 夜雨聆风
夜雨聆风





我用 AI 写了三个月代码,最后发现软件工程一点都没过时
# 我用 AI 写了三个月代码,最后发现软件工程一点都没过时
—
你有没有过这种体验?
打开 AI 编程工具,描述一下需求,代码唰唰唰就出来了。三个小时搞定一个模块,多巴胺疯狂分泌,觉得自己效率爆了。
然后第五天,系统崩了。
不是某一个功能坏了,是整个代码库像被白蚁啃过的木楼,看着还在,一碰就塌。
这不是段子。这是我自己,以及我身边一大批工程师,在过去一年里反复踩过的坑。
今天这篇文章,来自一位在大厂做了多年架构分享的资深工程师的内部复盘。没有广告,没有卖课,全是真金白银砸出来的教训。
—
## 一、AI 是杠杆,不是引擎
这句话值得刻在脑门上。
引擎是创造动力。杠杆本身就有力在那里,只是通过一个支点把它撬起来。力量的源泉还是人。
**AI 让会做事的人做得更多,也让不会做事的人错得更多。**
如果你发现 AI 在自己手上没发挥出价值,先别骂模型。反思一下自己的使用姿势。
同样的道理,代码这东西,过去我们叫它“资产”。但在 AI 时代,**生产出来的代码如果不加验证维护,就是一笔潜在的负债**。
为什么?因为人要维护它,复杂度增加时藏着 bug,总有一天会被改、被删、被重写。功能上线两周用户可能就不喜欢了。负债是确定的,价值是不确定的。
AI 把代码的生成成本打到了趋近于零。但维护、调试、回归、安全合规的成本,反而被进一步暴露了。
**生成趋零,不代表维护免费。**
—
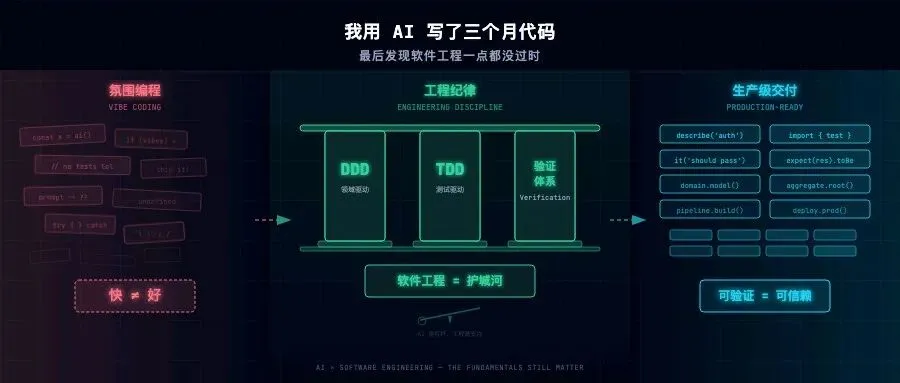
## 二、软件工程不仅没消亡,反而价值重估
说实话,我以前觉得软件工程快过时了。本硕都是这个专业,看着 AI coding 的势头,一度以为那些模块化、命名规范、契约式接口都是老黄历。
实践打脸了。
**所有最佳实践,最终都回归到了软件工程的传统框架里。** 区别只是约束对象从人变成了 AI。
模块化、领域建模、测试驱动开发,这些东西过去可能由专人负责。现在?你必须全会。因为你手下的每一个 agent 都是你的数字员工,你就是 team leader。
还有一件事让我感触很深:**写代码这个技能在贬值,判断代码写得对不对这个技能在升值。**
未来衡量工程师值多少钱,不是看你写代码有多快,而是你能不能稳定判断 AI 写出来的东西到底能不能上线。
技能通胀,品味通缩——写代码的能力在泛滥贬值,判断代码的能力却在稀缺升值。
—
## 三、氛围编程的甜蜜陷阱
“氛围编程”最近很火。但那句“前三个小时爽,第五天崩溃”不是段子——是我亲眼见过的真实事故。
问题出在哪?**你太容易被 AI 的编写速度带偏。** 它写代码快,做下一步设计也快,demo 跑起来的效率非常高,你跟着它越来越嗨。但你没发现的是,它在埋下越来越多的问题,逐渐把你引向更偏的方向。
多巴胺分泌太频繁了,你控制不住。等到发觉的时候,**为时已晚。**
从“氛围编程”到“工程纪律”,是必经之路。
—
## 四、从“能跑”到“能信”,差了一整套验证体系
很多人觉得 AI 写代码不靠谱,不敢用在核心场景。
但真相恰恰相反:**金融核心场景(计费、风控、出账)反而是 AI 最能发挥价值的地方。**
因为这些场景有三个特征:输入输出确定性高,验收标准可以形式化,规则密度大。一行测试用例跑出来,比人脑花 30 分钟凭直觉“感觉”代码对不对,靠谱得多。
矛盾的是:最容易被 AI 解决的东西,恰恰是目前最不敢碰的东西。
不是模型能力不行,是我们没有给它一套能让自己信得过的验证机制。
那验证机制怎么搭?三层缺一不可:
**第一层:硬约束(AI 动手之前)。** 写一份结构化的规则文件,告诉 AI 什么必须做、什么绝对不能做。这是 ROI 最高的一步。三到五天就能感受到效果。
**第二层:知识注入(上下文层)。** 让 AI 知道架构长什么样、接口规则是什么、目录结构如何。不用猜,不用编。
**第三层:事后约束(验证门禁)。** AI 执行完后自动触发质量校验,自动拦截不合规提交。注意,假绿灯比红灯危险一万倍。空脚本默认全部通过,等于体检仪器根本没接上。
一个 300 人工程团队的实践数据:前端人效提升 3 倍,后端提升 2 倍,千行代码缺陷率下降 55%。
产出效率 3 倍的同时缺陷率降了一半。传统认知里写得越快 bug 越多,两者本应正相关。把验证机制装进生产线本身,是破解这一矛盾的关键所在。
