 夜雨聆风
夜雨聆风





十个 AI 组了一个编辑部
还真不是。多调几次 AI 和让多个 AI 各司其职,是两回事。前者是你自己当调度员,手动把文章丢给不同的 AI,自己判断谁说得对。后者是一套自动运转的流程,每个 AI 有明确的角色、权限和边界,它们之间有严格的先后顺序和打回机制。你别笑,听起来简单,但真正做到”自动运转”这四个字,中间踩的坑说出来能写一本书。
说实话,我用了一个类比来设计这套系统,就是编辑部。
想象你是一家科技媒体的主编。你不写稿,不改稿,不审稿。你只做一件事,调度。决定谁在什么时候做什么,然后把所有人的产出汇总,做出最终判断。
这就是 KZCQL 里的”主Agent”。它不碰文章的任何一个字,但它决定文章的命运。主Agent 的禁止事项里写得清清楚楚,禁止直接写作,禁止直接评分,禁止修改规则,禁止跳过评审直接交付。它是一个纯粹的调度者,像交响乐团的指挥,自己不演奏任何一个音符,但整场演出由它掌控。

上篇我说过,写手和审核必须分开。但光分开还不够,还得让审核的人足够多、足够细、足够狠。
所以这个”编辑部”有 10 个人。2 个写手,4 个审稿编辑,1 个质检,1 个架构师,1 个规则制定者,加上主编。一共 10 个 AI 角色,各管一摊。
它们怎么分工的?一个一个说。
W1,记者。 它的任务是写初稿。不是随便写,而是调用一套专门的写作工具(叫 khazix-writer Skill),按照预设的写作规范来生成。写完之后,W1 还要自己做一轮自检,检查字数够不够、格式对不对、有没有违反写作规范。但请注意,W1 的自检只管”写得好不好”,不管”写得对不对”。事实准确性不是它的事。就像报社里的记者,写完稿子交给编辑,至于里面的事实是否准确,那是核查团队的事。
W2,文字编辑。 它和 W1 的区别在于,W1 从零开始写,W2 只负责改。而且 W2 的修改原则非常严格,每次只改 1 到 2 个最高优先级的问题,不做大改。我管这叫”外科手术”式修改。
为什么要这么限制?因为我在实际使用中发现,AI 改稿有一个致命的毛病,改一处好两处,越改越离谱。 上篇提到过,改 DeepSeek V4 的发布日期时,GPT-5.5 的正确日期反而被连带改错了。你敢信吗?改一个日期,把另一个正确的日期给改错了。如果让 W2 一次改太多地方,它改着改着就会把自己绕进去,改完之后文章可能比改之前更烂。
所以 W2 的策略是,每次只动最要命的那一两处,改完就交回去重新审。宁可多改几轮,也不要一轮改太多。这个原则在后面的迭代中被反复验证,每次 W2 试图”一次性解决所有问题”的时候,几乎都会引入新的错误。

