 夜雨聆风
夜雨聆风





PageIndex源码剖析:无向量推理式RAG的工程实现
本文深入剖析 VectifyAI/PageIndex 开源项目的源码架构与核心实现,面向对 RAG 系统底层设计感兴趣的开发者。文章逐模块拆解 CLI 入口、PageIndexClient 客户端、PDF/Markdown 双轨索引引擎、检索模块和工具函数库,辅以关键代码片段和时序图说明数据流转,帮助读者理解无向量推理式 RAG 的工程实现细节。
目录
-
概述 1.1 项目背景 1.2 技术定位 -
项目架构总览 2.1 目录结构 2.2 模块依赖关系 2.3 核心数据流 -
源码分析 3.1 CLI 入口:run_pageindex.py 3.2 客户端封装:PageIndexClient 3.3 PDF 索引引擎:page_index.py 3.4 Markdown 索引引擎:page_index_md.py 3.5 检索模块:retrieve.py 3.6 工具函数库:utils.py 3.7 配置系统:config.yaml 与 ConfigLoader 3.8 Agentic RAG 示例 -
技术亮点 4.1 树搜索替代向量搜索 4.2 异步并行摘要生成 4.3 懒加载工作空间 4.4 LiteLLM 多模型兼容 -
总结参考文献
1. 概述
PageIndex 是由 VectifyAI 开发的开源无向量 RAG 框架,在 GitHub 上获得约 25,500 星标(MIT 协议)。其核心思路是将长文档转化为层级树索引,由 LLM 通过树搜索推理完成检索,替代传统的”分块→嵌入→向量相似度”管线。在 FinanceBench 基准上达到 98.7% 准确率。
1.1 项目背景
-
作者:Mingtian Zhang、Yu Tang 及 PageIndex 团队 -
首次发布:2025 年 9 月 -
技术栈:Python 3.8+,依赖 LiteLLM、PyPDF2、PyMuPDF -
代码规模:7 个核心 Python 源文件,约 2,500 行代码
1.2 技术定位
PageIndex 解决的工程问题是:传统向量 RAG 在处理长文档时,语义相似度不等于相关性,固定大小分块破坏文档语义完整性。PageIndex 用”文档结构 + 推理”替代”向量嵌入 + 相似度”,实现可追溯、可解释的检索。
2. 项目架构总览
2.1 目录结构
PageIndex/├── run_pageindex.py # CLI 入口(PDF/Markdown 双模式)├── requirements.txt # 依赖声明├── pageindex/│ ├── __init__.py # 包导出聚合│ ├──client.py # PageIndexClient 客户端封装│ ├── page_index.py # PDF 索引引擎(核心,约 900 行)│ ├── page_index_md.py # Markdown 索引引擎(约 300 行)│ ├── retrieve.py # 检索接口(get_document / get_document_structure / get_page_content)│ ├──utils.py # 工具函数库(LLM 调用、树操作、JSON 提取等)│ └── config.yaml # 默认配置├── examples/│ ├── agentic_vectorless_rag_demo.py # Agentic RAG 完整示例│ └── documents/ # 示例 PDF 文档集├── cookbook/ # Jupyter Notebook 教程└── .github/ # CI/CD 与 Issue 管理
2.2 模块依赖关系
