 夜雨聆风
夜雨聆风





主题分块:让RAG系统真正理解文档主题
最近做了一个人事制度RAG项目,发现之前的分块方法都有局限。
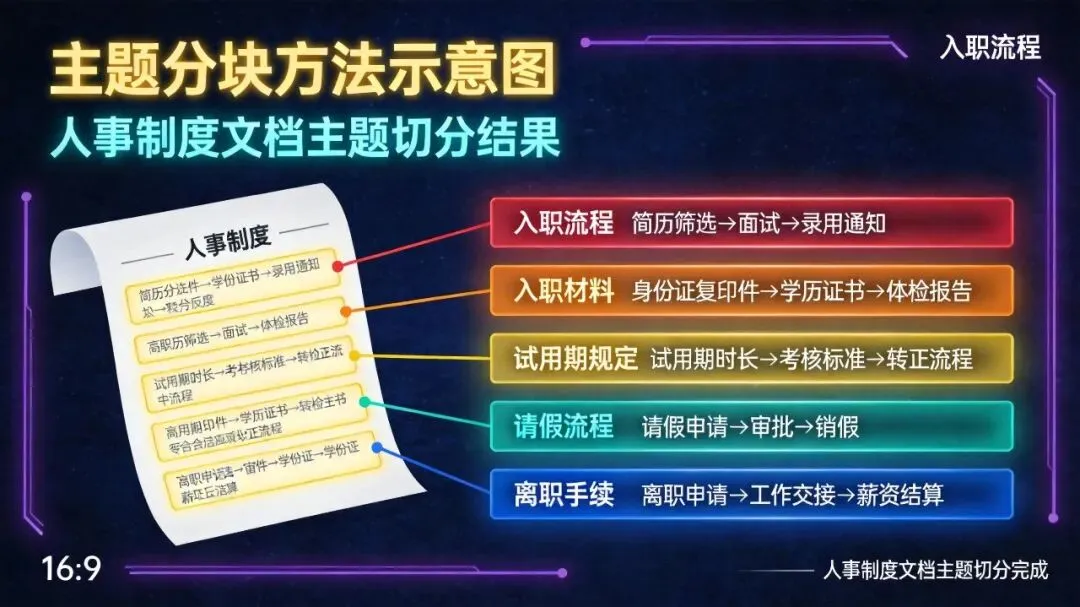
人事制度文档包含多个主题:入职流程、入职材料、试用期规定、请假流程、离职手续,用固定长度分块会把不同主题混在一起,用结构感知分块又因为文档结构不明显而效果一般。
后来试了主题分块,效果直接提升了一个档次。今天把这个方法分享给大家。
什么是主题分块?
不再按字数、换行、标题硬切,而是根据”主题/话题”来切分文本,保证同一个chunk里只讲同一件事,不同主题坚决切开。
它是语义分块的一种更明确、更强的形式,特别适合制度、手册、合同、年报、长文档RAG。
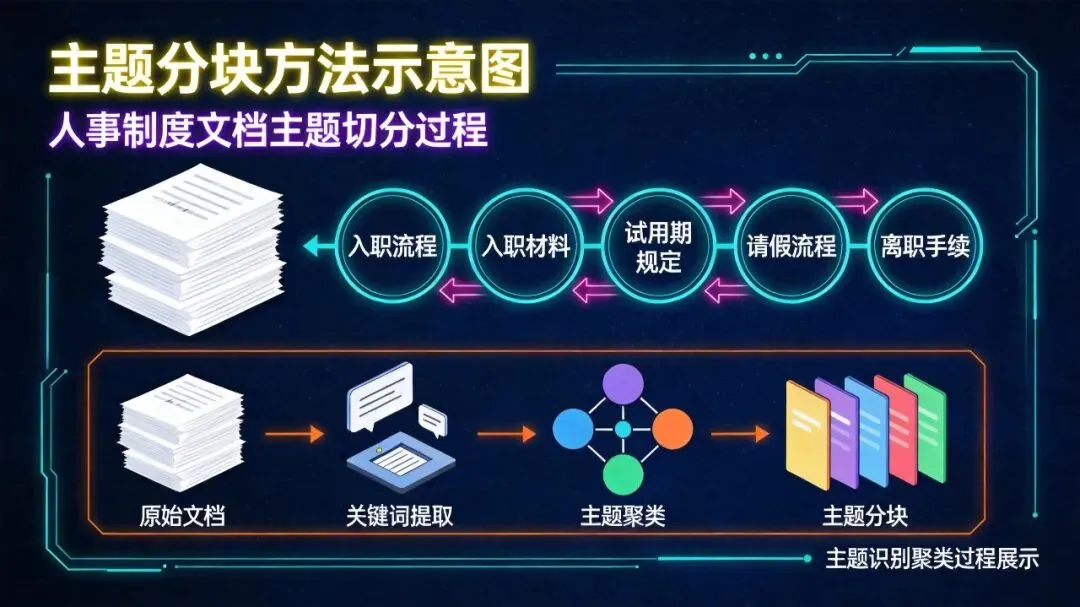
主题分块的核心逻辑
-
把文本切成句子或小段落 -
用embedding或主题模型(LDA/LLM)判断每段属于什么主题 -
把相同主题的内容聚在一起形成chunk -
控制块大小,避免过大或过小
比如人事文档会包含多个主题:入职流程、入职材料、试用期规定、请假流程、离职手续,主题分块就会严格按5个主题切成5块,不会混杂。
主题分块的优点
- 块内主题高度统一 :不会出现一段里一半讲入职、一半讲请假
- 检索精度显著提升 :用户问”入职材料”,只会召回”入职材料”块
- LLM回答更稳定、不编造 :上下文干净,模型不会混淆不同制度
- 对格式不敏感 :即使文档没标题、没排版,照样能切对
- 便于后续主题过滤、加权 :可以给每个块打标签:topic: 入职材料
我做人事制度RAG的时候,用主题分块,模型能准确回答”入职需要准备哪些材料”,而不会把请假流程的内容混进来。
主题分块的不足
-
需预设主题数量:需要知道文档大概包含哪些主题 -
小文档场景不适用:小文档主题单一,分块效果不明显 -
计算开销较大:需要对每个句子进行主题判断
适用场景
-
人事制度、流程手册 -
合同条款、法律文档 -
产品手册、技术规范 -
年报、研报、长文章 -
没有清晰标题结构,但内容分模块的文档
我做产品手册RAG的时候,用主题分块,模型能准确回答”产品的核心功能有哪些”,效果比之前用固定长度分块好太多了。
#加载word文档并转带标题结构的文本(先转markdown/提取标题)loader = Docx2txtLoader("../file/人事流程管理文档.docx")documents = loader.load()# 将word文档的文本转换为markdown格式def convert_to_narkdown(text):"""将word文档中的章节标题转换为markdown格式"""lines = text.split("\n")markdown_lines = []for line in lines:line = line.strip()if not line:markdown_lines.append(' ')continue# 匹配 "第一章 总则"、"第二章 招聘录用流程" 等格式 -> 一级标题if re.match(r'^第[一二三四五六七八九十百]+章\s+', line):markdown_lines.append(f"# {line}")# 匹配 "1.1 目的"、"2.1 招聘需求提交" 等格式 -> 二级标题elif re.match(r'^\d+\.