 夜雨聆风
夜雨聆风





AI蒸馏到底怎么"蒸"?一文说清从大模型到小模型的完整流程
大模型的能力,为什么能被「压缩」进一个小模型?蒸馏技术到底怎么运作,自动化问询怎么做,问题怎么设计,答案怎么分类,训练出来的决策逻辑为什么有时会出现「奇怪」的盲点?本文把蒸馏的里里外外说清楚。
你有没有想过,那些几百亿参数的大模型,里面的知识到底是怎么「灌」进一个小模型的?
这不是玄学,是一套有完整流程的技术活儿——AI 蒸馏(Knowledge Distillation)。今天把蒸馏的每一个环节都说清楚,包括大家最关心的:自动化问询怎么做、问题怎么设计、答案怎么分类、训练出来的决策逻辑有什么盲点,以及小模型到底能不能在你手机里跑起来。
先搞懂基本概念:教师模型和学生模型
蒸馏这件事,本质上是让一个大模型「教」一个小模型。
那个大模型叫教师模型(Teacher Model),通常是参数几百亿甚至上千亿的顶级选手,比如 GPT-4、Claude、国产的通义、文心之类的。知识丰富,但跑起来贵、慢、功耗高。
小模型叫学生模型(Student Model),参数少很多,可能几十亿或者更少。它要学的是教师模型的「判断能力」,而不是死记硬背。
简单说:蒸馏的目标不是让学生模型背答案,而是让它学会老师做判断的思路。
蒸馏的核心:软标签和温度参数
这节比较硬核,但搞清楚这个,后面的流程就很好理解了。
传统训练一个分类模型,输出的答案叫硬标签(Hard Label)——就是「这是猫,那是狗」,非黑即白。
但大模型厉害的地方在于,它不只是输出一个答案,它还会给每个可能的答案分配一个概率分布。比如判断一张图,大模型会说「60%是猫,30%是狗,10%是兔子」。这个概率分布就是软标签(Soft Label)。
这就是蒸馏的核心:不让学生死记硬背「这是猫」,而是让它去学老师给出的「60%猫 30%狗」这种概率分布。这个分布里藏着老师的推理思路和不确定性判断。
而温度参数(Temperature)就是控制这个分布「软硬程度」的开关。
