夜雨聆风
夜雨聆风





我用AI大神的Auto Research框架迭代了1000次我的APP,把提示词从30分提到了90分
普通人到底怎么才能用上国外顶级 AI 研究员的最新思想,来打造自己的产品?
视频版本:
大家好,我是麒桦。
最近我一直在死磕「伟大的我」APP 的 Mac 版。因为这次真的是把它当成艺术品在打磨,所以进度稍微慢了点,但很快就能和大家见面了。
在 Mac 版里,我设计了一个很酷的 Dashboard,有点像特工电影里的那种感觉。里面有一个我非常喜欢的核心功能,叫「战术地图」。
战术地图到底是什么?
「伟大的我」是一个帮助用户设立人生目标、每天打卡、每周复盘,并且不断迭代自己的个人成长 APP。
战术地图做的事情很简单:它会从你每天的打卡、复盘、和 AI 的聊天记录里,自动提炼出你正在推进的事件、项目、产品和任务,然后把它们变成一张行动脉络图。
也就是说,你可以一眼看清:
-
你最近真正推进的主线是什么; -
哪些事情之间互相影响; -
一个项目在时间线上是怎么发展的; -
哪些节点算里程碑,哪些只是临时状态。
如果这个功能做好了,它就不是一个普通的记录页,而是一个真正能帮助你理解自己行动路径的系统。
但刚开始,它的效果我很不满意。
最大的问题:提取出来的东西又碎又散
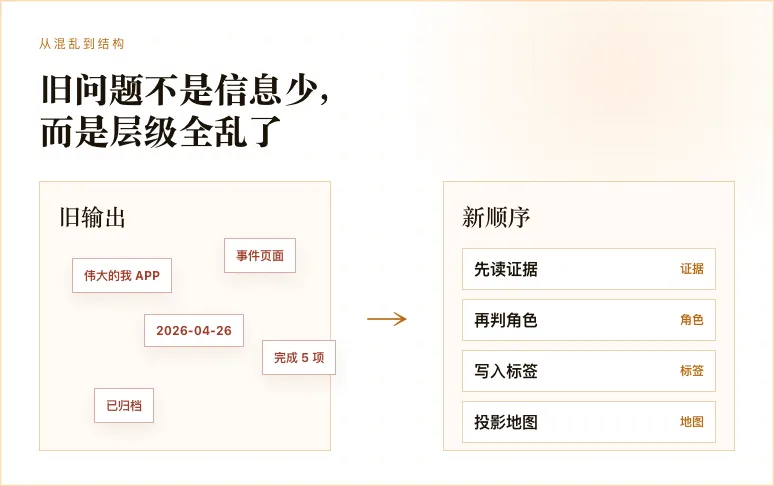
一开始的战术地图,经常会把一些很临时、很局部的东西,当成独立事件。
比如日期、版本号、一次性的进度状态,甚至「完成 5 项」这种临时描述,都可能被它提取成一个泡泡。结果就是地图上全是东西,但你反而看不出真正的主线在哪里。