run_pageindex.py├── pageindex.page_index (PDF)├── pageindex.page_index_md (Markdown)└── pageindex.utils (ConfigLoader)pageindex.client (PageIndexClient)├── pageindex.page_index├── pageindex.page_index_md├── pageindex.retrieve└── pageindex.utilspageindex.retrieve├── PyPDF2 (PDF 回退读取)└── pageindex.utils (remove_fields)
__init__.py 作为统一导出层,将所有公开 API 聚合导出:
from .page_index import *from .page_index_md import md_to_treefrom .retrieve import get_document, get_document_structure, get_page_contentfrom .client import PageIndexClient
2.3 核心数据流
从 PDF 文件到检索结果,数据经过三个关键阶段:
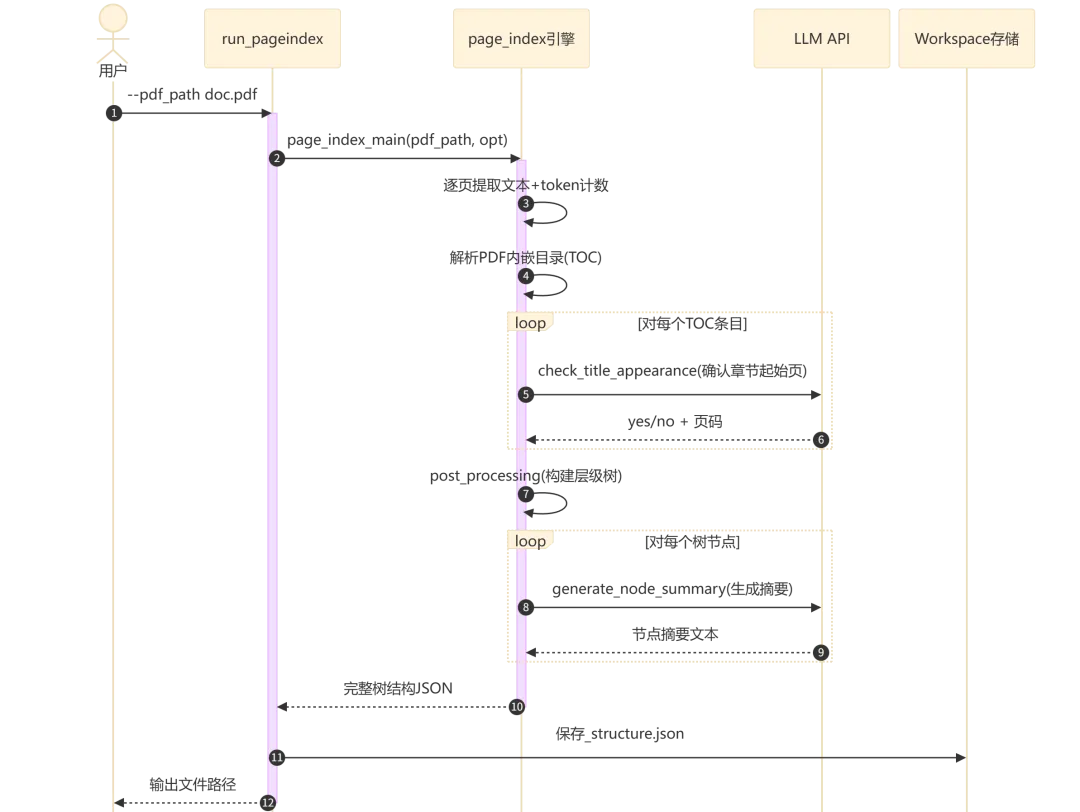
流程执行说明:
-
步骤 1-2:CLI 解析参数,委托 page_index.py执行核心索引逻辑 -
步骤 3-4:逐页提取文本并计算 token 数(支持 PyMuPDF/PyPDF2);同时解析 PDF 内嵌目录 -
步骤 5-7:对目录中每个章节条目,调用 LLM 验证其实际起始页码(模糊匹配) -
步骤 8-9:基于验证后的章节信息构建层级树,对每个节点异步并行调用 LLM 生成摘要 -
步骤 10-11:将最终树结构 JSON 持久化到 ./results/目录
3. 源码分析
3.1 CLI 入口:run_pageindex.py
文件职责:命令行参数解析、PDF/Markdown 模式分发、结果持久化。
核心流程:
if __name__ == "__main__":parser = argparse.ArgumentParser(description='Process PDF or Markdown document')parser.add_argument('--pdf_path', type=str)parser.add_argument('--md_path', type=str)parser.add_argument('--model', type=str, default=None)# ... 其他参数定义 ...args = parser.parse_args()# PDF 模式if args.pdf_path:user_opt = {'model': args.model,'toc_check_page_num': args.toc_check_pages,'max_page_num_each_node': args.max_pages_per_node,'max_token_num_each_node': args.max_tokens_per_node,'if_add_node_id': args.if_add_node_id,'if_add_node_summary': args.if_add_node_summary,'if_add_doc_description': args.if_add_doc_description,'if_add_node_text': args.if_add_node_text,}opt=ConfigLoader().load({k:vfork,vinuser_opt.items()ifvisnotNone})toc_with_page_number = page_index_main(args.pdf_path, opt)# 保存到 ./results/{pdf_name}_structure.json# Markdown 模式elif args.md_path:toc_with_page_number = asyncio.run(md_to_tree(md_path=args.md_path,if_thinning=args.if_thinning.lower() == 'yes',# ... 其他参数 ...))
