 夜雨聆风
夜雨聆风





我做了一个APP自动化测试Skill,从此AI替你打工
大家好,我是洋子
在进入正题之前,先从软件交付模式变更的视角,说说为什么我们要给AI写Skill,如果只关心Skill怎么做的,可以直接滑到下面的内容
unsetunset软件交付模式的演进unsetunset
AI时代来临,软件的交付模式正在面临巨大转变
过去我们交付软件依赖 CI流水线基建:开发用git提交代码 → 触发CI流水线 → 编译打包 → 代码门禁(单测、SA等) → 测试门禁(提测准入任务,一般是跑自动化,校验准入Case是否签章等) → 部署测试环境 → QA测试 → 上线发布。
开发用git提交代码到代码仓库后,代码托管平台监听到有代码push,CI流水线就会自动触发一系列自动化任务
所有自动化任务都依赖CI流水线,一旦流水线某个job执行失败,如单测case执行失败,环境部署失败等,依赖人工处理,不需要人介入的部分,也是依赖人为设计的自动化脚本
此阶段AI的含量为0,主导者是人
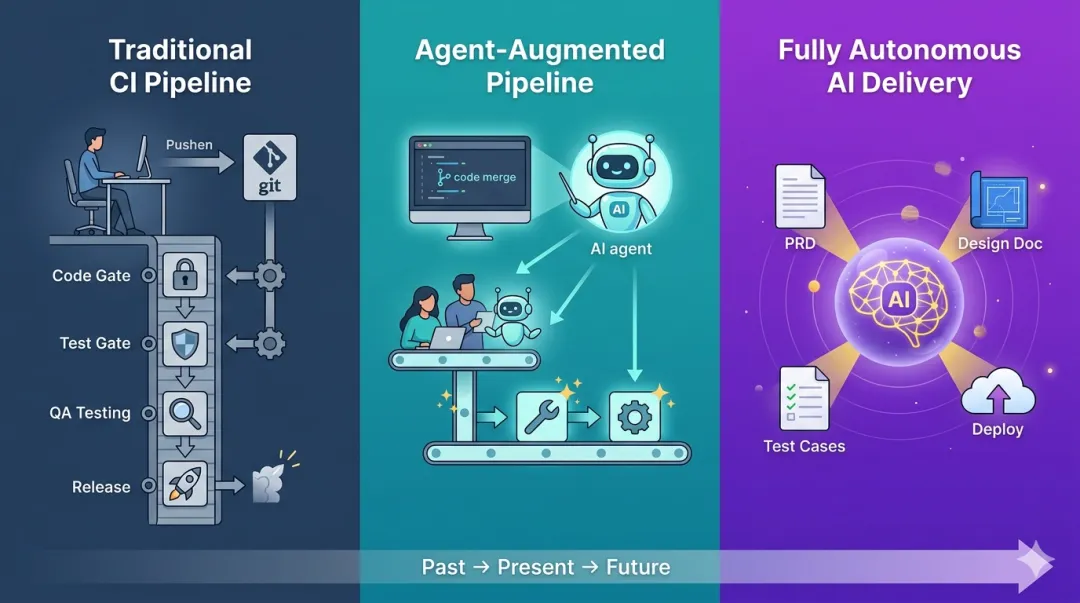
后来,各种AI Agent或AI测试平台横空出世,我们到了人机协作模式,你有没有发现,CI流水线这样的基建,正在被弱化使用,甚至被Agent代替
-
环境部署 → 部署Agent -
提测/提Bug → 交付助手Agent -
写测试用例 → 测试用例生成Agent -
构造测试数据 → 数据构造Agent -
上线 → 智能运维Agent -
……
完成工作任务通过与Agent采用自然语言对话(LUI)的形式进行,不再强依赖CI流水线,Agent 运行原理如下:
人定义意图 → 人编排 Workflow/ReAct 链路 → Agent 按规则执行
-
意图识别:靠 NLU 或 LLM 做分类,但分类体系、路由规则还是人设计的 -
Workflow 模式:人预先画好 DAG(有向无环图),Agent 按图执行,本质是”高级脚本” -
ReAct 模式:Agent 能自主推理下一步调什么工具,但工具集、边界、停止条件都是人定义的
此阶段虽有AI参与,主导者还是人,人来设计框架 + 定义边界,Agent来负责执行决策,AI的角色是受约束的自主体——能自主规划,但在人划定的围栏内