温度设得越高,概率分布越平缓,差异被放大,方便学生模型学到更细腻的判断逻辑;温度设得低,分布就接近「非黑即白」,跟硬标签差不多了。
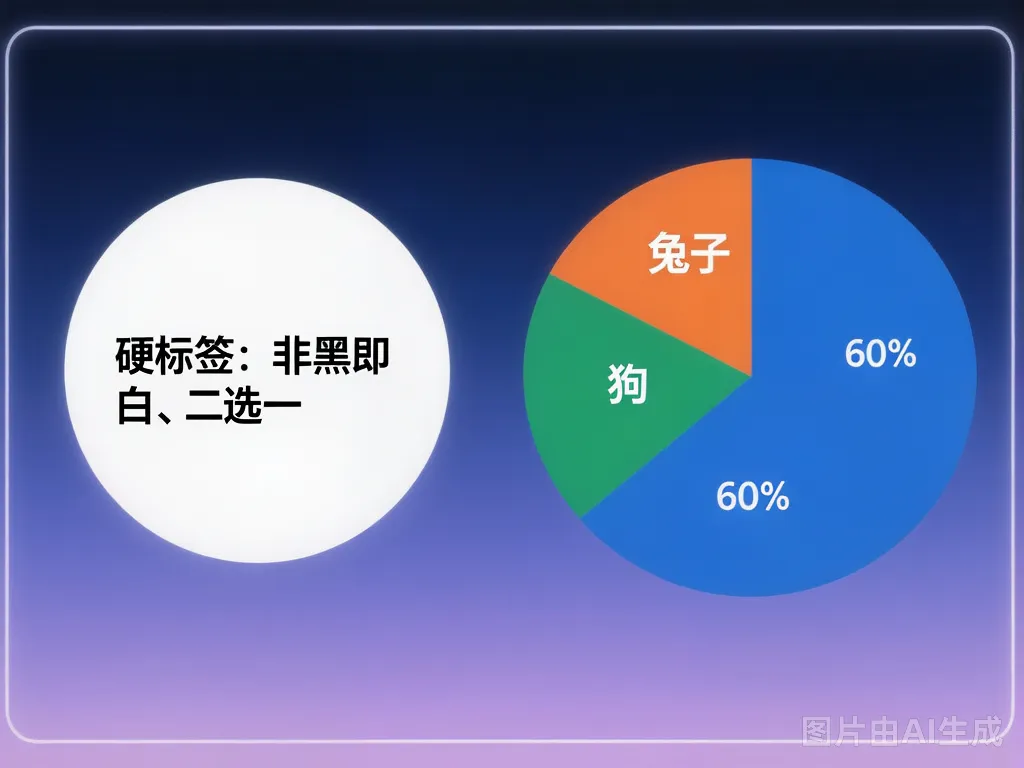
硬标签 vs 软标签对比,一侧是「猫/狗」二元标签,另一侧是「60%猫 30%狗 10%兔子」的概率分布
自动化问询:怎么批量从大模型挖知识
蒸馏的第一步,是从教师模型那里采集数据。这个过程叫自动化问询(Automated Querying)。
要问哪些问题
问题设计是整个蒸馏流程里最关键的环节之一,不是随便问几句就行。
主流的做法是多样性问题覆盖:
- 基础认知类:什么是深度学习?Transformer 是什么?用来采集模型对基础概念的理解。
- 情境题:如果你在写一篇关于 AI 的文章,你会怎么开头?用来采集推理和生成能力。
- 边界题:故意设计一些边界条件或陷阱问题,看模型怎么应对,测试它的鲁棒性。
- 对比题:A 和 B 有什么区别?用来采集模型区分相似概念的能力。
- 多步骤推理题:先说第一步,再说第二步,最后问结论,用来采集复杂推理链。
一般会设计几千到几万条不同类型的问题,形成一个覆盖广泛的「问询题库」。
多账号并发问询
一个人只有一个账号,问不了多少怎么办?
真实场景里,团队会用多账号并发的方式批量采集。脚本逻辑大概是这样:
# 伪代码示意
accounts = load_accounts(「accounts.json」) # 多个 API 账号
question_pool = load_questions(「questions.json」) # 问题题库
for question in question_pool:
# 轮询使用不同账号,分散请求压力
account = next(accounts)
response = call_api(account, question)
save_result(response)常见优化点包括:多账号轮询、请求间隔控制(避免被限流)、异常重试机制、数据实时清洗分流。
