 夜雨聆风
夜雨聆风





国内软件厂商要慌了,英伟达干掉碎片化AI大模型,吞吐量狂飙9倍
四月末,英伟达突然放了个大招,没卖显卡,直接把一个全模态推理模型开源了,名字叫Nemotron 3 Nano Omni,听着像小玩意,其实是给企业用的重武器,很多人一看架构和测试,背后一凉,这下子真要改局面了吗

先说个老问题,你以为的全能AI助手,真的是一体吗,很多企业在用的智能体,其实是拼装货,语音识别一套,图像理解一套,视频分析再来一套,最后丢给语言模型凑个答案,中间来回倒数据,调度一堆服务,延迟上天,钱也跟着哗哗流,这种接力赛,能快到哪去呢
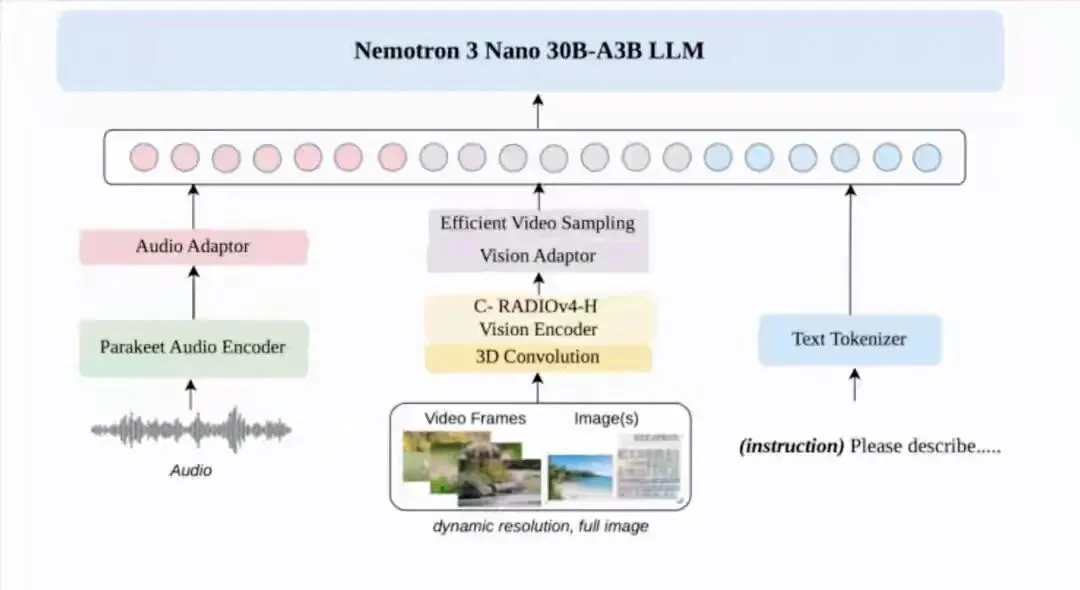
Nemotron 3上来就换打法,把视频音频图像文本,塞进一个网络里,不再四处调模型,它在同一个脑子里看,听,想,说,闭环走完,简单说,就是把原来一条条小轨道,熔成一条快线,串起来就快了不是

据称在多文档推理任务上,系统容量能拉到原来的七点四倍,碰上视频级推理,吞吐直接涨到九点二倍,这是什么感觉,别人还在两头搬,一趟趟倒,你这边一辆大卡车,整车拉走,速度上来,成本下去,业务就顺了对吧
更狠的是底层引擎,英伟达用了混合专家的分工思路,又把Mamba和Transformer拼了个合体,Transformer算得稳当,但吃内存,Mamba省显存,尤其擅长长上下文,再加一层三维卷积,专门压缩视频里的高密度信息,结果就是同样的机器,内存压力小了,计算更顺滑,据报道能把效率拉到四倍左右
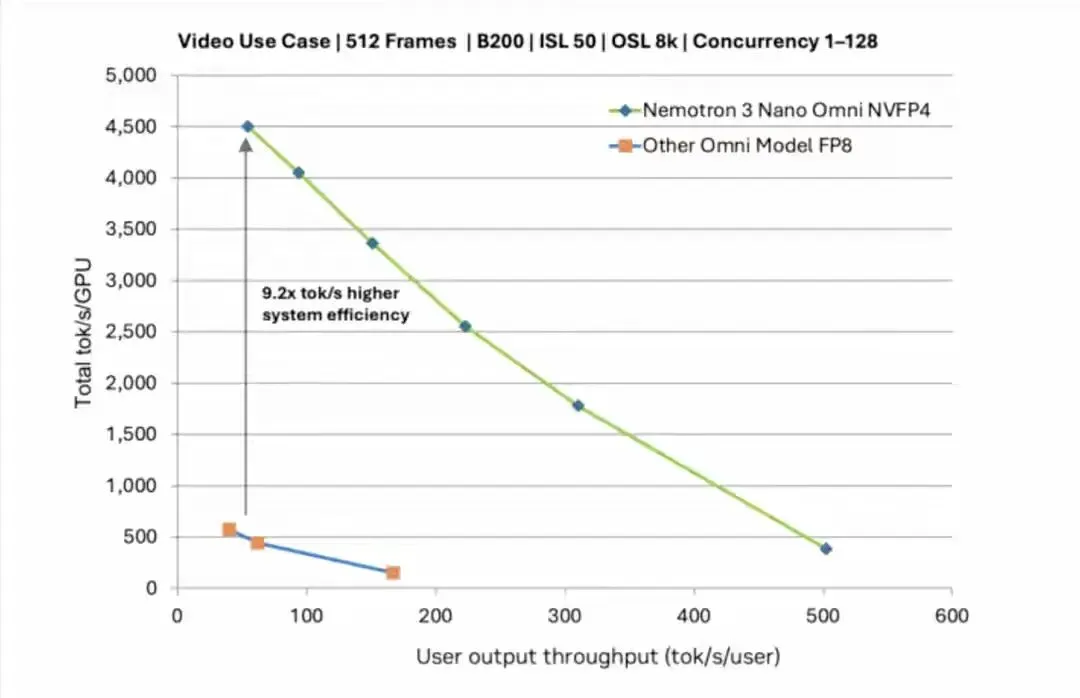
一个长句也得说清它的路数,一个脑子看图听音,理解多文档,串起超长上下文,抓关键帧,压低冗余帧,记住前后因果,快速切换专家,把重点丢给合适的分工,最后一句话吐出来,既快又稳
然后问题来了,这么猛的模型,为啥要免费开源,权重配方数据集,统统扔到社区,有人问老黄不赚钱了吗,真有免费午餐吗

