 夜雨聆风
夜雨聆风





我把 AI 助手放到两台机器之间跑,差点把代码删光了
先想一个很具体的风险场景:让本地 AI 助手在工作机和远程开发机之间搬测试文件,跑一个跨机器构建的小流程。它先 dir_list,接着不是去 /tmp 写中间产物,而是开始往项目源码目录里探,准备写一个”它觉得需要”的临时文件。
如果这类跨节点文件工具没有默认拒绝、路径白名单和人工确认,风险就不是”AI 能不能聪明一些”,而是它一旦想错,能不能真的碰到源码目录、覆盖文件,甚至把临时清理动作做成破坏动作。
这也是我去翻 OpenClaw 5/4 版本 release notes 的原因。我之前对 harness 的理解太泛泛——以为它就是个壳子负责把 prompt 喂给模型,其实 harness 真正的价值不是让 AI 更聪明,是 AI 出错时能够阻挡它。
升级 + doctor 跑通
OpenClaw 在 2026-05-04 下午发了 v2026.5.3。先升级:
openclaw self-updateopenclaw --version # 确认是 2026.5.3升级完先别急着接节点,跑一下 doctor:
openclaw doctorrelease notes 里提到这版修了 update / doctor 相关问题,所以升级后先跑 doctor 是个稳妥的动作。它至少能帮你先确认当前 OpenClaw 环境有没有明显配置或迁移问题;至于具体检查项和输出格式以你本机实际 doctor 结果为准,不要按文章里的示意去反推官方 schema。
file-transfer 这类能力不应该在没写清楚节点和路径边界时就默认可用。比起”默认开启再去关”显式配置会更稳妥——你不会在还没配好白名单的时候因为忘了某个开关而让 AI 已经能改动到文件了。
如果 doctor 报错按实际输出逐项修;如果 doctor 没覆盖 file-transfer 的完整权限策略,也不要跳过人工 review。
第一份 file-transfer 配置:把权限边界写明白
这一段不要直接抄。下面只是配置思路示意,用来说明应该把”节点、可读路径、可写路径、文件大小上限”这些边界写清楚;真实字段名和层级必须以 OpenClaw 官方 schema / 当前版本文档为准。
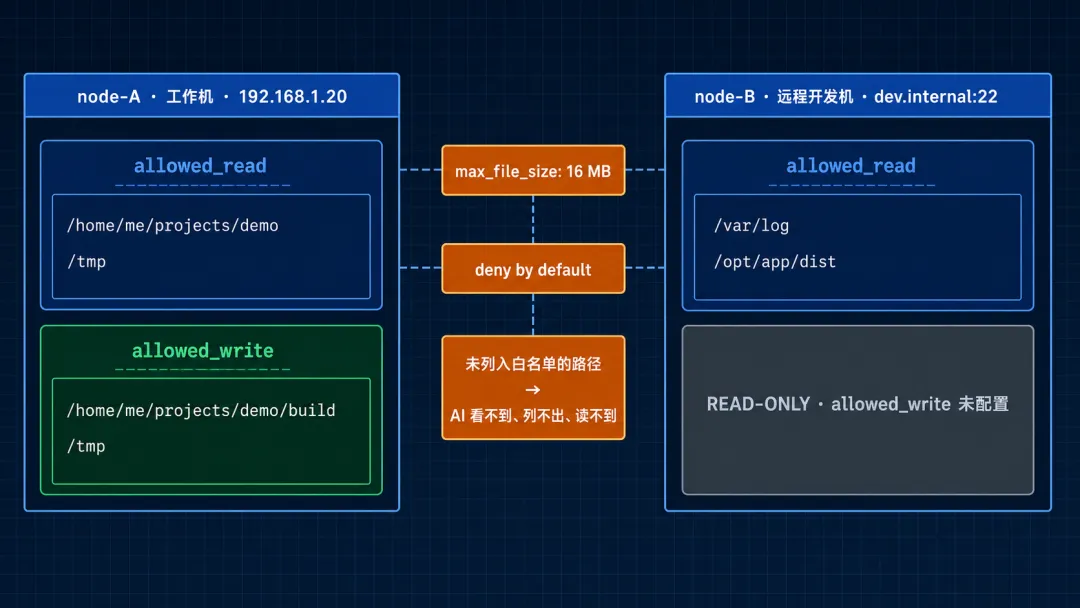
plugins: entries: file-transfer: enabled: true config: max_file_size_mb: 16 nodes: - name: node-A # 我的工作机 host: 192.168.1.20 paths: allowed_read: - /home/me/projects/demo - /tmp allowed_write: - /home/me/projects/demo/build - /tmp - name: node-B # 远程开发机,只允许读 host: dev.internal:22 paths: allowed_read: - /var/log - /opt/app/dist # 没写 allowed_write 等价于不允许写几个我自己踩过的坑:
