 夜雨聆风
夜雨聆风





知识库的动态更新:文档变了,向量怎么同步?新增、修改、删除三种场景一次讲透
大家好,我是James。
上一篇我们聊了 Agentic RAG,让 Agent 自己决定要不要检索、检索几次——本质上是把检索策略从「固定流程」变成了「动态决策」。但有一个更基础的问题我们一直没讲:知识库本身是会变的,文档更新了,向量怎么跟着动?
很多同学搭完第一个 RAG 系统之后,会遇到这么一个情况:
产品文档昨天改了定价,但 AI 今天还在跟用户说旧价格。
排查一圈发现,文档确实更新了,向量库却还是老版本——因为根本没有同步机制,每次改文档全靠手动重导。
这还是小问题。更麻烦的是:
-
文档改了,旧 chunk 还留在库里,和新内容同时被召回,LLM 拿到两个矛盾的片段,答案开始出现幻觉 -
一篇敏感合同被删了,但向量库里的 chunk 还在,三个月后用户还能检索到它 -
换了一个 embedding 模型,忘了重新入库,查询和索引用的是两个完全不同的向量空间,召回率腰斩
这些坑的根源是一样的:没有系统性地处理知识库的动态更新。
这篇文章就把这件事从头讲透。三种文档变更操作(新增、修改、删除),对应的向量同步策略,LangChain 的 Index API 怎么用,常见坑一一拆解。
01 为什么向量同步这么难:三角不一致
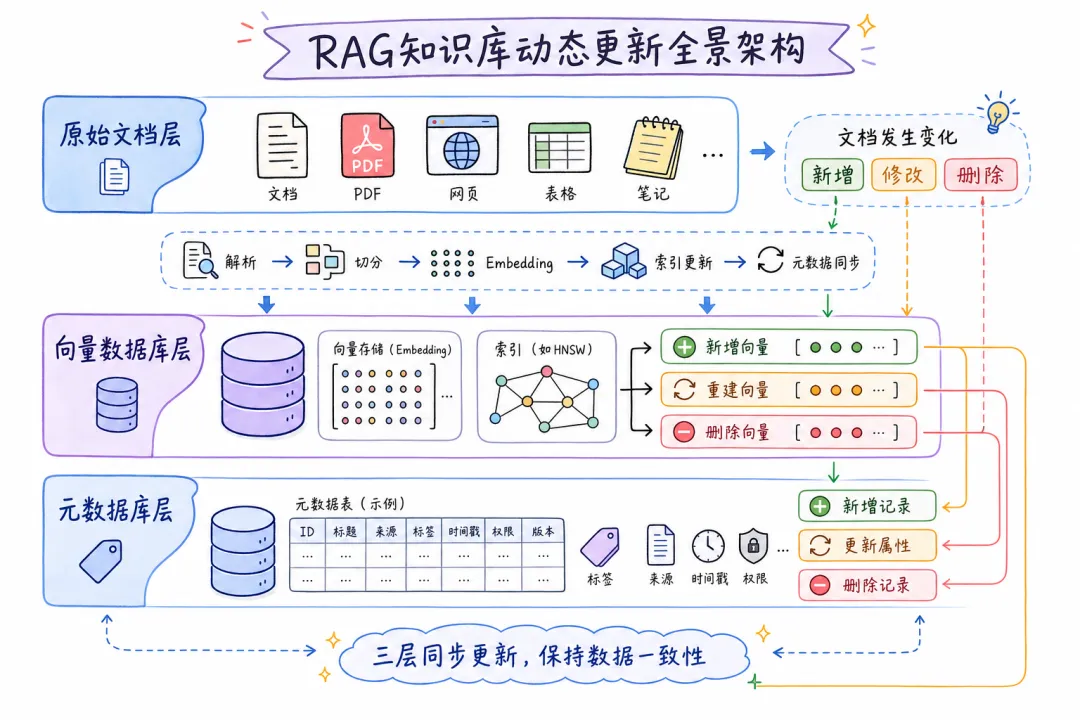
先把问题说清楚。
一个典型的 RAG 知识库,背后至少有三个存储层:
原始文档(S3/本地磁盘)
↓ 解析 → 切块 → Embedding
向量数据库(Milvus/Pinecone/Qdrant)
+
元数据库(PostgreSQL/SQLite) ← 记录 doc_id、版本、哈希
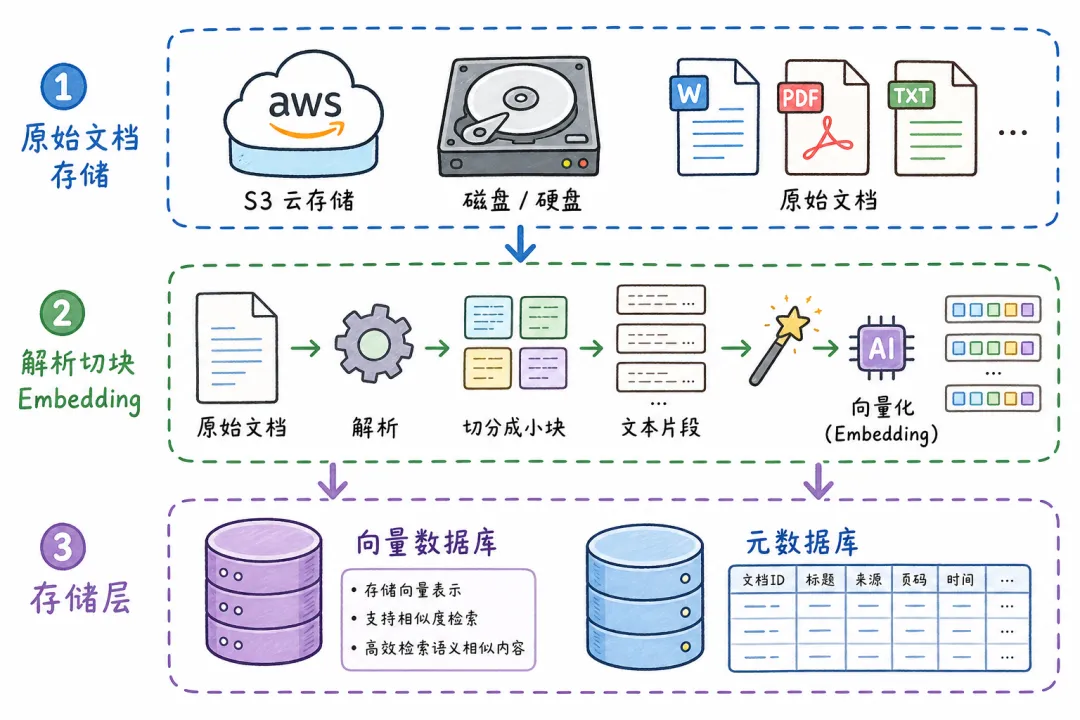
文档变了,这三层都要同步。任何一层没跟上,系统就开始出问题。
最常见的两个失控点:
失控点 1:只写新向量,不删旧向量。
假设你的「产品介绍.pdf」被切成了 10 个 chunk。文档更新了,你重新切块,生成了 8 个新 chunk,写进向量库。但旧的 10 个 chunk 还在里面。
查询时,旧的 chunk 和新的 chunk 都可能被召回。LLM 拿到矛盾信息,轻则答案不准,重则开始编造。
失控点 2:删了文档,向量成了孤儿。
文档从原始存储里删了,但没人通知向量库。这些「孤儿向量」继续活在库里,被用户查到,指向一个已经不存在的文档。如果涉及敏感数据,这就是一个合规事故。
所以向量同步的核心不是「把新向量写进去」,而是保证三层数据始终一致。
02 哈希去重:增量同步的核心武器
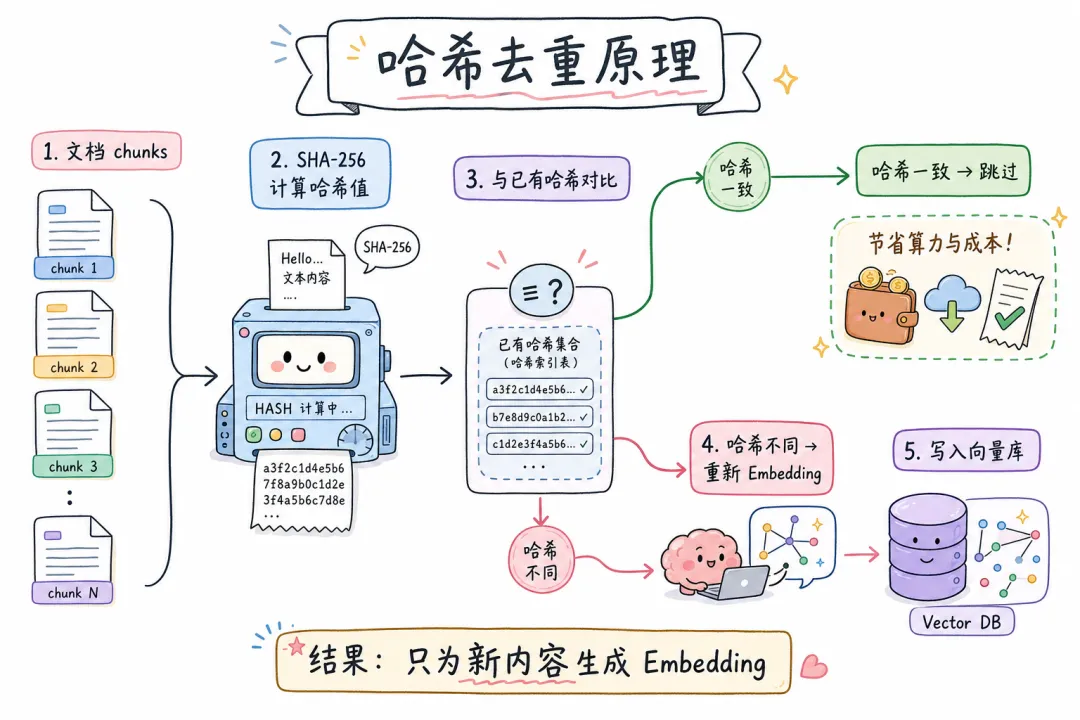
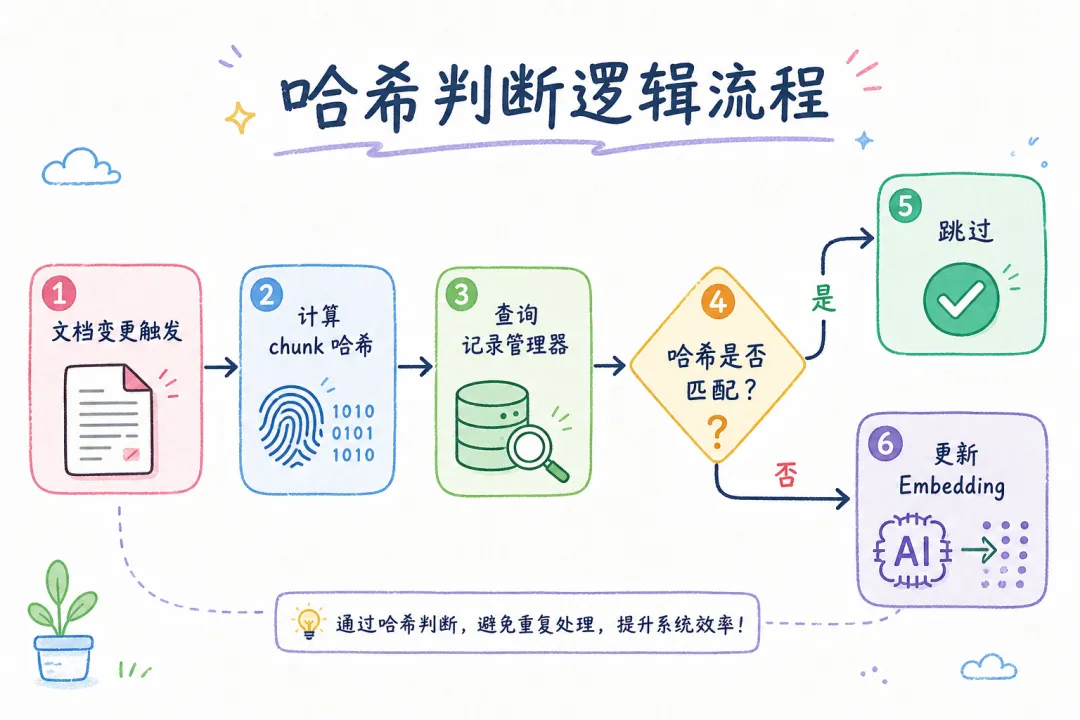
每次文档变化都要把所有 chunk 重新 Embedding,成本太高。聪明的做法是:先用哈希判断内容有没有变,没变就跳过。
