传统机器学习——AI世界里最重要的角色,凌晨三点替你拦下了一笔盗刷
支付宝之前公布过一个数据,在它平台上每天有上亿笔交易,每一笔从你按下”确认”到钱出去,中间有一道扫描。
这背后有一组模型每天7×24小时盯着数亿笔交易,给每一笔打分,把可疑的拦下来。靠着这些模型,支付宝的欺诈损失率降到了国外同类支付公司的1/200。
替你按下这道拦截键的,不是现在的大模型,而是一个1959年就有人提出概念的老技术。
2026年聊AI,大家嘴里的词都差不多——大模型、Agent、AGI、Vibe Coding。微信里每天都有人转发”某某AI又颠覆了某某行业”,支付宝首页推的是AI理财助手,钉钉、飞书都在往对话框里塞AI入口。”会用AI”成了一种新的职场竞争力,感觉不跟上就要被时代抛下。
但如果你问大多数人”AI是什么”,他们给你的答案几乎都是同一个:ChatGPT那样的东西,或者国内的豆包、文心一言、Kimi。
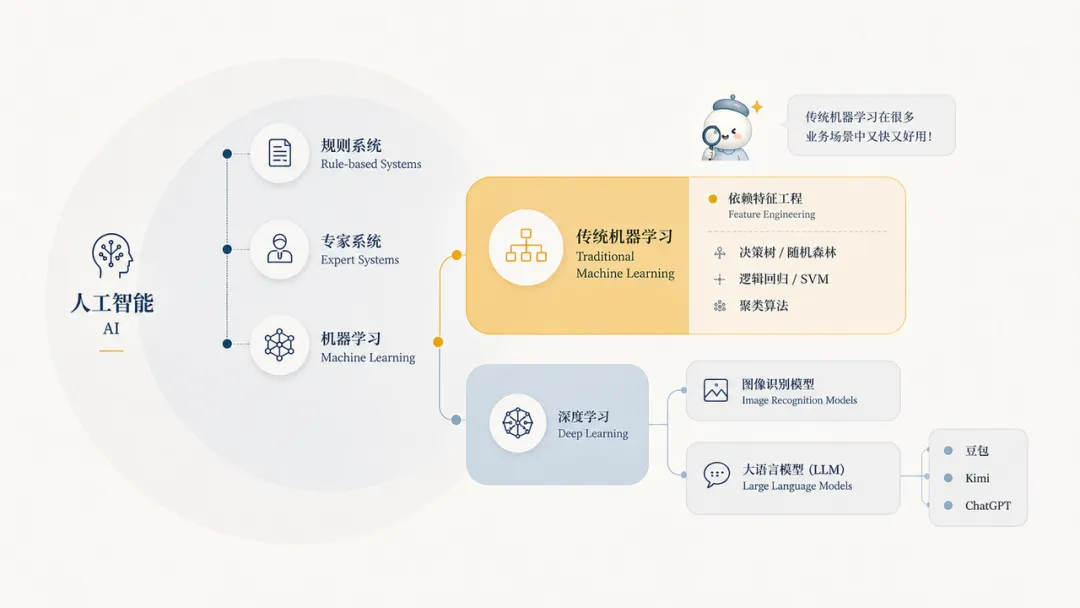
AI其实是一个套娃。最外面那层叫”人工智能”,凡是让机器表现得像有智慧的技术,都算。往里一层叫”机器学习”,是让机器从数据里自己找规律,而不是靠人一条条写死规则。再往里一层叫”深度学习”,是机器学习里一个特别厉害的流派,用了一种模仿大脑神经元结构的方法。最里面那层,才是大家最熟悉的大语言模型——豆包、Kimi、ChatGPT这些,都住在这里。
所以你每次用豆包、Kimi,用的是最里面那一层。但AI世界里大部分真正在运转的东西,住在更外面的那几层——尤其是”传统机器学习”这一层。
所谓传统机器学习,说的是大约2012年之前就成熟的那批算法。那一年,深度学习在一场图像识别比赛里把所有人打懵了,从那以后,”传统机器学习”这个词就带上了一点”老前辈”的意味。
在讲它具体在做什么之前,先得搞清楚”机器学习”这四个字到底是什么意思。
很多人以为机器学习是机器在”学知识”,就像人读书一样。这个理解有点偏。更准确的说法是:机器学习是机器在找规律。
打个比方。假如你要让一个程序识别”这封邮件是不是垃圾邮件”,有两种做法。
第一种:你自己来写规则。”如果邮件里有’中奖’这个词,标记为垃圾邮件。””如果发件人地址里有一串奇怪的数字,标记为垃圾邮件。”你能想到多少条就写多少条。这叫传统编程,靠的是你的经验和脑子。