更麻烦的是,一二级事件之间的关系也不稳定。有时候一个大事件下面塞了一堆不该属于它的东西;有时候明明是同一条主线,又被拆成很多碎片。
以前我们优化这种问题,基本就是看到哪里不对,就去改提示词。结果经常变成「拆东墙补西墙」:修好了一个 bug,另一个逻辑又崩了。
这也是我一直对这个功能不够满意的原因。它有潜力,但还不够稳定。
Auto Research 给了我一个新思路
前段时间,Andrej Karpathy 提到一个很有意思的概念:Auto Research。
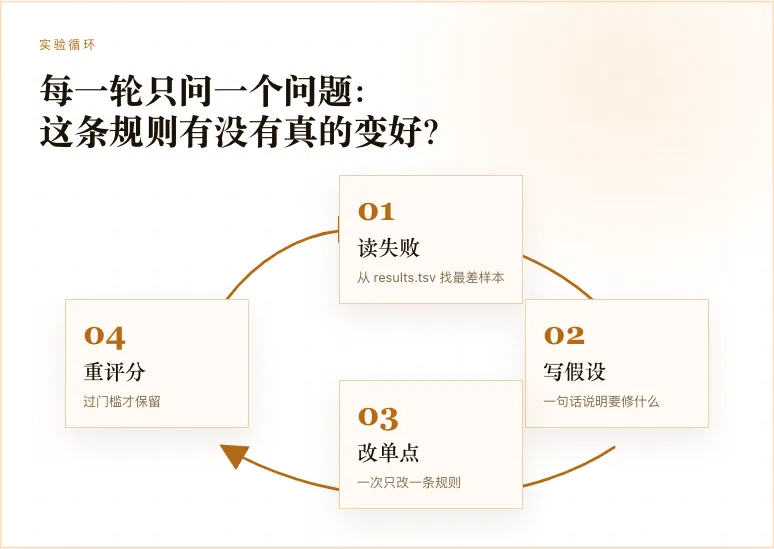
它的核心不是让 AI 一口气把所有东西都改完,而是把任务切得很小,建立一个稳定的评分机制,每次只改一点点,然后不断测试、评分、保留有效变化、淘汰无效变化。
这个思路我非常喜欢。
一开始我尝试把它用在文章优化上,但后来发现文章这类东西很难量化。什么叫更好?更有感染力?更有结构?这些当然可以判断,但很难稳定打分。
后来我突然意识到:AI 产品里的提示词和规则,反而是一个特别适合 Auto Research 的场景。
因为它既有很容易量化的部分,比如 JSON 格式是否稳定、输出是否合规、耗时是否可控;也有适合让大模型判断的部分,比如一级事件和二级事件之间的关系是否合理,事件命名是否清晰,主线是否突出。
我准备了两类数据
这次实验,我用了 DeepSeek V4 Flash 和 Doubao Seed 2.0 Lite 260428 作为主要提炼模型。
同时,我准备了两类数据。
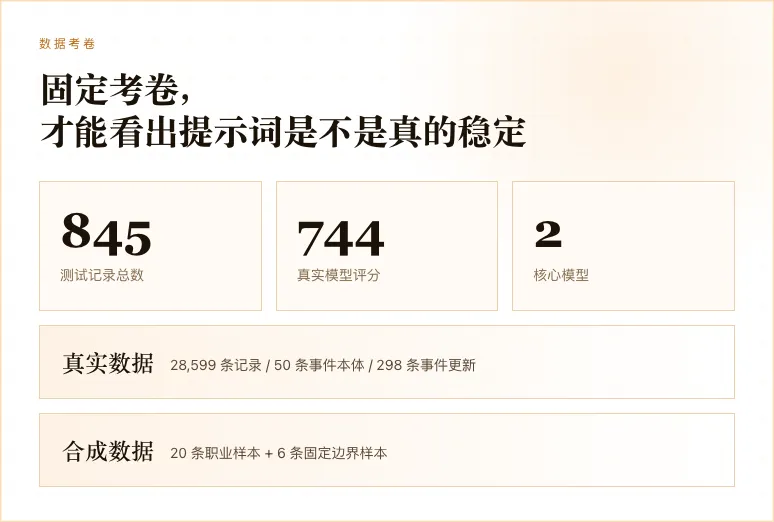