而现在,大模型的能力已经足够强大(如Claude Opus 4.6、GPT 5.4 等等), Claude Code、Codex、Gemini CLI 等AI工具已可以代替产品写PRD,UI做设计,开发写代码,QA做测试,运维做部署等等
此阶段人提供经验封装(Skill),AI负责自主编排,AI是主导执行者——人的经验以 Skill 形式”喂”给 AI,AI 决定何时、如何组合
所以我们写的Skill,本质就是”喂”给AI的经验,让AI获得某项技能。
想想最近很火的同事Skill,AI加载了这个Skill,就能化身成为同事的数字分身
unsetunset测试领域哪些Skill最有价值?unsetunset
我认为是自动化测试相关的Skill
既然是AI来主导,AI来代替人工测试是必须要解决的事情,这在以前,AI完全取代人工测试几乎是一件不可能的事情,但在AI时代,这一切正在发生
另外对于自动化测试,在AI时代,我认为UI自动化测试所带来的价值会高于接口自动化测试
为什么得出这个结论,除了一些互联网大厂还在区分服务端测试和客户端测试,现在越来越多的公司,一个QA要负责整个端到端的测试,并且客户端发现的Bug数量一般要远多于服务端的Bug,证明早在AI时代来临前,E2E测试重要性还是比服务端接口测试更高的
最近,接口自动化测试Skill 和 UI自动化测试Skill我都分别写了一套,两者在效果层面的对比如下:
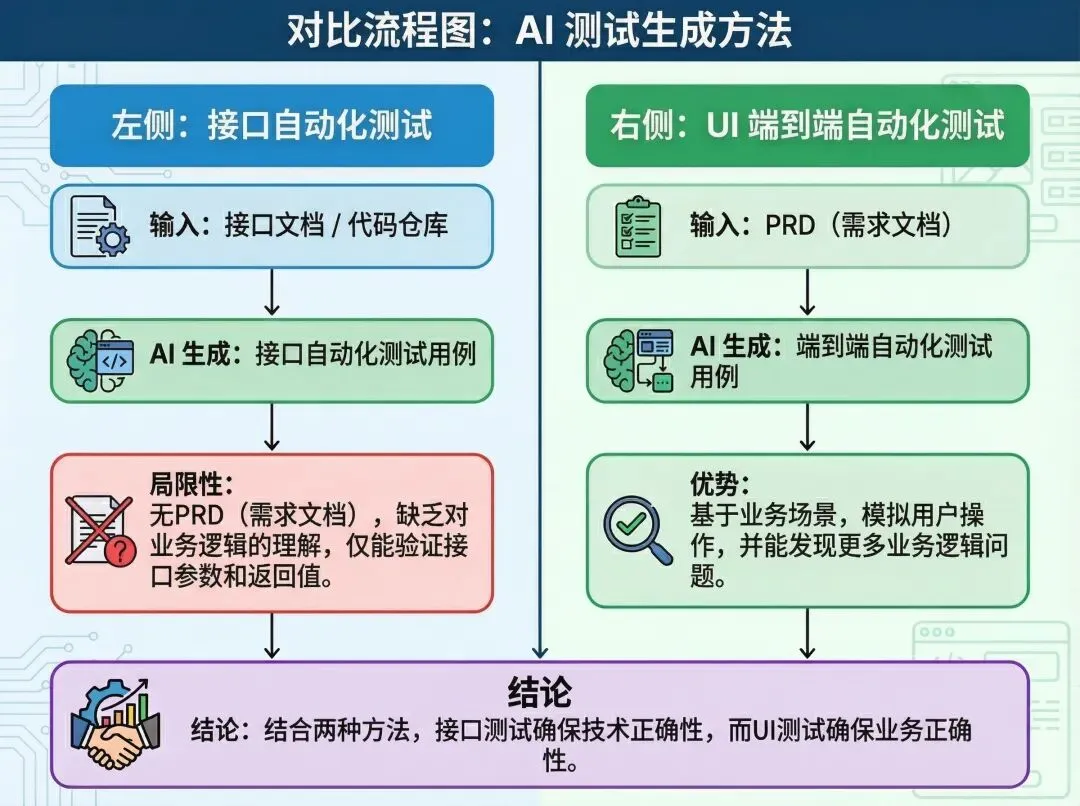
接口自动化测试Skill :很难发现业务逻辑Bug
通过读取接口文档或者读取代码库+Claude Rules规则(软件测试用例设计规范),能快速生成接口自动化测试用例,用Pytest框架管理用例,用Allure生成测试报告
运行AI生成的接口测试用例,我一看用例通过率100%,真的一点Bug都没有?但我点点点发现app明明有很多bug呀
分析了下为什么生成的接口测试用例无法发现业务问题,主要原因是AI不了解业务逻辑
AI生成接口自动化用例时,不能直接跟需求文档PRD关联,AI不知道PRD里的业务逻辑,仅仅通过接口文档,只能发现参数和返回值不符合预期,无法发现业务逻辑Bug
想想以前人工补充接口自动化测试用例,QA同学具备业务经验,都是了解接口参数如何进行关联,接口上下游都是什么,这样才能写出覆盖率更高的接口自动化用例