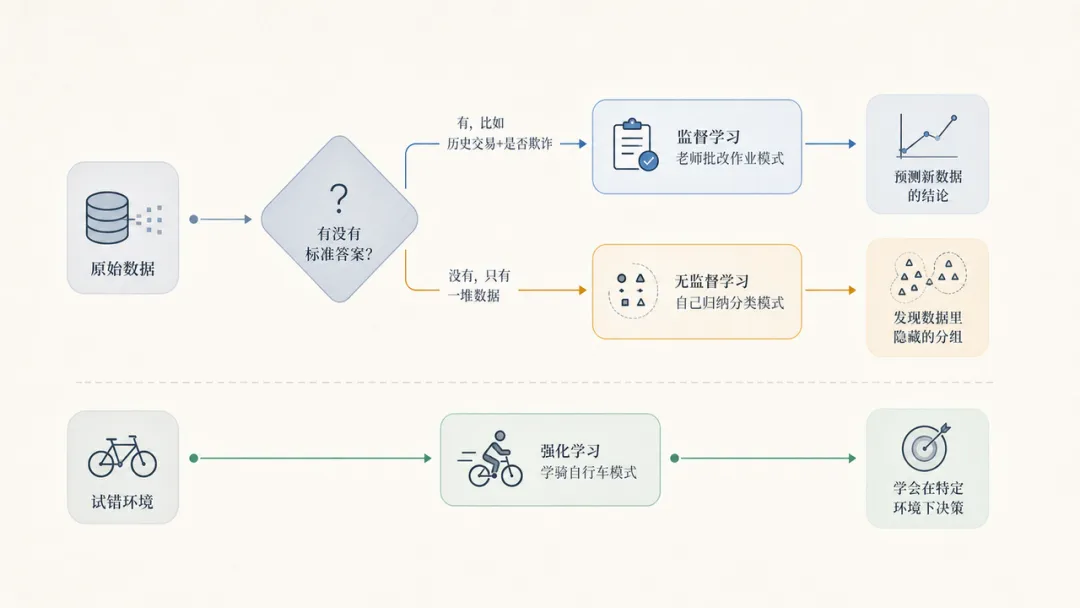
第二种:你不写规则,你喂数据。你把一百万封邮件丢给程序,同时告诉它每封是不是垃圾邮件。程序自己去找:什么样的邮件通常是垃圾邮件?有什么共同特征?找完之后,它就有了自己的判断能力——遇到新邮件,它能自己判断。这就是机器学习。
这个区别听起来简单,但背后的意义很大:你不需要提前知道所有规律,机器会自己从数据里挖。
绝大多数安全场景用的是第一种——监督学习。你喂给它历史数据,告诉它哪些是正常的、哪些是危险的,它就学会了判断。
但这里有一个关键问题,也是传统机器学习里最核心的一件事:你喂给机器的,不能是原始数据,而是经过加工的”特征”。
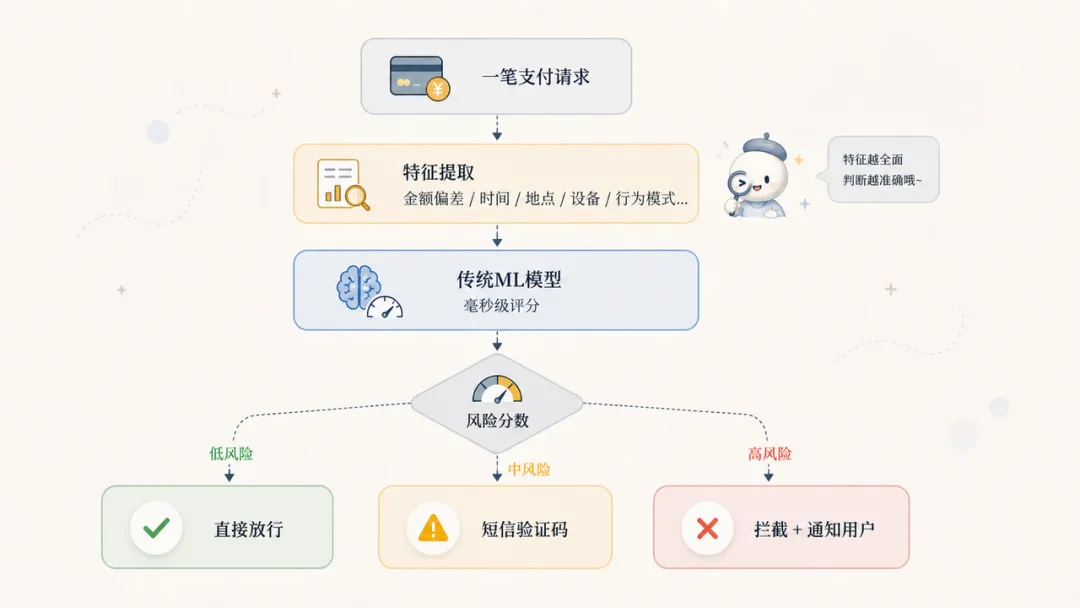
想象你要教一个从来没见过欺诈的人来识别可疑交易。你不能把一张银行流水单直接拍在他面前说”你自己看”。你得告诉他:要看什么。看金额有没有异常,看时间是不是凌晨,看地点和上次消费隔了多远,看这台设备有没有见过……
这个”告诉机器要看什么”的过程,在传统机器学习里叫做特征工程。
特征,就是你从原始数据里提炼出来的、对判断有用的信息。一笔交易的原始数据可能是一堆数字,但经过特征工程之后,它变成了几十个有意义的维度:这笔交易距离上一笔间隔了多少秒、金额偏离用户历史均值多少个百分比、商户类型和用户常用类型匹配度多少……
传统机器学习领域有一句行话,流传了几十年:”数据和特征决定了模型的上限,算法只是在逼近这个上限。”
换成人话:你教机器”看什么”比你用什么方法教它更重要。
这件事放到今天依然成立,而且在安全领域尤其关键。因为欺诈者会不断变换手法,但他们的行为模式里总有一些蛛丝马迹——只要你的特征设计得足够精准,模型就能捕捉到这些蛛丝马迹,哪怕它从没见过这种新型欺诈手法。
这也是为什么做信用卡风控的团队里,最值钱的往往不是写算法的工程师,而是那个最懂欺诈行为、能设计出精准特征的业务专家。
你可能会想:这种事,用豆包或者ChatGPT来判断不行吗?它们那么聪明。
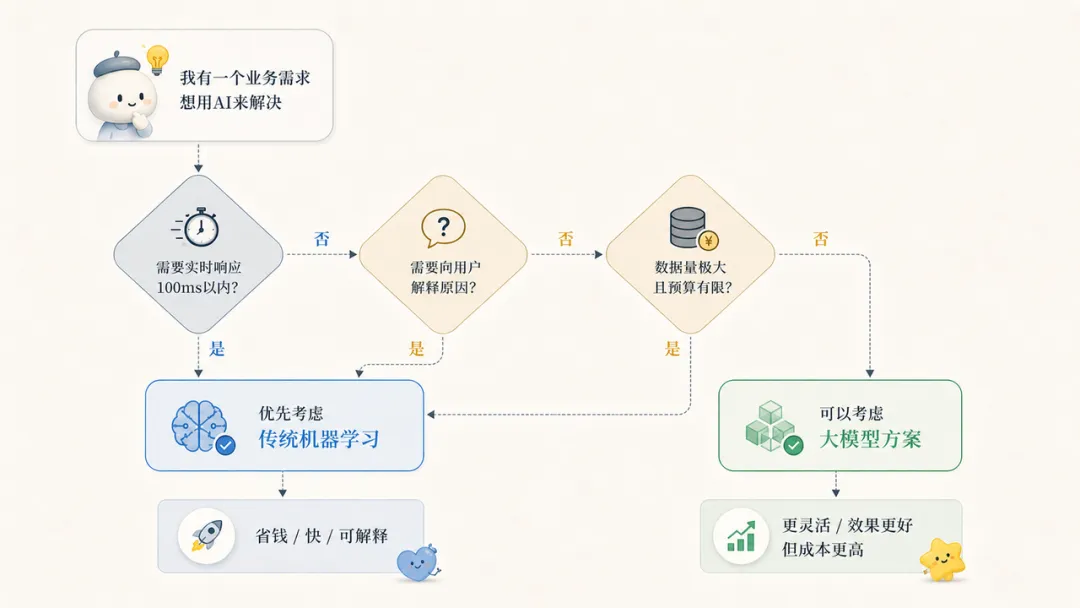
每天,国内的银行和支付系统要处理几十亿笔交易。每一笔都需要在你按下”确认支付”之后的几百毫秒内完成风险判断。大语言模型响应一次通常需要好几秒,成本也高——如果每笔交易都调一次大模型,光是这一项的算力成本就能让任何一家支付公司破产。