第一类是真实数据。来自我自己的「伟大的我」备份 ZIP,一共有 28,599 条记录,23 个附件,50 条事件本体,298 条事件更新。这里面有 active 事件,也有 archived 事件。
第二类是合成数据。因为我自己的使用数据会比较偏独立开发者,所以我让 GPT 生成了 20 条不同职业的合成样本,再加上 6 条固定边界样本,覆盖碎片化、主线/支线、多工作线、手动标题保护、删除/静音不复活等情况。
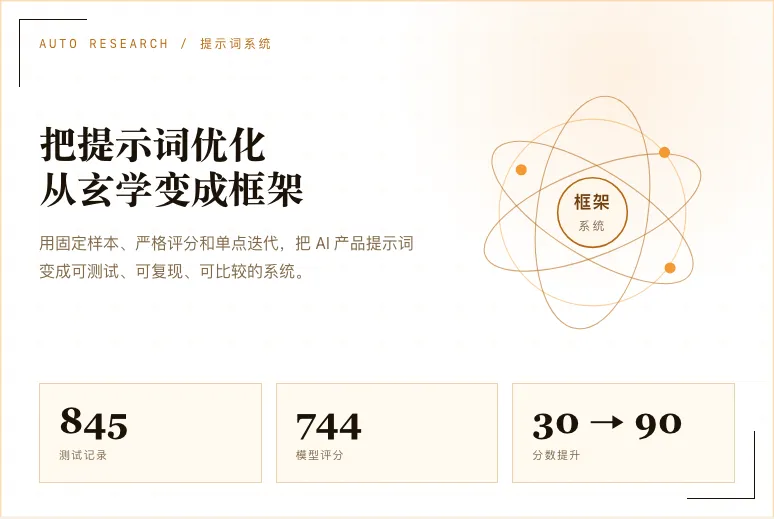
最终,我们一共得到 845 行测试记录,其中 744 次是真实模型评分。合成样本和真实 ZIP 样本大约各占一半。
这个实验不是随便跑几次看感觉,而是把模型放到固定考卷里反复测。
评分规则:不是看文笔,而是看是否听话
这次我给战术地图设定了几条非常明确的规则。
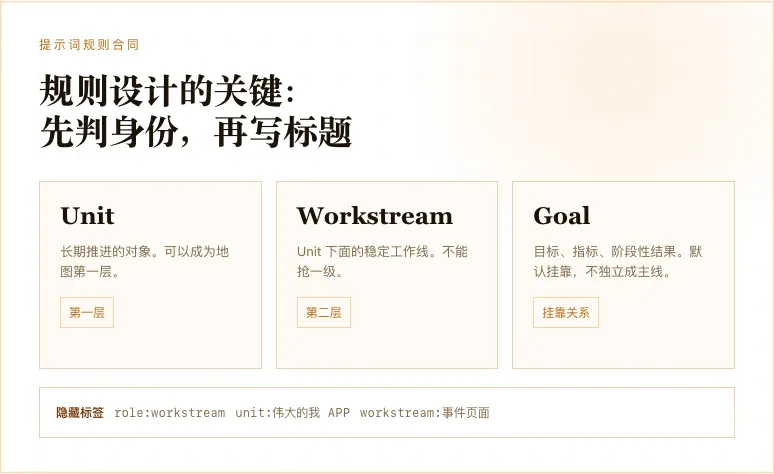
第一,一级事件必须是主线,不是任何出现过的名词都能成为一级事件。
第二,二级事件必须服务于一级事件,不能随便挂靠。
第三,日期、版本号、数量、一次性状态,不能被当成事件标题。
第四,用户手动修改过的标题要被保护,删除或静音过的事件不能被 AI 随便复活。
第五,同一套规则要同时适配 DeepSeek 和 Doubao,不能只对某一个模型有效。
这个部分很关键。因为真正稳定的提示词,不是写得漂亮,而是可测试、可复现、可比较。

迭代过程:每次只解决一个问题
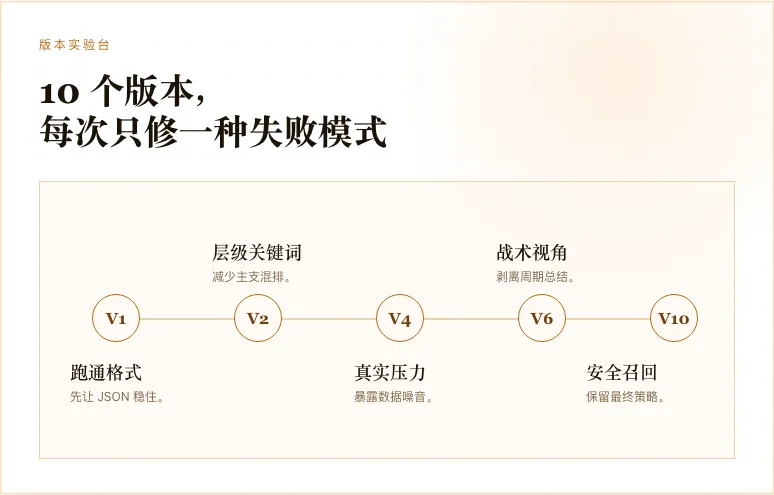
整个过程大概经历了 10 个版本。
V1 到 V2,重点解决的是格式稳定性和整体表达。让模型先别乱输出,先把基本结构站稳。
V3 到 V4,开始处理事件颗粒度。哪些东西能成为事件,哪些只是过程描述,必须区分清楚。