如果实在想通过AI生成的接口自动化测试能发现业务逻辑,我的想法是需要额外建设代码层面的知识图谱,加入白盒分析能力,获取接口调用链信息。图谱+接口文档作为上下文给到大模型,这样才能让LLM生成覆盖业务路径的测试用例,但构建知识图谱的成本本身就比较高
UI 自动化测试Skill:发现业务逻辑Bug的好帮手
UI 自动化可以从端到端的场景模拟用户的点击,所以天然就能发现和PRD实现不一致的业务逻辑
以往 UI 自动化往往因为业务快速迭代,导致元素定位不准确、稳定性较低,同时需要频繁人工维护用例,整体 ROI 偏低
AI 时代下情况有所变化
-
定位元素方面,对于 Web 开发或者Mac Electron的应用,可通过 CDP (Chrome DevTools Protocol),直接访问应用的 DOM 结构,提升元素定位能力。
-
对于安卓应用,也可以通过
uiautomator2拿到真实的DOM树结构 -
更关键的是,大模型具备一定的自修复能力,可以在执行失败时辅助分析原因并调整步骤,从而提高 UI 自动化可用性
unsetunset自动化测试Skill,我是怎么做的unsetunset
接口自动化Skill不再本文讨论范围内,后续会单独出其他文章谈,对于UI 自动化测试有两种,一种是Web 自动化,另一种是APP自动化
调研后发现,Web UI自动化测试选择方案很多,我之前也写过使用OpenClaw 零代码做Web UI 自动化测试,另外还有playwright-skill 以及browser_use这样的新框架(等我实操后再来分享效果)
而APP UI 自动化测试,由于APP内有各种各样业务逻辑,往往稳定性不高,但公司的产品一般都是有APP,APP 自动化测试也是需要解决的重点
目前还没有看到成熟APP 自动化测试AI Agent Skill方案,于是前段时间我自己实现了APP自动化测试 Skill
Skill 整体设计
对于Skill的整体设计,我拆分了两个Skill

-
第一个Skill是全量获取真实DOM树 -
第二个Skill是根据PRD生成APP自动化测试用例
这样设计的原因是,我仍然采用传统的元素定位方式DOM树+XPATH,先获取到每个页面的真实DOM树,这样生成出来的自动化测试用例才是真实可用的,另外不需要在每次生成自动化的时候都去执行全量DOM获取
如果不提供真实DOM树,大模型会自行推断,但自行推断生成出来的Case往往不可用,还得反复修改
为什么定位元素不用视觉定位框架?
