 夜雨聆风
夜雨聆风





从 Word2Vec 到 Qwen3 Embedding:向量模型为什么变成 AI 搜索底座?
摘要:Embedding 的进化史,不是“把文本变成向量”这么简单。Word2Vec 解决的是词如何进入连续空间,DSSM 和双塔模型解决的是 query、用户、商品、文档如何被快速召回,SBERT 和 DPR 解决的是 BERT 语义能力如何进入向量检索,E5、BGE、GTE 和 Qwen3 Embedding 则把 embedding 从一个召回模型,推成了 RAG、AI 搜索、推荐、代码检索和 Agent 记忆的基础设施。
很多人现在重新关注 embedding,是因为 RAG、AI 搜索、企业知识库、Agent memory 都绕不开它。大模型可以生成答案,但它不能凭空知道你的私有文档、商品库、工单、代码仓库和实时业务状态。只要系统还需要从外部世界取信息,就需要一个东西把 query 和候选内容放进可比较的空间里。
这个东西就是 embedding model。
但如果只说“embedding 是把文本转成向量”,就太浅了。这个定义解释不了为什么 Word2Vec、DSSM、YouTube 双塔、SBERT、DPR、E5、BGE-M3、Qwen3 Embedding 会出现在同一条技术线上。它们看起来都在做向量,实际上解决的问题完全不同。
Word2Vec 解决的是词表示问题:one-hot 太稀疏,词和词之间没有距离。DSSM 解决的是搜索匹配问题:query 和 document 需要投到同一个语义空间。推荐双塔解决的是工业召回问题:亿级 item 必须提前编码,线上只能做近邻搜索。SBERT 和 DPR 解决的是 Transformer 语义能力如何进入检索系统。E5、GTE、BGE-M3 和 Qwen3 Embedding 解决的则是另一个问题:embedding 能不能变成一个通用文本基础模型,而不是每个业务单独训练一个召回器。
所以这篇文章的主线不是“embedding 模型越来越强”,而是:
向量模型的角色,正在从语言表示,变成检索系统的底座。
如果只记一个结论,我会这样说:
从 Word2Vec 到 Qwen3 Embedding,技术演进的核心不是把向量维度做大,也不是把 benchmark 分数刷高,而是在不断重新平衡三件事:语义表达、召回效率、系统可控性。
先看完整路线
这条路线可以先压成一张表。后面每一节再展开讲。
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Word2Vec:先让词进入连续空间
在 Word2Vec 之前,文本表示最常见的方式是 one-hot 或词袋。一个词对应词表里的一个位置,出现就是 1,不出现就是 0。这个表示非常直接,但有一个致命问题:词和词之间没有距离。
“国王”和“王后”在 one-hot 里是两个完全独立的维度,“北京”和“中国”也是两个完全独立的维度。模型看不到它们之间有什么语义关系。更麻烦的是,词表越大,向量越稀疏,绝大多数位置都是 0。这样的表示适合倒排索引和关键词匹配,但不适合让神经网络学习语义结构。
Word2Vec 的关键变化,是把词映射成低维稠密向量。一个词不再是词表里孤立的 ID,而是连续空间里的一个点。语义相近的词,在训练后会出现在相近位置。
它背后的直觉来自分布式假设:一个词的意义,可以由它周围出现的词来刻画。也就是说,如果两个词经常出现在相似上下文里,它们的向量也应该接近。
Word2Vec 主要有两种训练方式。
第一种是 CBOW,也就是 Continuous Bag-of-Words。它用上下文预测中心词。比如句子里出现“我 在 北京 上班”,模型可以根据“我、在、上班”去预测“北京”。CBOW 的优势是训练快,对高频词比较稳定。
第二种是 Skip-gram。它反过来,用中心词预测上下文。比如给定“北京”,模型要预测周围可能出现“我、在、上班、中国、城市”等词。Skip-gram 对低频词更友好,因为每个中心词都会产生多个训练样本。
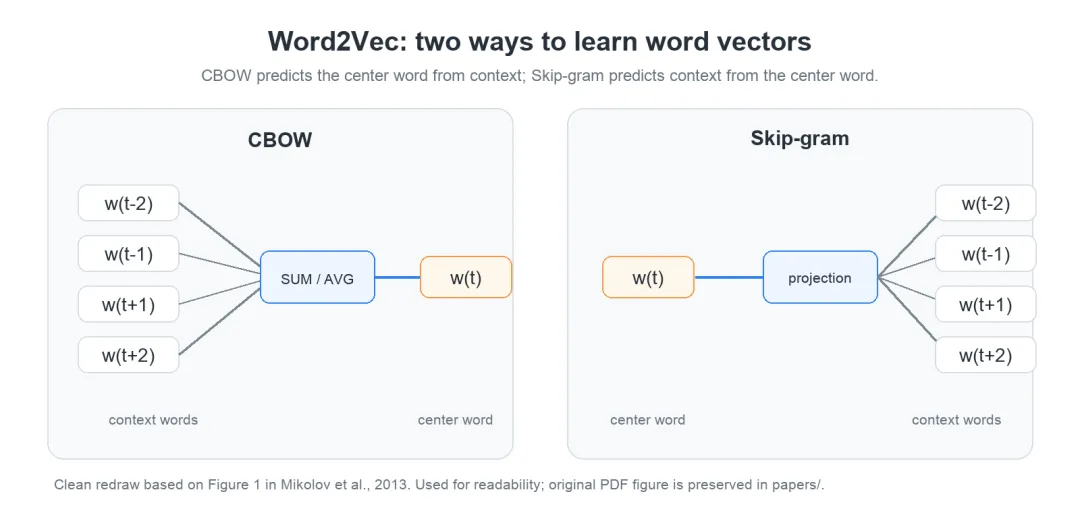
如果直接对整个词表做 softmax,成本会很高。Word2Vec 后续常用 negative sampling 来降低训练成本。模型不再每次都预测全词表,而是让一个真实的词对得分更高,同时采样几个负例词对,让它们得分更低。
可以把目标粗略理解成:
这已经有了后面对比学习的影子:正样本拉近,负样本推远。
Word2Vec 的意义很大。它第一次让“语义相似”变成了向量空间里的几何关系。更重要的是,它证明了一个简单事实:语言中的统计共现结构,可以被压缩进一个可计算、可比较、可迁移的向量空间。
但 Word2Vec 也有明显限制。
第一,它是词级表示,不是句子级表示。一个 query、一个商品标题、一段文档,并不能直接靠一个词向量表达清楚。
第二,它是静态表示。一个词只有一个向量。“苹果”在“苹果手机”和“苹果很好吃”里语义不同,但 Word2Vec 默认给它同一个表示。
第三,它没有真正解决检索相关性。Word2Vec 能告诉你“国王”和“王后”接近,但搜索系统要比较的是 query 和 document、user 和 item、问题和答案。词向量只是原材料,还不是召回模型。
所以 Word2Vec 是 embedding 的原点,但不是现代 embedding 检索系统的终点。它打开了连续语义空间这扇门,后面的技术要解决的是:如何把更长、更复杂、更任务相关的对象放进这个空间。
