 夜雨聆风
夜雨聆风





高度近视早筛新招:血检+免费在线测算工具
高度近视并发症早筛新招:血检+免费在线测算工具
近期,由复旦大学等多家机构合作完成的论文“Routine blood tests and machine learning identify complications in high myopia”在《Nature Communications》上发表。该研究首次构建了基于常规血常规检测与机器学习的高度近视并发症筛查模型,突破了传统影像学筛查在设备与人力上的限制,为高度近视并发症的规模化、低成本早期筛查提供了全新方案,并有望在基层医疗和社区场景中便捷落地。下面,让我们一起了解下这项研究。
往期有一篇关于免费预测近视早期发病风险的内容,可点击查看近视发生风险,一测便知——儿童近视早期预警计算器!。

一
背景与研究意义

(一)高度近视并发症的危害
高度近视(≤-6.0屈光度)并非单纯屈光不正,会显著增加白内障、青光眼、视网膜脱离、脉络膜新生血管、黄斑变性5类致盲性并发症风险,其中近视性黄斑变性是工作人群不可逆失明的首要原因,且超40%的近视性黄斑病变早期无症状,亟需高效早筛手段。
(二)传统筛查的局限性
现有筛查依赖光学相干断层扫描(OCT)、眼底自发荧光等专业影像学技术,存在三大问题:中低收入国家78%缺乏基础OCT设备;临床医生对影像结果的解读差异可达22%;检查耗时耗力,无法实现人群级筛查。
(三)血液检测的潜在价值
近年研究发现,血常规、代谢、炎症指标与眼部病理变化存在密切关联(如淋巴细胞/嗜碱性粒细胞与视网膜脱离相关、IL-6与青光眼相关、糖化血红蛋白与黄斑病变进展相关),且血液检测具备基层普及率近 100%、成本低(约300元/人,低于眼底成像400-600 元/人)、可同步反映全身健康的优势。同时,健康体检中的常规血液检测已覆盖相关指标,可实现无额外成本的机会性筛查,成为解决高度近视人群早筛难题的潜在方向。