API 调用与并发控制
大厂 API 一般有每分钟请求数(RPM)和每分钟 Token 数(TPM)两个限制。多账号并发时,通常会把请求分散到不同账号上,同时在每个账号内部做限流。
成熟团队会用任务队列(比如 Celery)来管理问询任务,支持断点续传,保证数据不丢失。
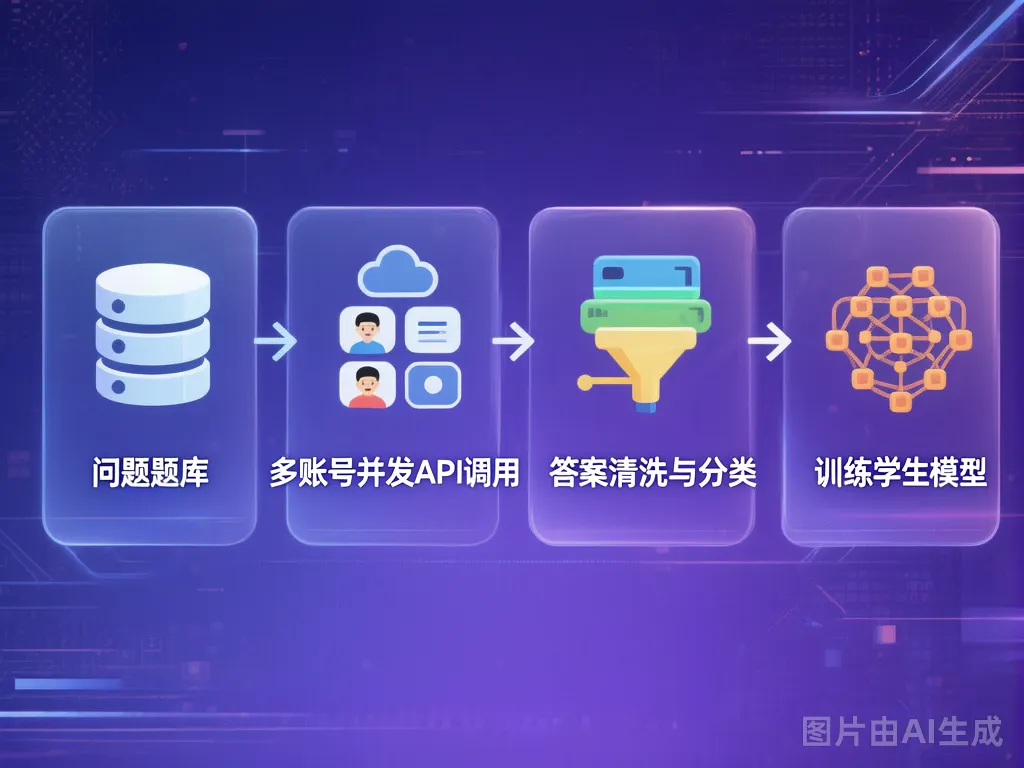
自动化问询全流程,从问题设计→多账号并发→答案清洗→数据存储
答案的处理与分类
问完了不代表数据就能用,还得做一轮清洗和分类。
软标签 vs 硬标签
前面说过,大模型输出的概率分布就是软标签。但在训练学生模型时,通常会同时用软标签和硬标签:
- 软标签损失:学生模型的输出分布和教师模型的概率分布之间的差异(KL 散度损失)。这是蒸馏的核心,让学生学到老师的「思考方式」。
- 硬标签损失:学生模型的预测和真实标签之间的交叉熵损失。这保证学生在标准答案上不跑偏。
两个损失函数通常按一定比例加权求和,作为最终的训练目标。
答案质量清洗
采集回来的答案不是每条都能用。需要做几轮清洗:
- 格式过滤:去掉乱码、空回复、格式异常的答案。
- 长度过滤:答案过短说明模型没认真回答,过长可能是复读或跑题。
- 质量评分:用另一个模型(或者规则)给答案打分,筛掉低质量样本。
- 一致性校验:同一个问题多次问,看答案是否稳定——不稳定的说明模型对这个知识点本身也不确定。
训练学生模型的决策逻辑
数据准备好了,接下来是最核心的环节:训练学生模型。
损失函数设计
学生模型的训练不是简单的「背答案」,而是用一个组合损失函数:
总损失 = α × 软标签损失 + (1-α) × 硬标签损失- α 是软标签权重,通常设 0.7~0.9,意味着蒸馏过来的知识比单纯的标准答案更重要。
- 温度参数 T 会参与软标签损失的计算:分布之间的差异要先除以 T 再算 KL 散度。
决策边界迁移
这是蒸馏真正有价值的地方。