GloVe 和 FastText:词向量还在补基础表示
Word2Vec 之后,GloVe 和 FastText 可以看成词向量阶段的两次重要补强。
GloVe 的出发点是,Word2Vec 更偏局部上下文预测,而语料里还有大量全局共现统计没有被直接利用。GloVe 直接构建词与词的共现矩阵,让词向量拟合共现概率的比例关系。它关心的不只是“两个词是否共现”,还关心“两个词和其他词的共现模式有什么差异”。
比如 “ice” 和 “steam” 都可能和 “water” 共现,但它们和 “solid”“gas”“cold”“hot” 的共现关系不同。GloVe 希望这种全局统计结构也能进入向量空间。
FastText 解决的是另一个问题:词向量对未登录词和低频词不友好。Word2Vec 通常把每个词当成一个独立单位,如果训练语料里没有某个词,就很难给它合理表示。FastText 把词拆成 character n-grams,也就是子词片段。一个词的向量由多个子词向量组合而来。
这对形态丰富语言、拼写变化、低频词都很重要。比如英文里 walking、walked、walks 共享子词结构,中文虽然没有空格形态变化,但在拼写错误、拼音、英文品牌、型号、混合文本里,子词信息也很有用。
这两条路线说明,早期 embedding 还主要在解决“词怎么表示得更稳”。它们没有改变一个事实:真正的搜索和推荐系统,不是只比较词和词。
搜索系统的问题是:用户输入一个 query,系统要在几百万、几千万、几亿候选里找相关内容。推荐系统的问题是:用户、场景、历史行为和 item 如何在同一个空间里快速匹配。
这个问题需要的不只是词向量,而是一个能把两侧对象编码到同一空间的模型。
于是,双塔出现了。
DSSM:双塔把 embedding 带进搜索系统
DSSM,也就是 Deep Structured Semantic Model,是理解后面双塔召回的一块关键拼图。它的核心思想很直接:query 走一个网络,document 或 title 走另一个网络,最后把两边投到同一个低维语义空间,用 cosine similarity 计算相关性。
这就是双塔结构的原型。
为什么这件事重要?
因为搜索系统不能对每个 query 和每个 document 都做复杂交互。假设有 1 亿个文档,用户来了一个 query,如果你要让 query 和每个 document 都一起进模型算一次相关性,线上根本跑不动。双塔的价值在于,document 侧可以提前离线编码并建索引,线上 query 只需要编码一次,然后做向量近邻搜索。
这其实是一个系统妥协:牺牲一部分 query-document 细粒度交互,换取大规模召回效率。
DSSM 用点击数据训练模型。一个 query 下,用户点击过的 document/title 是正样本,没有点击或随机采样的候选是负样本。训练目标是让点击文档的分数高于负例。它把早期词向量里的“共现统计”推进到搜索场景里的“点击监督”。
这一步带来了三个变化。
第一,embedding 从词级表示变成了对象级表示。query 可以是一个向量,document/title 也可以是一个向量。
第二,embedding 开始服务具体任务。这个向量空间不是为了让“猫”和“狗”接近,而是为了让用户 query 和相关文档接近。
第三,模型结构开始服从线上检索系统。双塔不是单纯的建模偏好,而是为了让文档可以离线编码、在线快速召回。
但 DSSM 也暴露了双塔的根本弱点:两边在最后相似度计算之前几乎没有交互。
这意味着模型只能把 query 和 document 各自压成一个向量,然后希望这个向量保留所有相关性信息。对于短标题、短 query 和大量点击数据,这个方法很有效;但对于复杂语义、长文档、组合约束、否定关系、数字型号,它很容易丢信息。
这就是双塔模型后面一直绕不开的问题:快是快,但太早把信息压扁了。
推荐双塔:向量召回真正工业化
如果说 DSSM 把双塔带进搜索,那么推荐系统把双塔推成了工业召回范式。
推荐里的双塔通常不是 query tower 和 document tower,而是 user tower 和 item tower。用户侧输入可能包括用户画像、历史点击、观看时长、购买行为、地理位置、设备、时间、上下文;物品侧输入可能包括 item ID、类目、标签、标题、作者、价格、视觉特征、发布时间等。
模型把用户编码成一个向量,把 item 编码成一个向量,然后用内积、cosine 或其他相似度做召回。
YouTube 推荐系统里的 candidate generation 就是典型例子。推荐系统不是直接从全量视频里精排,而是先用候选生成模型从海量视频里找出几百个可能感兴趣的视频,再交给更复杂的 ranking model。
这里的关键词不是“语义”,而是“规模”。
推荐系统里的全量候选可能是百万级、千万级甚至更大。item 向量必须能离线更新,线上用户向量必须能实时计算,ANN 检索必须足够快。双塔在这里解决的是 first-stage retrieval 的核心问题:在可接受延迟内,把全量候选缩小到一个可排序的集合。
但推荐双塔也说明了 embedding 的另一个侧面:它不一定只来自文本。
用户行为可以被 embedding,商品 ID 可以被 embedding,视频可以被 embedding,作者可以被 embedding,类目和标签也可以被 embedding。现代推荐系统里的 embedding table 本质上是在给各种离散实体学习连续表示。
