 夜雨聆风
夜雨聆风





为什么 2026 年的 AI 助手还是"金鱼记忆"?Hermes 给出了不同答案
阅读提示:本文面向有一定工程背景的读者,将从架构设计层面分析 Hermes Agent 的核心差异化。预计阅读时间 12 分钟。
前言:AI 时代的”无状态”困局
在 2025 年的技术版图中,大模型的推理能力已然触及新的高度,但一个令人沮丧的困局依然普遍存在:无论你与 AI 助手进行了多少次深度长谈,一旦开启新对话,它依然是个”熟悉的陌生人”。你不得不一次次重复背景、偏好与决策逻辑,这种摩擦力正在持续消磨开发者对 Agent 工具的生产力预期。
这个现象揭示了行业的一个公开秘密:市场上绝大多数 AI 助手,本质上只是无状态套壳(Stateless Wrapper)——它们包装了模型的推理能力,却没有承载人类工作痕迹的容器。
Hermes Agent 正在尝试打破这一局面。它不仅是一个聊天接口,而是一个真正的有状态智能体运行时(Stateful Agent Runtime)——不仅在对话,而是在持续学习并固化你的数字资产。
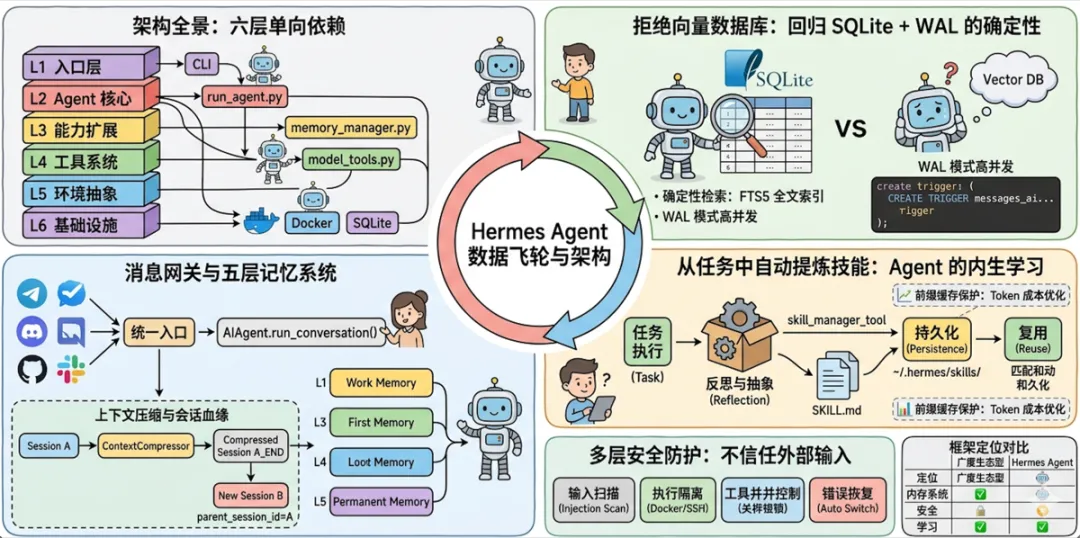
架构全景:六层单向依赖
在深入各个设计决策之前,有必要先建立整体认知。Hermes 的核心是一套严格的六层单向依赖架构:
设计哲学:每一层只依赖下层,不感知上层。从零依赖的
hermes_constants.py开始,这种极致解耦使得各层可以独立测试、替换和扩展,是构建长期可维护系统的基本前提。
一、拒绝向量数据库:回归 SQLite + WAL 的确定性
当大多数开发者盲目推崇向量数据库(Vector DB)进行语义检索时,Hermes 做出了一个看似逆潮流的选择:SQLite + WAL(Write-Ahead Logging)模式。
这个决策背后有清晰的技术逻辑。向量检索的核心是语义相似度,在处理模糊信息时有效,但在记忆检索场景中极易产生语义漂移——它可能找回一条数学上相似但逻辑上谬误的记录。对于需要精确回溯决策历史的 Agent 来说,概率性的模糊匹配是一个结构性缺陷。
确定性检索:FTS5 全文索引
Hermes 押注的是 SQLite 内置的 FTS5(Full-Text Search 5)。通过 session_search 工具,Agent 可以进行精确的前缀、布尔和短语搜索,从原始记录中提取线索,而不依赖模糊的数学猜测。
更重要的是,FTS5 虚拟表通过触发器与 messages 表保持实时同步:
-- 任何新消息写入,立即同步到全文搜索索引CREATE TRIGGER messages_ai AFTER INSERT ON messages BEGIN INSERT INTO messages_fts(rowid, content) VALUES (new.id, new.content);END;这意味着:无需额外维护 Elasticsearch 或 Redis,所有对话记录的变更都自动反映到搜索索引中。
高并发下的稳健性
WAL 模式配合 BEGIN IMMEDIATE 事务,Hermes 实现了读写并发支持。当 Gateway 多平台同时写入遭遇 database is locked 时,系统会进行最多 15 次、带随机抖动(20–150ms)的指数退避重试。无论是 Telegram 和 Discord 同时调用,还是后台正在进行记忆固化,系统都能保持稳健。
单文件的 SQLite 还带来了额外的工程红利:备份、迁移、调试的复杂度降至最低,这正是构建持久化生产工具所需要的确定性基石。
二、从任务中自动提炼技能:Agent 的内生学习
