 夜雨聆风
夜雨聆风





RAG入门:让AI读懂你的文档
这是我的AI学习日记第9篇。上一篇搭建了AI助手,这篇来点更高级的——让AI读懂你的私有文档。
先说结论
-
公司有一堆技术文档,想问AI相关问题,但AI不知道这些内容 -
项目有大量业务文档,想让AI帮忙分析,但AI不了解你的业务 -
自己积累了很多学习笔记,想让AI帮你整理,但AI没读过这些
RAG可以解决这个问题。
普通AI:只能回答训练时学过的内容RAG AI:可以回答你的私有文档里的内容
什么是RAG
通俗解释
普通AI考试:- 题目:请回答问题- AI:凭记忆回答(可能答不上来)RAG AI考试:- 题目:请回答问题- AI:先查阅相关资料 → 找到答案 → 回答问题
技术原理
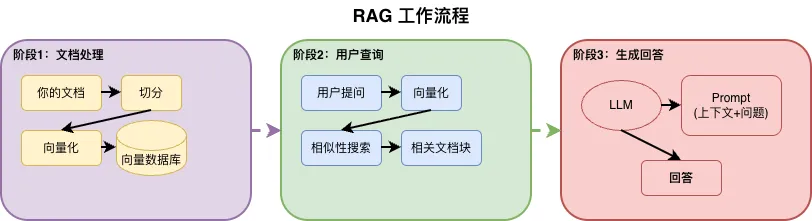
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
为什么需要RAG
场景1:企业知识库
-
技术规范文档 -
业务流程说明 -
历史项目文档 -
FAQ知识库
场景2:代码库分析
-
需求文档 -
设计文档 -
API文档 -
代码注释
场景3:个人学习助手
-
技术文章收藏 -
学习笔记 -
电子书
RAG技术栈
主流方案
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
我的入门选择
LangChain + Chroma + BGE + DeepSeek-
LangChain:文档全,示例多 -
Chroma:本地运行,零配置 -
BGE:国产开源,中文效果好 -
DeepSeek:便宜,API调用简单
第一步:环境准备
安装依赖
pip install langchain langchain-community chromadb sentence-transformers依赖说明
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Python版本
第二步:准备文档
创建示例文档
# 创建示例文档目录import osos.makedirs("docs", exist_ok=True)# 创建几个示例文档docs = {"tech_spec.md": """# 用户登录技术规范## 接口设计### 请求方式POST /api/v1/auth/login### 请求参数- username: 用户名,必填- password: 密码,必填- captcha: 验证码,可选### 返回格式{"code": 0,"message": "success","data": {"token": "xxx","expireTime": 3600}}## 安全要求1. 密码必须使用BCrypt加密存储2. 登录失败5次后锁定账号30分钟3. Token有效期不超过24小时""","business_rule.md": """# 转账业务规则## 基本规则1. 单笔转账限额:50,000元2. 单日累计限额:200,000元3. 转账时间:00:00 - 23:59## 手续费规则| 金额范围 | 手续费 ||----------|--------|| 0 - 1000 | 免费 || 1000 - 10000 | 2元 || 10000以上 | 5元 |## 风控规则1. 大额转账(>10万)需要短信验证2. 新设备首次转账需要人脸识别3. 异常时间段(00:00-06:00)转账需要额外验证""","faq.md": """# 常见问题FAQ## Q1: 忘记密码怎么办?A: 点击登录页面的"忘记密码",通过手机验证码重置密码。## Q2: 为什么转账失败?A: 可能原因:1. 余额不足2. 超过转账限额3. 收款账户异常4. 网络问题## Q3: 如何修改手机号?A: 进入"我的" → "设置" → "账户安全" → "修改手机号",需验证原手机号和新手机号。## Q4: Token过期怎么办?A: Token过期后需要重新登录。建议在Token过期前调用刷新接口。"""}for filename, content in docs.items():with open(f"docs/{filename}", "w", encoding="utf-8") as f:f.write(content)print("✅ 示例文档创建完成")
第三步:构建向量数据库
加载文档
from langchain_community.document_loaders import DirectoryLoader, TextLoader# 加载文档目录loader = DirectoryLoader("./docs",glob="**/*.md",loader_cls=TextLoader,loader_kwargs={"encoding": "utf-8"})documents = loader.load()print(f"✅ 加载了 {len(documents)} 个文档")
切分文档
from langchain.text_splitter import RecursiveCharacterTextSplitter# 创建切分器text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, # 每块最大500字符chunk_overlap=100, # 块之间重叠100字符separators=["\n\n", "\n", "。", "!", "?", ";", ",", " ", ""])# 切分文档chunks = text_splitter.split_documents(documents)print(f"✅ 切分成 {len(chunks)} 个文本块")
创建向量数据库
from langchain_community.embeddings import HuggingFaceEmbeddingsfrom langchain_community.vectorstores import Chroma# 创建Embedding模型(使用BGE中文模型)embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5",model_kwargs={"device": "cpu"},encode_kwargs={"normalize_embeddings": True})# 创建向量数据库vectorstore = Chroma.from_documents(documents=chunks,embedding=embeddings,persist_directory="./chroma_db")# 持久化存储vectorstore.persist()print("✅ 向量数据库创建完成")
第四步:问答测试
简单问答
# 创建检索器retriever = vectorstore.as_retriever(search_kwargs={"k": 3} # 返回最相关的3个文本块)# 检索测试query = "转账手续费是多少?"docs = retriever.invoke(query)print(f"问题:{query}\n")print("相关文档:")for i, doc in enumerate(docs, 1):print(f"\n--- 文档块 {i} ---")print(doc.page_content[:200] + "...")