这和 Word2Vec 其实是同一类思想:把离散符号放进连续空间。只不过 Word2Vec 的符号是词,推荐系统的符号是用户、商品、视频、广告、类目和行为序列。
推荐双塔的局限也很清楚。
第一,它强依赖平台内行为闭环。如果用户和 item 的历史交互足够多,模型可以学得很好;但冷启动用户、冷启动商品、长尾 item 会困难。
第二,它更像行为相似,不一定是语义理解。用户喜欢 A,所以可能喜欢 B,这不等于模型理解了 A 和 B 的文本语义。
第三,双塔仍然缺少细粒度交互。用户某一次具体需求和 item 某个具体属性之间的匹配,往往要交给后面的排序模型。
所以推荐双塔把 embedding 工业化了,但它没有解决语言理解。这个问题要等到 Transformer 和 BERT 之后,才被重新打开。
BERT:语义理解变强,但检索变慢
BERT 带来的变化,是上下文表示。
Word2Vec 时代,一个词通常只有一个向量。BERT 之后,同一个词在不同句子里会有不同向量。“苹果发布新手机”和“苹果很甜”里的“苹果”,上下文不同,表示也不同。
BERT 用 Transformer encoder 做双向上下文建模。每个 token 可以 attend 到句子里的其他 token,因此模型能捕捉更复杂的语义、句法、指代和组合关系。
在文本匹配任务里,BERT 最直接的用法是 Cross-Encoder:把 query 和 document 拼在一起输入模型,让所有 token 充分交互,然后输出一个相关性分数。
这类模型通常很准,因为 query 里的每个词都可以和 document 里的每个词交互。它能看出局部匹配、否定、数字、实体、短语关系,也能判断一些双塔容易压扁的信息。
但 Cross-Encoder 有一个致命问题:不能大规模召回。
因为 document 不能提前独立编码。每来一个新 query,都要和每个候选 document 重新拼接、重新跑模型。如果候选有 1 亿个,这个成本不可接受。
所以 BERT 在检索系统里造成了一个新的张力:
Cross-Encoder 相关性强,但太慢;Bi-Encoder 可以召回,但交互弱。
后面很多 embedding 模型,本质上都是在这个张力里找平衡。
SBERT:把 BERT 重新双塔化
SBERT 的出现很自然。既然原生 BERT 做句对匹配太慢,那能不能把 BERT 改造成 sentence embedding 模型?
SBERT 用 Siamese 或 triplet network 结构,把两个句子分别输入同一个 BERT/RoBERTa encoder,得到两个句向量,再用 cosine similarity 比较。
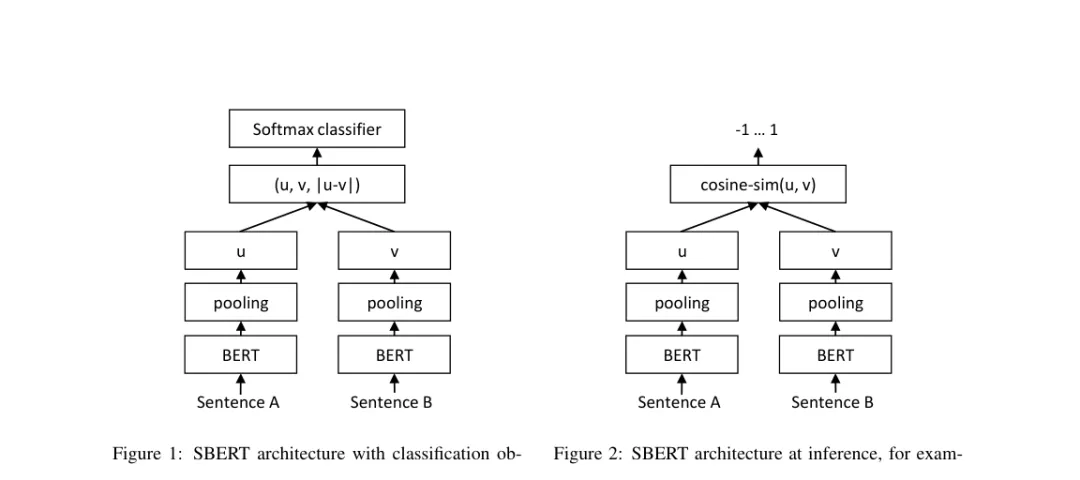
它的意义不是“发明了双塔”,而是把强语义模型重新拉回双塔结构。BERT 的上下文理解能力被保留下来一部分,但句子可以提前编码,向量可以缓存,可以做近邻搜索。
SBERT 论文里有一个很有代表性的数字:如果用普通 BERT/RoBERTa 做 1 万个句子的相似句搜索,需要约 5000 万次推理,论文估算大约 65 小时;SBERT 可以把这个过程降到约 5 秒。这个量级差异说明,检索系统的结构约束不是小问题。
SBERT 解决的是 sentence-level semantic similarity。它让句子、段落、短文本可以变成可比较的向量。它对聚类、去重、STS、语义搜索都很有用。
但 SBERT 也不是开放域检索的完整答案。
第一,STS 相似度不等于检索相关性。两个句子语义相似,不代表一个文档能回答一个问题。比如 query 是“如何治疗偏头痛”,一个文档如果也在讨论“偏头痛症状”,语义很近,但不一定包含治疗方法。
第二,训练数据很关键。SBERT 如果主要在 NLI、STS 数据上训练,就会更擅长句子相似,而不一定擅长 passage retrieval。
第三,负样本还不够难。真实检索里,最难的不是随机负例,而是“看起来很像但其实不回答问题”的 hard negatives。
于是 dense retrieval 进入下一阶段:专门为检索训练双编码器。
DPR:双塔进入开放域问答和 RAG 前夜
DPR,也就是 Dense Passage Retrieval,是现代 RAG 检索线里的重要节点。
DPR 的任务很明确:给一个自然语言问题,从大量 passage 里找出包含答案的段落。它不再只是判断两个句子像不像,而是要解决 open-domain QA 的 first-stage retrieval。
模型结构仍然是双编码器:
训练时,一个问题对应一个正 passage,同时采样负 passage。DPR 常用 in-batch negatives,也就是一个 batch 里其他问题的正 passage,可以顺便当作当前问题的负例。这样可以在不显著增加计算的情况下扩大负样本数量。
目标可以粗略写成:
这就是典型的对比学习:正 passage 拉近,负 passage 推远。
DPR 的意义在于,它证明 dense retriever 可以在开放域问答里挑战传统 BM25。论文在多个 QA 数据集上报告,DPR 相比强 Lucene-BM25,在 top-20 passage retrieval accuracy 上有 9 到 19 个点的绝对提升。
这对后来的 RAG 很关键。因为 RAG 系统需要先把相关文档取出来,再交给生成模型。如果第一阶段检索不到证据,生成模型后面再强也只能胡猜。
但 DPR 也暴露了 dense retrieval 的典型问题。