大模型的决策边界非常细腻,它能区分微妙的语义差异。学生模型参数量小,直接训练很难学到这些细腻的边界,但通过蒸馏——学老师输出的软标签——就能把这种判断能力「迁移」过来。
训练过程中,学生的 logits( softmax 前的原始输出)会经过温度 T 的缩放,然后和老师的软标签对齐。这样学生不仅学到了「答案是什么」,还学到了「答案之间有多大的差距」。
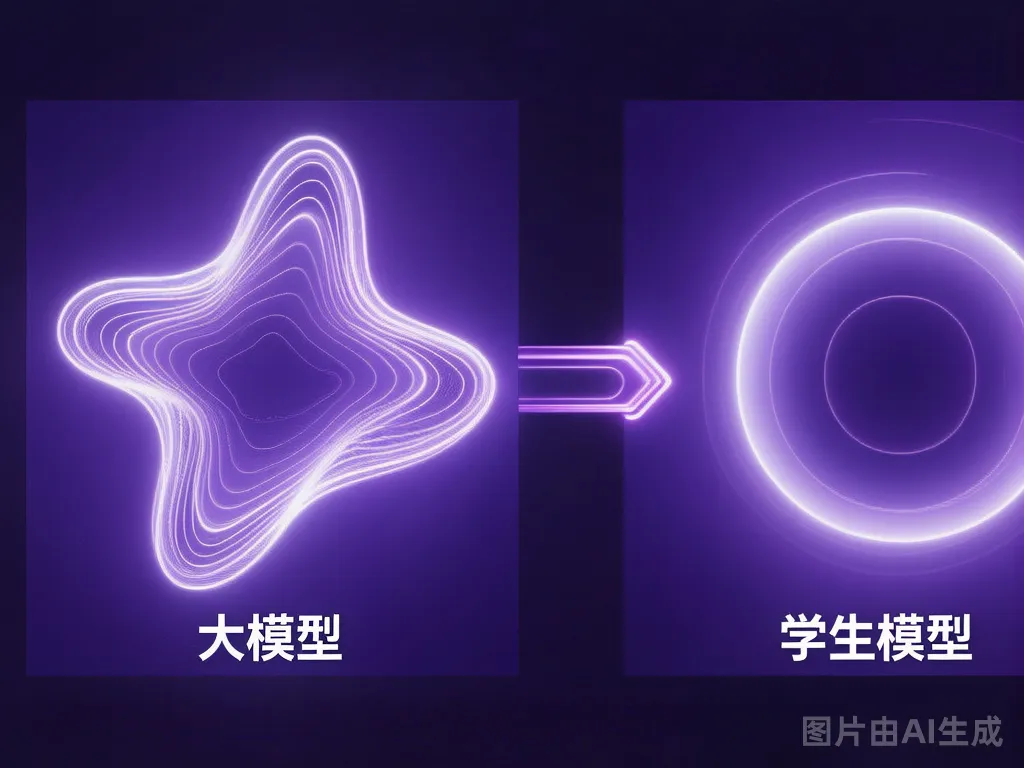
大模型决策边界(细腻波浪线)vs 学生模型蒸馏后决策边界(平滑曲线),体现知识压缩效果
蒸馏的盲点:不是所有知识都能传过去
说完了怎么蒸馏,也得说说它做不到的事。
知识覆盖的盲点
蒸馏本质上是「有监督学习」,学生只能学到老师给过的那些问题的答案。如果问询题库覆盖不全,学生就会在某些领域「偏科」。
典型的盲点包括:
- 长尾知识:问询题库里覆盖少的方向,学生模型学得就差。
- 分布外(Out-of-Distribution):训练数据里没见过的问题类型,蒸馏过来的学生模型很可能乱答。
- 实时知识:教师模型的知识是有截止日期的,蒸馏后的学生模型当然也有同样的局限。
过度拟合教师风格
学生模型有时候会过度模仿教师的表达风格,而不是真正学到知识本质。这就好比学生模仿学霸的笔记格式,但没理解里面的逻辑。
推理能力 vs 记忆能力
蒸馏擅长迁移「判断能力」,但对复杂推理链的迁移效果相对有限。一个能推理十步的教师模型,蒸馏出来的学生模型可能只能稳定推理三到四步。
小模型的优势:省算力、快推理
虽然有盲点,但蒸馏出来的小模型在很多场景下是真香的。
参数量的压缩直接带来成本和速度的优势:
- 推理成本:小模型可以在消费级 GPU 甚至 CPU 上跑,推理成本是大模型的十分之一甚至更低。
- 响应速度:延迟从几百毫秒降到几十毫秒,实时应用体验大幅提升。
- 部署门槛:不需要昂贵的数据中心服务器,中小团队也能跑起来。
端侧部署:手机、汽车、离线运行的可能性
这是很多人最关心的问题:小模型能不能在手机、汽车上跑?能不能离线用?
