 夜雨聆风
夜雨聆风





高通工程师让AI代理“打工”:7分钟自动搞定模型部署,你信吗?

🐉 龙哥读论文知识星球来了!
还在手动部署模型?高通工程师已经让AI代理“打工”了!星球里每天更新AI自动化工程、边缘计算、Agent实战等硬核干货,帮你从“调参侠”升级为“部署架构师”!👇扫码加入「龙哥读论文」知识星球,前沿工程实践、实用资源一站式拿捏~
龙哥推荐理由:
这篇来自高通的“技术报告”没有花哨的理论,全是工程实践的干货。它直击AI模型部署到边缘设备时最痛的几个点:流程长、易出错、依赖专家经验。然后,它提出了一个非常务实的解决方案:用AI代理(Agent)来“打工”,把部署流程自动化。这可不是空想,论文里用ESRGAN、YOLO等模型做了详实的案例测试,展示了从PyTorch到可运行推理的完整自动化路径。对于做AI落地、边缘计算、Agent应用的同学来说,这篇论文提供了一个极佳的“AI部署AI”的工程框架和设计思路,非常值得一读。
原论文信息如下:
论文标题:
AIPC: Agent-Based Automation for AI Model Deployment with Qualcomm AI Runtime
发表日期:
April 2026
发表单位:
Qualcomm Technologies, Inc.
原文链接:
https://arxiv.org/pdf/2604.14661v1.pdf
开源代码链接:
https://github.com/quic/ai-engine-direct-helper/tree/main/tools/skills/qai-runnerskill
AI模型部署太头疼?高通工程师让AI代理来打工!

揭秘AIPC:如何将部署流水线“驯服”成自动化工作流?
六步流水线,步步为营
第一步:模型准备与基线建立让AI代理先跑通原始PyTorch模型,用样例输入生成一套“黄金标准”输出。这一步至关重要,后面所有转换对不对,都得回来跟这个基线比对。
第二步:ONNX转换与接口验证让AI代理自动写ONNX导出脚本,并把整个推理流水线拆成预处理、模型推理、后处理三个独立模块。拆开的好处是,后面出问题了容易定位,也方便为量化批量生成校准数据。
第三步:QAIRT模型构建把ONNX模型转换成QAIRT能用的格式(比如QNN或SNPE)。这里有很多坑,AIPC通过Agent Skills告诉代理要用--preserve_io这样的选项来保持接口稳定,优先选择FP16精度以便验证,并自动触发Context Binary(上下文二进制文件)的编译。
第四步:推理执行与精度对齐让转换好的模型真正跑起来,并检查输出和“黄金标准”的误差是否可接受。AIPC这里用了个巧招:写一个AIPC加载器,让原来的ONNX推理脚本不经修改,直接就能用QAIRT后端跑。这样代理就不用学习一套全新的推理API了,大大降低了犯错几率。
第五步:量化与优化(可选)在前面的流程都稳定后,才进入量化阶段。因为预处理模块已经标准化,代理可以自动生成校准数据,并驱动量化工具链。
第六步:性能分析模型能跑之后,可以进一步收集性能数据,生成部署报告。
核心法宝:“技能包”+“验证循环”
Agent Skills(代理技能):这不是替代底层SDK,而是把部署经验封装成“技能包”。比如,“遇到不支持的算子该怎么办?”、“转换失败时应该先尝试在PyTorch层修复还是在ONNX图层面修复?”。这些技能以文档或模板的形式提供给AI代理,相当于给了它一本“部署问题速查手册”。
验证循环:每一个阶段都有明确的输入和输出要求,并且要验证结果。比如ONNX转换完,必须跑一下推理,数值上跟PyTorch基线比对。这就防止了AI代理生成一堆看起来没毛病的代码,但实际上根本跑不通或者结果不对的情况。