设计要点:
-
使用 Python 标准库 argparse,所有参数均可选,缺失时回退到config.yaml的默认值 -
user_opt字典先过滤掉None值,再通过ConfigLoader.load()与默认配置合并,实现”用户提供什么就用什么,未提供的用默认值”的语义 -
Markdown 模式通过 asyncio.run()驱动异步函数md_to_tree(),因为摘要生成是 LLM 密集型 I/O 操作,异步并发可大幅减少总耗时
3.2 客户端封装:PageIndexClient
文件:pageindex/client.py,约 230 行。
PageIndexClient 是自托管模式下的高层 Python API,封装了索引生成、工作空间持久化和检索的完整生命周期。
初始化与配置:
classPageIndexClient:def__init__(self, api_key=None, model=None, retrieve_model=None, workspace=None):if api_key:os.environ["OPENAI_API_KEY"] = api_keyelifnot os.getenv("OPENAI_API_KEY") and os.getenv("CHATGPT_API_KEY"):os.environ["OPENAI_API_KEY"] = os.getenv("CHATGPT_API_KEY")self.workspace = Path(workspace).expanduser() if workspace elseNoneoverrides = {}if model:overrides["model"] = modelif retrieve_model:overrides["retrieve_model"] = retrieve_modelopt = ConfigLoader().load(overrides orNone)self.model = opt.modelself.retrieve_model = _normalize_retrieve_model(opt.retrieve_model or self.model)
API Key 管理遵循优先级:构造参数 api_key > 环境变量 OPENAI_API_KEY > 环境变量 CHATGPT_API_KEY(向后兼容)。
索引方法 index() 的核心逻辑:
defindex(self, file_path: str, mode: str = "auto") -> str:file_path = os.path.abspath(os.path.expanduser(file_path))doc_id = str(uuid.uuid4())if mode == "pdf"or (mode == "auto"and ext == '.pdf'):result = page_index(doc=file_path, model=self.model, ...)# 缓存每页文本,避免检索时重读 PDFpages = []withopen(file_path, 'rb') as f:pdf_reader = PyPDF2.PdfReader(f)fori,pageinenumerate(pdf_reader.pages,1):pages.append({'page':i,'content':page.extract_text()or''})self.documents[doc_id] = {..., 'structure': result['structure'], 'pages': pages}elif mode == "md":result = asyncio.run(coro) # 或在线程池中运行self.documents[doc_id] = {..., 'structure': result['structure']}if self.workspace:self._save_doc(doc_id)return doc_id
关键设计决策:
-
索引时即提取并缓存每页文本( pages数组),使后续检索无需原始 PDF 文件 -
Markdown 异步函数调用兼容已有事件循环场景(使用 ThreadPoolExecutor回退) -
持久化时从 structure中移除text字段以减小存储体积,检索时按需懒加载
工作空间持久化采用两段式设计:
workspace/├── _meta.json # 轻量注册表,仅存元数据(名称、路径、页数)└── {doc_id}.json# 完整文档 JSON(结构 + 页面内容)
加载时先读 _meta.json,仅注入元数据到内存;当首次调用 get_document_structure 或 get_page_content 时触发 _ensure_doc_loaded() 按需加载完整 JSON。
3.3 PDF 索引引擎:page_index.py
文件:page_index/page_index.py,约 900 行,是整个项目最核心的模块。
顶层入口函数 page_index_main():
defpage_index_main(pdf_path, opt):pdf_name = get_pdf_name(pdf_path)page_list = get_page_tokens(pdf_path, model=opt.model)# 1. 提取目录toc_of_pdf = extract_toc(pdf_path)# 2. 目录条目验证(LLM 模糊匹配章节起始页)toc_in_list = check_title_and_convert(toc_of_pdf, page_list, start_index=1, model=opt.model)# 3. 添加前言节点(如果第一章不在第 1 页)toc_in_list = add_preface_if_needed(toc_in_list)# 4. 构建层级树tree = post_processing(toc_in_list, end_physical_index=len(page_list))# 5. 添加节点文本内容add_node_text_with_labels(tree, page_list)# 6. 生成节点摘要(异步并行)tree = asyncio.run(generate_summaries_for_structure(tree, model=opt.model))# 7. 生成文档描述doc_description = generate_doc_description(clean_structure, model=opt.model)return {'doc_name': pdf_name, 'doc_description': doc_description, 'structure': tree}
六大处理阶段详析:
阶段一:文本提取与 Token 计数
使用 PyMuPDF(默认)或 PyPDF2 逐页提取文本,同时调用 LiteLLM 的 token_counter 计算每页 token 数。Token 计数用于后续控制节点大小(max_token_num_each_node)。
defget_page_tokens(pdf_path, model=None, pdf_parser="PyPDF2"):if pdf_parser == "PyMuPDF":doc = pymupdf.open(pdf_path)for page in doc:page_text = page.get_text()token_length = litellm.token_counter(model=model, text=page_text)page_list.append((page_text, token_length))elif pdf_parser == "PyPDF2":# ...