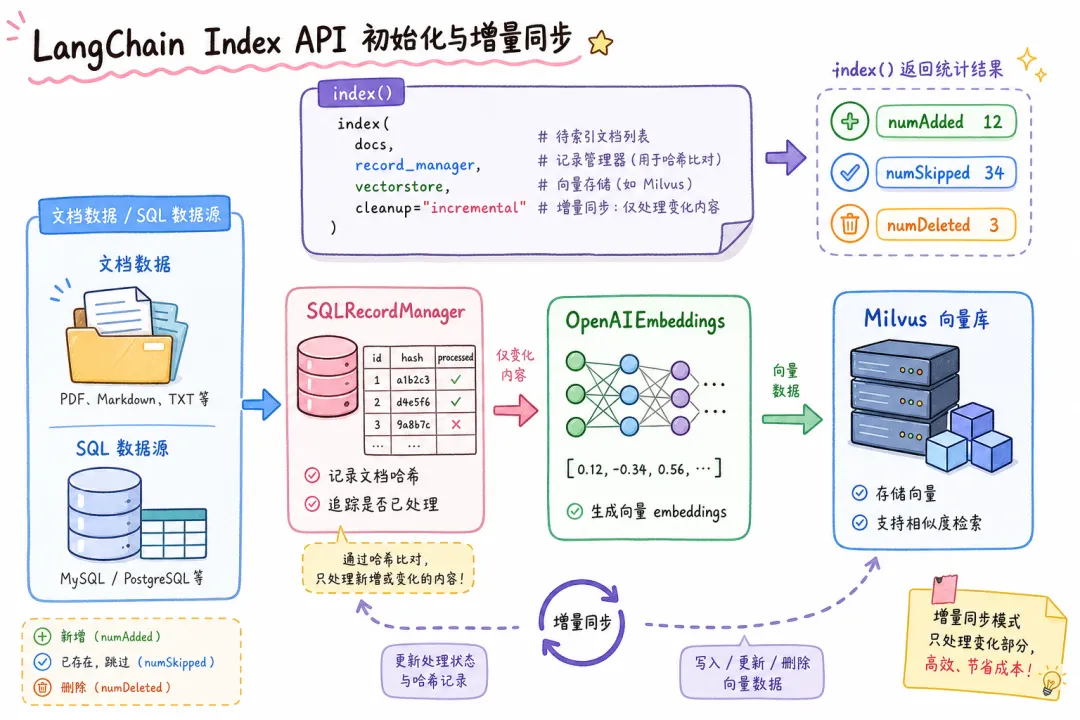
这是 LangChain Index API 的核心思路。
原理很简单:
文档 chunk → 计算 SHA-256 哈希 → 与记录管理器中已有哈希对比
↓
哈希一致 → 跳过(不重新 Embedding)
哈希不同 → 重新 Embedding → 写入向量库
用代码实现:
import { index } from "langchain/indexes";
import { SQLRecordManager } from "@langchain/community/indexes/sqlite";
import { OpenAIEmbeddings } from "@langchain/openai";
import { Milvus } from "@langchain/community/vectorstores/milvus";
import { Document } from "@langchain/core/documents";
import * as crypto from "crypto";
// 初始化向量库
const embeddings = new OpenAIEmbeddings({ model: "text-embedding-3-large" });
const vectorStore = await Milvus.fromExistingCollection(embeddings, {
collectionName: "knowledge_base",
});
// 初始化记录管理器(用 SQLite 存哈希记录)
const recordManager = new SQLRecordManager("milvus/knowledge_base", {
dbUrl: "sqlite:///record_manager.db",
});
await recordManager.createSchema();
// 增量同步文档
async function syncDocuments(docs: Document[]) {
const result = await index({
docsSource: docs,
recordManager,
vectorStore,
options: {
cleanup: "incremental", // 增量模式:自动清理旧版本
sourceIdKey: "source", // 用 source 字段标识文档来源
},
});
console.log(`新增: ${result.numAdded}, 跳过: ${result.numSkipped}, 删除: ${result.numDeleted}`);
}
// 计算内容哈希(用于手动比对)
function contentHash(text: string): string {
