录个屏就能复刻App:这个AI工具让前端开发直接变了天
录个屏就能复刻App:这个AI工具让前端开发直接变了天
最近智谱发布了一个叫GLM-5V-Turbo的多模态模型,我用了一下,说实话有点震惊。
以前复刻一个App页面,流程是这样的:设计师在Figma里标注每一个元素的尺寸、颜色、间距,输出一份详细标注稿;前端工程师对着标注稿一个像素一个像素地还原;设计师review,发现不对的地方打回去改;来回三四轮,一个页面可能要磨一两天。
现在呢?录个屏,或者截张图,一句话扔给GLM-5V-Turbo,几分钟出活。
我录了一段微信读书的操作视频,从首页到书架到个人页,完整录了一段,然后直接扔给模型。提示词就一句话:基于视频帮我复刻这个App。没告诉它这是微信读书,没给任何UI说明文档。
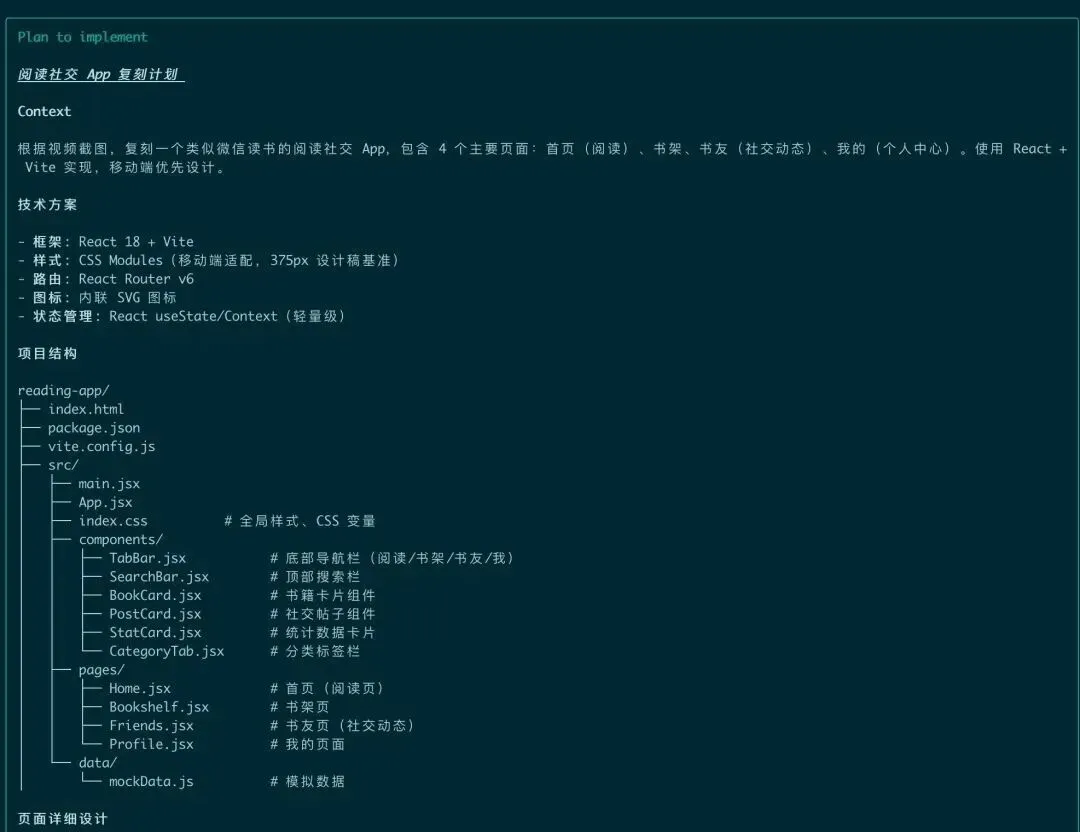