路径白名单应该按默认拒绝来设计: 官方 release notes 里提到 file-transfer 使用 per-node path policy,并且默认拒绝未授权路径。也就是说,设计配置时不要想着”先全开再慢慢收”,而是先只给任务必需的目录。
写权限要比读权限更窄: 如果一个节点只是提供日志、构建产物或配置文件给 AI 读取,就不要给它写路径。需要落盘的中间产物尽量放在专门的 build / tmp 目录里,而不是源码目录。
16MB 上限不要随手调大: 官方 release notes 提到 file-transfer 有 16MB ceiling。它不只是性能考虑也能避免 AI 把超大日志、dump 或二进制文件塞进 agent loop。真有大文件需求走 rsync 或 scp,别走 AI loop。
4 个文件工具怎么用
配置生效后,release notes 里提到这版给 AI 暴露的 4 个工具:
dir_list — 列目录,让 AI 跑「列一下 node-B 的 /var/log」时,理想状态下应该拿到类似这样的结构化 entries(下面仍是示意):
{ "node": "node-B", "path": "/var/log", "entries": [ {"name": "syslog", "type": "file", "size": 2418293}, {"name": "nginx", "type": "dir"} ]}如果当前版本返回的是结构化数组而不是一段 ls 文本,AI 就能少一层解析误差;如果真实输出字段不同就按真实 tool output 调整 prompt 和解析逻辑。
file_fetch — 拉文件。适合读取白名单内的具体文件,比如远端构建日志、配置片段或产物摘要。
dir_fetch — 拉目录。适合读取白名单内的一组文件。这个能力要特别谨慎,因为目录范围一旦给大,AI 能接触到的上下文也会迅速变大。
file_write — 写文件。建议只开放到明确的输出目录,例如 build、tmp、artifacts,而不是源码根目录:
{ "node": "node-A", "path": "/home/me/projects/demo/build/out.txt", "operation": "create", "bytes_written": 142}上面这个 JSON 只是理想化的结构化返回示意,不代表官方实际字段。写作或实测时要以当前版本真实 tool output 为准。
四个工具加起来够大部分跨机器文件读取和写入场景。chmod、chown、删除、软链接这类更危险的操作,release notes 里没有列成这次 file-transfer 暴露的工具;如果要做这些应该交给更严格的人工流程或额外 plugin,不要默认塞进 AI loop。
