夜雨聆风
夜雨聆风





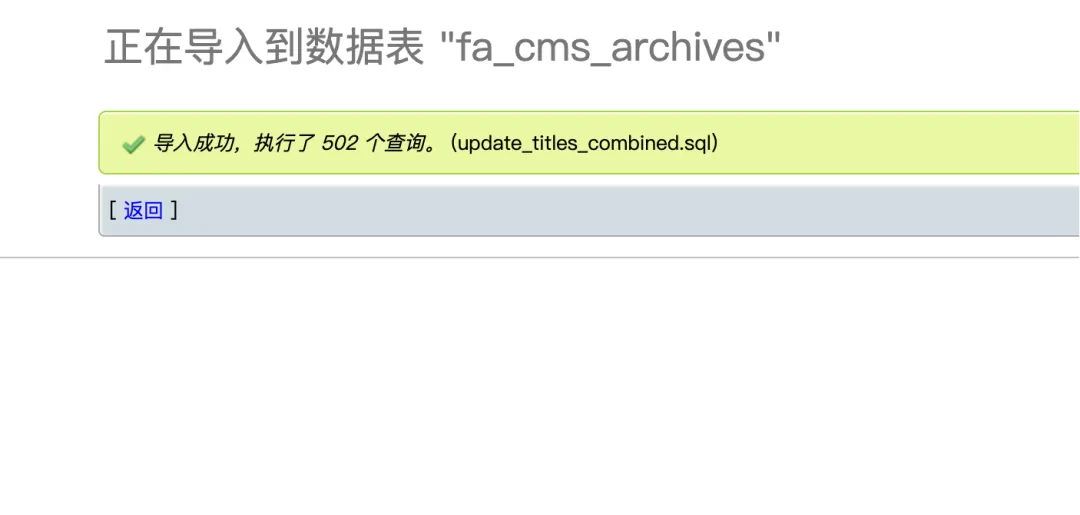
从 Excel 表格读取「编码」与「型号」两列,生成一份 MySQL 更新脚本
我能为你提供什么服务?
网站建设 | 小程序开发 | 软件定制
我是鹏魔王,一个做网站、小程序的程序员,记录生活日常、及技术分享。
本欲起身离红尘,奈何影子落人间,欢迎关注,祝大家早日实现财务自由!
把 Excel 里的「编码」对应的「型号」同步到数据库文章标题
来个python 脚本处理一下,看成品
#!/usr/bin/env python3"""用途----从 Excel 表格读取「编码」与「型号」两列,生成一份 MySQL 更新脚本:把 fa_cms_archives.title 更新为「编码-型号」的格式。背景----很多产品导入后文章标题(title)被写成了编码(xxxx)。现在希望用「编码-型号」的格式替换标题,便于后台管理与前台展示。输出----- update_titles_combined.sql:UPDATE 语句集合(可导入 MySQL 执行)- update_titles_combined_report.csv:映射预览(便于抽查)- update_titles_combined_duplicates.csv:当同一编码对应多个型号且冲突时输出(可选)说明----脚本默认只更新指定范围(where-model-id / where-channel-id),避免误改其它栏目内容。"""import argparseimport refrom pathlib import Pathfrom typing import Optional, Tupleimport pandas as pddef _norm(s: str) -> str:# 用于匹配列名/表头:去掉空格和换行,统一比较s = "" if s is None else str(s)s = s.strip()s = re.sub(r"\s+", "", s)return sdef _escape_mysql_string(value: str) -> str:# 生成 SQL 时避免引号/反斜杠导致语法错误s = "" if value is None else str(value)return s.replace("\\", "\\\\").replace("'", "\\'")def _find_header_row(df_raw: pd.DataFrame) -> int:# Excel 可能第一行是空/合并单元格,此处扫描前 50 行定位真正表头行target_a = _norm("编码")target_b = _norm("型号")scan_rows = min(len(df_raw), 50)scan_cols = min(len(df_raw.columns), 50)for r in range(scan_rows):row = df_raw.iloc[r, :scan_cols].tolist()norms = {_norm(x) for x in row}if target_a in norms and target_b in norms:return rraise ValueError("未在前 50 行中找到包含「编码」「型号」的表头行")def _build_where(model_id: int, channel_id: int) -> str:# 构造 SQL WHERE 子句,限制更新范围conds = []if model_id:conds.append(f"`model_id`={model_id}")if channel_id:conds.append(f"`channel_id`={channel_id}")return " AND ".join(conds) if conds else "1"def build_mapping(xlsx_path: Path) -> pd.DataFrame:"""读取 Excel,返回两列:jw_code, product_model"""df_raw = pd.read_excel(xlsx_path, dtype=str, keep_default_na=False)header_row = _find_header_row(df_raw)df = df_raw.iloc[header_row + 1:].reset_index(drop=True)df.columns = df_raw.iloc[header_row].tolist()# 定位列jw_code_col = Noneproduct_model_col = Nonefor c in df.columns:if _norm(c) == _norm("编码"):jw_code_col = cif _norm(c) == _norm("型号"):product_model_col = cif not jw_code_col or not product_model_col:raise ValueError("Excel 中未找到「编码」或「型号」列")# 清洗数据mapping = (df[[jw_code_col, product_model_col]].rename(columns={jw_code_col: "jw_code", product_model_col: "product_model"}).astype(str).apply(lambda x: x.str.strip()))mapping = mapping[mapping["jw_code"] != ""].drop_duplicates(subset=["jw_code"])return mappingdef gen_sql(mapping: pd.DataFrame, table: str, where_clause: str) -> str:"""根据映射生成 UPDATE SQL"""lines = ["SET NAMES utf8mb4;"]for _, row in mapping.iterrows():jw_code = _escape_mysql_string(row["jw_code"])product_model = _escape_mysql_string(row["product_model"])combined_title = f"{jw_code}-{product_model}"sql = (f"UPDATE `{table}` "f"SET `title`='{combined_title}' "f"WHERE `title`='{jw_code}' AND {where_clause};")lines.append(sql)return "\n".join(lines)def main():parser = argparse.ArgumentParser(description="根据 Excel 中的「编码」「型号」生成 MySQL 更新脚本,把标题更新为「编码-型号」格式")parser.add_argument("--xlsx", required=True, help="Excel 文件路径")parser.add_argument("--table", default="fa_cms_archives", help="目标表名(默认 fa_cms_archives)")parser.add_argument("--where-model-id", type=int, default=2, help="附加条件:model_id(默认 2)")parser.add_argument("--where-channel-id", type=int, default=235, help="附加条件:channel_id(默认 235)")parser.add_argument("-o", "--output", default="update_titles_combined.sql", help="输出 SQL 文件名")parser.add_argument("--report", default="update_titles_combined_report.csv", help="映射报告文件名")parser.add_argument("--dup", default="update_titles_combined_duplicates.csv", help="重复冲突报告文件名")args = parser.parse_args()xlsx_path = Path(args.xlsx)if not xlsx_path.exists():raise FileNotFoundError(f"Excel 文件不存在:{xlsx_path}")print("[1/4] 读取 Excel 并建立映射...")mapping = build_mapping(xlsx_path)print(f" 共 {len(mapping)} 条有效映射")# 检查重复冲突(同一编码对应多个型号)dup_mask = mapping.duplicated(subset=["jw_code"], keep=False)if dup_mask.any():dups = mapping[dup_mask].sort_values("jw_code")dups.to_csv(args.dup, index=False, encoding="utf-8-sig")print(f" 警告:发现 {dups['jw_code'].nunique()} 个编码存在多型号冲突,已导出 {args.dup}")# 生成预览报告mapping.to_csv(args.report, index=False, encoding="utf-8-sig")print(f" 映射预览已导出:{args.report}")# 生成 SQLwhere_clause = _build_where(args.where_model_id, args.where_channel_id)sql_content = gen_sql(mapping, args.table, where_clause)Path(args.output).write_text(sql_content, encoding="utf-8")print(f"[2/4] SQL 已生成:{args.output}")print(f"[3/4] WHERE 条件:{where_clause}")print("[4/4] 完成!执行以下命令导入数据库:")print(f" mysql -u<用户名> -p<密码> <数据库名> < {args.output}")if __name__ == "__main__":main()