 夜雨聆风
夜雨聆风





拆解Claude code源码!Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems
这是一篇极具工程价值与系统设计启发的深度分析论文。不同于传统的算法模型研究,本论文聚焦于软件工程(Software Engineering)与系统架构领域,通过逆向工程剖析了前沿商业级 AI 编程智能体(Claude Code)的底层设计哲学与工程实现(https://arxiv.org/abs/2604.14228)。

1. 🎯 研究动机 (Research Motivation)
- 核心问题
:随着 AI 辅助编程工具从代码补全(如 Copilot)向完全自主的智能体(如 Devin, Claude Code)演进,系统必须具备规划、工具调用、文件读写和执行 Shell 命令的能力。然而,这些商业级智能体背后的架构设计、安全边界与上下文管理机制通常是封闭的,缺乏公开的架构级剖析。 - 解决必要性
:构建生产环境可用的智能体所面临的挑战(如:如何防止模型失控、如何管理极其有限的上下文窗口、如何进行多智能体协同)是行业的共同痛点。剖析现有成熟商业系统的代码级实现,能够为未来的智能体架构设计提供标准和避坑指南。 - 研究意义 (Significance)
:本文填补了商业智能体架构说明的空白,将 Claude Code 抽象出 5 个人类价值观驱动的 13 个设计原则,并提炼了 7 组件与 5 层子系统架构。同时,通过与开源系统 OpenClaw 的对比,揭示了不同部署环境(CLI 工具 vs. 多渠道网关)对智能体架构设计的深远影响。
2. 🧮 数学表示及建模 (Mathematical Modeling & Formulation)
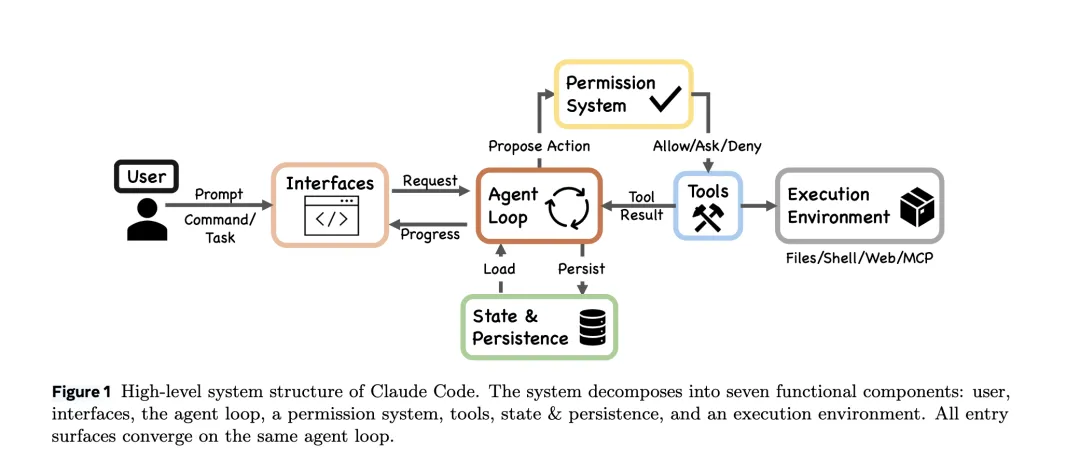
由于本文属于软件工程与系统架构(Systems & Architecture)类研究,并未提出新的机器学习损失函数或神经网络架构。但为了严谨表述其核心的智能体查询循环(Agentic Query Loop)与权限控制建模,我们可以将其工作流形式化抽象如下:
符号定义:
: 时刻的对话状态与上下文窗口(Context Window)。
:当前可用的工具集(Tool Pool),结合了内置工具、MCP、插件等。
:权限与安全策略集合(Permission System),采用“拒绝优先(Deny-first)”逻辑。
:由 5 层子系统构成的上下文压缩管道(Compaction Pipeline)。
逻辑架构与控制流抽象: 智能体的核心是一个带有状态管理的无休止循环(While-true loop)。其状态转移过程可形式化为:
- 动作生成
:模型基于当前压缩后的上下文和可用工具集,生成动作(包含文本响应或工具调用请求)。 - 安全拦截与权限决策
:若动作 为工具调用,必须经过安全层评估决策 。拒绝策略具有最高优先级。 - 执行与状态转移
:若权限允许(或用户批准),环境执行该动作并返回结果 ;否则返回拒绝反馈供模型重试。 - 上下文更新
:合并历史状态,进行新一轮的压缩与组装。
3. 🧪 实验方法与设计 (Experimental Methodology)
- 分析对象与架构
:对 Anthropic 发布的 Claude Code(版本 v2.1.88)TypeScript NPM 包进行静态代码提取与逆向分析,涉及约 512K 行代码、1884 个文件。 - 核心机制拆解
: - 架构比例
:发现智能体的“AI 决策逻辑”仅占整个代码库的约 1.6%,剩余 98.4% 均为操作基础设施(Operational Harness)。 - 上下文管理
:设计了 5 层渐进式压缩管道(Budget reduction, Snip, Microcompact, Context collapse, Auto-compact),以应对 1M token(Claude 4.6 系列)的上下文压力。 - 权限分级
:内置 7 种权限模式(包括 plan, default, acceptEdits, auto 等),通过独立于模型的拦截器和沙箱保护机器安全。 - 对比基线 (Baseline)
:在架构讨论环节,引入了独立的开源 AI 智能体系统 OpenClaw(一个本地优先的 WebSocket 个人助理网关)作为对照组,对比两者在信任模型、扩展架构和路由机制上的异同。
4. 📊 实验结果及核心结论 (Results & Core Insights)
由于是系统分析论文,结论体现为高维度的架构 Insights,而非 Benchmark 打榜分数:
- 重基础设施,轻决策脚手架 (Minimal scaffolding, maximal harness)