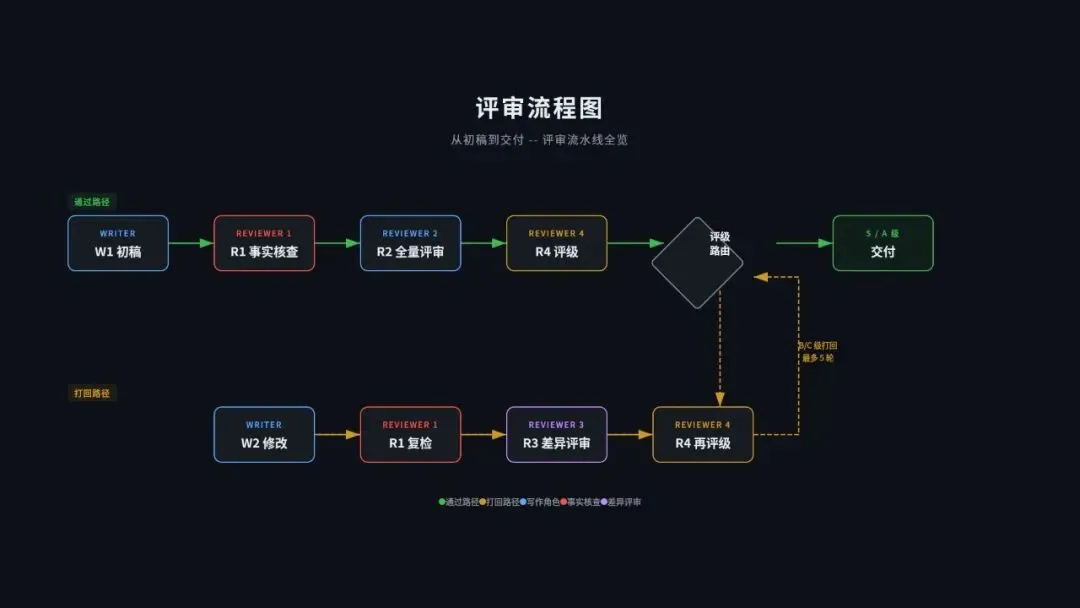
说完写手,说审稿编辑。这是整个编辑部最核心的部分,有四个人,形成一个层层递进的审查链条。
R1,事实核查员。 它是整个流程的第一道关卡。R1 手里有 18 条”一票否决”规则加 1 条严重警告,编号从 V-01 到 V-19。任何一条否决项触发,文章直接打回,后面的评审全部跳过。
这 18 条否决规则加 1 条警告覆盖了什么?日期错误、数据错误、引述错误、价格错误、事实反转、配图缺失、图文矛盾……基本上,上篇文章里出现的所有翻车类型,都被编进了规则里。每一条规则的背后,都是一次真实的翻车教训。V-18″配图内容与文章主题不符”,是配图事故之后加的。V-19″论点偏移”,是发现 AI 写着写着跑题之后加的。其中 V-15″背景膨胀”比较特殊,它不触发否决,只标记警告,但会扣分。
举个例子。V-01 是”核心事实日期错误”,V-02 是”数据/统计信息不准确”。而且 R1 不是只看文字觉得”这个日期可能不对”就完事了,对于关键事实声明,它必须联网验证。去查官方来源,确认这个日期到底对不对。
上篇那篇文章里,R1 一把就抓住了 5 个日期错误,DeepSeek V4 的发布日期、GPT-5.5 的发布日期、GLM-5.1 的发布日期、Kimi K2.6 的 GA 日期,还有一个融资日期。五个日期,五个全错。如果当时有 R1,这篇文章根本走不到发布环节。
R2,资深审稿编辑。 如果 R1 放行了,18 条否决规则全部通过,文章才会来到 R2 面前。R2 做的是 10 个维度的全量评审,满分 100 分,各维度满分不同。
这 10 个维度是 D1 标题、D2 开头、D3 内容深度、D4 结构、D5 语言风格与质感、D6 金句、D7 配图、D8 结尾、D9 事实、D10 技术规范。每个维度都有明确的评分标准,不是”我觉得还行就给 8 分”,而是逐条对照规则打分。
注意 D7,配图。R2 不是看一眼图觉得”还行”就打分,而是逐图检查,图片文件存不存在、图片内容和对应段落的语义是否匹配、图片风格是否和整体统一。上篇那篇文章,R2 给 D7 打了 0 分,评语是”配图缺失,无法评分”。后来补了图,但内容和文字对不上,再后来文字改了图没跟着改,三次翻车,三次都是不同类型的失败。
R2 还有一个特点,它只提问题,不给修改建议。它告诉你”第三段逻辑不连贯”,但不会告诉你”建议改成什么什么”。修改是 W2 的事,R2 只负责诊断。这个分工很重要,如果评审者同时给出修改方案,W2 就会偷懒,直接照搬 R2 的建议,而不是自己思考怎么改最好。

R3,校对员。 这个角色只在迭代阶段出现。当 W2 根据评审反馈修改完文章之后,R3 不做全量评审,只看 W2 改了哪些地方。它的核心问题是,上轮评审指出的问题,你解决了没有?有没有在修改的过程中引入新的问题?
R3 有一条很硬的规则,改动超 30%,退回全量审。 如果 W2 的修改幅度超过了文章总篇幅的 30%,R3 会自动拒绝评审,把文章退回给 R2 做全量评审。为什么?因为改动太大意味着这不是”修改”,而是”重写”。既然是重写,就应该按新文章的标准重新审一遍。
这个机制是为了防止 W2 借”修改”之名行”重写”之实。重写是 W1 的活,W2 不能抢。职责边界必须清晰,否则整个流程的信任链就会断裂。
R4,编委会/终审。 它是评审流程的最后一关。R4 不直接看文章,而是汇总 R1、R2、R3 的评审报告,给出一个综合评级,S、A、B、C、D、F。
S 是 95 分以上,卓越,可以直接发。A 是 85 到 94 分,优秀,通过评审。B 是 75 到 84 分,良好,需要 W2 再改改。C 是 65 到 74 分,合格但需要较大修改,走 W2 迭代。D 是 60 到 64 分,勉强及格,退回 W1 重写。F 是不及格,同样退回 W1 重写。
只有达到 A 级及以上,文章才会进入人工终审,也就是我亲自看一遍,确认没问题之后才发。B 级及以下的文章,AI 系统不会让它走到我面前。
到这里,你可能已经发现了一个问题,谁来监督这些评审自己不犯错?
说真的,R1 到 R4 都是 AI。AI 会犯错,评审 AI 也会犯错。如果 R2 给了一篇烂文章 90 分,怎么办?如果 R1 漏掉了一个日期错误,怎么办?如果 R3 和 R2 对同一段修改给出了完全相反的评价,听谁的?
这就是 I1 存在的理由。
I1,质检/纪检。 它是整个系统里最特殊的一个角色。I1 不参与正常的写作-评审流程。它平时”隐身”,只有在特定条件下才会被激活,人类主动要求审查、评审结果出现异常、或者发生了事故。
I1 的调查报告不经过主Agent,直接呈报给人类。它是整个系统里唯一一个可以直接”越级上报”的角色。这个设计是刻意的,如果 I1 的报告要经过主Agent 过滤,那主Agent 就有可能隐瞒对自己不利的信息。独立汇报渠道是督察有效的先决条件。
举个例子。有一次,系统在归档文章的时候,发现配图文件没有被正确保存到归档目录。这看起来是一个小问题,但 I1 被激活之后做了全面调查,发现这不是偶然事件,配图归档流程存在系统性漏洞,而且这个问题在之前的多次迭代中都没有被发现。I1 的调查报告直接交到了我手上,促发了一次系统性的规则修复。
I1 只调查,只汇报。 这种独立性是它能发挥作用的关键。如果 I1 也参与正常流程,它就会被流程”同化”,失去独立的判断力。就像纪检委不能同时兼任业务部门的主管一样。