第一,训练数据分布很重要。DPR 在 QA 数据上训练,很适合问题-段落检索;换到法律、医疗、电商、代码、企业文档,未必直接泛化。
第二,hard negative 决定上限。随机负例太容易,模型学不到细粒度边界。后续 ANCE、RocketQA 等工作都在围绕更难负样本、更强训练策略做改进。
第三,单向量压缩仍然会丢信息。一个 passage 可能包含多个主题、多个实体、多个答案线索。把它压成一个向量,难免损失 token 级匹配。
这就是为什么 ColBERT、SPLADE 和 hybrid retrieval 会出现。
ANCE 和 hard negatives:dense retrieval 真正难的是负样本
很多人理解 dense retrieval 时,只看到“把文本编码成向量”。但训练 dense retriever 的难点,常常不是 encoder,而是负样本。
如果负样本是随机 passage,任务太简单。用户问“中国首都是哪里”,随机负样本可能是“如何训练猫”“篮球比赛规则”,模型很容易区分。这种训练不会教模型处理真实检索里的难例。
真实难例往往是这样的:
用户问“中国首都是哪里”,负例可能也在讲“中国城市”“北京历史”“上海是中国最大城市”。它们和 query 有大量重合词,语义也接近,但不一定直接回答问题。
ANCE 的思路是用 ANN index 动态挖负样本。模型训练过程中,会定期用当前模型给 corpus 建索引,然后检索出模型认为相似但其实不相关的 passage,把这些作为 hard negatives。这样,模型不断被自己当前最容易混淆的候选挑战。
这一步很重要,因为它把训练和检索系统连接起来了。负样本不是人为随便采的,而是来自当前检索器在真实索引上的错误。
可以把它理解成:
DPR 证明了双编码器可以做开放域检索;ANCE 进一步说明,双编码器要变强,需要让模型在自己的近邻空间里犯错,然后从这些错误里学习。
这和今天 embedding 模型训练里的大规模弱监督、合成数据、hard negative mining 是同一条线。embedding 模型的能力不只来自 backbone,也来自它看过什么正负样本。
ColBERT:承认单向量不够
双塔模型最大的问题,是太早把文本压成一个向量。ColBERT 的思路是:能不能保留双塔的离线编码优势,同时不要把所有 token 信息都压成一个向量?
ColBERT 采用 late interaction。
query 和 document 仍然分别编码,但不是各自只输出一个向量,而是输出 token-level contextual embeddings。检索打分时,对 query 里的每个 token,在 document token 向量里找最大相似度,然后求和。
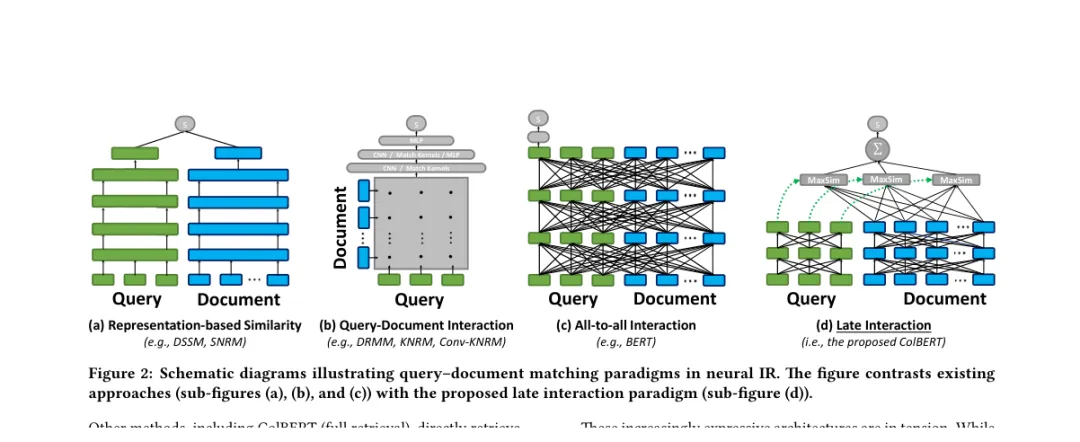
这个 MaxSim 操作让模型保留了更细粒度的词项匹配。query 里的每个重要 token,都可以在 document 里找对应证据。和 Cross-Encoder 相比,它没有让 query 和 document 在 Transformer 层里完全交互;和普通 Bi-Encoder 相比,它又比单向量更细。
ColBERT 的价值在于,它明确提出了一个折中点:
不是所有检索都必须在“单向量双塔”和“全交互 Cross-Encoder”之间二选一。可以先独立编码,再做轻量 token 级交互。
代价也很明显。
ColBERT 的索引比单向量大很多,因为每个 document 不再只有一个向量,而是多个 token 向量。检索和存储复杂度也更高。对于大规模线上系统,这会带来工程压力。
所以 ColBERT 代表的不是“单向量失败”,而是提醒我们:单向量召回很高效,但有表达边界;当任务需要更细粒度匹配时,要么加 multi-vector,要么加 sparse signal,要么加 reranker。
现代 embedding 系统通常会把这些东西组合起来。
SPLADE:另一种补偿是回到稀疏词项
ColBERT 用 multi-vector 修补单向量。SPLADE 则走另一条路线:用神经网络生成稀疏词项权重,重新回到倒排索引。
传统 BM25 的问题是只看字面词项,不懂语义扩展。SPLADE 用预训练语言模型输出词表维度的稀疏向量。输入一段文本后,模型不只是保留原文词,还可能激活一些语义相关词。
比如商品标题写“户外折叠蛋卷桌”,模型可能给“露营”“便携”“桌子”等词权重。这样用户搜“露营桌”时,即使原文没有完整匹配,也能通过扩展词命中。
SPLADE 的关键不是 dense vector,而是 learned sparse vector。它的输出仍然可以进入倒排索引。也就是说,它试图同时要两件事:神经语义扩展和传统搜索系统的可索引性。
这条线在电商搜索里很有意义。因为电商 query 里品牌、型号、规格、颜色、适配关系这些字面约束不能丢。纯 dense retrieval 容易把 iPhone 14 和 iPhone 15 拉得太近,业务上却可能完全不能替换。稀疏检索至少能保住词项级约束。
所以从 ColBERT 到 SPLADE,我们看到的是同一个信号:
双塔单向量不是终点。真实搜索系统会不断把 token 级交互、稀疏词项、hard negatives、reranker 加回来。
BEIR 和 MTEB:embedding 进入 benchmark 时代
DPR、ColBERT、SPLADE 之后,dense retrieval 和 embedding 模型越来越多,一个新问题出现了:到底怎么比较它们?