:与 LangGraph 强制规定状态图节点不同,Claude 采用极简的响应式循环(ReAct 变体),将工程精力主要投入在确定性的基础设施上(如工具路由、错误恢复、权限拦截),让模型自身掌握最大的决策自由度。 - 防线的脆弱性共振 (Vulnerability of Defense in Depth)
:虽然 Claude 采用了多层深度防御,但研究发现这些层级存在共同的性能约束瓶颈。例如,当 Shell 命令包含超过 50 个子命令时,为了避免 UI 卡顿,系统会跳过细粒度的拒绝规则检查而回退到全局通用提示。这证明了即使是深度防御,在性能压力下也可能产生安全盲区。 - 上下文是绝对的瓶颈 (Context as binding constraint)
:所有子系统的设计都在向“上下文窗口妥协”。例如:子智能体(Subagents)执行完毕后,仅仅将“总结(Summary)”返回给主对话上下文,而单独在侧链(Sidechain)文件中保存完整的执行日志(JSONL),以防止主窗口爆炸。
5. 🧐 深度锐评 (Critical Review)
优势 (Strengths):
- 稀缺的生产级系统切片
:学术界充斥着基于开源小模型的“玩具级”Agent 框架,而本文深入解剖了硅谷一线大厂(Anthropic)的生产级商业系统。其提出的“1.6% 逻辑 vs 98.4% 基座”的结论,为学术界“过度设计 Agent 规划流程”敲响了警钟。 - 极高的数据密度与工程指导性
:将庞大的 TypeScript 项目精准还原为逻辑架构图,梳理出的 4 种扩展机制(MCP, 插件, 技能, Hook)按照上下文开销(Context Cost)进行排序(零开销、低开销、中开销、高开销)的设计非常精妙,具有极强的实操指导意义。
不足 (Weaknesses):
- 逆向工程的固有认识论局限 (Epistemological Constraints)
:由于基于 NPM 包的静态代码分析,作者无法获取服务端的真实路由逻辑、灰度开关(Feature Flags)的具体分布,也无法知晓被废弃的代码分支。这导致部分分析可能仅仅是“死代码(Dead Code)”或实验特性。 - 定量评估的缺失
:论文详细分析了 5 层上下文压缩管道(Compaction Pipeline),但完全没有提供这 5 层开启/关闭状态下的性能消融实验(Ablation Study)。系统架构是否真的优于传统的 RAG 截断?缺乏数据支撑。
改进方向: 建议在后续研究中引入动态追踪与网络层拦截,通过构建模拟的代码修复任务(如 SWE-Bench),抓取系统在真实运行中对 LLM API 的实际请求 Payload,以此来定量分析每层上下文压缩对 Token 消耗与任务成功率的具体贡献。
6. 🧠 思考题 (Progressive Questions)
- Q1 基础理解
:根据论文所述,Claude Code 提供了 4 种扩展机制(MCP, Plugins, Skills, Hooks)。如果我们需要让智能体在每次调用终端命令行(BashTool)之前,静默检查目标文件的只读属性而不消耗大量的 Prompt Token,应该选择哪一种机制?为什么? - Q2 深度分析
:论文指出 Claude Code 采用了“仅追加(Append-only)”的会话持久化存储,并且在跨会话恢复(Resume)时拒绝自动恢复历史权限。这种极其保守的安全性设计,在面临跨周期、长时间运行(Long-horizon)的代码重构任务时,会造成怎样的工作流断裂? - Q3 开放延展
:论文揭示了工业界 Agent 极高比例(98.4%)的代码都在处理环境适配、权限判断和上下文压缩,而非复杂的决策树(树搜索/图路由)。随着未来 GPT-5/Claude 4 等基础模型拥有无限长上下文(Infinite Context)和原生内置工具调用能力,你认为这 98% 的工程脚手架是被模型本身吞噬殆尽,还是会演化出更厚重的新型架构形态?
7. 💡 One More Thing (其他亮点)
隐藏的架构彩蛋:时间维度漏洞的发现论文第 11.3 节提到了一组非常有意思的独立安全研究发现:由于系统在初始化加载时(扩展初始化 -> 信任对话框弹出 -> 权限强制执行),使得 Hook 和 MCP 服务器等扩展代码可以在用户点击同意信任(Trust Dialog)之前就执行。这导致了至少两个高危的 CVE 漏洞(CVE-2025-59536 等)。这个细节完美证明了:在 AI 智能体设计中,除了空间上的权限隔离(防逃逸),时间上的执行序列(Temporal Ordering)同样能成为极具威胁的攻击面。这是本篇架构分析给安全工程师的一份绝佳“伴手礼”。