我的核心使用诉求是AI来代替人工测试,不只是回归测试,冒烟和模块测试都交给AI,所以执行速度不能太慢
而字节Midscene.js靠纯视觉定位框架痛点问题就是执行速度慢,因为每次执行Case都要过大模型,另外纯自然语言描述Case看似灵活,实则难管理
如果自动化只是用来做例行回归,接受跑一晚上第2天来看结果,这种使用场景倒是比较适合用Midscene.js ,有使用过Midscene.js的同学可以评论区留言说下使用感受

unsetunsetUI 自动化测试 Skill 实操步骤unsetunset
先执行dump-ui Skill再执行prd-to-test Skill生成APP自动化测试用例
dump-ui skill: 获取真实DOM树
使用前置条件:
-
安卓真机连接PC,打开USB调试 -
提前安装好被测APP
加载skill方法:
-
把skill原文件放在 ~/.claude/commands/目录下,Claude Code会自动加载skill里面的dump-ui.md文件内容,skill原文件进测试开发学习圈获取
使用方法:
打开Claude Code VSCode插件引用文件作为上下文或者Claude Code命令行,输入/dump-ui 自己的需求
第一次使用需要输入应用包名,属于前置信息,比如获取应用包名等,知道包名后AI才能调用ADB打开应用,包名属于配置信息,AI自己会固化在生成的配置文件中

dump-ui Skill有两个功能说明:
-
全量页面自动探索,适用于第一次使用或者后续有新页面迭代的场景 -