早期很多模型只在少数数据集上报告结果。有的模型在 STS 很强,有的在 QA retrieval 很强,有的在分类聚类强,有的只在英文强。单一指标很容易误导。
BEIR 解决的是 zero-shot information retrieval 评测。它把不同领域、不同任务的检索数据集放在一起,测试模型在未见领域上的泛化能力。它的重要性在于提醒大家:一个 retriever 在 MS MARCO 上强,不代表它在医疗、金融、事实核查、问答、实体检索上都强。
MTEB 则把范围进一步扩大。它不只看 retrieval,还覆盖 classification、clustering、pair classification、reranking、retrieval、STS、summarization 等任务。原始 MTEB 覆盖 8 类 embedding 任务、58 个数据集和 112 种语言。
MTEB 的出现,把 embedding 模型从“某个检索模型”推向“通用文本表示模型”。一个 embedding model 不再只需要回答“能不能检索”,还要回答:
它能不能做分类?
能不能做聚类?
能不能做跨语言检索?
能不能做语义相似?
能不能在未见任务上泛化?
这对模型训练目标产生了反向影响。后来的 E5、GTE、BGE、Qwen Embedding 都不再只优化单一检索任务,而是围绕多任务、多语言、多场景构建训练数据和评测体系。
但 benchmark 也带来新风险。
第一,MTEB 分数高,不一定代表业务数据好。真实企业知识库、电商搜索、代码搜索、法务检索里的 query 和 document 分布,可能和公开 benchmark 差异很大。
第二,多任务平均分会掩盖具体任务缺陷。一个模型分类强、聚类强,不代表你的 RAG retrieval 强。
第三,leaderboard 会推动模型围绕公开数据优化。使用时仍然需要在自己的数据上评测。
所以 BEIR/MTEB 的意义不是替代业务评测,而是让 embedding 领域有了共同语言。
E5:通用 embedding 开始成型
E5 是现代通用 text embedding 的重要节点。它的全称可以理解成 EmbEddings from bidirEctional Encoder rEpresentations,论文标题是 Text Embeddings by Weakly-Supervised Contrastive Pre-training。
E5 的核心思路是,用大规模弱监督文本对做对比学习,让模型学到可迁移的文本表示。它不是只在少量人工标注数据上训练,而是构建 CCPairs 这样的大规模 text pair 数据,让模型看到大量 query-passage、title-body、question-answer、相似文本等弱监督关系。
这一步很重要,因为 embedding 模型要泛化,不能只靠单一任务。一个通用 embedding 模型需要见过很多种“文本之间应该接近”的关系。
E5 还有一个很实用的设计:输入前缀。
典型用法是:
这个前缀看起来简单,但它把任务角色写进了输入。query 和 passage 不一定是对称的。用户问题、文档段落、标题、答案、分类标签,它们在任务里的角色不同。前缀能让模型知道当前文本是查询还是被检索内容。
这可以看作 instruction-aware embedding 的早期形式。后来的 GTE-Qwen、E5-Mistral、Qwen3 Embedding 会把这件事做得更系统。
E5 的意义在于,它把 embedding 模型从“为某个检索数据集训练一个双编码器”,推向“用大规模弱监督和多阶段训练得到通用文本向量”。论文报告 E5 在 BEIR zero-shot 和 MTEB 上都取得很强结果,说明这种路线是有效的。
但 E5 也说明了一个新问题:embedding 的训练开始越来越像基础模型训练。数据规模、数据混合、任务格式、负样本、微调集、评测集,都会影响模型能力。
模型结构不再是唯一重点,训练配方变成了核心资产。
GTE 和 BGE:通用 embedding 开始卷训练配方
GTE,也就是 General Text Embedding,是阿里通义实验室的一条通用 embedding 路线。它强调 multi-stage contrastive learning:先用大规模弱监督数据预训练,再用高质量标注数据微调。
这个范式后来非常重要,因为它把 embedding 训练拆成了两个目标。
第一阶段要泛化。模型需要从大量弱监督文本对里学到广泛语义关系,不要只适配某个窄任务。
第二阶段要对齐任务。模型需要在高质量检索、相似度、分类、rerank 等数据上调整,让向量空间真正服务下游。
BGE 也是类似方向,但 BGE-M3 把系统野心推得更明显。
BGE-M3 里的 M3 指 Multi-Linguality、Multi-Functionality、Multi-Granularity。它支持 100 多种语言,支持不同检索功能,也支持从短句到长文档的不同粒度输入。更关键的是,它不只输出 dense embedding,还同时支持 sparse retrieval 和 multi-vector retrieval。
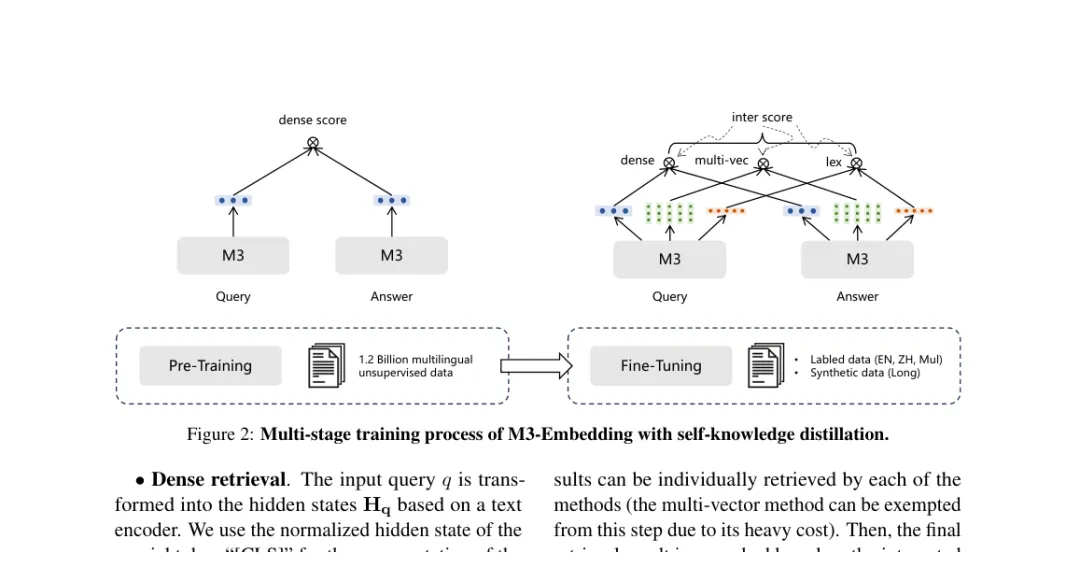
这意味着 BGE-M3 已经不再是传统意义上的“一个向量模型”。
它更像一个检索表示底座:
dense 向量负责语义召回;
sparse 权重保留词项信号;
multi-vector 保留细粒度 token 交互;
长文本支持降低切片损失;
多语言支持跨语言检索。
BGE-M3 背后的信号很明确:真实检索系统不满足于单一表示。BM25、dense vector、ColBERT-style multi-vector 各有优势。与其在系统里维护多个完全割裂的模型,不如让一个 embedding model 同时学会多种检索表示。
这就是 embedding 从模型走向系统组件的关键一步。
为什么 LLM 会进入 embedding?