从ESRGAN到Whisper:看AI代理如何应对不同复杂度模型的挑战
ESRGAN(图像超分):结构规整,基本全是卷积。对AIPC来说这就是“新手村”任务,用来验证工作流本身是否通畅。结果非常顺利。
YOLOv8(目标检测):生态成熟,但部署时需要把后处理(如NMS非极大值抑制)从模型主体里拆出来。这考验的是AIPC流水线中“模块化”设计的能力。
LPRNet(车牌识别):这个轻量网络遇到了具体算子问题——MaxPool3d在导出ONNX时可能不兼容。这就需要触发AIPC的“模型手术”能力,在PyTorch层面对算子进行等效替换。
YOLO-World(开放词汇检测):结合了视觉和文本特征,里面用了Einsum算子,可能不被支持。同时接口和多模态对齐也更复杂。
Whisper(语音识别):真正的硬骨头来了!它是Transformer编码器-解码器结构,核心矛盾在于:语音序列长度是动态的,解码是自回归(一个个token生成)的,但NPU最喜欢固定形状的批量计算。这种结构性冲突,自动化工具很难完美解决,往往需要人工设计更巧妙的固定化方案。
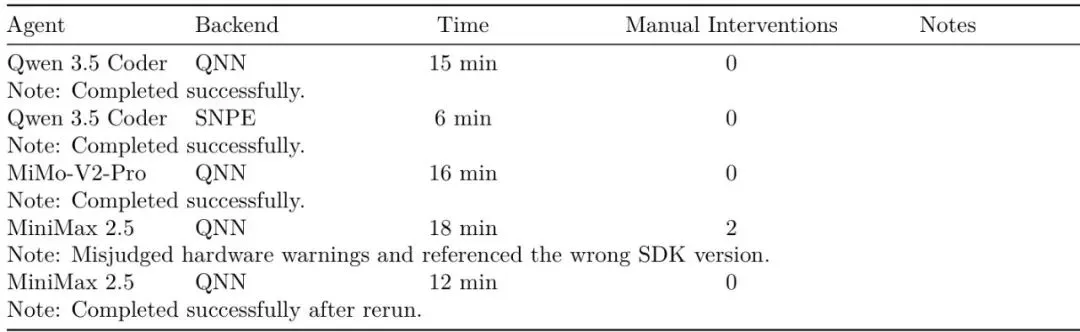
ESRGAN果然是最乖的,全自动完成,时间也短。
LPRNet和YOLO-World因为算子问题需要1次人工干预,但干预后都能成功。
Whisper就不一样了,人工干预了3次,最终还是失败了(“Yes*”带星号表示部分成功或需额外步骤)。这正好划出了当前全自动部署的能力边界:对于动态解码、自回归生成这类结构,自动化可以辅助执行和定位,但核心的冲突解决还需要人的智慧。

AI代理也分“优等生”和“刺头”?工作流遵循能力大比拼
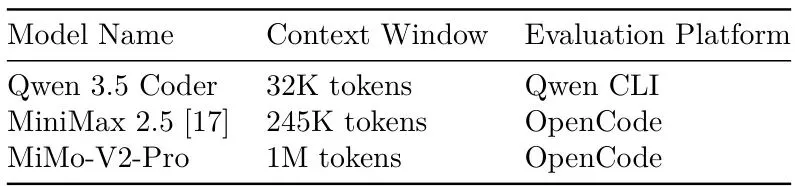


失败不是终点:AIPC如何将人工干预转化为进化燃料?
未来已来:“AI部署AI”的基础设施雏形与展望
工作流抽象:将特定领域的复杂工程任务,分解为标准化的、可验证的阶段。
知识注入:将专家经验封装成机器可读、可执行的“技能”或“模板”。
代理驱动:利用LLM的理解和工具调用能力,在约束范围内自动执行流程。
持续学习:将失败和人工干预转化为系统知识,实现闭环优化。