仅扫描已有页面,只对已知的页面DOM做版本更新,这样速度会更快,也可以两者同时使用
在执行前CC会让你选择执行的模式,我这里安装第一种(扫描已有页面)并且跳过未登录页面

等待全量Dump任务完成,AI会自动帮你写一个全量dump脚本,自动执行脚本保存DOM树

全量Dump完毕后,会在data/ui-dumps文件夹里面存放该app的所有页面的dom信息
如果执行该Skill时,某个页面DOM已经存在,会创建带版本号(V2,V3,..)的xml文件,后续在使用生成用例Skill时,会选择使用最新版本的页面DOM
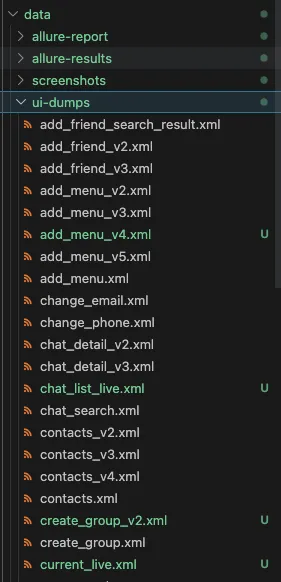
执行完毕后会有一个UI Dump 更新报告,提示哪些页面DOM进行了版本变更,部分页面可能存在获取DOM失败的情况,可以让Cluade 编写补救脚本或者给到页面的正确导航路径,重新获取,也可以选择先跳过
prd-to-test Skill :生成APP 自动化测试用例
先加载prd-to-test Skill,加载方式同上(skill原文件进测试开发学习圈获取)
在Claude Code命令行窗口,执行/prd-to-test 需求文档本地路径就可以开始生成APP自动化测试用例

如果PRD文档过大,Skill会让Claude Code按APP功能模块维度返回,让用户选择本次要生成case的模块,先跑通一个模块后,再去生成其他模块的case
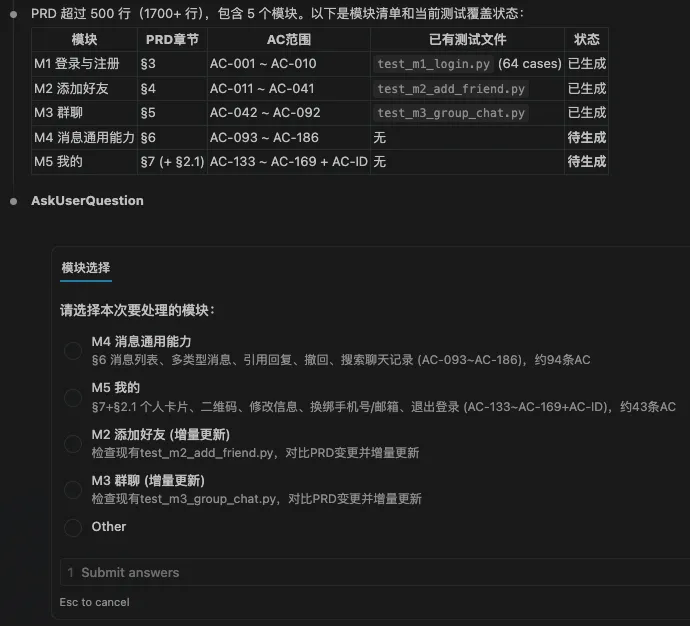