二
研究设计与研究对象

研究采用“模型构建 – 院内验证 – 社区落地”” 的三阶段设计,覆盖回顾性病例对照、医院前瞻性、社区横断面三大场景,总研究样本337,982人,其中高度近视相关样本13,633人,是目前该领域样本量最大、验证最全面的研究,研究对象均为中国人群,严格遵循赫尔辛基宣言,经各参与机构伦理委员会批准。
(一)第一阶段:多中心回顾性病例对照研究(模型构建与外部验证)
1、研究时间与对象
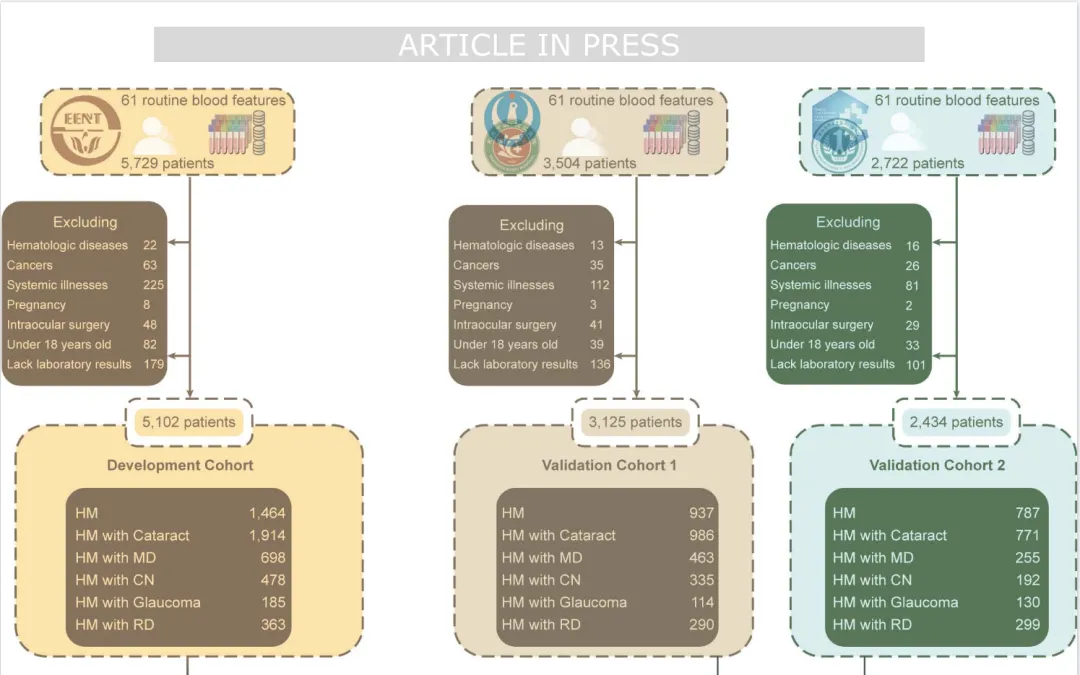
2016年1月-2024年12月,纳入中国5家三级医院10,661名高度近视患者,排除血液疾病、癌症、急性感染、自身免疫病、妊娠、近6个月内眼内手术、18 岁以下及实验室数据缺失者。
2、队列划分
①发现队列(是机器学习模型构建阶段的核心研究人群,也是整个研究中用于筛选关键特征、开发和初步优化模型的基础队列):复旦大学眼耳鼻喉科医院5,102人(含无并发症高度近视1,464人,合并5类并发症患者3,638 人)。
②外部验证队列1:复旦大学徐汇中心医院、普陀人民医院3,125人。
③外部验证队列2:皖北煤电集团总医院、安徽医科大学第一附属医院2,434人。
3、核心目的:筛选血液指标、构建机器学习模型并完成跨机构外部验证。
(二)第二阶段:医院前瞻性队列研究(临床实用性验证)
1、研究时间与对象:2025年1月-5月,纳入复旦大学眼耳鼻喉科医院、徐汇中心医院5,067名初诊高度近视患者,4,572人符合入组标准。
2、核心目的:在临床真实场景中实时用模型筛查,结合眼科金标准检查验证模型的阳性预测值、假阳性率及对眼科资源分配的优化作用。
(三)第三阶段:社区横断面研究(人群级筛查可行性验证)
1、研究时间与对象:2024年7月,在上海徐汇区长桥、漕河泾2个社区卫生服务中心开展,纳入311,254名社区成人,筛选出1,905名高度近视患者,1,894人符合入组标准。
2、核心目的:验证模型在基层社区、大规模人群中的筛查效果,评估其对社区眼科转诊阳性率的提升作用。
三
研究方法:从血液指标筛选到
模型临床转化的全流程设计