别急,看官方口径里那句不显眼的描述,当用NVFP4这种低精度量化时,这个模型在Blackwell新架构GPU上,处理企业负载的吞吐领先,这话什么意思,翻译成人话,就是软件给你,调教也教你,真要把性能跑满,还是得上黑威尔的新卡,想省心上限高,就准备上机柜吧
这就像送你一台高配引擎,还贴了使用手册,你能启动车没问题,但想飚到官方宣称的极速,只能加指定的油,配指定的轮胎,买指定的底盘,闭环不就这样扣上了么
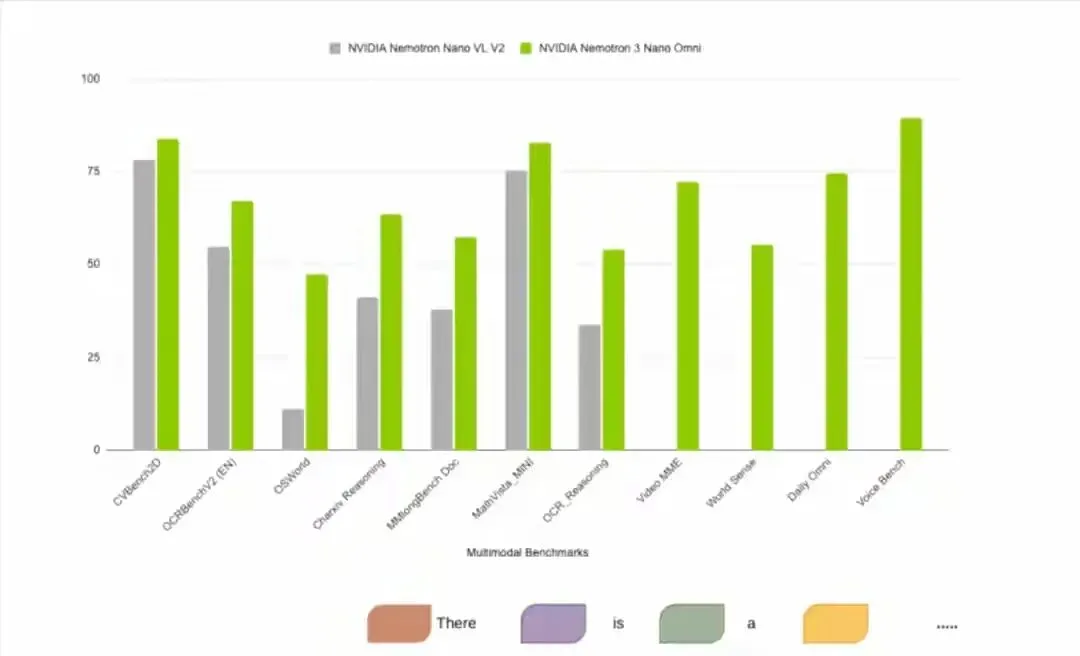
这波操作的指向也很清晰,过去靠拼API讲故事拿融资的中间层,会被正面顶到墙角,企业以前找七八个模型凑合一套工作流,现在有个一体底座,吞吐更高,延迟更低,维护更省,你说采购会怎么选,还会愿意为一堆拼装的粘合剂付费吗
当然,开源不等于谁都赚麻利,真要跑起来,数据清洗要做,私有知识要接,权限管理要通,AIGC要回流业务,工程活一点没少,不过底座统一之后,生态的取舍就直白了,你要么围着这个引擎打磨,要么另起一套系统,谁更快落地,谁更能吞掉工作负载,答案不难猜
国内玩家怎么选,继续砸钱做闭源全模态,守住技术壁垒,还是接受开源底座,专注行业知识和产品化,把时间放在场景里,这题不轻松,要算硬件依赖,要算数据合规,要算长期成本,值得吗
还有个现实点,企业会不会被硬件锁死,预算顶得住吗,混合部署行不行,部分任务留在自家算力,重负载跑到公有云或私有Blackwell集群,这样折中能不能兼顾速度和成本
再退一步看,英伟达的策略很直接,用免费且强悍的软件扫清壁垒,让大家都跑到同一条赛道,然后在硬件端收割溢价,熟不熟悉,这跟当年的CUDA生态有点像吧,先把开发者握住,后面水到渠成
我更关心落地细节,多文档检索写作能不能一键跑通,视频理解能不能进生产,客服质检会不会立刻提效,安全控管可不可控,这些如果跑顺了,企业才会大规模上车,否则再牛的模型也只是个演示
最后抛个问题,开源一体机的枪声已经响了,谁能最快把它变成能赚钱的产品,谁又能在硬件采购上拿到更好的性价比,国内厂商要不要绕开正面冲撞,另辟路径做国产软硬一体,还是顺势搭车做生态,很难一句话下结论,评论区见面再聊吧!