Hermes 真正差异化的能力,在于其闭环学习机制:它不是被动执行指令,而是能从任务经验中自动提炼结构化知识。

技能固化流水线
当 Agent 完成复杂任务后,会通过 skill_manager_tool 将成功经验抽象为 SKILL.md 文件,存储在 ~/.hermes/skills/ 目录下。每个技能文件遵循统一的 frontmatter 格式,包含 name、description、platform 等元数据。
加载策略同样经过细致设计。prompt_builder.py 中的 build_skills_system_prompt() 采用双层缓存:进程内 LRU 缓存 + 磁盘 mtime 检测。只要技能目录未发生修改,就直接返回缓存结果,避免每轮对话反复扫描磁盘。扫描时还会进行平台感知过滤——SKILL.md 中的 platform 字段若与当前运行平台不匹配,该技能自动跳过,确保上下文的纯净度。
前缀缓存保护:一个被忽视的 Token 成本优化
这里有一个值得专门说明的架构细节。Hermes 将 pre_llm_call 插件返回的动态上下文注入用户消息(User Message),而非系统提示词(System Prompt)。
原因在于:Anthropic 等主流提供商对静态系统提示词有前缀缓存优化。如果系统提示词每轮都变化,缓存失效会导致输入 Token 成本显著增加。将动态记忆上下文放在用户消息中,既能让模型获取最新信息,又能保持系统提示词稳定,充分享受缓存优惠。
由于 Gateway 每轮对话都会新建 AIAgent 实例,实例级缓存自然失效。Hermes 的解决方案是从 SQLite 回读上一轮存储的 system_prompt,确保前缀缓存跨实例不被破坏。
三、消息网关:统一入口与会话血缘管理
Hermes 的 Gateway 不是简单的消息转发器,它是一套统一的平台抽象。无论通过 Telegram、Discord、Slack、WhatsApp、Signal、Matrix 还是 Email 接入,背后的逻辑全部收敛于核心的 AIAgent.run_conversation()。
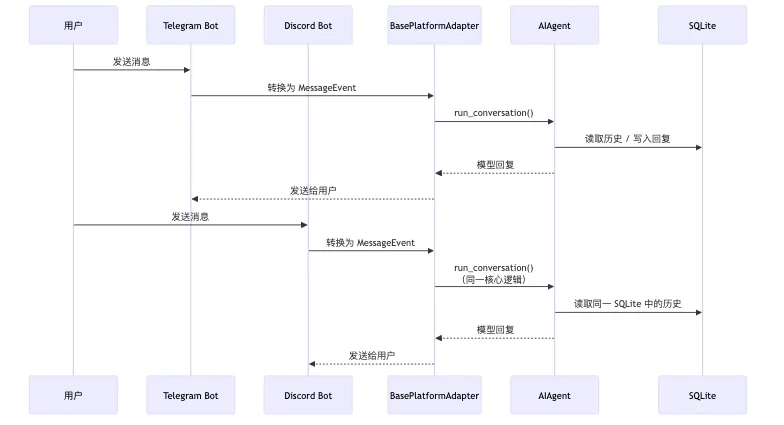
平台适配器的抽象边界
gateway/platforms/base.py 中的 BasePlatformAdapter 将各平台原生消息统一转换为 MessageEvent,使 Agent 完全解耦于具体平台。每个适配器在 connect() 时获取平台锁,防止同一用户启动两个实例导致 Token 冲突。
上下文压缩与会话血缘
当对话接近模型上下文上限时,ContextCompressor 触发压缩。但它不是简单地”丢弃数据”——压缩后,原始 session 被 end_session() 标记为 end_reason='compressed',同时创建新的 session,其 parent_session_id 指向旧 session。

这一设计将上下文压缩从”信息销毁”变为”信息归档”,带来三个关键保障:
-
1. 被压缩的原始内容仍可通过 FTS5 精确检索 -
2. get_session_lineage(session_id)可返回完整的 session 谱系列表 -
3. 跨平台记忆一致——你在 Telegram 里建立的知识,CLI 里同样可以访问
以下是五层记忆系统的流转全貌:
四、多层安全防护:从不信任外部输入
当 Agent 拥有执行终端命令和自我进化的能力,安全性成为最高优先级。Hermes 的安全体系建立在多个相互独立的防护层之上。

Prompt Injection 扫描