(一)血液指标采集与质量控制
1、指标范围:提取61项常规临床血液检测指标,分为三大类 —— 血细胞分析24项、生化分析31项、凝血分析6项,均为基层医院可常规检测的指标。
2、样本采集:新诊断高度近视或并发症患者在就诊24小时内采集静脉血,排除稳定期/随访期检测数据,确保指标反映疾病初始状态。
3、质量控制:所有参与中心均完成室间质量评价,室内质量控制每日进行,变异系数(CV)控制在5%以内,保证不同中心数据的一致性和可靠性。
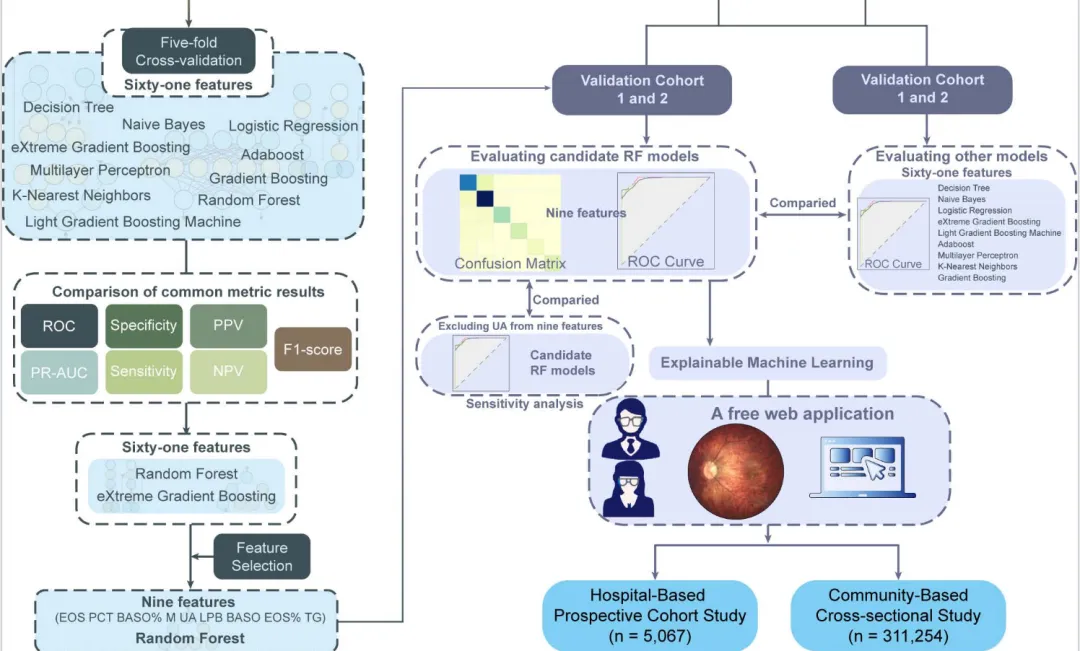
(二)、机器学习模型构建与算法筛选
1、数据预处理:缺失值≤20%的样本用中位数插补,缺失值>20%的样本剔除;采用SMOTE合成少数类过采样技术解决并发症样本分布不均的问题,避免模型偏倚。
2、模型构建与算法选择:对比随机森林(RF)、XGBoost、逻辑回归等10种机器学习算法,采用 SMOTE 法解决数据类别不平衡问题,通过五折交叉验证优化超参数。结果显示随机森林(RF) 性能最优,且9特征RF模型与61全特征模型性能无显著差异,兼顾预测精度与临床实用性。
3、模型验证与评估:从AUC(受试者工作特征曲线下面积)、灵敏度、特异度、阳性预测值(PPV)、阴性预测值(NPV)等多维度评估,结合决策曲线分析(DCA)、校准曲线验证模型临床价值,并开展亚组分析(排除糖尿病/高血压等干扰因素)验证模型稳健性。
4、临床转化:开发免费在线网页工具(https://high-myopia.streamlit.app/),输入9项血液指标即可实时输出高度近视及5类并发症的风险概率,实现临床快速应用,点击链接进去如下图所示。