到 E5、GTE、BGE 这一代,embedding 模型已经很强。但 2024 年之后,一个新趋势变得明显:用大语言模型做 embedding backbone。
这背后有三个原因。
第一,LLM 有更强的语言理解和指令跟随能力。传统 BERT-style encoder 很适合表示学习,但 LLM 在多语言、长文本、复杂任务描述、代码、推理意图上更强。把 LLM 的能力迁移到 embedding,理论上可以提升复杂 query 理解。
第二,LLM 可以参与训练数据生成。现代 embedding 训练需要大量高质量、多任务、多语言的文本对。LLM 可以合成 query、改写文档、生成难负例、产生任务 instruction,降低数据构建成本。
第三,embedding 任务本身开始 instruction 化。用户不只是问“这两段话像不像”,而是问“给定一个网页搜索 query,找能回答它的 passage”“给定一个代码问题,找相关函数”“给定一个医学问题,找可靠证据”。不同任务需要不同向量空间偏好。
E5-Mistral、NV-Embed、GTE-Qwen2 都属于这条线。它们说明 decoder-only LLM 也可以被改造成强 embedding model。
但 LLM-based embedding 有一个现实代价:成本。
一个 7B embedding model 可能分数很高,但线上实时编码 query、离线重算文档库、构建 ANN 索引、支持高并发,都比小 encoder 模型贵。尤其在企业 RAG 或电商搜索里,embedding 不是偶尔跑一次,而是持续服务线上流量。
所以这条路线后面一定会分化:
大模型 embedding 追求效果上限;
中小模型 embedding 追求性价比;
reranker 负责在候选集上补精度;
MRL、量化、蒸馏、缓存、混合检索负责把系统成本压下来。
Qwen3 Embedding 就是在这个背景下出现的。
Qwen3 Embedding:双塔范式被 foundation model 重新封装
Qwen3 Embedding 的论文标题是 Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models。这个标题里最重要的词不是 embedding,而是 foundation models。
它说明 Qwen3 Embedding 的定位不是传统双塔小模型,而是基于 Qwen3 foundation model 做 text embedding 和 reranking 的一整个系列。
从官方信息看,Qwen3 Embedding 包括 0.6B、4B、8B 三个 embedding 模型,也包括 0.6B、4B、8B 三个 reranker 模型。Embedding 模型支持 32K sequence length,0.6B 维度最高 1024,4B 最高 2560,8B 最高 4096,并且支持 MRL,也就是 Matryoshka Representation Learning,可以按需要截取不同维度使用。它还支持 instruction-aware 输入,允许用户针对不同任务、语言和场景写 instruction。
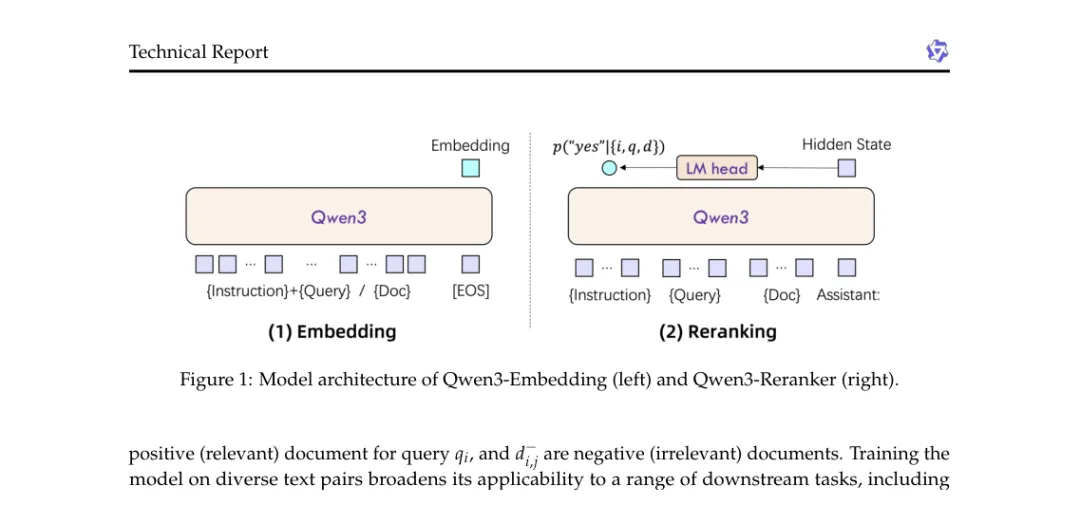
这几个设计合在一起,说明它已经不是“给文本算一个向量”这么简单。
第一,它保留了双塔召回的系统结构。
Qwen3 Embedding 的 embedding model 本质上仍然是 bi-encoder。query 单独编码,document 单独编码,最后用向量相似度检索。这个结构和 DSSM、SBERT、DPR 一脉相承,因为大规模召回仍然需要离线 document embedding 和 ANN index。
第二,它把 backbone 换成了 Qwen3 foundation model。
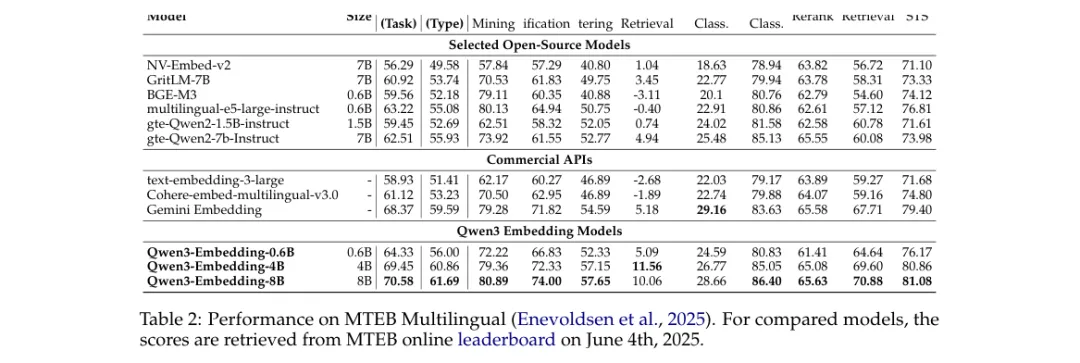
这意味着 embedding model 继承了 Qwen3 的多语言、长文本、代码和复杂文本理解能力。官方报告强调,Qwen3 Embedding 在 multilingual MTEB、代码检索、跨语言检索、多语言检索上表现突出。
第三,它把 instruction 写进 embedding。
传统 embedding 常常假设同一个文本只有一个通用向量。但现实任务不是这样。同一段文本,在“找相似句子”“找能回答问题的证据”“找代码片段”“做聚类”“做 bitext mining”里,应该被不同方式理解。
Qwen3 Embedding 官方示例会给 query 加类似这样的 instruction:
document 侧则不一定加 instruction。这种设计把检索任务显式告诉模型,让模型在编码 query 时带上任务意图。
第四,它把 reranker 作为同系列组件一起发布。
这点非常关键。现代检索系统通常不是 embedding 一步到位,而是:
Embedding 模型负责快,reranker 负责细。Qwen3 同时提供 embedding 和 reranker,说明它面向的是完整检索链路,而不只是一个向量 API。
