96.33%!0.9B开源模型登顶文档解析SOTA——闭源API的付费墙正在开裂
百度PaddleOCR-VL-1.6在OmniDocBench v1.6权威评测中以96.33%的准确率超越Gemini-3-Pro、GPT新一代模型等闭源巨头,刷新文档解析SOTA。一个仅0.9B参数的开源模型,正在改写“企业级文档理解必须依赖重型闭源大模型”的行业铁律。
企业想要从堆积如山的发票、合同、表格中自动提取结构化数据,要么购买按次计费的闭源API,要么部署需要A100集群才能跑起来的重型多模态大模型。成本高得离谱,但所有人似乎都默认了这条规则。
直到一个只有0.9B参数的开源模型,用96.33%的准确率把这条规则撕开了一道口子。
2026年6月,百度文心大模型衍生模型PaddleOCR-VL-1.6正式发布,在OmniDocBench v1.6评测集上一举超越Google Gemini-3-Pro、OpenAI GPT新一代模型以及智谱GLM-OCR等国内外主流闭源方案,综合性能登顶全球第一。
这不是一次普通的榜单更新,而是一场榜单地震——一个轻量级开源模型,在包含表格、印章、手写体、多栏排版的复杂文档测试集上,把那些动辄千亿参数的闭源巨兽拉下了王座。
这不是百度第一次在OCR领域制造惊喜。PaddleOCR在GitHub上的Star数已经突破79.2K,超越Google Tesseract OCR,成为全球最受欢迎的开源OCR项目。但1.6版本的冲击力完全不同——它不仅是一个更好的OCR工具,而是一把直接刺向闭源文档解析商业模式的瑞士军刀。
问题来了:为什么一个0.9B参数的轻量模型,能在企业级文档理解这个高价值战场上改写规则?当开源模型的准确率开始碾压闭源方案,那些按次收费的API服务商,还能守住他们的付费墙吗?
OmniDocBench v1.6是什么?它是目前业界最严苛的文档解析评测基准之一,测试集涵盖了多栏排版、嵌套表格、重叠印章、模糊手写体、多语言混合等真实场景中的“脏数据”。在这个基准上拿高分,意味着模型具备了处理企业真实文档的能力,而不仅仅是在干净样本上做秀。
PaddleOCR-VL-1.6交出的成绩单令人窒息:总指标96.33%,在文本识别、公式解析、表格还原等关键子项上全面领先。对比一下:Gemini-3-Pro,Google的多模态旗舰,参数量远超PaddleOCR-VL-1.6,却在这个基准上被反超;GPT新一代模型,OpenAI的最新力作,同样败下阵来。
更值得注意的是,PaddleOCR-VL-1.6在古籍文档识别上也展现出显著增强的能力——这是连许多闭源模型都刻意回避的硬骨头。
榜单背后的隐喻远比数字本身更值得玩味。过去两年,行业的共识是:文档解析需要大参数量、强推理能力的闭源多模态大模型。企业要么接受高昂的API调用成本,要么忍受传统OCR+规则引擎的低准确率。
PaddleOCR-VL-1.6的登顶,等于用开源的方式证明了一件事:文档解析不是参数量竞赛,而是架构效率和训练策略的比拼。