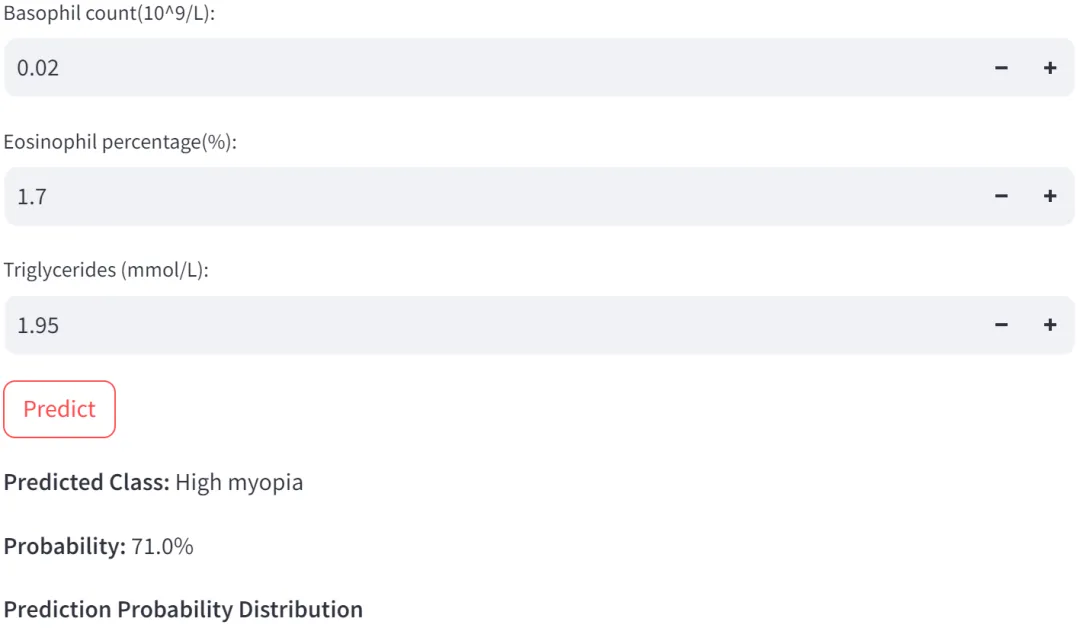
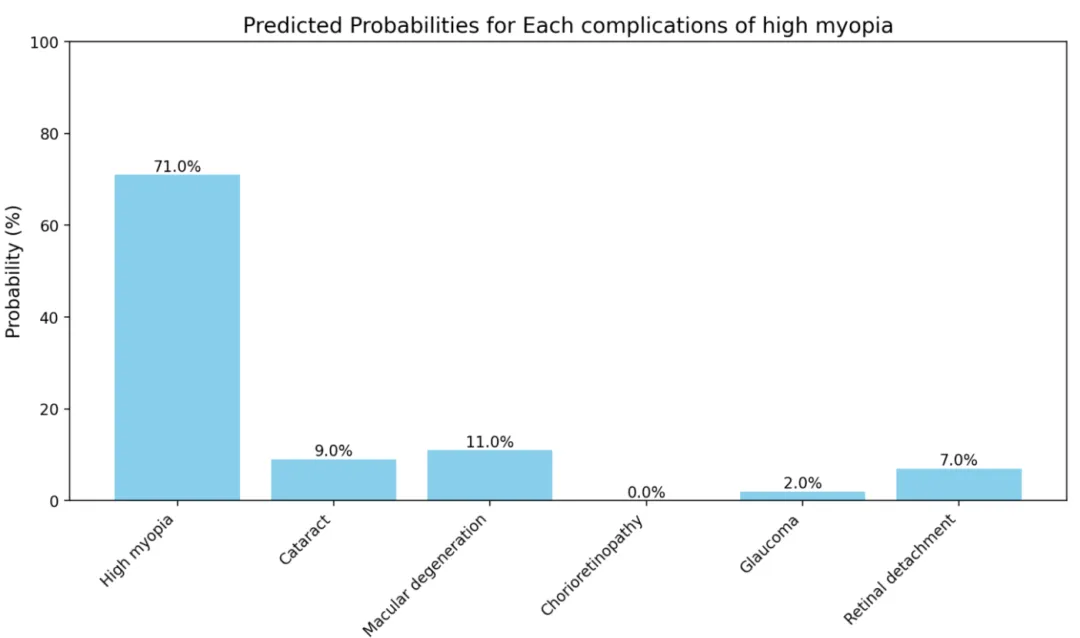
包括以下9项指标:
1、嗜酸性粒细胞计数:Eosinophil count(EOS)——血细胞分析
2、血小板压积:Plateletcrit(PCT)—— 血细胞分析
3、嗜碱性粒细胞百分比:Basophil percentage(BASO%)—— 血细胞分析
4、单核细胞计数:Monocyte count(M)—— 血细胞分析
5、尿酸:Uric Acid(UA)—— 生化分析
6、载脂蛋白 B:Lipoprotein B(LPB)—— 生化分析
7、嗜碱性粒细胞计数:Basophil count(BASO)—— 血细胞分析
8、嗜酸性粒细胞百分比:Eosinophil percentage(EOS%)—— 血细胞分析
9、甘油三酯:Triglycerides(TG)—— 生化分析