return crypto.createHash("sha256").update(text).digest("hex");
}
三种清理模式对比:
| 模式 | 自动清理已删除文档 | 实时清理旧版本 | 适用场景 |
|---|---|---|---|
none |
❌ | ❌ | 只需去重,手动管理清理 |
incremental |
❌ | ✅(写入时) | 文档只会修改,不会删除 |
full |
✅ | ✅(批次结束后) | 需要处理文档删除 |
scoped_full |
❌ | ✅(批次结束后) | 分批索引,按批次清理 |
关键差异: incremental 模式能在写入时实时清理旧版本,新旧内容并存的时间窗口最短;full 模式在全批次写入完成后才清理,适合每次传入完整文档列表的场景。
03 新增文档:幂等写入,不怕重复投递
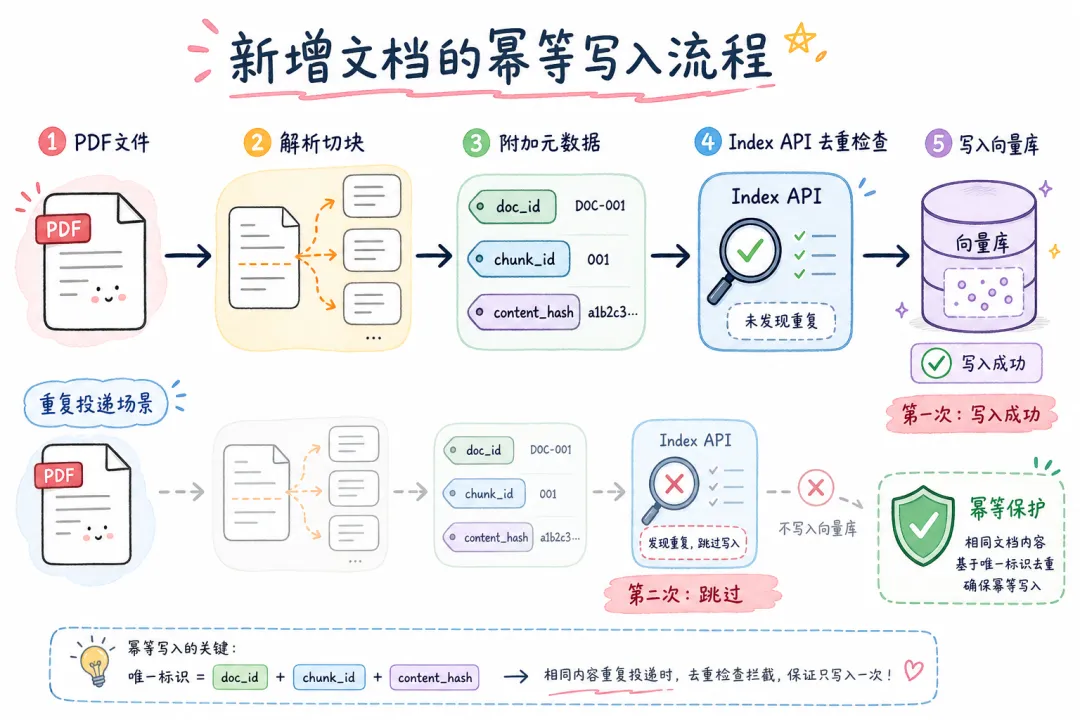
新增是三种操作里最简单的,但有一个坑:重复投递。
消息队列重复消费、worker 崩溃重启后重试——这些场景都会导致同一篇文档被触发多次「新增」。如果没有幂等保护,向量库里会堆满重复的 chunk,占存储、拖检索速度。
正确的新增流程:
interface ChunkMetadata {
doc_id: string;
chunk_id: string;
content_hash: string;
version_id: number;
source: string; // 原始文件路径/URL(Index API 必需)
source_type: string; // "pdf" | "confluence" | "notion"
embedding_model: string;
created_at: string;
is_deleted: boolean;
}
async function addDocument(filePath: string) {
// 1. 解析 + 切块
const loader = new PDFLoader(filePath);
const docs = await loader.load();
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 512,
chunkOverlap: 50,
});
const chunks = await splitter.splitDocuments(docs);
// 2. 附加元数据(每个 chunk 携带来源信息)
const docId = generateDocId(filePath);
const chunksWithMeta = chunks.map((chunk, i) => ({
...chunk,
metadata: {
...chunk.metadata,
doc_id: docId,
chunk_id: `${docId}-chunk-${i}`,