在HuggingFace上,PaddleOCR-VL-1.6已经获得186个likes和4003次下载。对于一个发布仅数日的模型来说,这个增长速度传递的信号很明确:开发者社区正在用脚投票。他们看到了一个不需要A100集群、不需要按次付费、可以在本地部署微调的文档解析方案,而它的准确率甚至比最贵的闭源API还要高。
如果把GPT新一代模型比作一门需要重型卡车拖拽的攻城炮,那PaddleOCR-VL-1.6就是一把精心设计的瑞士军刀——轻便、多功能、在特定场景下反而更锋利。
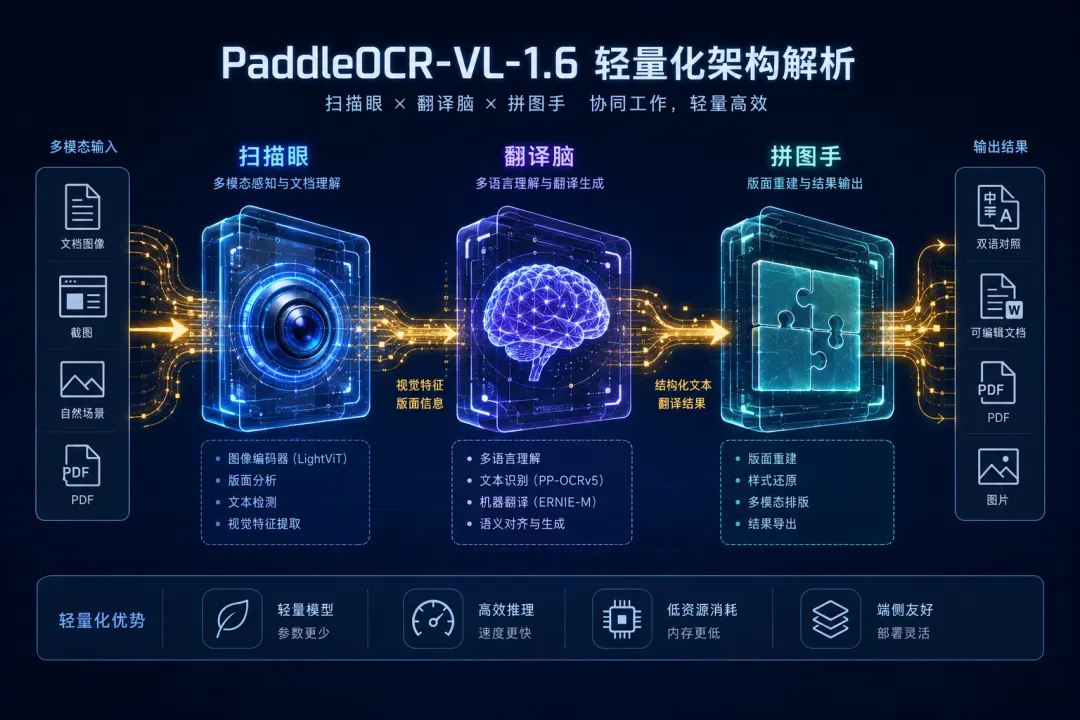
这把军刀的核心锻造工艺,来自三个技术突破。第一,视觉-语言对齐的轻量化设计。PaddleOCR-VL-1.6基于ERNIE-4.5-0.3B基座构建,总参数量控制在0.9B,远低于动辄数百B的闭源大模型。
它像一个被高度训练的“翻译官+扫描仪”合体,而不是一个试图理解万物再顺便做OCR的通用大脑。据GitHub技术文档显示,模型引入了全新的区域感知数据优化框架,能够自动识别文档中的弱区域并针对性增强训练。
第二,多粒度文档元素理解能力。传统OCR只能识别文字,遇到表格就崩溃,碰到印章就抓瞎。PaddleOCR-VL-1.6则像一个“拼图手”,能同时处理文字、表格、图像、印章、公式等多种元素,并将它们还原为结构化的Markdown或JSON格式。
据官方发布说明,模型在Real5-OmniDocBench和OmniDocBench v1.5上也取得了最领先的分数,证明这种多粒度能力不是实验室特调,而是真正的泛化能力。
第三,渐进式后训练优化方案。这是1.6版本相比1.5版本最关键的进化。据arXiv论文显示,PaddleOCR-VL-1.5已经实现了多任务0.9B VLM的鲁棒文档解析。而1.6版本在此基础上引入了从CPT(持续预训练)到SFT(监督微调)再到RL(强化学习)的渐进式训练管线,专门挖掘困难文档区域进行优化。
结果就是:推理速度大幅提升,显存占用显著降低,在一张普通消费级显卡上就能流畅运行。对比上一代1.5版本,1.6在复杂表格还原、印章重叠识别、手写体理解等场景下的准确率提升明显。更重要的是,由于延续了前代架构,企业和开发者可以实现无需额外适配的平滑迁移——这意味着已经部署了1.5版本的企业,可以零成本升级到SOTA性能。
PaddleOCR-VL-1.6的开源,不是一次单纯的技术发布,而是一颗投入商业文档解析市场的深水炸弹。冲击波正在扩散,三类玩家感受到了明显的震感。
第一类,按次收费的闭源文档解析API服务商。他们的商业模式建立在信息不对称之上:企业不知道开源方案能达到什么水平,只能接受高昂的调用费用。现在,一个准确率更高的开源模型摆在面前,企业CIO们会怎么选?答案不言自明。
这就像用免费子弹打穿付费城墙——当开源方案的成本趋近于零,闭源API的定价体系就失去了根基。
第二类,依赖传统OCR+规则引擎的垂直厂商。他们的技术栈还停留在“检测-识别-后处理”的流水线时代,遇到复杂表格需要手写大量规则,维护成本极高。PaddleOCR-VL-1.6的端到端文档解析能力,等于用深度学习的方式一次性替代了这条脆弱的流水线。那些靠堆人力做规则引擎的厂商,可能在一夜之间失去技术护城河。