四
关键研究结果

该9特征随机森林模型在多场景下均表现出高准确性、高稳健性,核心性能指标如下:
(一)多中心回顾性验证:模型准确性高,跨机构适用性好
1、发现队列:宏平均AUC达0.9649(95%CI:0.9528-0.9770),PR-AUC达0.8812;对高度近视总体及5类并发症的AUC均>0.94,其中白内障AUC最高达0.9790。
2、外部验证队列:验证队列1宏平均AUC为0.9020,验证队列2宏平均为0.9010,虽略低于发现队列,但仍保持高准确性,说明模型跨机构推广性良好。
3、稳健性:亚组分析(排除糖尿病/高血压等干扰因素)后,发现队列宏平均 AUC 0.9560,验证队列 1 0.9010,验证队列 2 0.9008,与全人群无显著差异;剔除 UA 后,验证队列 1、2 宏平均 AUC仍达0.8589、0.8613,满足临床筛查需求。
(二)医院前瞻性验证
5067名患者中,模型筛查高风险人群的PPV达86%、NPV达94%,平均灵敏度70%、特异度94%,白内障外的其他并发症假阳性率均低于0.6%,大幅减少不必要的眼科转诊。
(三)社区大规模筛查
31 万社区成人中,模型筛选出的高度近视高风险人群经眼科确诊后,总体PPV达 74%,其中黄斑变性PPV最高(79.5%),青光眼、视网膜脱离均为 75%,显著提升社区眼科转诊的阳性检出率。
(四)核心指标的生物学合理性:与并发症病理机制高度契合
研究证实,9项核心指标并非单纯的统计学指标,其变化与高度近视并发症的发病机制直接相关,验证了模型的生物学基础,而非单纯的数据分析结果:
1、嗜酸性/嗜碱性粒细胞(EOS、BASO、EOS%、BASO%):与眼部局部炎症相关,IL-4/IL-13介导的嗜酸性/嗜碱性粒细胞活化会增加血管渗漏,促进视网膜脱离、脉络膜新生血管的发生。
2、血小板压积(PCT):与血栓形成相关,血小板异常活化会加重眼部微循环障碍,增加青光眼、视网膜脱离风险。
3、尿酸(UA):作为体内重要的抗氧化剂,可中和眼部氧化应激,对黄斑变性起保护性作用。
4、甘油三酯(TG)、载脂蛋白B(LPB):与脂质代谢相关,血脂异常会导致Bruch膜脂质沉积,引发视网膜色素上皮功能障碍,促进黄斑变性进展。
5、单核细胞(M):作为炎症细胞,参与眼部慢性炎症反应,加重高度近视的眼底病理性改变。
五
研究的创新点和局限性

(一)创新点
1、技术创新:首次将常规血常规与机器学习结合,实现高度近视5类并发症的一站式筛查,突破了传统影像学筛查的设备和人力壁垒。
2、临床转化创新:模型仅需9项常规血液指标,基层医院均可检测,且开发了免费在线工具,无需专业算法知识即可操作,实现零成本落地。
3、成本与效率创新:依托健康体检的常规血液检测,无需额外采血,实现机会性筛查;血液检测成本远低于影像学检查,且能同步反映全身健康,具备 “一举两得” 的临床价值。
4、场景创新:覆盖医院、社区、基层医疗三大场景,验证了模型在不同医疗资源条件下的适用性,尤其适合医疗资源匮乏的地区。
(二)局限性
1、人群局限性:研究对象均为亚洲人群,暂未在非洲、欧洲、拉美等人群中验证,血液指标和并发症患病率的种族差异可能影响模型泛化性。
2、设计局限性:社区研究为横断面设计,无法验证血液指标与并发症的因果关系和时间关联性;且仅对模型高风险人群进行眼科确诊,低风险人群未系统检查,可能存在验证偏倚。
3、性能局限性:模型对黄斑变性、脉络膜新生血管、视网膜脱离的灵敏度低于0.6,存在一定漏诊风险;白内障假阳性率达14.22%,大规模应用可能增加基层眼科负担。
4、其他局限性:未开展正式的卫生经济学分析,无法量化模型的临床经济效益;未整合多组学数据,仍有提升预测精度的空间;未明确模型对并发症早期 / 晚期的检出偏好,对干预时机的指导有限。
六
研究结论与未来展望

(一)核心结论
基于9项常规血液指标的随机森林模型可实现高度近视及5类并发症的高效、低成本筛查,在健康体检、社区、基层医疗场景中可作为一线初筛工具,筛选出高风险人群后再进行眼科影像学确诊,能大幅提升筛查效率、合理分配眼科资源,尤其适合医疗资源匮乏地区。
(二)未来方向
1、开展跨种族、跨地区的外部验证,优化模型以提升泛化性。
2、结合智能手机眼底成像技术,构建“血液初筛+影像确诊” 的两级筛查体系;
3、开展机制研究,探索通过调节核心血液指标(如降甘油三酯)降低高度近视并发症风险的治疗新途径;优化模型阈值,降低白内障假阳性率,提升黄斑变性等疾病的灵敏度。
4、开展卫生经济学研究,量化模型对医疗成本的节约效应。
该研究为高度近视并发症的防控提供了全新的血液学筛查范式,将眼科筛查从 “专科化” 推向 “大众化”,对全球尤其是发展中国家的防盲治盲工作具有重要的临床价值和公共卫生意义。

参考文献:
[1] Li S, Ren J, Wang F, et al. Routine blood tests and machine learning identify complications in high myopia. Nat Commun. 2026 Mar 14.


记得点赞加关注哦