\d+\s+', line):markdown_lines.append(f"## {line}")# 匹配 "1.1.1 xxx" 等格式 -> 三级标题elif re.match(r'^\d+\.\d+\.\d+\s+', line):markdown_lines.append(f"### {line}")else:markdown_lines.append(line)return "\n".join(markdown_lines)# 转换为markdown格式markdown_content = convert_to_narkdown(documents[0].page_content)# 结构感知粗切:按markdown标题层级分割(对应word的标题1/2/3)headers_to_split_on = [("#", "一级标题"),("##", "二级标题"),("###", "三级标题")]header_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)header_chunks = header_splitter.split_text(markdown_content)# 递归细切:对超长标题块二次分割,仅在块内切,不破坏结构text_splitter = RecursiveCharacterTextSplitter(chunk_size=800,chunk_overlap=150,separators=["\n\n","\n","。",";",","," "])final_chunks = text_splitter.split_documents(header_chunks)# 查看结构for chunk in final_chunks:print(f"标题路径:{chunk.metadata}")print(f"内容:{chunk.page_content[:200]} ...\n")
实操心得
-
选择合适的主题模型:小文档用embedding模型,大文档用LDA或LLM -
预设合理的主题数量:根据文档内容复杂度调整,一般5-10个主题 -
控制chunk大小:最小200token,最大800token,根据模型上下文窗口调整 -
结合结构信息:如果文档有标题结构,可以结合结构感知分块一起使用 -
人工标注少量样本:提高主题判断的准确性
最近做一个合同RAG项目,用主题分块,模型能准确回答”违约责任条款”的具体内容,效果非常好。
主题分块 vs 其他分块方法
-
固定长度分块:简单但容易破坏语义边界 -
结构感知分块:适合有明确结构的文档 -
对话式分块:适合聊天记录 -
主题分块:适合主题明确的长文档
最后想说的
主题分块是语义分块的进阶版,效果确实好,但也需要一定的技术储备。
如果你正在做主题明确的长文档RAG,强烈建议试试主题分块,效果会比普通分块好很多。
当然,具体实现的时候要根据文档类型和项目需求调整参数,找到最适合的分块策略。
大家有什么主题分块的经验,欢迎在评论区分享!