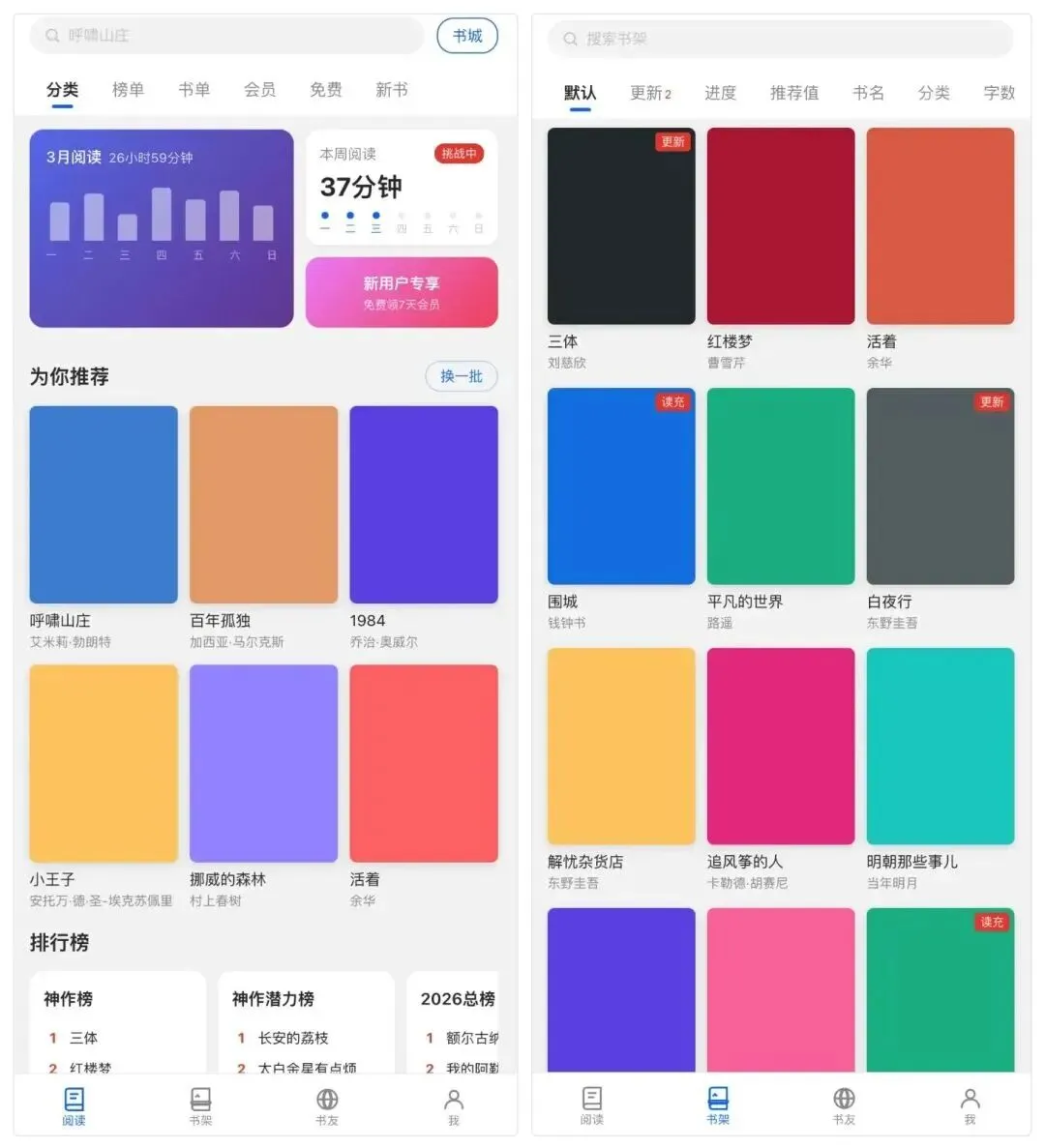
模型接到任务后,先输出了一份完整的复刻计划:页面拆解、组件清单、交互逻辑、技术选型,条理清晰得像一个有经验的前端工程师在做技术方案评审。然后按照计划逐步实施,最终交付的效果让我相当意外——底部tab栏、顶部菜单切换、卡片式书籍列表,全部都还原了,而且每个tab和菜单项都是可点击、可交互的。
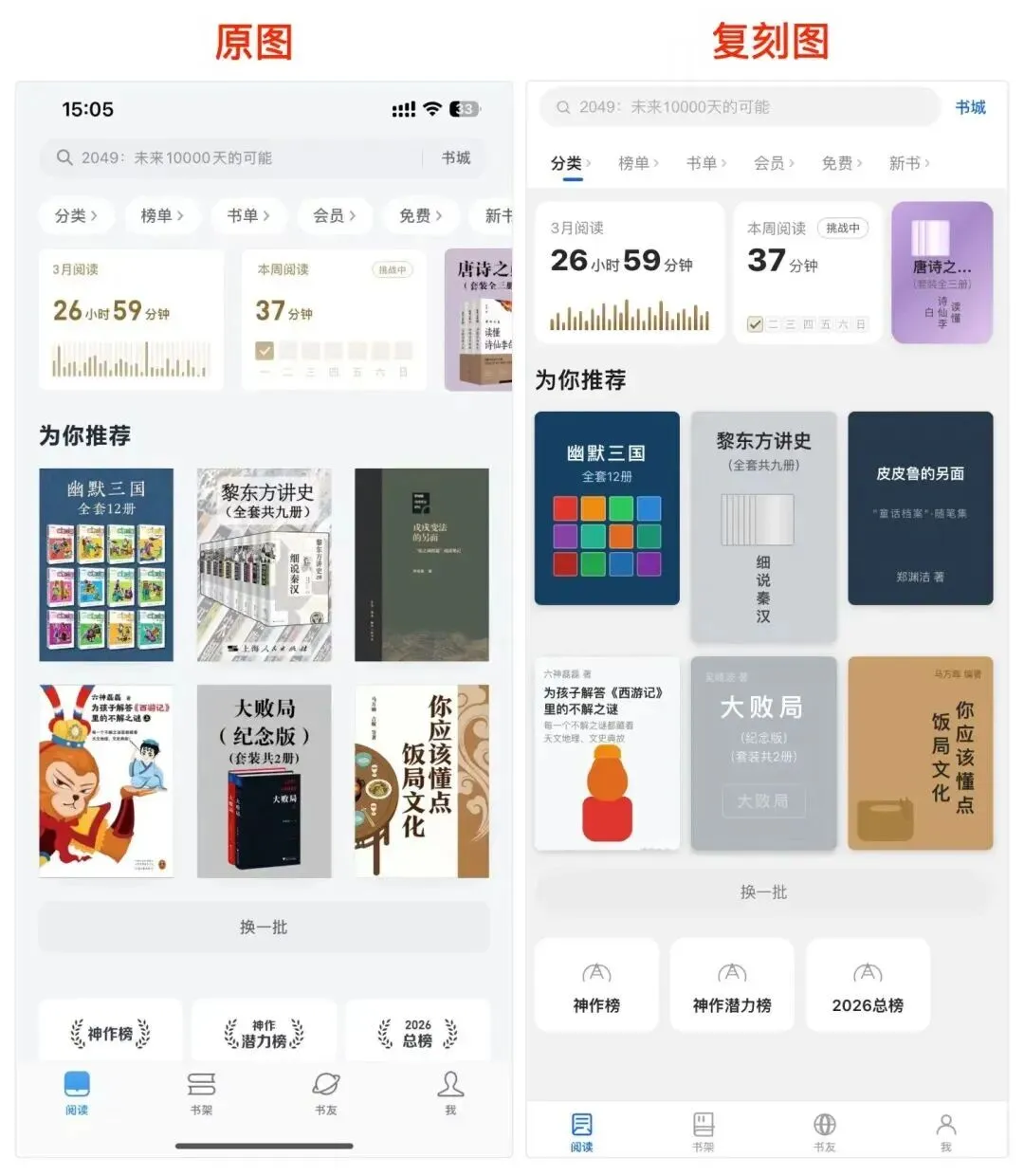
我又试了一下:换成一张高清截图,复刻微信首页。这回效果直接拉满,连文字排版的间距、字号层级几乎都对得上。
这件事的底层逻辑很清晰。GLM-5V-Turbo是原生多模态模型,从预训练阶段就把视觉和语言统一建模。它看设计稿的方式跟人类设计师一样:感知到”这里有一个圆角卡片,背景是半透明毛玻璃效果,左上角有绿色状态指示灯”,然后直接把视觉理解翻译成CSS和组件代码。中间没有OCR转文字再猜语义的有损环节,视觉信息到代码的转换是一步到位的。
再试文档解读:扔一份PDF研报,让它基于图表写分析。GLM-5V-Turbo对图表的数据提取非常精准,柱状图的对比、折线图的拐点、表格里的关键数值,都被准确地引用到了文字分析中,而且自动把原报告的图片嵌进文章里,真的做到了图文并茂。
说实话,AI工具每隔几个月就会出现一个让你感觉”行业又往前走了一步”的节点。视觉编程能力的成熟,就是其中一个。
以前我们用AI写代码,本质上还是在给模型喂文字。现在,截个图、录个视频就能直接下指令,模型看得懂你眼睛看到的东西,这个门槛的降低是质变级别的。
当一个工具能直接”看”懂你的工作内容,而不需要你把工作内容翻译成它能理解的格式,它就真的开始进入你的工作流了。
视觉编程时代已经到来,录个屏就能复刻App,你的前端工作流该更新了。
一枚普通程序员的副业实验田,主业写bug,副业搞Money。
 夜雨聆风
夜雨聆风