidden_states: [total_patches, hidden_size] cu_seqlens: cumulative sequence lengths,用于flash attention position_embeddings: RoPE的cos/sin矩阵 """ # Pre-norm架构:先norm再attention residual = hidden_states hidden_states = self.norm1(hidden_states) # Self-attention with RoPE hidden_states = self.attn( hidden_states, cu_seqlens=cu_seqlens, position_embeddings=position_embeddings ) hidden_states = residual + hidden_states # FFN (Feed-Forward Network) residual = hidden_states hidden_states = self.norm2(hidden_states) hidden_states = self.mlp(hidden_states) hidden_states = residual + hidden_states return hidden_statesclass Qwen3VLVisionAttention(nn.Module): """支持Flash Attention 2的多头自注意力""" def __init__(self, config): super().__init__() self.hidden_size = config.hidden_size self.num_heads = config.num_attention_heads self.head_dim = self.hidden_size // self.num_heads assert self.hidden_size % self.num_heads == 0 # QKV投影 self.qkv = nn.Linear(self.hidden_size, 3 * self.hidden_size, bias=True) # 输出投影 self.proj = nn.Linear(self.hidden_size, self.hidden_size, bias=True) def forward(self, hidden_states, cu_seqlens, position_embeddings): """使用Flash Attention 2加速的attention实现""" import torch from flash_attn import flash_attn_varlen_func seq_len = hidden_states.shape[0] # 计算QKV qkv = self.qkv(hidden_states) qkv = qkv.reshape(seq_len, 3, self.num_heads, self.head_dim) q, k, v = qkv.unbind(dim=1) # 应用RoPE cos, sin = position_embeddings q = apply_rotary_pos_emb_vision(q, cos, sin) k = apply_rotary_pos_emb_vision(k, cos, sin) # Flash Attention # cu_seqlens用于支持变长序列的高效计算 attn_output = flash_attn_varlen_func( q, k, v, cu_seqlens_q=cu_seqlens, cu_seqlens_k=cu_seqlens, max_seqlen_q=seq_len, max_seqlen_k=seq_len, dropout_p=0.0, causal=False # 视觉编码器不需要causal mask ) # 输出投影 attn_output = attn_output.reshape(seq_len, self.hidden_size) output = self.proj(attn_output) return output使用Flash Attention带来了显著的性能提升,特别是对于高分辨率图像。cu_seqlens(cumulative sequence lengths)参数允许在一个batch中高效处理不同尺寸的图像,避免了padding带来的计算浪费。
9. 总结与展望
通过本文的深入分析,我们全面了解了Qwen3-VL的技术实现。从Chat Template的灵活输入处理,到视觉处理流水线的动态分辨率支持,再到DeepStack的多层特征融合和MRoPE-Interleave的改进位置编码,每个组件都体现了精心的设计和优化。
参考资料
https://zhuanlan.zhihu.com/p/717884243
https://mp.weixin.qq.com/s/k4H7LNyZJ8FxAJrEHc9REw
https://mp.weixin.qq.com/s/NAQzVRUrfU19pSh5087X7Q
更多 ROS、具身智能相关内容,请关注古月居 👍
点点关注点点赞,发现更多自动驾驶/具身智能/GitHub 有趣内容! 🚀
往期内容回顾 👀🔥 自动驾驶 | CREStE: 基于反事实表征与互联网先验的可扩展无地图导航🔥 具身智能 | 机器学习分类全面指南:从迁移学习到联邦学习🔥 十分钟实用教程 | 不用服务器也能玩OpenClaw?——基于Ollama的边缘AI协作实战