第五,它支持 MRL 可变维度。
MRL 的直觉是,把表示学习成一种“套娃”结构。前 256 维应该已经有可用语义,前 512 维更好,完整 1024/2560/4096 维最好。这样用户可以按成本和效果取舍:高召回质量用高维,低成本场景用低维。
这对线上系统很实用。向量维度直接影响索引大小、内存、检索延迟和吞吐。embedding 模型如果只能输出固定大维度,部署成本会很高。MRL 让同一个模型服务不同成本档位。
所以 Qwen3 Embedding 的意义,不是“又一个更高分 embedding 模型”,而是它把过去分散的几条线收束到一起:
双塔召回;
LLM backbone;
多阶段训练;
多语言和长文本;
instruction-aware;
MRL 可变维度;
embedding + reranker 组合。
这就是为什么它可以作为这篇文章的终点。它仍然继承 Word2Vec 以来的向量空间思想,也继承 DSSM 以来的双塔召回结构,但训练、能力和系统边界已经完全变了。
从 Word2Vec 到 Qwen3 Embedding,真正变了什么?
把整条线放在一起看,技术变化可以分成五次。
第一次,是从离散符号到连续空间。
Word2Vec、GloVe、FastText 解决的是表示问题。词不再是 one-hot,而是连续向量。这个阶段的关键词是 distributional semantics。
第二次,是从词向量到对象向量。
DSSM、推荐双塔把 query、document、user、item 放进同一个空间。embedding 开始服务召回系统,而不只是 NLP 表示。
第三次,是从静态语义到上下文语义。
BERT 让文本表示依赖上下文,Cross-Encoder 让 query-document 可以充分交互。但计算太慢,所以 SBERT、DPR 又把它重新改造成 bi-encoder。
第四次,是从单任务检索到通用 embedding。
BEIR、MTEB、E5、GTE、BGE 推动 embedding 变成多任务、多语言、多场景的基础模型。训练不再只看一个数据集,而是看大规模弱监督、多阶段对比学习、hard negatives 和任务混合。
第五次,是从 embedding model 到检索系统组件。
BGE-M3、Qwen3 Embedding 说明,现代 embedding 不只是输出一个向量。它要和 sparse retrieval、multi-vector、reranker、instruction、MRL、长文本、多语言、代码检索一起工作。
这条线的底层逻辑一直没变:大规模检索需要把候选提前编码。只要 document/item 侧不能和 query 在线全量交互,双塔就不会消失。
但双塔也一直不够。它太早压缩信息,所以系统会不断把细粒度能力加回来:hard negatives、late interaction、sparse weights、reranker、instruction、LLM-generated data。
这就是 embedding 进化的真实形状:
它不是从弱模型走向强模型,而是在效率和表达之间来回折中。
为什么这件事在 RAG 和 Agent 时代重新重要?
大模型出来以后,很多人以为检索会被生成替代。实际发生的是相反的事:检索更重要了。
原因很简单。大模型的上下文窗口再长,也不能把全世界、全公司、全商品库、全代码仓库都塞进去。它需要外部记忆。RAG、AI 搜索、企业知识库、代码助手、Agent memory,本质上都要回答同一个问题:
当前任务需要哪些外部信息?
这个问题不是生成模型自己能稳定解决的。它需要 embedding model 把 query、任务状态、用户意图、文档、代码、网页、商品、历史记忆放进可检索空间。
在传统搜索里,embedding 是召回模块的一部分;在 RAG 里,embedding 决定模型能不能看到正确证据;在 Agent 里,embedding 决定系统能不能找回历史经验、工具说明、代码片段和中间状态。
所以 embedding 的地位反而上升了。
但这也带来新的要求。
第一,embedding 不能只懂相似度,还要懂任务。
“找相似内容”和“找能回答问题的证据”不是一回事。“苹果手机发布会”和“苹果最新手机价格”语义相近,但一个是新闻,一个是购买意图。Instruction-aware embedding 会越来越重要。
第二,embedding 不能只懂英文短文本。
企业文档是多语言、长文本、表格、代码、PDF、OCR、FAQ、工单混合体。模型必须处理长上下文、多语言和领域术语。
第三,embedding 不能脱离 reranker。
召回模型负责覆盖,reranker 负责精度。越是复杂问题,越不能指望一个向量相似度做最终判断。
第四,embedding 不能只看公开榜单。
真实业务需要自己的评测集。尤其是 hard negatives、领域术语、数字、实体、否定、时间约束、权限边界,这些往往比 MTEB 平均分更重要。
作者判断:embedding 下一阶段会卷什么?