阶段二:目录验证
PDF 内嵌目录的页码标注往往不精确(罗马数字前言、图表页等)。PageIndex 对每个目录条目调用 LLM 进行模糊匹配验证:
asyncdefcheck_title_appearance(item, page_list, start_index=1, model=None):title = item['title']page_number = item['physical_index']page_text = page_list[page_number-start_index][0]prompt = f"""Yourjobistocheckifthegivensectionappearsorstartsinthegiven page_text.Note: do fuzzy matching, ignore any space inconsistency in the page_text.The given section title is {title}.Reply format: {{"thinking": "...", "answer": "yes or no"}}"""response = await llm_acompletion(model=model, prompt=prompt)
所有目录条目并发验证(asyncio.gather),大幅缩短总耗时。
阶段三:层级树构建
defpost_processing(structure, end_physical_index):for i, item inenumerate(structure):item['start_index'] = item.get('physical_index')if i < len(structure) - 1:ifstructure[i+1].get('appear_start')=='yes':item['end_index']=structure[i+1]['physical_index']- 1else:item['end_index']=structure[i+1]['physical_index']else:item['end_index'] = end_physical_indextree = list_to_tree(structure)return tree
list_to_tree() 函数根据 structure 字段(如 "1.2.3")推断父子关系,将扁平列表转为嵌套树结构。
阶段四:文本注入
add_node_text_with_labels() 递归遍历树,根据每个节点的 start_index 和 end_index 从页面缓存中提取对应文本,并注入 <physical_index_N> 标签保留页码信息。
阶段五:异步并行摘要生成
asyncdefgenerate_summaries_for_structure(structure, model=None):nodes = structure_to_list(structure) # 树展平为列表tasks = [generate_node_summary(node, model=model) for node in nodes]summaries = await asyncio.gather(*tasks) # 并发执行所有LLM调用for node, summary inzip(nodes, summaries):node['summary'] = summaryreturn structure
这是整个索引流程中最耗时的阶段(节点数 × LLM 单次调用延迟),异步并发可将总耗时从 N * T 降至约 max(T_i)。
3.4 Markdown 索引引擎:page_index_md.py
文件:page_index/page_index_md.py,约 300 行。
Markdown 模式与 PDF 模式的根本差异在于:Markdown 文件的层级信息直接来源于标题(# 标记),无需 LLM 验证目录页码。
核心流程:
asyncdefmd_to_tree(md_path, if_thinning=False, ...):withopen(md_path, 'r', encoding='utf-8') as f:markdown_content = f.read()# 1. 正则提取标题节点node_list, markdown_lines = extract_nodes_from_markdown(markdown_content)# 2. 提取每个节点的文本内容nodes_with_content = extract_node_text_content(node_list, markdown_lines)# 3. 可选:树瘦身(合并过小节点)if if_thinning:nodes_with_content = tree_thinning_for_index(nodes_with_content, ...)# 4. 构建层级树tree_structure = build_tree_from_nodes(nodes_with_content)# 5. 可选:生成摘要if if_add_node_summary == 'yes':tree_structure = await generate_summaries_for_structure_md(tree_structure, ...)return {'doc_name': ..., 'line_count': ..., 'structure': tree_structure}