content_hash: contentHash(chunk.pageContent),
version_id: 1,
source: filePath, // Index API 用这个做去重 key
source_type: "pdf",
embedding_model: "text-embedding-3-large",
created_at: new Date().toISOString(),
is_deleted: false,
} as ChunkMetadata,
}));
// 3. 用 Index API 写入(自带去重)
await syncDocuments(chunksWithMeta);
}
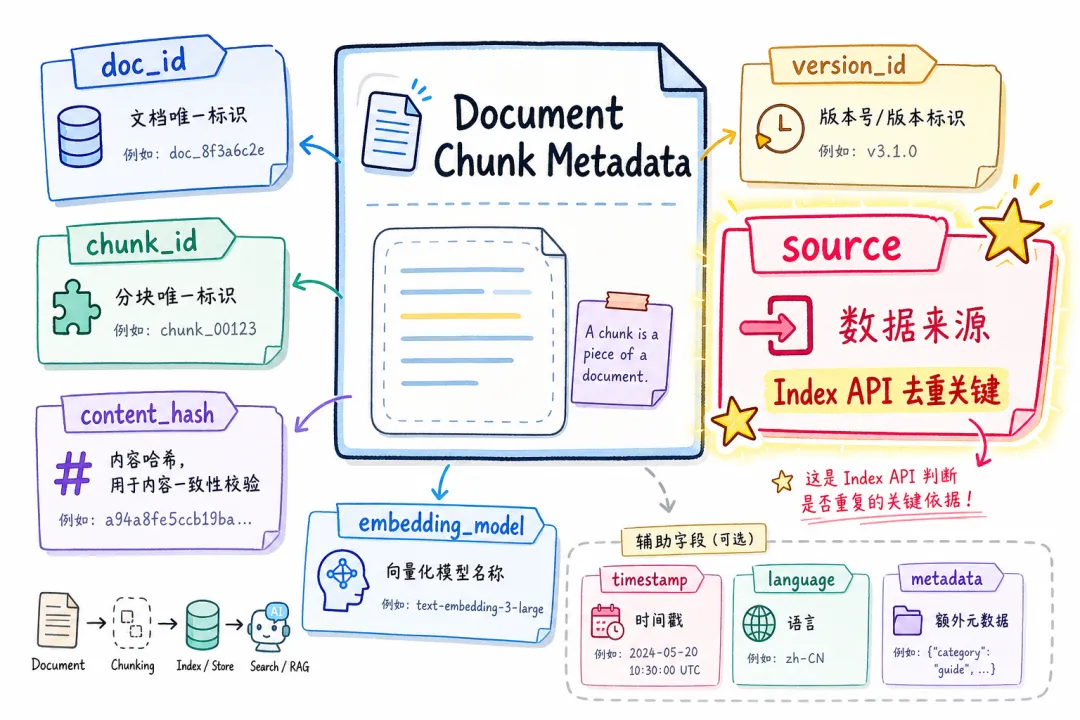
哈希去重保证了幂等性:同一篇文档无论触发多少次,只要内容没变,第二次起全部跳过,不会产生重复记录。
04 修改文档:旧 chunk 清理是核心,不是可选项
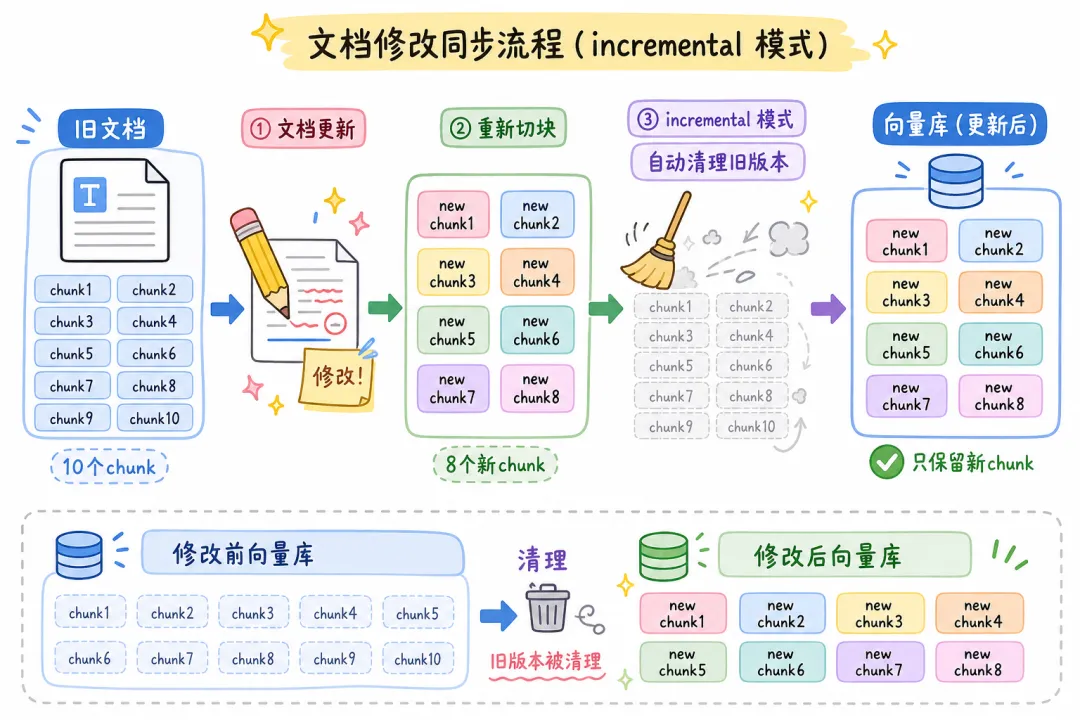
修改比新增复杂,原因前面说了:必须清理旧版本向量。
incremental 模式的删除逻辑是基于 source 字段的:同一个 source,内容哈希变了,就把旧 chunk 删掉,写入新 chunk。
async function updateDocument(filePath: string, newContent: string) {
// 重新切块,source 保持原路径不变
const newChunks = await splitContent(newContent, {
source: filePath, // ← 关键:source 不变,Index API 才能识别是同一文档的更新
});
// incremental 模式:自动删旧写新
const result = await index({
docsSource: newChunks,
recordManager,
vectorStore,
options: {
cleanup: "incremental",
sourceIdKey: "source",
},
});
// 预期:num_deleted > 0(旧 chunk 被清理),num_added > 0(新 chunk 写入)
console.log(result);
// { numAdded: 8, numUpdated: 0, numSkipped: 0, numDeleted: 10 }
}
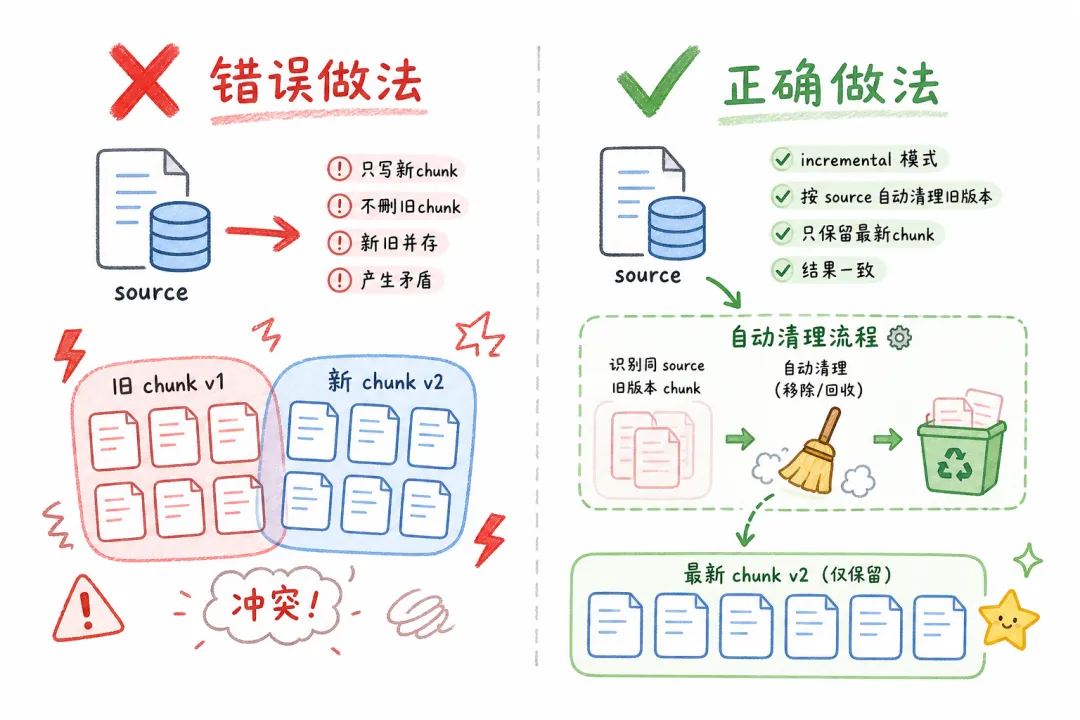
一个高频踩坑点:文档重新切块后 chunk 数量变了。
假设原来 10 个 chunk,更新后内容精简了,变成 6 个。如果用的是基于 chunk_id 的 upsert,旧的 7-10 号 chunk 会永远留在库里。