我判断 embedding 接下来不会只卷 leaderboard,而会卷六件更具体的事。
第一,卷 instruction。
同一个文本在不同任务里应该有不同向量。未来 embedding model 会更像小型任务解释器:先理解“我要找什么”,再决定如何编码 query。Qwen3 Embedding 这类 instruction-aware 设计只是开始。
第二,卷 reranker 组合。
单 embedding 分数很难承担最终相关性判断。更实际的系统会默认使用 embedding recall + reranker,甚至 dense + sparse + reranker。embedding 厂商如果只给向量模型,不给 reranker,会越来越不完整。
第三,卷长文档。
今天很多 RAG 系统的问题不是模型不会回答,而是 chunk 切坏了。长文档 embedding、hierarchical retrieval、section-aware retrieval、多粒度索引会继续重要。BGE-M3 的 multi-granularity、Qwen3 的 32K context 都是这个方向。
第四,卷多语言和代码。
企业知识不是纯英文自然语言。中文、英文、代码、日志、表格、混合术语会放在一个系统里。embedding 模型需要在跨语言、跨模态、代码检索上保持稳定。
第五,卷成本。
8B embedding 很强,但不是所有系统都用得起。MRL、量化、蒸馏、小模型、缓存、异步离线编码、低维索引,会成为工程胜负手。
第六,卷业务评测。
未来真正有价值的 embedding 评测,不是只看 MTEB 排名,而是能不能快速构建企业自己的 hard-negative benchmark。谁能把线上失败样本变成评测和训练数据,谁的 embedding 系统就会越用越强。
最后总结
从 Word2Vec 到 Qwen3 Embedding,embedding 的故事可以压成一句话:
一开始,我们只是想让词有向量;后来,我们想让 query、文档、用户和商品能快速匹配;现在,我们想让大模型系统能稳定地从外部世界找回正确的信息。
Word2Vec 证明了语义可以进入连续空间。DSSM 和推荐双塔证明了向量空间可以服务大规模召回。BERT 证明了上下文语义很强,但也暴露了 Cross-Encoder 的计算瓶颈。SBERT 和 DPR 把强语义模型重新双塔化。ColBERT、SPLADE、BGE-M3 说明单向量不够,需要多向量、稀疏权重和混合检索。E5、GTE、Qwen3 Embedding 则把 embedding 推向基础模型化、instruction 化和系统组件化。
所以 Qwen3 Embedding 的位置,不是“Word2Vec 的大号版本”。它更像是这条路线的阶段性汇合点:Word2Vec 的连续空间思想,DSSM 的双塔召回结构,BERT 的上下文语义,DPR 的 dense retrieval,E5/GTE 的多阶段对比训练,BGE-M3 的多功能检索,以及 LLM 时代的 instruction 和 reranker,都被重新组织进一个 embedding 系列里。
这也是为什么 embedding 值得重新写。
它不是旧 NLP 的遗产,而是 AI 应用系统的入口。
参考资料
1. Tomas Mikolov et al. Efficient Estimation of Word Representations in Vector Space. arXiv:1301.3781, 2013. https://arxiv.org/abs/1301.37812. Tomas Mikolov et al. Distributed Representations of Words and Phrases and their Compositionality. NeurIPS 2013. https://arxiv.org/abs/1310.45463. Jeffrey Pennington, Richard Socher, Christopher Manning. GloVe: Global Vectors for Word Representation. EMNLP 2014. https://aclanthology.org/D14-1162/4. Piotr Bojanowski et al. Enriching Word Vectors with Subword Information. TACL 2017. https://arxiv.org/abs/1607.046065. Po-Sen Huang et al. Learning Deep Structured Semantic Models for Web Search using Clickthrough Data. CIKM 2013. https://www.microsoft.com/en-us/research/publication/learning-deep-structured-semantic-models-for-web-search-using-clickthrough-data/6. Paul Covington, Jay Adams, Emre Sargin. Deep Neural Networks for YouTube Recommendations. RecSys 2016. https://research.google/pubs/deep-neural-networks-for-youtube-recommendations/7. Jacob Devlin et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805, 2018. https://arxiv.org/abs/1810.048058. Nils Reimers, Iryna Gurevych. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. EMNLP 2019. https://arxiv.org/abs/1908.100849. Vladimir Karpukhin et al. Dense Passage Retrieval for Open-Domain Question Answering. EMNLP 2020. https://arxiv.org/abs/2004.0490610. Lee Xiong et al. Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval. ICLR 2021. https://arxiv.org/abs/2007.0080811. Omar Khattab, Matei Zaharia. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. SIGIR 2020. https://arxiv.org/abs/2004.1283212. Thibault Formal et al. SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking. SIGIR 2021. https://arxiv.org/abs/2107.0572013. Nandan Thakur et al. BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. NeurIPS Datasets and Benchmarks 2021. https://arxiv.org/abs/2104.0866314. Niklas Muennighoff et al. MTEB: Massive Text Embedding Benchmark. EACL 2023. https://arxiv.org/abs/2210.0731615. Liang Wang et al. Text Embeddings by Weakly-Supervised Contrastive Pre-training. arXiv:2212.03533, 2022. https://arxiv.org/abs/2212.0353316. Shitao Xiao et al. C-Pack: Packaged Resources To Advance General Chinese Embedding. arXiv:2309.07597, 2023. https://arxiv.org/abs/2309.0759717. Jianlv Chen et al. M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. ACL Findings 2024. https://arxiv.org/abs/2402.0321618. Liang Wang et al. Improving Text Embeddings with Large Language Models. arXiv:2401.00368, 2024. https://arxiv.org/abs/2401.0036819. Chankyu Lee et al. NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models. arXiv:2405.17428, 2024. https://arxiv.org/abs/2405.1742820. Yanzhao Zhang et al. Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models. arXiv:2506.05176, 2025. https://arxiv.org/abs/2506.0517621. Qwen Team. Qwen3 Embedding official blog and model cards. 2025. https://qwenlm.github.io/blog/qwen3-embedding/ ; https://github.com/QwenLM/Qwen3-Embedding