V5 到 V6,重点处理边界问题。比如日期、版本号、临时完成状态、泛化的大标题,不能被提取成主线。
V7 之后,真正困难的问题出现了:二级事件归属。
一级事件其实相对好做。模型只要知道哪些东西是主线,分数就能很快上来。但二级事件很难,因为它需要判断一个小事件到底属于哪个父级,还是应该独立成一个平级分支。
这里如果规则不够清楚,模型就很容易把所有东西塞进一个大框里。
最大的坑:归属感
这次实验里,我觉得最大的坑不是命名,也不是格式,而是「归属感」。
比如一个人同时在做 APP 开发、内容运营、视频脚本和用户反馈。它们当然都和这个人有关,但不代表它们都应该被塞进同一个一级事件下面。
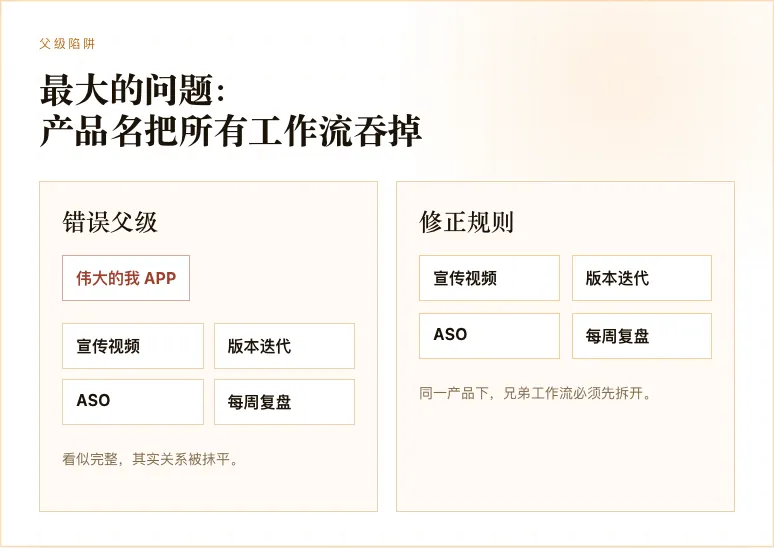
最糟糕的情况,是 AI 生成一个听起来很正确的大标题,比如「伟大的我 APP 整体运营」,然后把所有东西都装进去。
这看起来很完整,但实际上把结构毁掉了。因为所有东西都属于一个大框,就等于你什么关系都没有讲清楚。
所以后来我加了一个更硬的边界规则:先判断同级,再判断父子;先看是否是独立工作流,再看是否需要挂靠。不能因为两个事情都和同一个产品有关,就强行放进同一个父级。
这个调整之后,二级归属的分数从 52.7 提升到了 97.8。
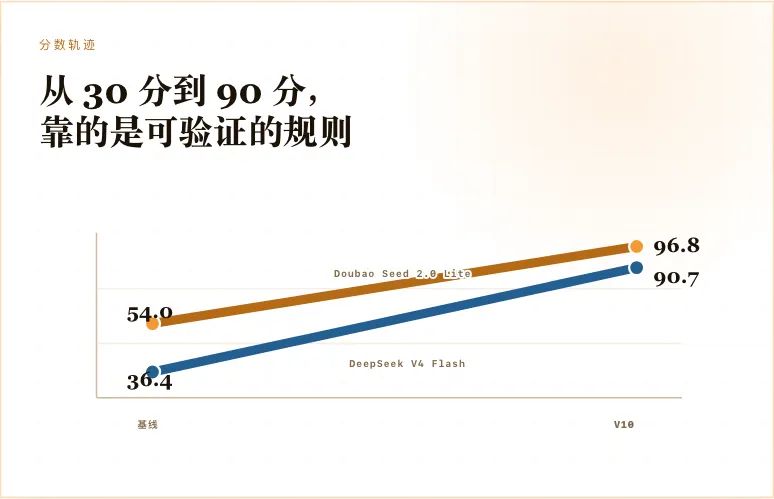
最终结果:从 30 分到 90 分
最后的结果很明显。
DeepSeek V4 Flash 从 36.4 分提升到了 90.7 分。
Doubao Seed 2.0 Lite 260428 从 54.0 分提升到了 96.8 分。