龙迷三问
AIPC到底是什么?它和传统的模型转换工具有什么区别?AIPC(AI Porting Conversion)是一套自动化工作流框架,而不是一个单一的转换工具。传统工具(如qnn-onnx-converter)只负责“从A格式到B格式”的转换这一步。而AIPC管理的是从原始模型准备,到最终精度验证的完整部署链条,它通过AI代理来串联和驱动各个底层工具,并注入部署领域的专家知识(Agent Skills)来处理中间可能出现的各种错误。区别在于,AIPC关注的是“如何系统化、自动化部署这件事本身”。
部署流程中提到的“模型手术”是什么意思?“模型手术”是指在保证功能基本不变的前提下,为了满足部署工具的兼容性要求,对模型结构进行的修改。这不是训练后的模型压缩,而是部署前的“整形”。常见“手术”包括:1. 动态转静态:把动态输入尺寸固定下来;2. 算子替换:用一组受支持的简单算子,替换掉一个不受支持的复杂算子。AIPC将这类操作标准化,并允许AI代理在遇到特定错误时自动尝试执行。
为什么需要Agent Skills?直接把所有文档扔给AI代理不行吗?不行,效果会差很多。部署知识庞杂且具有强顺序性和决策性。直接把海量文档扔给LLM,它很容易“幻觉”出错误的API,或者在错误的时间点尝试错误的修复方法。Agent Skills的作用是提炼、组织和约束知识,告诉代理:“在这个阶段,你主要会遇到A、B两类问题;遇到A,你应该优先尝试X方案;如果X不行,再考虑Y方案”。这相当于给代理提供了一个清晰的“决策树”和“操作手册”,极大地提高了其执行的成功率和效率。
龙哥点评
论文创新性分数:★★★★☆
将AI代理用于自动化AI模型部署这一特定工程领域,并系统性地提出“工作流分解+技能注入+验证循环”的设计模式,具有很强的工程方法创新性。它不是简单调用API,而是重构了部署流程本身以适应自动化。
实验合理度:★★★★☆
作为技术报告,其实验设计贴合工程实践。通过从简单到复杂的模型案例来探查自动化边界,通过不同代理的对比来观察工作流遵循度,实验目标清晰,观测指标(人工干预次数、时间)直接有效。未进行大规模重复统计实验符合其报告定位。
学术研究价值:★★★☆☆
研究价值主要体现在AI for AI Engineering(AI用于AI工程)和约束性Agent工作流设计这两个交叉方向。它为如何将领域知识有效注入AI代理、构建可进化的人机协作系统提供了宝贵的工程范式和实践经验,对后续研究和工业工具开发有启发意义。
稳定性:★★★☆☆
对于结构规整的模型,工作流稳定性和成功率较高。但面对复杂模型(如Whisper)或全新未知错误时,仍需依赖人工判断和干预。系统的稳定性目前高度依赖于预先定义的Skills和修复规则的完备性。
适应性以及泛化能力:★★★☆☆
方法论层面(工作流分解、技能设计)具有很好的泛化潜力,可迁移至其他硬件平台部署。但具体实现目前紧密绑定QAIRT工具链。要适配新平台,需要重新开发一整套针对该平台的Agent Skills和验证步骤。
硬件需求及成本:★★★☆☆
运行AIPC工作流需要能运行现代LLM代理的环境,这可能涉及API调用成本(文中提及每次部署约0.7-10美元)或本地大模型的计算资源。对于目标边缘设备本身,部署产出的模型性能与手工部署无异。
复现难度:★★★★☆
论文相关的工作流和Skill已作为QAI AppBuilder工具链的一部分开源,提供了实践的起点。但完整复现需要特定的高通硬件平台(如Snapdragon X Elite)、QAIRT SDK授权以及配置AI代理环境,有一定门槛。
产品化成熟度:★★★☆☆
已集成到高通的官方工具链中,说明具备了初步的产品形态。适合高通平台开发者用于提升部署效率,尤其适用于常见视觉模型。但距离成为通用、全自动、黑盒式的部署产品还有距离,目前更接近一个“强大的自动化助手”。
可能的问题:本文作为技术报告,深度案例研究是其优点,但也因此缺乏对更广泛模型和代理的大规模系统性评估。对于“Skills”的设计方法论,如何体系化地构建和评估其有效性,文中讨论可进一步深化。
参考文献
*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的“阅读原文”,查看更多原论文细节哦!