incremental 模式用 source 做关联,只要 source 一样,不管 chunk 数量怎么变,旧版本全部清理干净。
05 删除文档:软删除 + 延迟物理清理的标准姿势
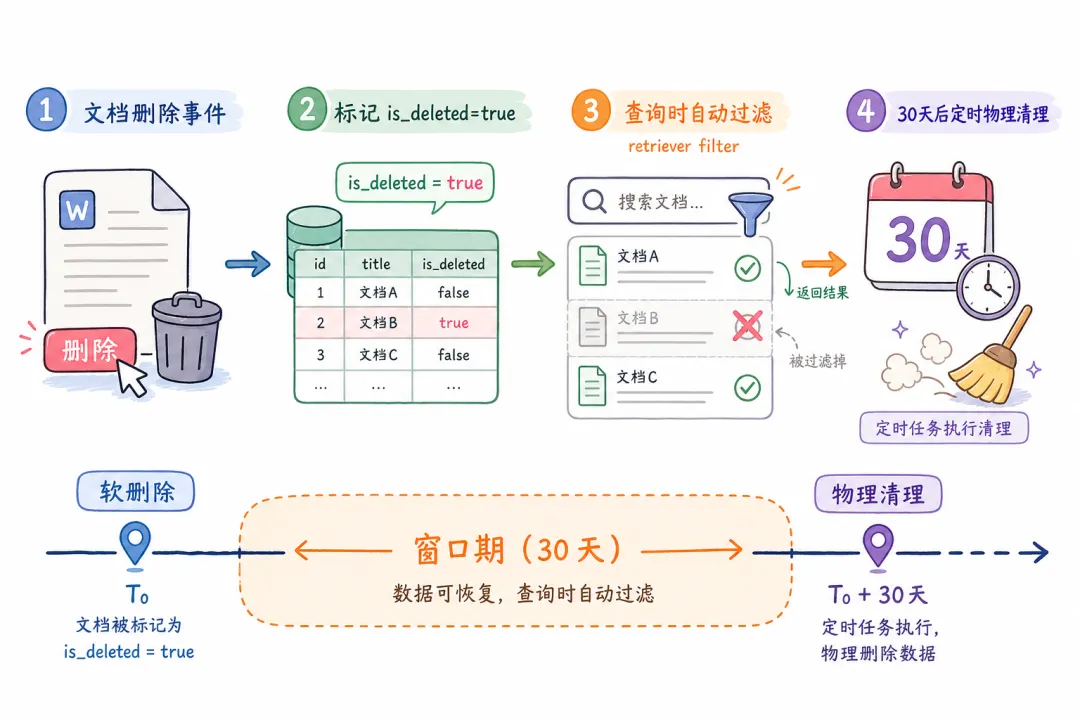
文档删除是最容易埋雷的操作。两种思路:
方案 A:直接物理删除
// 直接从向量库删
async function hardDeleteDocument(source: string) {
await index({
docsSource: [], // 传空列表
recordManager,
vectorStore,
options: {
cleanup: "full", // full 模式:传入列表之外的文档全部删除
sourceIdKey: "source",
},
});
// 问题:需要传入所有"应该保留"的文档列表,适合文档集合小的场景
}
// 更精准的做法:按 source 删除
async function deleteBySource(source: string) {
// 先从记录管理器查出这个 source 对应的所有 vector ID
// 再批量删除
const ids = await recordManager.listKeys({ after: 0, before: Date.now(), groupIds: [source] });
await vectorStore.delete({ ids });
await recordManager.deleteKeys(ids);
}
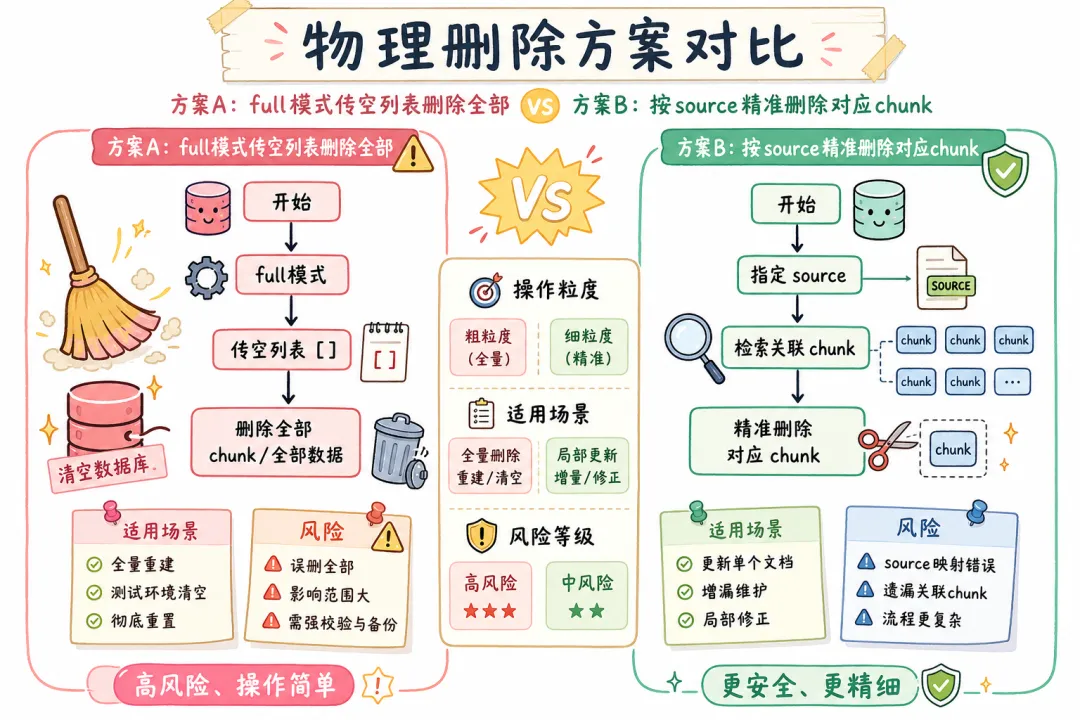
方案 B:软删除(推荐)
// 软删除:不立即物理清理,先标记 is_deleted
async function softDeleteDocument(docId: string) {
// 1. 更新元数据库:is_deleted = true
await metaDB.update(
{ is_deleted: true, deleted_at: new Date().toISOString() },
{ where: { doc_id: docId } }
);
// 2. 查询时自动过滤(向量库元数据过滤)
// retriever 配置中加 filter: { is_deleted: false }
// 3. 定时任务:30天后执行物理清理
await schedulePhysicalCleanup(docId, 30 * 24 * 60 * 60 * 1000);
}
// 软删除检索器:只返回 is_deleted=false 的结果
const retriever = vectorStore.asRetriever({
filter: { is_deleted: false },
k: 5,
});
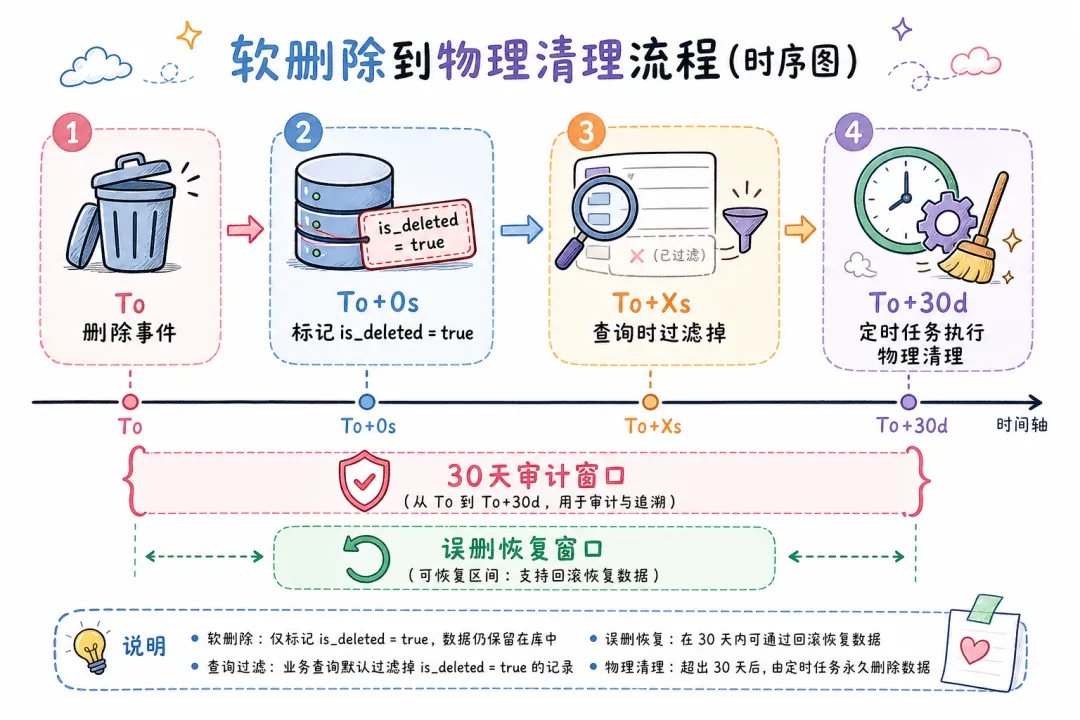
为什么推荐软删除?