标题提取使用正则 r'^(#{1,6})\s+(.+)$',同时跟踪代码块状态以避免将代码块内的 # 误识别为标题:
defextract_nodes_from_markdown(markdown_content):header_pattern = r'^(#{1,6})\s+(.+)$'code_block_pattern = r'^```'in_code_block = Falsefor line_num, line inenumerate(lines, 1):if re.match(code_block_pattern, stripped_line):in_code_block = not in_code_blockcontinueifnot in_code_block:match = re.match(header_pattern, stripped_line)ifmatch:node_list.append({'node_title':...,'line_num': line_num})
树瘦身(tree_thinning_for_index)是 Markdown 模式的特色功能。当某节点的总 token 数低于阈值时,将其子节点内容合并到父节点,精简树结构:
deftree_thinning_for_index(node_list, min_node_token=None, model=None):for i inrange(len(result_list) - 1, -1, -1):total_tokens = current_node.get('text_token_count', 0)if total_tokens < min_node_token:children_indices=find_all_children(i,current_level, result_list)# 合并子节点文本到父节点merged_text=parent_text+'\n\n'+ child_textresult_list[i]['text'] = merged_text# 标记子节点为待删除nodes_to_remove.update(children_indices)
3.5 检索模块:retrieve.py
文件:pageindex/retrieve.py,约 140 行,提供三个无状态检索函数,设计为可供 Agent 直接调用的工具。
三个核心函数:
get_document(documents, doc_id) — 返回文档元数据 JSON:
defget_document(documents: dict, doc_id: str) -> str:doc_info = documents.get(doc_id)result = {'doc_id': doc_id,'doc_name': doc_info.get('doc_name', ''),'doc_description': doc_info.get('doc_description', ''),'type': doc_info.get('type', ''),'status': 'completed',}if doc_info.get('type') == 'pdf':result['page_count'] = _count_pages(doc_info)else:result['line_count'] = doc_info.get('line_count', 0)return json.dumps(result)
get_document_structure(documents, doc_id) — 返回不含全文的树结构,节省 LLM 上下文 token:
defget_document_structure(documents: dict, doc_id: str) -> str:structure = doc_info.get('structure', [])structure_no_text = remove_fields(structure, fields=['text'])return json.dumps(structure_no_text, ensure_ascii=False)
get_page_content(documents, doc_id, pages) — 支持范围查询和逗号分隔:
def_parse_pages(pages: str) -> list[int]:for part in pages.split(','):if'-'in part:start, end = int(...)result.extend(range(start, end + 1))else:result.append(int(part))returnsorted(set(result))
PDF 模式下优先使用缓存的页面文本;若缓存不存在则回退到 PyPDF2 实时读取。Markdown 模式下按行号范围匹配节点文本。