而且还有一个更关键的问题:说得清楚。银行拒绝一笔交易,是要能说清楚理由的——”这笔交易被我们的模型判断为高风险”不够,得说”因为这三个具体特征触发了风险规则”。大模型是个黑盒,它给你一个结论,但很难告诉你完整的推理路径。传统机器学习不一样,它的决策过程是可以被拆解和解释的。
模型会同时盯着几十个维度,而这些维度全都是经过精心设计的特征——不是原始的交易记录,而是从中提炼出来的有意义的信号:这笔交易的金额偏离你历史均值多少、发生的时间在你的常规消费时段之外多远、商户类型和你的偏好匹配度多少、这台设备有没有见过、IP地址距离你的常驻城市多远……这些信息在毫秒级别被整合,然后给出一个”这笔交易有多可疑”的分数。
有意思的地方在于,这个模型学到的规律,往往比人想到的规律更细腻。比如,”凌晨在异地用一台新设备连续小额消费五次”比”白天在本地刷了一笔大额”可疑得多——这不是人写进去的规则,是模型从几亿条历史数据里,通过那些精心设计的特征,自己悟出来的。
如果你用的是QQ邮箱或者163,答案可能是”很久了”。不是因为垃圾邮件消失了——每天全球发出的垃圾邮件数量还在几千亿封的量级——而是因为有个模型一直在帮你过滤,过滤得太好以至于你感觉不到它的存在。
它识别垃圾邮件的方式,也是特征驱动的:发件人的域名有没有见过、邮件里某些词的出现频率、HTML代码里有没有隐藏链接、发送时间和正常商业邮件的模式差异……这些特征组合在一起,让模型能在几毫秒内做出判断。
你在微博发一条内容,在小红书上传一张图,在抖音发一个视频。这些内容在你发出去之前或者发出去的瞬间,会经过一道自动审核。
原因同样是量级问题。抖音每天新增的视频内容是几千万条,小红书的笔记是几百万篇。如果每一条都调大模型来判断,成本是天文数字。实际的做法是:传统机器学习做粗筛,把明显有问题的和明显没问题的分开,只把那些”说不准”的边缘内容,才送去给更复杂的模型做精判。
传统机器学习是这条流水线上的第一道门,也是最重要的一道门——因为它挡住了95%的流量。
你家路由器,或者公司的网络防火墙,里面大概率跑着某种异常流量检测模型。它会学习”正常的网络访问是什么样的”,然后当出现不正常的模式时——比如某台设备突然开始以机器的速度向外发送大量数据——它会报警或者直接切断。