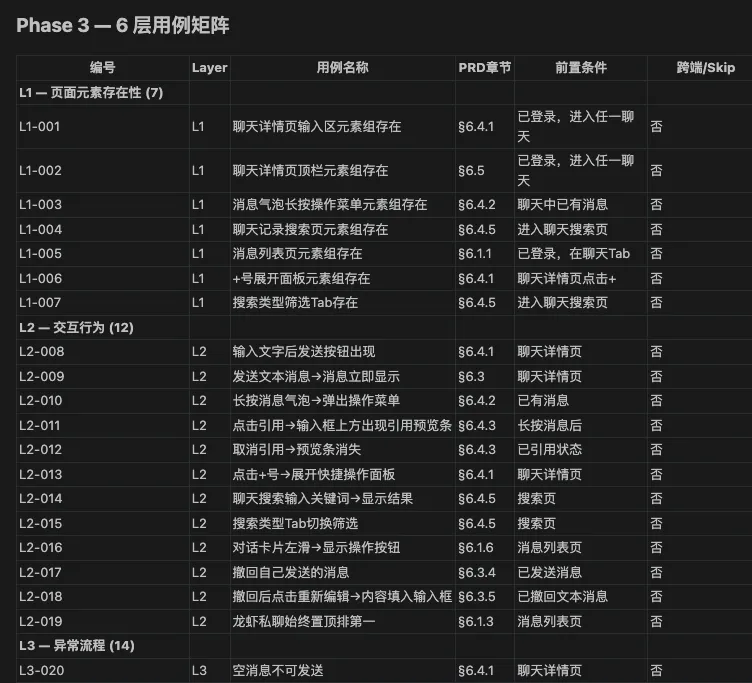
执行到用例设计环节,Skill里面描述了软件测试用例设计规范,按照6层纬度去生成测试用例
-
L1:页面元素存在性 :页面元素是否存在 -
L2:交互行为:当前页面有哪些用户交互行为 -
L3:异常流程:异常的操作流程 -
L4:验收标准:产品验收需要通过的Case -
L5:数据边界值:如输入框等有数据输入的情况(等价类,边界值等) -
L6:主流程(场景Case):场景化case,保证流程是通过
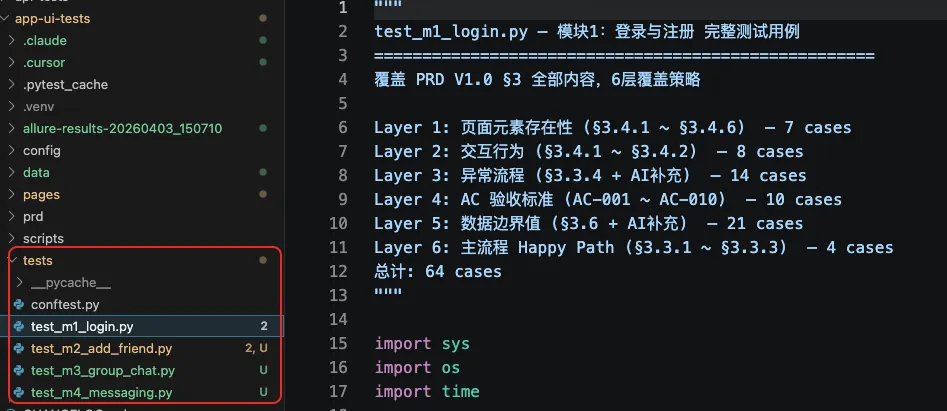
test_m4_messaging.py,生成完毕后Claude Code自动验证刚刚生成的Case,给出生成报告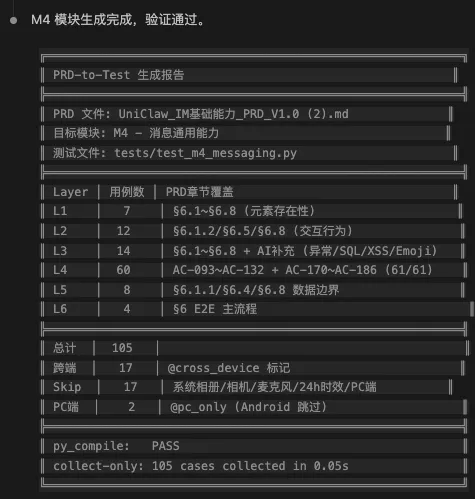
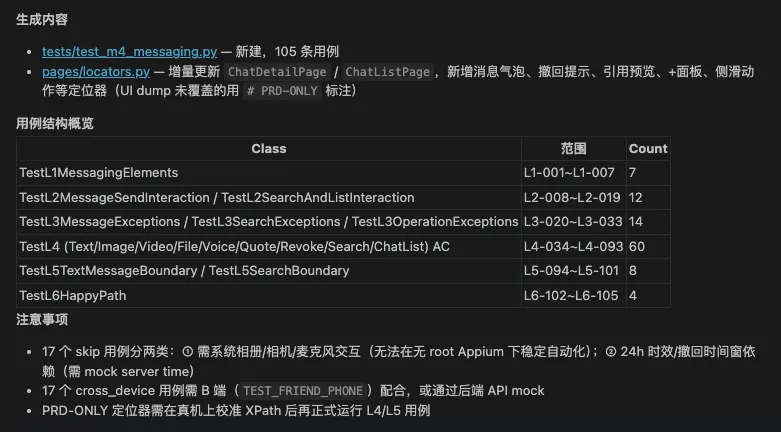
连接真机,执行自动化测试脚本,会产出Allure测试报告,测试报告自动填充前置步骤,测试步骤,测试截图等信息
部分不好执行的场景(比如打开相册,麦克风授权,删除好友等)脚本自动标记skip跳过,这时由人工测试来覆盖
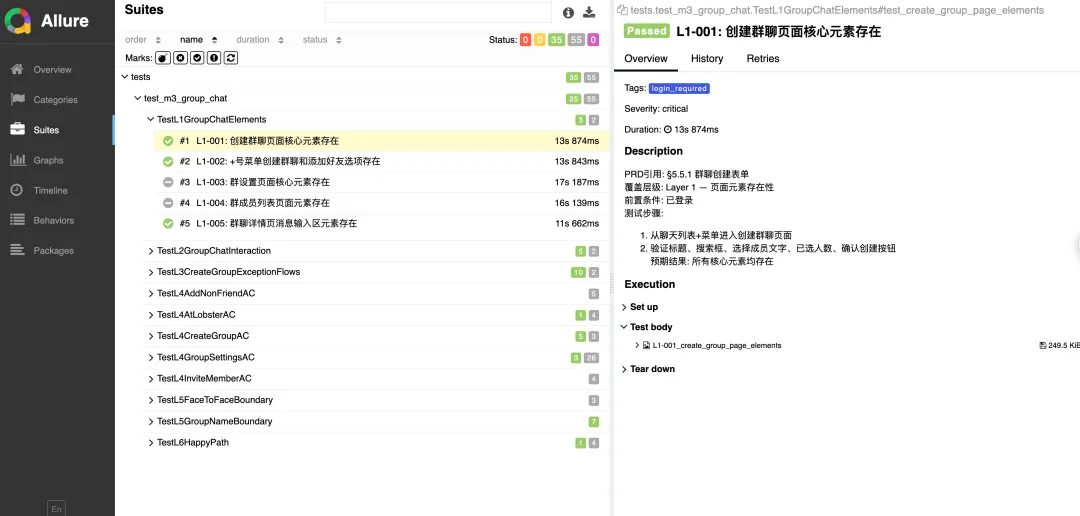
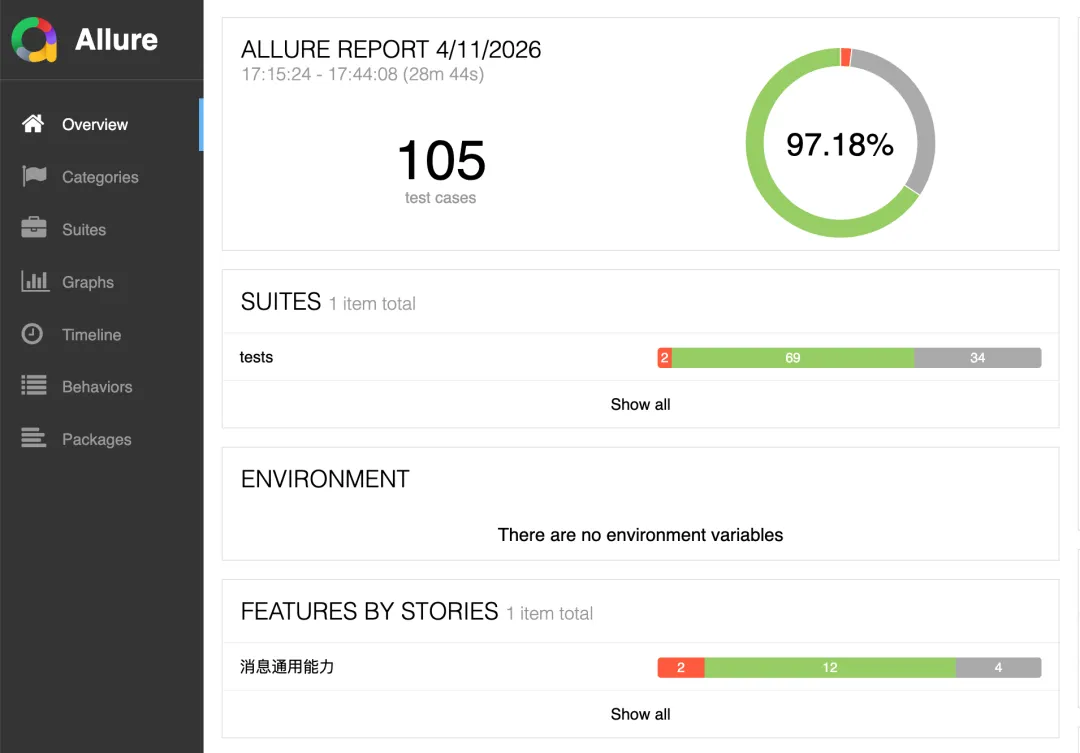
