 夜雨聆风
夜雨聆风





Claude官方确认源码泄露!它真正厉害的地方,不在某一段提示词,而在它背后那套完整的工程系统
-
源码可在公众号首页免费获取,仅供学习使用。
很多人研究 Claude Code,第一反应都是去看它的 prompt,或者看它接了哪些工具。
但如果你真的把它的源码拆开,会发现:这些都只是表层。
Claude Code 真正厉害的地方,不在某一段提示词,而在它背后那套完整的工程系统:怎么约束模型行为、怎么治理工具调用、怎么拆分 Agent 角色、怎么控制上下文成本、怎么处理运行时生命周期。
换句话说,Prompt 只是门面,工程才是底盘。
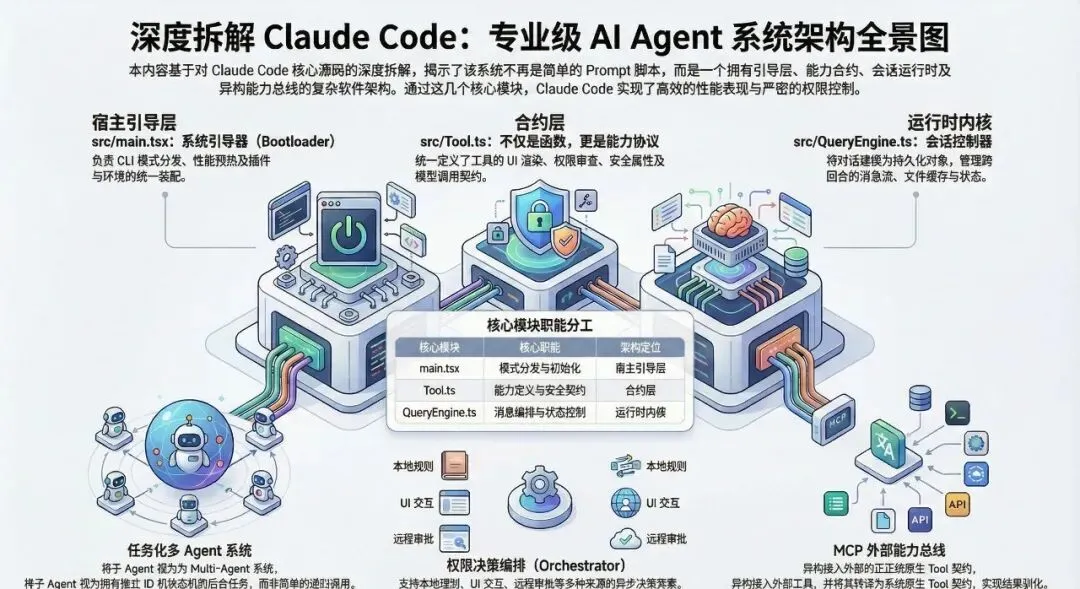
一、Claude Code 根本不像一个“CLI 工具”
这次泄露事件里,从 npm 包里的 cli.js.map 提取出了 4756 个源码文件,顺着入口、工具、提示词、权限、Hook、插件、Agent 调度一路看下去,得到一个很明确的判断:
ClaudeCode 不是一个“把大模型接进终端”的小工具,而更像一个完整的 Agent 运行平台。
从目录结构就能看出来,它不只有 CLI,还包括:
-
entrypoints -
tools -
services -
commands -
components -
coordinator -
hooks -
plugins -
tasks -
memdir
这意味着它解决的问题,已经不是“让模型调用几个命令”这么简单,而是在搭一个可扩展、可治理、可长期运行的系统。
二、它的 Prompt,不是一段话,而是一台组装机器
大多数人理解的 system prompt,是一段启动时塞进去的固定文本。
Claude Code 不是。
它的 system prompt 是动态拼装的。
一部分是稳定不变的内容,比如:
-
身份定位 -
系统规范 -
做任务的原则 -
风险动作规则 -
工具使用规范 -
语气和输出风格
另一部分则会根据当前会话动态变化,比如:
-
memory -
session guidance -
环境信息 -
语言设置 -
MCP instructions -
scratchpad -
token budget -
brief mode
这里最值得注意的一点是:它还专门设计了静态边界和动态边界。
为什么?因为静态部分更适合做缓存,动态部分放后面,不会破坏前面的 cache 命中。
这背后反映的不是 prompt 技巧,而是非常典型的产品化思维:
不是只关心“能不能跑”,而是关心“能不能长期、稳定、低成本地跑”。
三、Claude Code 的“稳”,来自制度,不来自模型自觉
很多 coding agent 都有一个共同问题:
你让它修一个 bug,它顺手给你重构半个项目;你让它加一个功能,它顺手补了很多你没要的抽象;你让它测一下,它嘴上说“通过了”,其实根本没跑。
Claude Code 对这些问题的处理方式很直接:
不要赌模型自觉,直接把规则写死。
比如它会明确要求模型:
-
不要擅自增加需求外功能 -
不要过度抽象 -
不要乱重构 -
不要瞎加注释和文档字符串 -
不要假装自己测试过 -
先读代码,再改代码 -
方法失败后先诊断原因,不要直接换方向
这类约束看起来不起眼,但它其实非常关键。
因为 AI Agent 最大的问题,从来不是“不会做”,而是“会做错方式”。
Claude Code 的强,不只是模型能力强,而是它把好行为变成了制度。
四、工具调用也不是“模型想调就调”
Claude Code 并不是模型一决定调用工具,系统就立刻执行。
真正的流程中间,还会经过很多层:
-
输入校验 -
schema 验证 -