这同样是传统机器学习在做的事,安静、持续、不声不响。
一个可以帮你记住这一切的比喻:如果把AI世界比作一栋大楼,大模型是那个会写报告、能开会、能做创意的高级顾问,住在顶楼的玻璃办公室里。传统机器学习是那个在门口、在电梯间、在监控室、在每一道门背后工作的保安团队。
讲到这里,很多人会觉得这些东西和自己没什么关系——那是工程师的事。
但如果你是一个产品经理、运营、或者任何需要和AI打交道的人,有一件事是你现在就可以做的:学会判断,你的问题适合用什么工具。
很多人在2026年的第一反应是”这个功能要用AI做”,然后直接去接大模型的API。有时候这是对的,但很多时候,一个简单的传统机器学习方案会让你省钱、省时间、还更好解释。
举一个具体的例子。假设你在做一个社区产品,想识别恶意评论。很多人的第一反应是接大模型,让它判断每条评论是不是恶意的。但更聪明的做法是:先用一个简单的传统模型跑一遍,把明显的垃圾评论过滤掉,只把那些”说不准”的评论送给大模型判断。这样成本可以降低90%,效果基本一样。
如果你稍微想动动手,有一个特别适合入门的路径:Kaggle上有一个公开的信用卡欺诈数据集,全球几十万人用它练过手。你不需要有任何数学背景,网上有大量教程,用Python装一个叫Scikit-learn的工具包,半天时间你就能跑出一个能识别欺诈交易的小模型。那个体验会让你对”机器是怎么学习的”有完全不一样的感受——比读一百篇文章都管用。
大模型确实越来越快、越来越便宜。有些以前只能靠传统机器学习做的事,现在大模型也能做了。但那些对速度、成本、可解释性要求极高的场景,还没有任何东西能替代传统机器学习。更有意思的是,现在越来越多的系统在把两者结合——传统模型做粗活,大模型做精活,各司其职,配合着跑。
但我知道,当所有人都在追大模型、追Agent的时候,那个最不起眼的老技术,今晚还在你看不见的地方上班。
Arthur Samuel在1959年第一次提出”机器学习”这个词的时候,世界上还没有互联网,没有智能手机,没有云计算。六十七年之后,他提出的这个概念,正在每一秒钟保护着几十亿人的账户、邮箱、数据和隐私。它不会出现在发布会上,不会有人为它鼓掌,不会有科技博主为它写”颠覆性的一天”。
但有时候,最值得关注的,恰恰是那些它还在做的旧东西。

 夜雨聆风
夜雨聆风