PS:初次执行生成Case可能会有些错误,AI会启动自修复环节后重新执行测试,如图我第一次运行某模块Case成功率只有约5%,经过AI自修复后,成功率提升到97%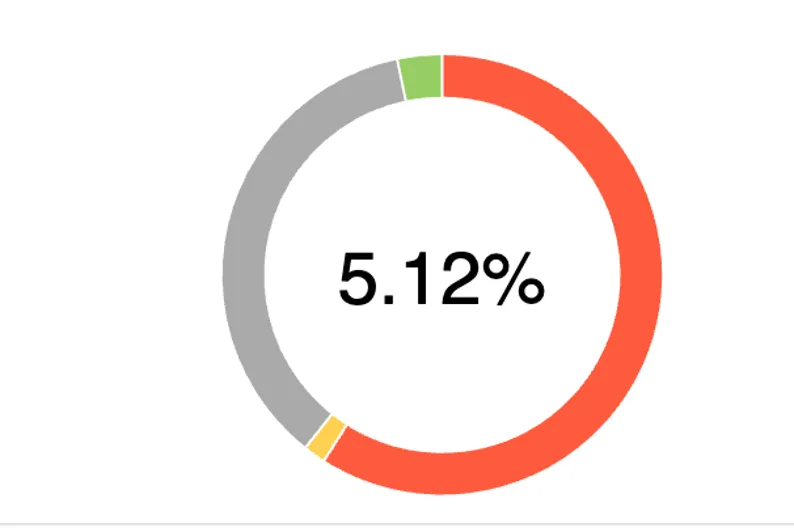
结束语
最后在实践AI代替人工测试的过程,有几点跟大家分享
对AI的信任
AI生成出来的Case是否是有效的,目前现阶段通过我的实践来看,粗估是80%首次AI生成出来Case可用,经过AI自修复后,部分功能的Case可以达到100%可用(我用的是Claude Opus 4.6 模型,业界公认最好的模型之一)
那这100% 可用的Case里面,是否有无效操作,或者执行不到位的情况?
的确存在,现阶段即使AI 认为通过的Case,我还是会人工核实检查一遍,便于后续继续优化Skill,对于有明显错误的Case让AI再次进行调整
部分元素无法定位
AI在修复UI自动化测试用例过程中,部分元素可能无法定位(比如点击按钮,弹Tab,Tab上选项无法定位),最后只能用坐标或者ADB命令来定位,一些异常场景AI踩坑的经验,可以写进skill,方便下次AI快速解决
对于交互逻辑比较复杂,跨页跨端的场景,传统DOM树遍历的方式可能会存在无法定位到太深的元素,或者遍历深度不足,比如一个下单流程,有选品-》加购物车-》支付等这样比较长的链路,最后的支付流程可能很难被遍历到
这样的场景还是需要人工来测试或者结合一些其他的UI自动化测试框架,比如Airtest等视觉定位框架
工作流转化
我现在的工作模式已经转为AI辅助QA的工作模式,通过一系列的Skill,让AI主导测试
用AI后效率到底提升了多少?