风险预判 -
权限判断 -
PreToolUse Hook -
正式执行 -
tracing / analytics -
PostToolUse Hook -
失败后的补充处理
这套流程的意义很现实。
因为模型会传错参数,会误操作,会做高风险动作,也会在失败后丢失上下文。
如果没有这层治理,系统在 demo 里可能还凑合,但一到真实环境就会频繁翻车。
所以你会发现,Claude Code 对工具的理解不是“能不能调用”,而是:
调用之前怎么防错,调用过程中怎么控风险,调用之后怎么补上下文。
这就是工程成熟度。
五、它最值钱的一点,是把 Agent 角色拆开了
Claude Code 至少有几类内建 Agent:
-
Explore Agent -
Plan Agent -
Verification Agent -
General Purpose Agent
这里最关键的不是“多 Agent”本身,而是它们的职责划分非常明确。
比如 Explore 和 Plan 往往是只读的,只负责理解问题、梳理结构、产出计划;而 Verification Agent 的任务不是“看看差不多行不行”,而是:
尽量去找问题,尽量去搞坏它。
它会要求跑 build、跑测试、跑 linter、跑类型检查,甚至根据不同改动做专项验证。
这个设计特别重要,因为同一个 Agent 如果既负责实现,又负责给自己验收,它天然会倾向于觉得自己没问题。
而 Claude Code 的思路是:
实现的人和验收的人,最好不是同一个角色。
这其实不是 AI 时代的新发明,而是成熟软件工程里早就验证过的常识。
六、真正拉开差距的,是“上下文经济学”
Claude Code 还有一个很容易被忽略、但特别值钱的能力:
它把上下文当预算来花。
比如:
-
system prompt 分静态和动态边界,方便缓存 -
skill 按需注入,不是一开始全塞进去 -
MCP instructions 按连接状态动态加载 -
tool results 会做清理和摘要 -
fork 出来的子 Agent 会尽量复用主线程缓存前缀
这些设计看起来都不炫,但对产品非常重要。
因为一旦请求量上来,token 成本、上下文冗余、缓存命中率,都会直接影响体验和运营成本。
很多人做 Agent,只在意“这次能不能跑通”。
Claude Code 在意的是:
这套系统每天跑几万次,还能不能扛得住。
七、Claude Code 值得学的,不是某个技巧,而是一整套方法
把这些细节串起来看,你会发现 Claude Code 真正值得研究的,并不是某个 prompt 模板,也不是某个 Agent 花招。
它真正厉害的地方,是把下面这些东西连成了闭环:
-
行为规范 -
工具治理 -
权限控制 -
Agent 分工 -
上下文管理 -
生命周期管理
所以这篇源码研究最后给人的启发也很直接:
Prompt 当然重要,但真正拉开差距的,是工程。
如果你在做 AI Agent,这可能比研究一百个提示词技巧都更值得。
因为当系统走向真实生产环境后,真正决定体验上限的,往往不是“模型会不会回答”,而是:
它能不能稳定地做事,安全地做事,低成本地长期做事。
结语
拆完 4756 个源码文件之后,我们看到的 Claude Code,不再是一个“prompt 写得很厉害”的产品,而是一套高度工程化的 Agent 系统。
这也是它和很多同类产品真正拉开差距的地方。
一句话总结:Claude Code 的秘密,不在 prompt 里,而在它背后那套把行为制度、工具治理、Agent 分工、上下文经济学和生命周期管理串起来的工程系统。
来源参考
-
@tvytlx :ClaudeCode 你想知道的所有秘密,源码深度研究报告