删除操作不可逆。误删了一篇重要文档,软删除可以 30 秒内恢复;物理删除就要重新解析、切块、Embedding,至少几分钟。对于敏感文档(合规删除要求),软删除 + 延迟物理清理还能提供 30 天的审计窗口。
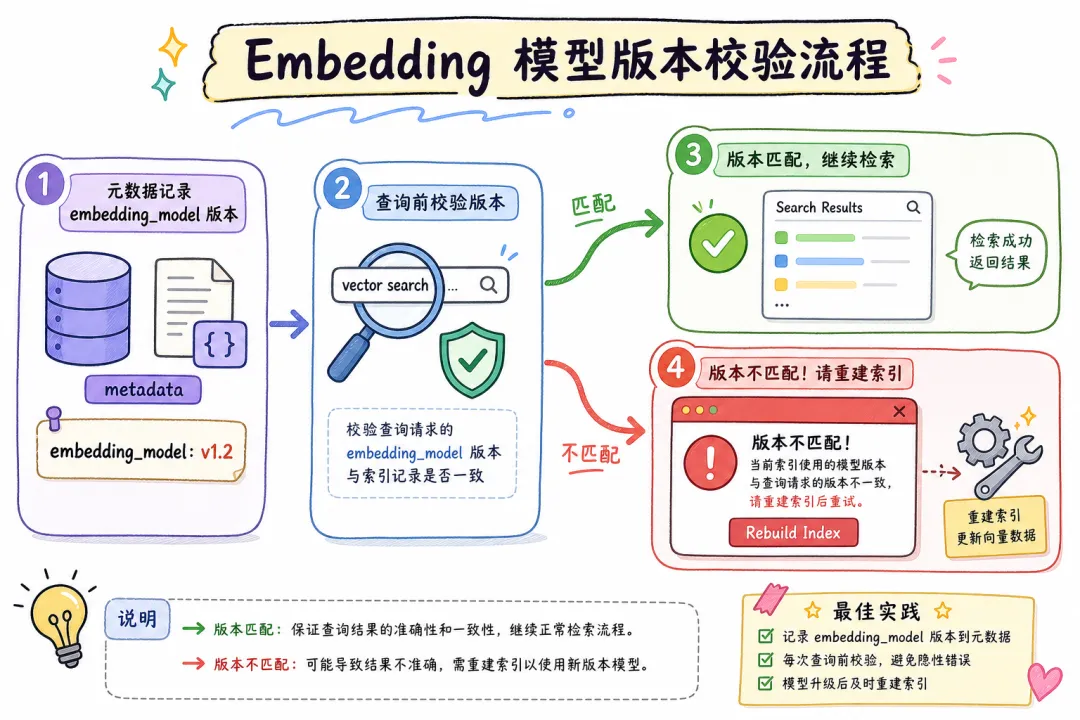
06 Embedding 模型升级:最容易被忽视的定时炸弹
这个问题不如「文档更新」直观,但在真实项目里炸过不止一次。
本质是向量空间不兼容。
OpenAI 的 text-embedding-3-small 和 text-embedding-3-large 向量空间不同,维度也不同(1536 vs 3072)。索引时用 small,查询时误用 large,就等于在两个完全不相干的数学空间里做距离计算——结果是随机的。
// 元数据里记录 embedding 模型版本(关键)
interface EmbeddingMetadata {
embedding_model: string; // "text-embedding-3-large"
embedding_model_version: string; // "2025-01-15"
embedding_dimension: number; // 3072
}
// 查询前校验模型版本
async function safeSearch(query: string, expectedModel: string) {
// 检查向量库的模型版本记录
const indexMeta = await getIndexMetadata();
if (indexMeta.embedding_model !== expectedModel) {
throw new Error(
`模型不匹配!索引用的是 ${indexMeta.embedding_model},` +
`查询用的是 ${expectedModel}。请先重建索引。`
);
}
return await vectorStore.similaritySearch(query, 5);
}
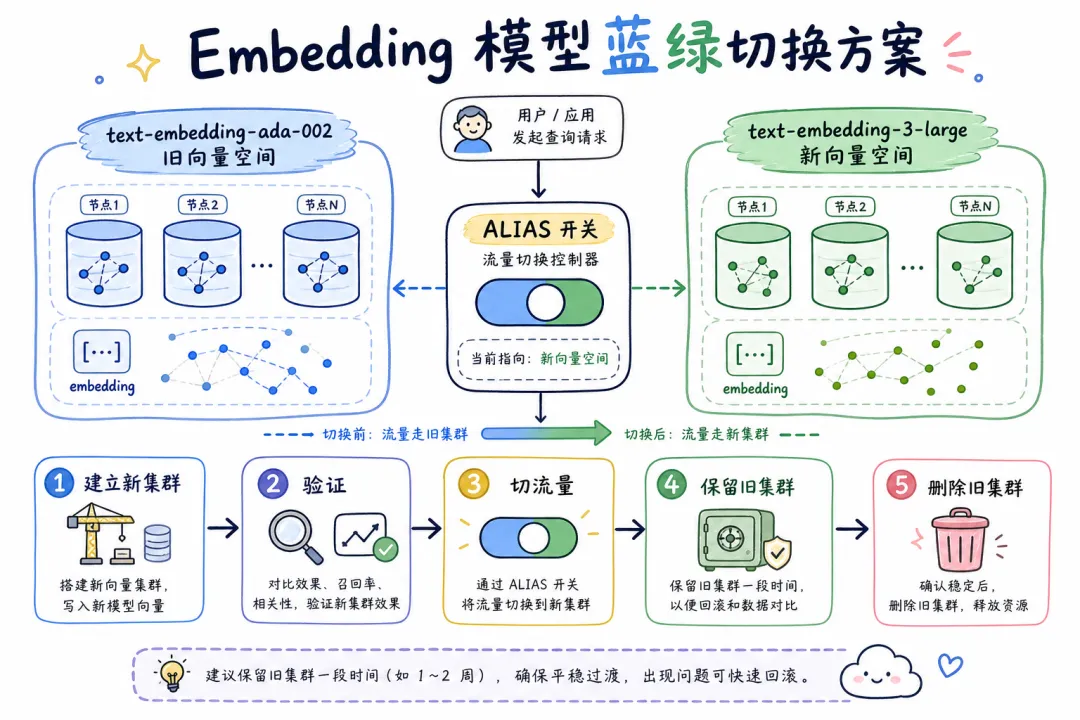
模型升级的正确姿势:蓝绿切换,不原地升级。
1. 新建 collection(knowledge_base_v2),用新模型重新入库全量数据
2. 双索引并行运行一周,对比召回率
3. 确认 v2 稳定后,通过别名切换(alias swap)把流量切过去
4. 保留 v1 两周,用于回滚
5. 确认无问题后,删除 v1
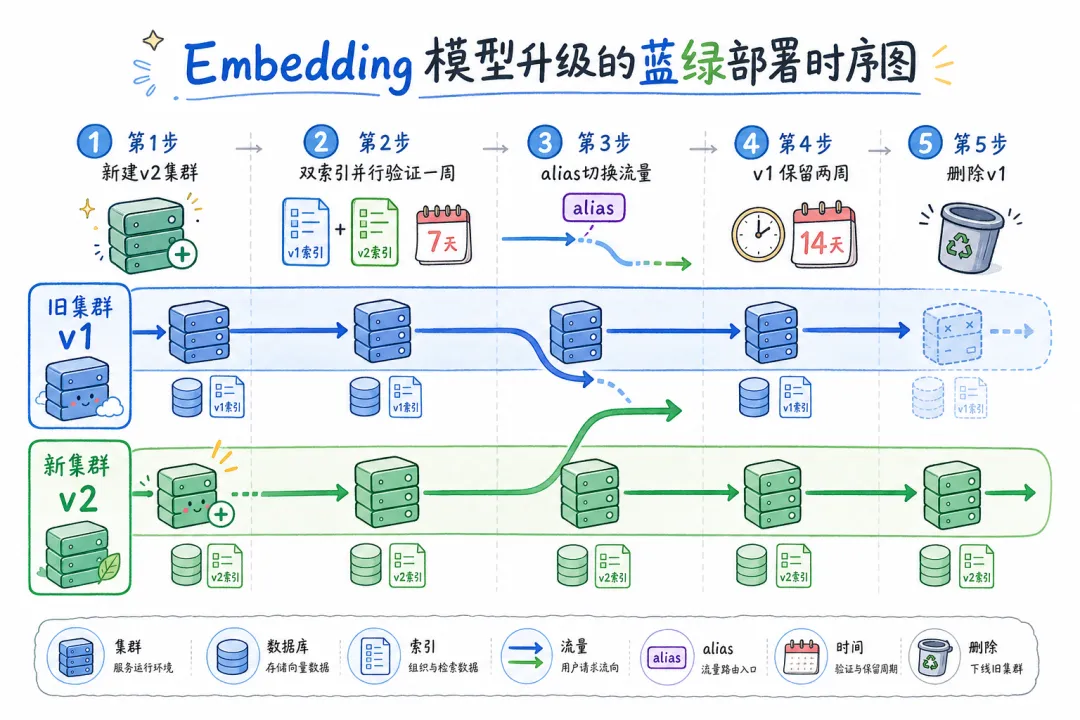
原地升级(直接把旧 chunk 替换)的风险是:替换过程中,库里同时存在新旧两种向量空间的数据,检索结果完全不可预期。
07 生产级同步架构:事件驱动 + 补偿机制
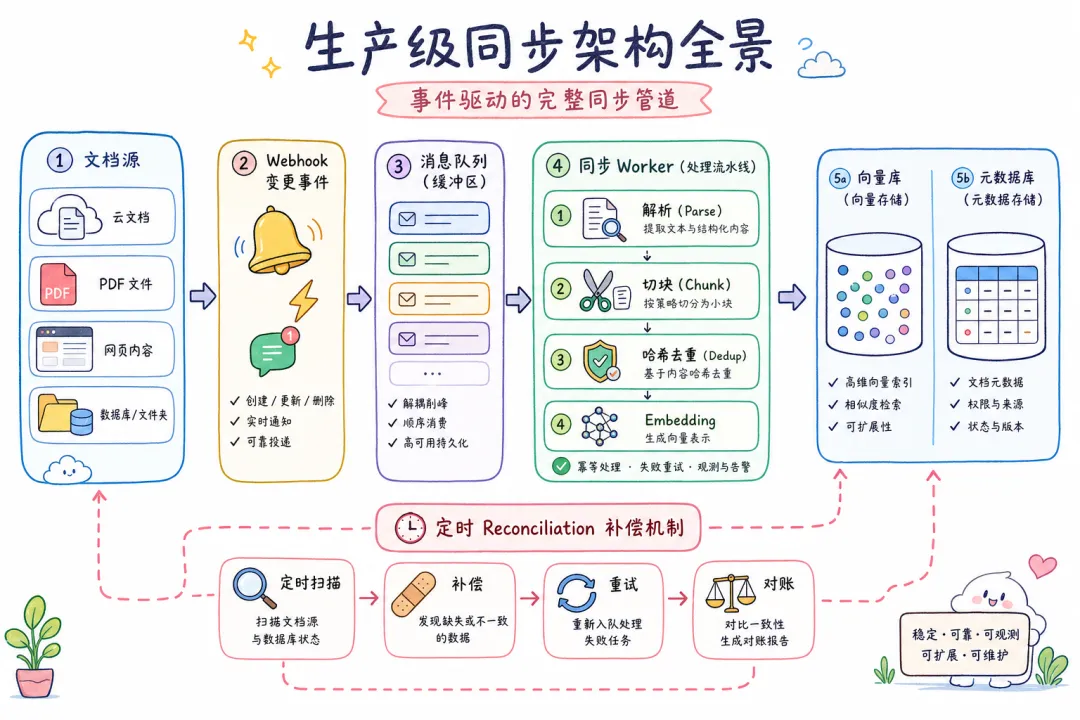
前面讲的都是单次操作。生产环境里,文档变更是持续发生的,需要一套自动化的同步管道。
推荐架构:
文档源(Confluence/Notion/S3)
↓ 变更事件(Webhook / CDC / 轮询)