第三类,动辄需要A100集群部署的重型多模态大模型方案。这些方案准确率可能不低,但部署成本高得吓人。PaddleOCR-VL-1.6能在普通GPU甚至CPU上运行,意味着企业可以将文档解析能力下沉到边缘设备、私有服务器,而不需要把敏感文档上传到云端API。对于金融、医疗、政务等强合规行业,这是一个无法拒绝的诱惑。
百度的战略意图也很清晰。PaddleOCR-VL-1.6是PaddlePaddle生态的一枚特洛伊木马——它以文档解析为入口,将企业开发者绑定到百度的AI基础设施上。一旦企业的文档处理工作流跑在PaddlePaddle上,向上扩展到大模型训练、推理优化、模型部署就变得顺理成章。GitHub上79.2K的Star数不是虚荣指标,而是一个生态帝国的地基。
技术狂欢之后,冷冰冰的现实总会浮出水面。96.33%是实验室准确率,但真实企业场景中的文档,往往比OmniDocBench测试集更“脏”——发票褶皱、印章重叠、多语言混合、手写涂改、复印件模糊,每一个变量都可能让准确率大幅衰减。
行业内的一个残酷经验是:实验室SOTA的96%准确率,到了真实产线可能衰减到90%以下。对于月处理百万级文档的企业来说,10%的错误率意味着每月数万张文档需要人工复核——这依然是一笔不小的成本。
但讽刺的是,恰恰是这个“衰减问题”,构成了开源模型对闭源API最致命的攻击点。闭源API是一个黑箱,企业无法针对自己的文档类型进行优化。而PaddleOCR-VL-1.6是开源的,企业可以用自己的数据对模型进行微调——用真实场景中的褶皱发票、重叠印章样本“驯化”模型,将准确率从90%推到99%以上。
PaddleOCR-VL-1.6的GGUF版本已经在HuggingFace上线,下载量达到2054次。这意味着模型可以在消费级硬件上运行,企业不需要搭建昂贵的GPU集群就能完成微调和推理。对于中小型企业来说,这是一个质变的门槛降低——过去只有大厂才能玩得起的文档AI,现在一个创业团队也能轻松部署。
从SOTA到产线的最后一公里,从来不是技术问题,而是工程问题。PaddleOCR-VL-1.6提供的不是一套完美无缺的方案,而是一个可以无限接近完美的起点。它把“驯化模型”的权力交还给了企业,而不是锁在API的付费墙后面。
96.33%这个数字,注定会成为文档解析历史上的一个分水岭。它宣告了一个事实:在垂直场景的深度优化面前,通用大模型的参数优势不再是不可逾越的壁垒。一把精心锻造的瑞士军刀,可以在特定战场上比攻城炮更精准、更高效、更致命。
当文档解析这个高频刚需场景被开源方案占领,闭源API的付费城墙还能撑多久?当企业发现可以用自己的数据将模型“驯化”到99%准确率,他们还会为按次计费的API买单吗?答案正在风中飘荡。
对于那些还在依赖闭源API的企业来说,或许该认真问自己一个问题:你的文档数据,值得被锁在一堵付费墙后面吗?
你的团队是否还在为文档解析的API调用成本头疼?开源模型的96.33%准确率,是否足以让你考虑从闭源方案迁移?评论区聊聊你的真实经历~
 夜雨聆风
夜雨聆风