3.6 工具函数库:utils.py
文件:pageindex/utils.py,约 500 行,包含项目的基础设施层。
LLM 调用封装(带 10 次重试):
defllm_completion(model, prompt, chat_history=None, return_finish_reason=False):model = model.removeprefix("litellm/")max_retries = 10for i inrange(max_retries):try:response=litellm.completion(model=model,messages=messages,temperature=0)return response.choices[0].message.contentexcept Exception as e:ifi<max_retries-1:time.sleep(1)else:return""
所有 LLM 调用统一设置 temperature=0,确保索引和摘要生成的确定性。
JSON 提取函数 extract_json() 处理 LLM 输出的常见格式问题:
defextract_json(content):# 提取 ```json ... ``` 代码块start_idx = content.find("```json")if start_idx != -1:json_content = content[start_idx+7:content.rfind("```")].strip()# 兼容 Python None → JSON nulljson_content = json_content.replace('None', 'null')# 移除尾随逗号json_content = json_content.replace(',]', ']').replace(',}', '}')return json.loads(json_content)
树操作工具函数族:
|
|
|
|---|---|
structure_to_list(structure) |
|
get_leaf_nodes(structure) |
|
remove_fields(data, fields) |
text) |
write_node_id(data) |
|
create_node_mapping(tree) |
node_id → node 的快速查找映射 |
3.7 配置系统:config.yaml 与 ConfigLoader
config.yaml 定义所有默认值:
model:"gpt-4o-2024-11-20"retrieve_model:"gpt-5.4"# 当前仓库默认值(非公开模型代号),实际使用时若未设置则回退为 model 的值toc_check_page_num:20max_page_num_each_node:10max_token_num_each_node:20000if_add_node_id:"yes"if_add_node_summary:"yes"if_add_doc_description:"no"if_add_node_text:"no"
ConfigLoader 使用 Python types.SimpleNamespace 实现属性式访问(opt.model 而非 opt['model']),用 yaml.safe_load 读取默认值,合并用户覆盖项时校验未知键:
classConfigLoader:defload(self, user_opt=None) -> config:if user_opt isNone:user_dict = {}self._validate_keys(user_dict) # 拒绝未知配置键merged = {**self._default_dict, **user_dict}return config(**merged)
3.8 Agentic RAG 示例
文件:examples/agentic_vectorless_rag_demo.py。
示例展示了如何将 PageIndex 的三个检索函数包装为 OpenAI Agents SDK 的 @function_tool,构建自主导航文档的 AI Agent。
Agent 工具定义模式:
from agents import function_toolfrom pageindex.retrieve import get_document, get_document_structure, get_page_content@function_tooldeftool_get_document(doc_id: str) -> str:"""获取文档元数据:名称、描述、页数"""return get_document(client.documents, doc_id)@function_tooldeftool_get_structure(doc_id: str) -> str:"""获取文档层级树结构(摘要,不含全文)"""return get_document_structure(client.documents, doc_id)@function_tooldeftool_get_content(doc_id: str, pages: str) -> str:"""获取指定页面内容,pages支持"5-7"或"3,8"格式"""return get_page_content(client.documents, doc_id, pages)