消息队列(Kafka/Redis Queue)
↓ 消费(at-least-once delivery)
同步 Worker
├── 解析 + 切块
├── 哈希去重(跳过未变化的 chunk)
├── Embedding(只对变化的 chunk)
└── 写向量库 + 更新元数据库
↓
一致性检查(定时 Reconciliation)
└── 扫描元数据库和向量库的差异,自动补偿
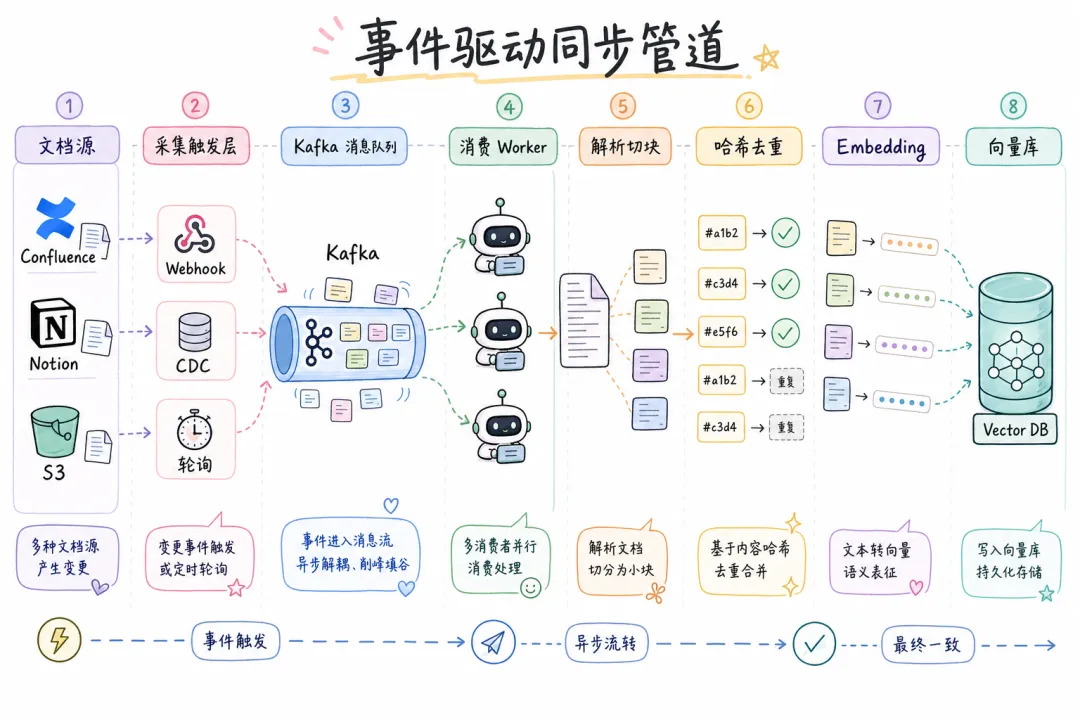
关键设计点:
// Worker 的幂等处理
async function processDocumentEvent(event: DocumentChangeEvent) {
const { type, source, docId } = event;
// 记录处理状态(避免重复处理)
const status = await getProcessingStatus(event.eventId);
if (status === "completed") {
console.log(`事件 ${event.eventId} 已处理,跳过`);
return;
}
try {
await markProcessing(event.eventId);
switch (type) {
case "created":
case "updated":
await syncDocumentToVectorStore(source, { cleanup: "incremental" });
break;
case "deleted":
await softDeleteDocument(docId);
break;
}
await markCompleted(event.eventId);
} catch (err) {
await markFailed(event.eventId, err.message);
throw err; // 触发消息队列的重试机制
}
}
// 定时 Reconciliation:发现并修复不一致
async function reconcile() {
// 1. 查元数据库:所有 is_deleted=false 的文档
const activeDocs = await metaDB.findAll({ is_deleted: false });
// 2. 查向量库:所有存在的 doc_id
const vectorDocIds = await vectorStore.listDocIds();
// 3. 找出差异:元数据库有但向量库没有的
const missing = activeDocs.filter(d => !vectorDocIds.includes(d.doc_id));
// 4. 补偿:重新同步缺失的文档
for (const doc of missing) {
console.log(`补偿同步: ${doc.source}`);
await syncDocumentToVectorStore(doc.source, { cleanup: "incremental" });
}
}