试想原来我一个需求写用例要0.5天,人工测试要3天,而现在AI 30分钟比用例生成完,30分钟完成自动化测试脚本执行,算上调整case时间1个小时,不到1天就能完成一轮测试(仅举例,具体提效时间由不同需求&流程有所区别)
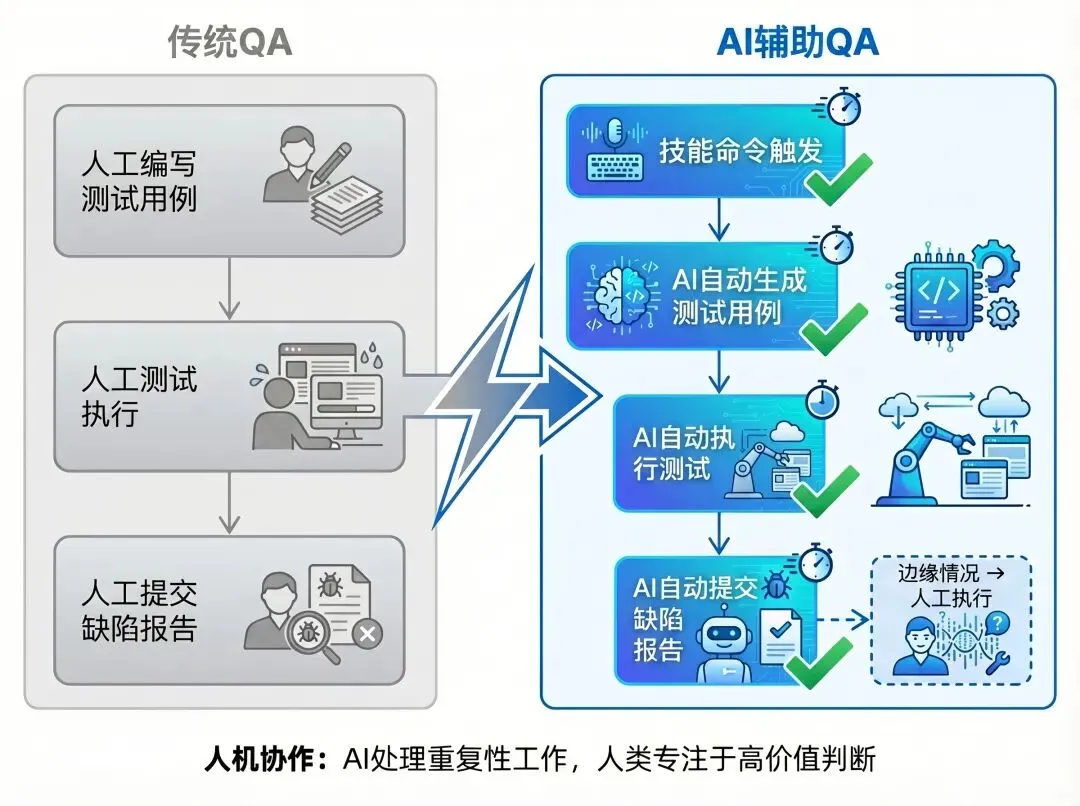
AI辅助QA的模式仍然不是终点,skill命令执行目前还需要人来触发
能否完全交给AI,执行完AI给我测试报告,我只来验收结果?
这正是我目前还在探索的事情,利用OpenClaw等Agent,把工作流完全交给AI自主完成,当然在实现这一切以前,先需要把skill这样的单点能力完善好,后续交给AI才能更加顺利
本文中涉及的两个Skill,已经放在测开学习圈里面了,欢迎进圈获取
【往期推荐】
大厂测开面试都在问AI,这个实战项目直接帮你准备好了
利用OpenClaw+飞书,AI驱动UI自动化测试实战案例来了
26届拿到字节测开实习offer(附面经)

你好,我是洋子,非典型理工男,毕业于中国传媒大学,前百度高级测试开发工程师,现AI测试工程师。利用半年时间,通过自学从功能测试进阶到测试开发,点击查看我的学习路线
我组建了测试开发学习圈子(限时特惠,立减20元),一直持续分享测开找工作的经验,提供高频面试题答案/简历1V1优化/问题答疑/学习资料等服务,目前已经累计服务超过1000 人,欢迎点此了解
同时,我也是 B 站 UP 主:Bug挖掘机,日常分享软件测试领域干货知识,输出面试、工作经验,欢迎围观
测试开发学习交流群开放中,后台回复【进群】即可加入
关注公众号获取 原创测试开发学习路线/10G电子书/简历模板/大厂面试真题/测试工具/测试文档模板等福利