结合AI回答
from openai import OpenAIimport os# 初始化DeepSeek客户端client = OpenAI(api_key=os.getenv("DEEPSEEK_API_KEY"),base_url="https://api.deepseek.com")def rag_chat(query: str) -> str:"""RAG问答"""# 1. 检索相关文档docs = retriever.invoke(query)context = "\n\n".join([doc.page_content for doc in docs])# 2. 构建Promptprompt = f"""请根据以下参考资料回答问题。如果资料中没有相关信息,请说"根据现有资料无法回答"。参考资料:{context}问题:{query}请回答:"""# 3. 调用AIresponse = client.chat.completions.create(model="deepseek-chat",messages=[{"role": "user", "content": prompt}])return response.choices[0].message.content# 测试questions = ["用户登录的接口是什么?","转账超过10万需要什么验证?","忘记密码怎么办?","Token有效期是多长?"]for q in questions:print(f"\n问:{q}")print(f"答:{rag_chat(q)}")
运行效果
问:用户登录的接口是什么?答:根据技术规范,用户登录接口是:- 请求方式:POST /api/v1/auth/login- 请求参数:username(用户名)、password(密码)、captcha(验证码,可选)问:转账超过10万需要什么验证?答:根据转账业务规则,大额转账(>10万)需要短信验证。问:忘记密码怎么办?答:根据FAQ,可以通过以下方式重置密码:点击登录页面的"忘记密码",通过手机验证码重置密码。问:Token有效期是多长?答:根据技术规范,Token有效期不超过24小时。
第五步:封装成工具
# rag_assistant.pyimport osfrom typing import List, Optionalfrom openai import OpenAIfrom langchain_community.document_loaders import DirectoryLoader, TextLoaderfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_community.embeddings import HuggingFaceEmbeddingsfrom langchain_community.vectorstores import Chromaclass RAGAssistant:"""RAG问答助手"""def __init__(self,docs_dir: str = "./docs",db_dir: str = "./chroma_db",api_key: Optional[str] = None):self.docs_dir = docs_dirself.db_dir = db_dirself.api_key = api_key or os.getenv("DEEPSEEK_API_KEY")# 初始化组件self.embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5",model_kwargs={"device": "cpu"},encode_kwargs={"normalize_embeddings": True})self.client = OpenAI(api_key=self.api_key,base_url="https://api.deepseek.com")self.vectorstore = Noneself.retriever = Nonedef build_index(self):"""构建向量索引"""print("正在加载文档...")loader = DirectoryLoader(self.docs_dir,glob="**/*.md",loader_cls=TextLoader,loader_kwargs={"encoding": "utf-8"})documents = loader.load()print(f" 加载了 {len(documents)} 个文档")print("正在切分文档...")text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=100,separators=["\n\n", "\n", "。", "!", "?", ";", ",", " ", ""])chunks = text_splitter.split_documents(documents)print(f" 切分成 {len(chunks)} 个文本块")print("正在构建向量数据库...")self.vectorstore = Chroma.from_documents(documents=chunks,embedding=self.embeddings,persist_directory=self.db_dir)self.vectorstore.persist()self.retriever = self.vectorstore.as_retriever(search_kwargs={"k": 3})print("✅ 索引构建完成")def load_index(self):"""加载已有索引"""self.vectorstore = Chroma(persist_directory=self.db_dir,embedding_function=self.embeddings)self.retriever = self.vectorstore.as_retriever(search_kwargs={"k": 3})print("✅ 索引加载完成")def chat(self, query: str, show_context: bool = False) -> str:"""问答"""if not self.retriever:raise ValueError("请先调用 build_index() 或 load_index()")# 检索docs = self.retriever.invoke(query)context = "\n\n".join([doc.page_content for doc in docs])if show_context:print(f"\n--- 检索到的相关内容 ---")for i, doc in enumerate(docs, 1):print(f"\n[文档块 {i}]")print(doc.page_content[:200] + "...")# 构建Promptprompt = f"""请根据以下参考资料回答问题。如果资料中没有相关信息,请说"根据现有资料无法回答"。参考资料:{context}问题:{query}请回答:"""# 调用AIresponse = self.client.chat.completions.create(model="deepseek-chat",messages=[{"role": "user", "content": prompt}])return response.choices[0].message.content# 使用示例if __name__ == "__main__":# 创建助手assistant = RAGAssistant()# 首次使用:构建索引# assistant.build_index()# 后续使用:加载已有索引assistant.load_index()# 问答while True:query = input("\n请输入问题(输入 quit 退出): ")if query.lower() == "quit":breakanswer = assistant.chat(query, show_context=True)print(f"\n回答:{answer}")
踩过的坑
坑1:Embedding模型下载慢
import osos.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
坑2:文档编码问题
loader = TextLoader(file_path, encoding="utf-8")坑3:切分粒度不合适
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, # 调整这个值chunk_overlap=100, # 调整这个值)
-
技术文档:chunk_size=500-1000 -
长篇文章:chunk_size=1000-2000 -
对话记录:chunk_size=300-500
坑4:检索不到相关内容
retriever = vectorstore.as_retriever(search_kwargs={"k": 5} # 增加返回数量)
# 相似度检索docs = vectorstore.similarity_search(query, k=3)# MMR检索(最大边际相关性,增加多样性)docs = vectorstore.max_marginal_relevance_search(query, k=3)
进阶方向
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
写在最后
如果你也在学AI,欢迎关注我,一起交流。
作者:Tony | 老程序员,正在学AI
本文是AI学习日记系列的第9篇
关注我,一起学习AI