—
## 五、战略归人,战术归 AI
人和 AI 怎么分工?一句话总结:
**战略层的事,人干。战术层的事,AI 干。**
领域建模、模块边界定义、API 契约设计、技术选型、安全合规,这些是战略。错了就是系统级风险,通用模型不知道你们公司的特点,必须人来把关。
样板代码、代码迁移、脚本编写、单元测试、文档生成,这些是战术。AI 做得又快又好。
**战略承载的是“为什么这样做”的因果链。颠倒这两层,事故就来了。**
还有一件事特别重要:最值钱的工程经验,不应该散落在每个人的聊天记录里。
同一类任务做了两三次,就该总结成可复用的技能文档。多个工程师有类似经验,就沉淀为团队级资产。否则老手离职那天,这些能力也跟着走了。
—
## 六、DDD + TDD,AI 时代的护城河
这两样东西在 vibe coding 语境下的价值,比我预想中大得多。
DDD 解决的是**业务复杂度**。通过通用语言、限界上下文、聚合根,把混乱的领域知识映射成可维护的代码骨架。
TDD 解决的是**代码正确性**。通过红绿重构循环,确保骨架里的每一块肌肉收缩到位。
DDD 告诉我们什么样的模型是合理的,TDD 告诉我们这个模型的行为到底对不对。两者非但不冲突,反而互为约束。
如果自己没有领域模型的主心骨,AI 产出的就是一大坨看起来像模像样、实际上边界模糊、到处漏业务逻辑的代码。没有 TDD 兜底,你甚至不敢重构这段代码,因为不知道改了以后会不会挂。
**DDD 给 AI 划出领地范围,TDD 给 AI 的产出盖上检验合格的章。**
—
## 七、几个血泪教训
在实践这套方法论的过程中,我们还踩了不少具体的坑。以下是几个最疼的。
**上下文窗口用到 30%-40% 时,模型智商就急剧下降。** 规则塞得太多,AI 可能只读了前两条就动手了。所以强约束永远放在文件里,不要靠聊天上下文。
**“尽量不使用 double”这种模糊语言,等于在给 AI 预留自由发挥的空间。** AI 看到“尽量”,大部分时候当没看到。必须用 must / must not,没有商量余地。
**AI 会悄悄漂移。** 一开始它遵循了你定的规则,你觉得很安心。后来某天你发现它不知什么时候已经把代码写到了不该写的地方,你自己都没发现。持续的验证门禁不是可选项,是必选项。
**不要迷信代码采纳率。** 去年某头部云厂商给客户的代码采纳率数据是 40% 左右。今年内部已经没人在看这个指标了。资深工程师无脑 accept 就能接近 100%。真正该关注的是:代码能不能经得起验证,能不能放心上线。
**7×24 无人值守写代码?** 你睡觉的时候代码仓库多了十万行代码,早上起来就傻眼了。功能也许能跑通,但你真想把它们合并到生产分支吗?面对这十万行代码,大部分人无从下手。
—
## 八、入门路径:躺着进去,站着出来
如果你刚开始用 AI 编程,别一上来就动核心业务代码。
先做前端 UI,难度最低,跟模型交互最直观。再开发内部工具,非对客的提效工具,不需要那么严格。然后尝试非核心业务代码。最后才动核心交易和账务逻辑。
**先用 AI 做一些非对客但内部提效明显的工具,一两周内就能看到显著效果,逐步掌握核心方法。**
实操优先级按 ROI 排序:
第一,写一份结构化的规则文件。这是见效最快的入口。
第二,补齐架构说明和代码能力地图,让 AI 知道边界在哪。
第三,配置自动验证脚本,拦截不合规提交。
第四,把个人经验沉淀为可复用的技能文档。这是长期价值最高的事。
—
## 写在最后
我们正处在爆发点的前期。
AI 是杠杆而非引擎,真正的爆发需要工程化手段的成熟。关键瓶颈不是模型能力,而是验证机制能不能让人放心。
不管各种新概念怎么变,核心就一条:**结果必须可验证。**
生产级软件不是 Demo。不能一句话扔给大模型就指望它产出一个可用的系统。真正可信赖的交付,需要从业务目标出发,经过架构设计、边界定义、模块拆分、接口定稿,一步步用工程化的方法把 AI 的行动范围框死。
没有验证机制的 AI 代码就是一个黑盒——你不知道它为什么对,也不知道它什么时候会错。如果 AI 写的代码最终只有 AI 能改,那软件行业将从工程退化为黑盒迷信。知识断层不可逆,调试变成猜谜,技术债复利爆炸,人的判断力萎缩。
**让人始终保有验证和修改的能力,这是我们防止软件退化成黑盒的最后一道防线。**