建议验证 3 个翻车点 + 用 /steer 拉回
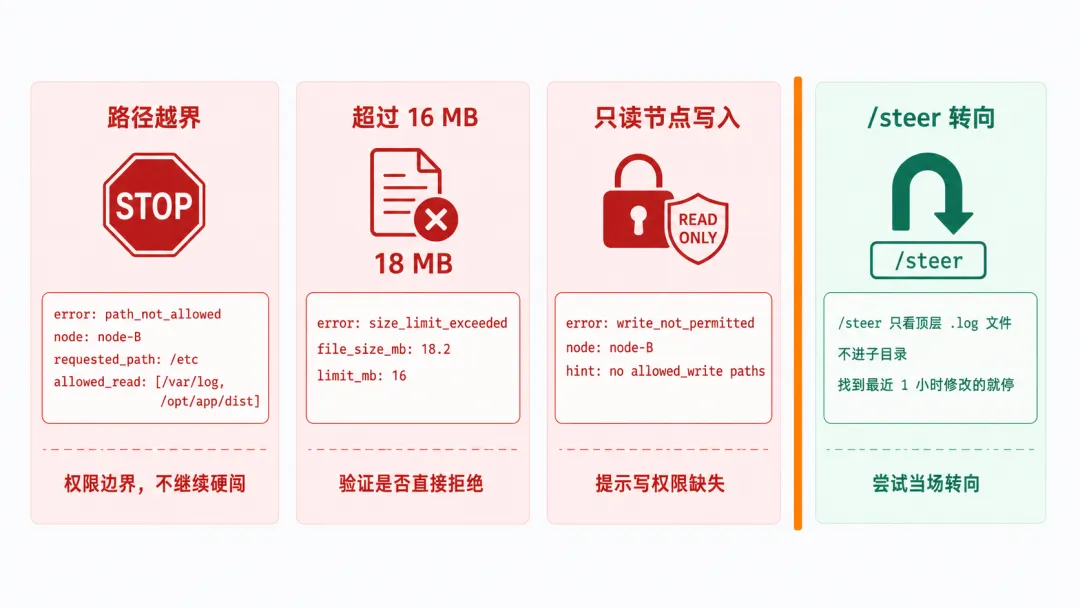
配完之后建议至少验证三个会失败的场景,确认默认兜底是不是真兜得住。下面的错误内容是预期形态示意,不代表 OpenClaw 官方实际错误码。
翻车 1:访问白名单外路径: 让 AI 在 node-B 跑 dir_list /etc:
error: path_not_allowednode: node-Brequested_path: /etcallowed_read: [/var/log, /opt/app/dist]理想状态下错误应该能让 AI 明确知道这是权限边界,不是路径拼错或临时失败,至于它会不会自动掉头要看模型和当前 agent loop 的行为,不要把这件事当成必然。
翻车 2:超 16MB 文件: 伪造一个 18MB 文件让它 fetch:
error: size_limit_exceededfile_size_mb: 18.2limit_mb: 16这里要确认的是:超出上限时是否直接拒绝,以及是否会留下半个文件或中间状态,实际行为以当前版本实测为准。
翻车 3:往只读节点写: AI 试图在 node-B(没配 allowed_write)写 patch:
error: write_not_permittednode: node-Bhint: this node has no allowed_write paths configured如果错误里能提示”这个节点没有写权限”,AI 才更容易改去有写权限的节点;但这仍然要实测确认,不要假设它一定会自动修正。
用 /steer 当场改方向: 如果跑到一半发现 AI 在 dir_list 完 /var/log 之后开始递归翻每个子目录明显跑偏,可以在 prompt 里敲:
/steer 只看顶层 .log 文件,不进子目录,找到最近 1 小时修改的就停如果 /steer 生效下一步它应该回到顶层、按 mtime 过滤、停在第一个匹配。比起重启 session 再讲一遍上下文这种当场改方向的价值在于保留中间结果;但具体能省多少时间、模型是否完全照做,都要按实际 session 表现判断。
收尾:
我现在的做法是:把这份 file-transfer 配置当成项目级配置文件签进仓库。新人 clone 下来运行的时候权限边界已经写好。
AI 助手在这个项目里能做什么、不能做什么,跟开发者本人无关,是项目模板的一部分,跟 lint 规则、CI 配置一样。
适合三类人:① 本地多机器跑工作流的,比如一台跑模型、一台跑数据;② 在 SSH 远程开发机里改代码的,本地 AI 但访问远端文件;③ 团队内部自建工具 Agent 的小队,需要把权限策略变成可审计、可 review 的配置。
一句话:别给 Agent 全权限,先给路径策略,模型再强也有犯错的时候。