Agent 循环流程:
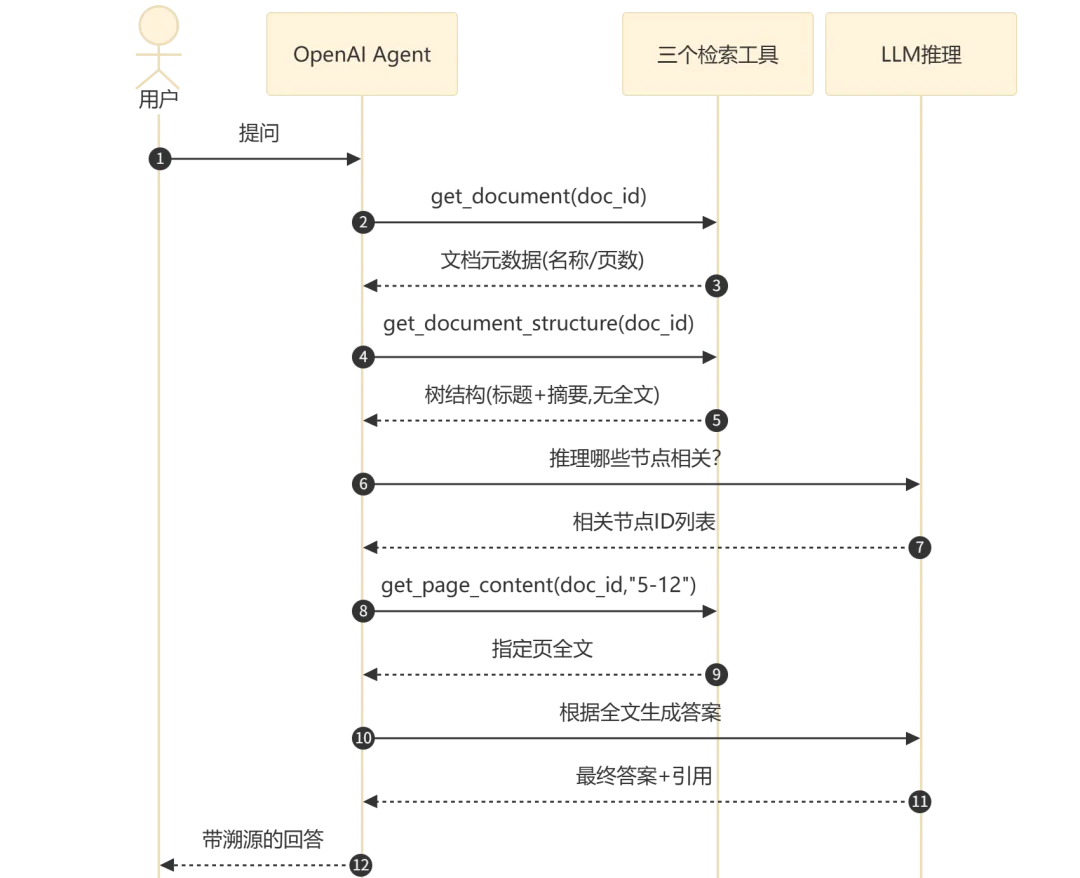
流程执行说明:
-
步骤 1-2:Agent 首先获取文档元数据,确认文档存在并了解规模 -
步骤 3-4:获取树结构(仅标题和摘要),此步骤不包含全文,最大限度节省 LLM 上下文 -
步骤 5-6:Agent 根据树结构进行推理决策,判断哪些节点与用户问题最相关 -
步骤 7-8:Agent 根据选中的节点 ID 获取对应页面的完整文本 -
步骤 9-12:Agent 将提取的文本作为上下文,合成最终答案并返回
4. 技术亮点
4.1 树搜索替代向量搜索
PageIndex 的核心算法创新在于用结构化树搜索替代向量相似度搜索。传统 RAG 的问题是”一刀切”分块破坏了文档的自然语义边界,PageIndex 利用 PDF 内嵌目录或 Markdown 标题层级保留文档的原始结构。检索精度从”语义近似”提升到”结构定位”,且每条检索结果都有页码引用可追溯。
工程实现上,post_processing() 将 LLM 验证后的扁平目录列表转为嵌套树,get_document_structure() 在检索阶段返回去除全文的骨架结构,让 Agent 以最小 token 成本完成导航决策。
4.2 异步并行摘要生成
generate_summaries_for_structure() 将所有节点展平后使用 asyncio.gather(*tasks) 并发调用 LLM 生成摘要。对于含 50 个节点的文档,如果每个摘要 LLM 调用耗时 2 秒,串行需要 100 秒,异步并发仅需约 2 秒(受限于最慢的单次调用)。这是 PageIndex 在保持高质量索引的同时实现可用性能的关键设计。
4.3 懒加载工作空间
PageIndexClient 的工作空间管理采用两段式加载。_meta.json 仅存储轻量元数据(名称、路径、页数),完整 JSON 在首次访问 get_document_structure 或 get_page_content 时才通过 _ensure_doc_loaded() 加载。对于有数十个文档索引的应用场景,启动时仅加载元数据可避免将所有树结构一次性读入内存。
存储时也做了优化——_save_doc() 在持久化前用 remove_fields(doc['structure'], fields=['text']) 移除结构中的全文,因为 PDF 的全文已在 pages 数组中缓存,无需冗余存储。
4.4 LiteLLM 多模型兼容
通过 LiteLLM 网关层,PageIndex 支持 100+ LLM 提供商而无需修改核心代码。_normalize_retrieve_model() 函数智能处理模型名称前缀,对 Anthropic、Azure 等非 OpenAI 提供商自动添加 litellm/ 前缀,对已带前缀的模型名直接透传。
utils.py 中的 llm_completion() 和 llm_acompletion() 封装了 10 次自动重试逻辑,并在同步/异步两种场景下提供一致的接口。
5. 总结
PageIndex 的源码实现体现了”结构优于嵌入”的工程哲学,其架构设计有以下关键特征:
-
模块职责清晰:CLI 入口、客户端封装、PDF 引擎、Markdown 引擎、检索接口、工具库六层分离,每层约 200-900 行,可读性强 -
异步优先:LLM 密集操作全链路使用 asyncio 并发,保证实际可用性能 -
容错设计:LLM 调用 10 次重试、JSON 解析多层回退、工作空间数据降级加载 -
扩展友好:LiteLLM 多模型兼容、config.yaml 集中管理默认值、 ConfigLoader校验机制防止配置漂移 -
约 2,500 行核心 Python 代码实现了完整的推理式 RAG 管线,证明了无向量检索范式的工程可行性
对于想深入理解或二次开发 PageIndex 的开发者,建议阅读顺序:先 utils.py(基础设施),再 retrieve.py(检索入口),接着 page_index.py(核心索引逻辑),最后 client.py(完整生命周期)。
参考文献
[1] PageIndex GitHub 仓库:https://github.com/VectifyAI/PageIndex
[2] PageIndex 官方文档:https://docs.pageindex.ai
[3] DeepWiki – PageIndex 源码分析:https://deepwiki.com/VectifyAI/PageIndex
[4] PageIndex 框架介绍博客:https://pageindex.ai/blog/pageindex-intro
[5] PageIndex FinanceBench 基准测试:https://pageindex.ai/blog/Mafin2.5
[6] LiteLLM 文档:https://docs.litellm.ai