在将 AGENTS.md、.cursorrules、.hermes.md 注入系统提示词之前,prompt_builder.py 会执行安全扫描,分为两个阶段:
-
• 不可见字符检测:识别 zero-width space(U+200B)等隐藏 Unicode 字符 -
• 模式匹配:正则检测 ignore previous instructions等典型注入模式
一旦检测到威胁,文件内容会被替换为警告文本,防止恶意仓库通过上下文文件劫持 Agent。
执行环境物理隔离
BaseEnvironment 与宿主机解耦,支持 Local、Docker、SSH、Modal 以及 Daytona。同一段代码在不同后端上无缝运行,文件操作和终端执行不绑定本地操作系统。
工具并发的精细风险控制
工具调用并非简单的”全并行”或”全串行”。_should_parallelize_tool_batch() 基于工具名称和文件路径重叠进行精细分析:
|
|
|
|---|---|
_NEVER_PARALLEL_TOOLS
clarify) |
|
_PATH_SCOPED_TOOLS
read_file、write_file) |
|
_PARALLEL_SAFE_TOOLS |
ThreadPoolExecutor 并发 |
错误分类与自动恢复
agent/error_classifier.py 将 API 错误分为 RATE_LIMIT、AUTH_FAILURE、PAYLOAD_TOO_LARGE、CONTEXT_OVERFLOW、SERVER_ERROR 等类型,并决定重试策略或故障转移路径。更关键的是,_restore_primary_runtime() 会在每次 run_conversation() 启动时自动切回主模型——一次网络抖动不会导致永久降级。
五、框架定位对比:广度生态 vs 深度运行时
在 2025 年的开源 Agent 生态中,不同框架的设计取向存在根本性差异:
|
|
|
|
|---|---|---|
| 核心定位 |
|
|
| 记忆系统 |
|
|
| 工具体系 |
|
|
| 安全模型 |
|
|
| 学习能力 |
|
SKILL.md |
| 上下文压缩 |
|
parent_session_id 血缘链路 |
| 适用场景 |
|
|
广度生态型框架适合需要大量平台连接的商业场景;Hermes 的价值主张则不同——它是一个随使用深度持续增值的工具,贪婪地吸收你的决策逻辑,并将其转化为专属的生产力资产。
结语:数据飞轮的终极形态
Hermes Agent 的架构选择,折射出一种对 AI 工具本质的不同理解:AI 不应只是消耗品,而应是能够承载人类工作痕迹和决策逻辑的容器。
通过 SQLite 的确定性记录、精密的 Token 成本优化、严密的安全防护,以及自主的技能提炼机制,Hermes 试图构建的是一种真正的”数据飞轮”——越用越好,越用越懂你。
这也引出一个值得认真思考的问题:当一个 Agent 完整数字化了你的经验、决策偏好乃至犹豫时的直觉,这份”经验资产”究竟归谁所有? 是存储于算力巨头云端的模型服务,还是你亲手调教出来的本地系统?
Hermes 选择了后者,将数据主权交还给用户。在 AI 工具日益同质化的今天,这或许是最值得关注的差异化方向——不是更强的推理,而是更深的记忆。
延伸阅读
-
• 第1篇 10 分钟装好 Hermes,用 Profile 隔离你的“工作人格”和“生活人格”[1] -
• 第3篇 一条消息的“生死之旅”:穿越 Hermes 六层架构的 2900 行状态机[2] -
• 第4篇 别再往 System Prompt 里塞东西了!深度拆解 Hermes Agent 的“五层记忆”黑科技[3]