这不是某一次偶然跑出来的好结果,而是在固定样本、固定评分、反复测试之后得到的提升。
更重要的是,最后的提示词不是只对一个模型有效。DeepSeek 更适合做大结构重排,Doubao 更适合做日常刷新和稳定提炼。它们可以分别扮演不同角色。
这件事给我的真正启发
这次实验之后,我对提示词的理解有了一个变化。
提示词不是魔法咒语。
真正重要的不是某一句话写得多漂亮,而是它背后有没有一套稳定的框架:数据怎么准备,规则怎么拆,测试怎么跑,分数怎么打,什么时候保留,什么时候回滚。
所以我现在更愿意把它理解成一个系统工程。
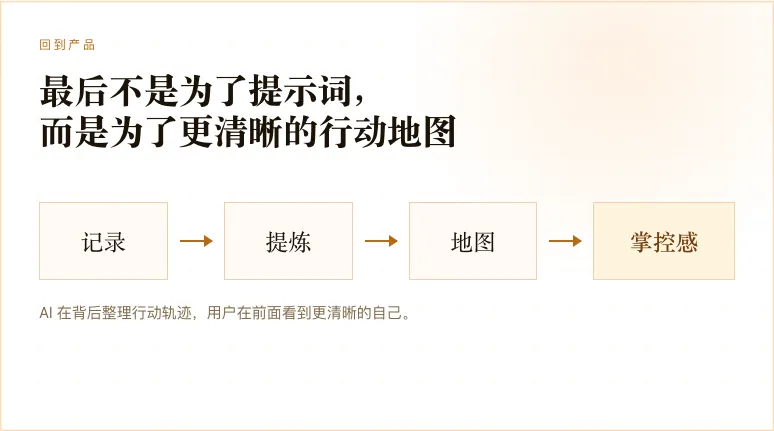
提示词是入口,框架才是核心。

回到「伟大的我」
这件事最后还是要回到产品本身。
我希望「伟大的我」不是一个普通的打卡软件,也不是一个只会陪你聊天的 AI 工具。
它更像一个帮你完成人生任务的系统。
你写下目标,每天回顾自己的胜利和阻碍,每周复盘校准下一步。AI 在背后持续帮你整理行动轨迹、提炼关键事件、识别主线和支线,最后把你的人生推进过程变成一张越来越清晰的地图。
这也是我做 Mac 版 Dashboard 和战术地图的原因。
当一个人能清楚看到自己正在推进什么,过去几周发生了什么,哪些事情在互相影响,下一步应该往哪里走,他就不只是「记录了生活」,而是真的开始拥有一种掌控感。
这次用 Auto Research 优化战术地图,对我来说不只是一次提示词实验。
它让我更确定一件事:普通人当然可以用上顶级 AI 研究员的新思想。关键不是把概念停留在朋友圈里,而是把它放进自己的真实产品、真实问题、真实数据里,然后让它一轮一轮变好。
这就是我这次最想分享的东西。