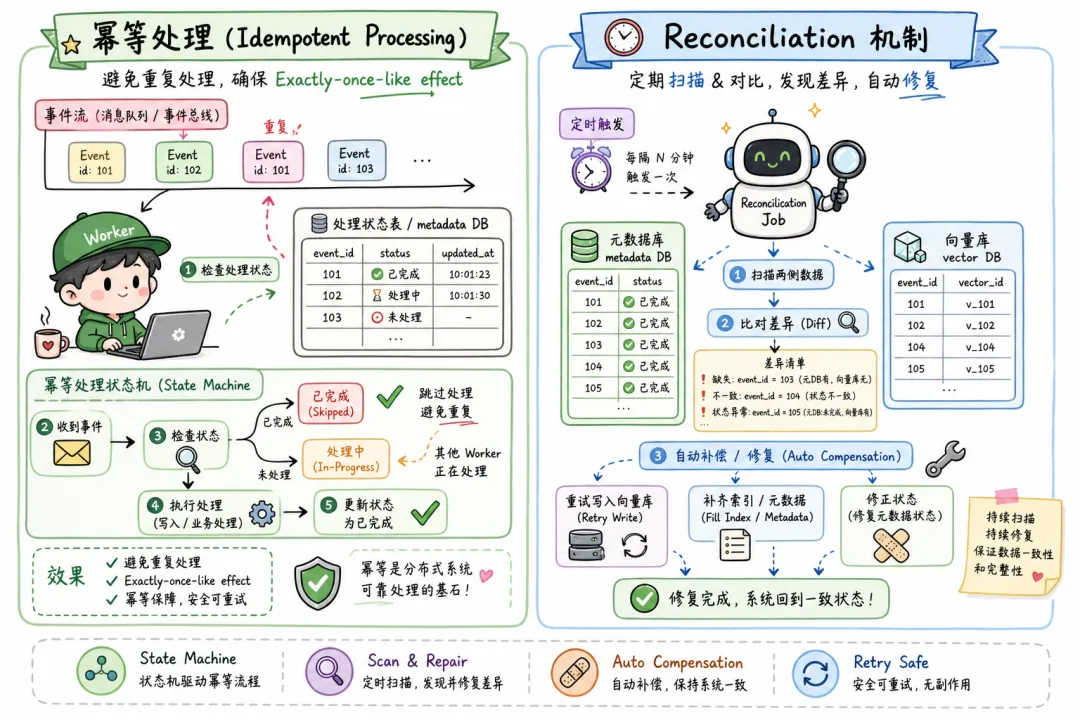
08 常见坑:这几个错误 90% 的人都踩过
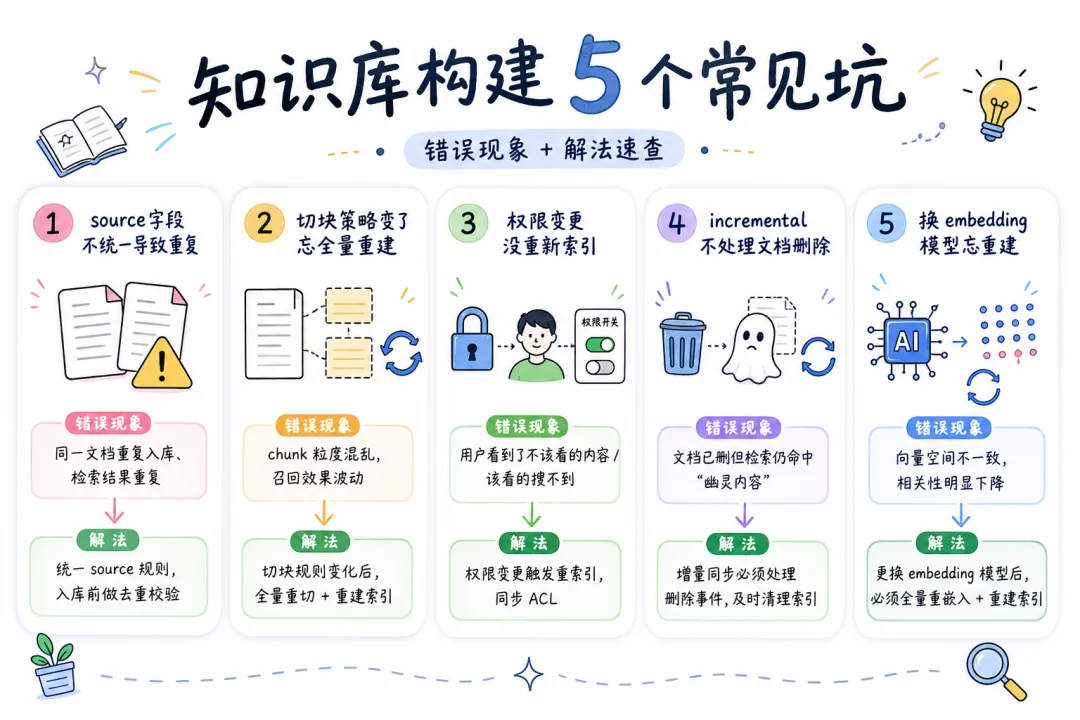
坑 1:source 字段没有统一规范,导致同一文档被识别为不同来源。
/data/docs/product.pdf 和 ./docs/product.pdf 对于 Index API 来说是两个不同的 source。文档更新了,旧 chunk 没被清理,反而增加了一份新的。
→ 规范:所有文档统一用绝对路径或全局唯一 ID 作为 source。
坑 2:切块策略变了,但忘了触发全量重建。
从 chunkSize=512 改成 chunkSize=256,同一篇文档切出来的 chunk 数量翻倍。incremental 模式无法感知切块策略的变化(只看内容哈希),结果新旧两套 chunk 并存在库里。
→ 解法:把切块策略(chunkSize、overlap、策略名)也写进元数据,切块策略变更时触发 full 模式重建。
坑 3:权限变更没有触发重新索引。
一篇文档从「所有人可见」改为「仅高管可见」,但向量库里 chunk 的 acl 字段还是旧的。普通员工查询时仍能召回。
→ 解法:权限变更事件和内容变更事件一样,都要触发文档重新索引,确保 acl 元数据同步。
坑 4:incremental 模式不处理文档删除。
incremental 只能清理「已更新文档的旧版本」,无法感知「文档从源系统被彻底删除」。如果文档被删了,还用 incremental 模式,旧 chunk 永远不会消失。
→ 解法:文档删除事件用 full 模式(传入剩余文档的完整列表),或手动按 source 删除记录。
坑 5:换了 embedding 模型,忘了重建索引。
上线前测试用 text-embedding-ada-002,上线后业务方要求换 text-embedding-3-large。直接换了调用模型,但历史 chunk 还是 ada-002 的向量,查询时召回率骤降。
→ 解法:模型版本写进元数据,换模型时检查不一致,强制触发全量重建。
总结
知识库动态更新,核心是保证向量库、元数据库、原始文档三层一致,任何一层脱轨都会导致召回结果失真。
-
哈希去重是增量同步的基础:用 SHA-256 判断 chunk 内容是否变化,未变的跳过 Embedding,大幅节省成本 -
修改文档必须清理旧向量: incremental模式按source自动清理旧版本,单纯写入新 chunk 是最危险的做法 -
删除推荐软删除 + 延迟物理清理:保留 30 天审计窗口,误删可恢复,合规删除有保障 -
切块策略变更 = 全量重建: incremental模式无法感知切块策略变化,策略改了必须触发重建 -
Embedding 模型升级用蓝绿切换:不原地改,新建索引验证稳定后切别名,保留旧索引用于回滚 -
生产环境加补偿机制:定时 Reconciliation 扫描三层数据差异,自动修复不一致
下一篇我们进入 RAG 效果评估,聊聊怎么知道你的检索到底好不好——用数据说话,而不是「感觉还行」。
关注我,James 的成长日记,持续分享干货,帮你在 AI 时代少走弯路。