答案是:能,而且正在成为现实。
苹果的设备端 AI(Apple Intelligence)用的就是蒸馏后的小模型,在 iPhone 上跑,运行时不依赖云端。特斯拉的自动驾驶系统也在用蒸馏模型做实时的感知和决策。
关键在于量化和架构优化。蒸馏后的小模型通常还会做一轮 INT8 甚至 INT4 量化,把参数从 32 位浮点压缩到 8 位整数甚至 4 位,体积再缩小几倍,同时精度损失控制在可接受范围内。
离线运行完全没有问题——因为模型已经在本地了,推理过程完全在设备上完成,不走网络。
主流的端侧推理框架包括:
- llama.cpp / GGUF:让大模型在 CPU 和 GPU 上都能高效推理
- TensorFlow Lite:Google 出品,移动端部署很成熟
- Core ML:苹果生态,深度整合 iOS 和 macOS
- Qwen.cpp / Qwen2.5-Olite:国产模型里做端侧优化比较积极的
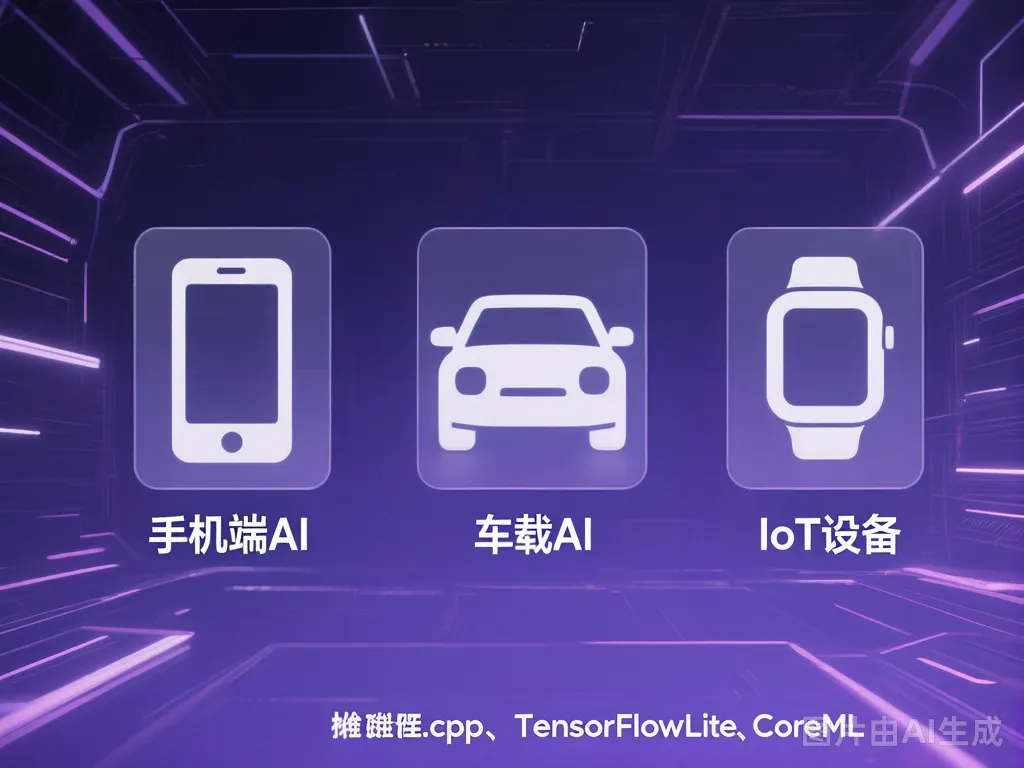
端侧部署场景图,左侧是手机、汽车、智能手表,右侧标注推理框架名称
怎么看 AI 蒸馏:理性期待,精准应用
AI 蒸馏不是万能钥匙,它是一把很锋利但有特定用途的刀。
它最适合的场景是:
- 已有顶流大模型,想快速得到一个便宜、快、能在边缘设备跑的小模型
- 业务场景相对固定,不需要模型有多强的泛化能力
- 端侧部署、隐私敏感(数据不能出设备)
不太适合的场景:
- 需要实时获取最新知识的任务
- 需要强推理能力的复杂任务(直接用大模型更稳妥)
- 训练数据和题库覆盖严重不足的垂直领域
所以对待蒸馏模型,期待要合理——它大概率不是 60 分的教师模型变成 60 分的学生模型,而更可能是 60 分的教师模型变成 55 分的学生模型,但速度提升 10 倍、成本降低 20 倍。在合适的使用场景里,这笔账是划算的。
觉得有用?点个关注,持续获取优质内容。