最后两个角色,不在编辑部的日常运作里,但在系统的长期进化中至关重要。
A1,技术顾问。 它从”元层”审查整个系统的架构健康度。什么叫元层?就是它不审文章,它审”审文章的系统”。A1 有一套八维度的评分框架,从规范一致性、流程完整性、规则覆盖度、职责清晰度等八个方面给系统打分。
如果 R2 是给文章打分,A1 就是给 R2 本身打分。它问的问题是,R2 的评审标准够不够清晰?R1 的否决规则有没有遗漏?W2 的修改流程有没有设计缺陷?整个系统的运转效率如何?
A1 也不直接修改任何东西。它只出诊断报告,列出问题和优先级,然后交给 E1 去执行。
E1,规则制定者。 它根据 A1 的审查建议来修改系统规则。A1 说”配图审查规则不够完善”,E1 就去设计新的配图规则;A1 说”R3 的回退机制需要量化标准”,E1 就去制定具体的百分比阈值。
E1 有一个硬性约束,不能凭空创造规则。每一条规则变更都必须有审查依据,要么来自 A1 的架构审查报告,要么来自人类的反馈。没有依据的规则,E1 无权添加。这个约束防止了”规则膨胀”,如果每个 AI 都可以随意加规则,系统很快就会被互相矛盾的规则搞瘫痪。

好,10 个角色介绍完了。它们怎么协作?
一篇文章的完整生命周期是这样的,W1 写初稿,交给 R1 做事实核查。R1 用 18 条否决规则逐项检查,全部通过之后,文章进入 R2 的全量评审。R2 从 10 个维度打分,然后 R4 汇总所有评审意见,给出综合评级。
如果评级是 A 级或以上,文章进入人工终审,我看完没问题就可以发了。
如果评级是 B 级,文章进入迭代循环,W2 根据评审反馈做精准修改,R1 复检(或者 R3 做差异评审),然后 R4 再评级。这个循环最多跑 5 轮。如果 5 轮之后还没达到 A 级,系统会强制退出循环,把文章交给我来决定怎么处理。
如果评级是 C,文章走 W2 的迭代修改流程,和 B 级类似,但需要改的更多。如果评级是 D 或 F,文章直接退回给 W1 重写,评级太低说明问题不在细节,而在根本,初稿的方向或质量就有大问题,小修小补没用。
这就是整个编辑部的运作方式。10 个 AI,各司其职,互相制约。写手不能审自己的稿,评审不能改文章,质检独立于流程之外,架构师只看系统不看文章,规则制定者不能凭空造规则。
不是换更强的AI,而是分工。
这套系统搭好之后,我做的第一件事就是让它跑一遍,用上篇那篇满是错误的 DeepSeek V4 文章作为测试用例。结果如何?
编辑部搭好了,但第一次”出刊”还是出了问题。
你猜怎么着,架构审查只打了 74 分。
74 分是什么概念?及格线以上,但离”好用”还差得远。A1 的体检报告列出了 15 个问题,其中最严重的三个是,人类反馈闭环缺失、验证链路断裂、规则覆盖不足。
怎么说呢,编辑部虽然搭起来了,但运转起来磕磕绊绊。有的环节有流程但没闭环,有的规则写了但没执行,有的角色分工清楚但边界模糊。就像一个新成立的团队,每个人都知道自己该干什么,但配合起来总是差那么一点。
从 74 分到真正能用的系统,中间还差了好几轮进化。
如果你也在搭类似的系统,或者对这套编辑部的某个角色特别感兴趣,评论区聊聊。
下一篇,我们看看这份 74 分的体检报告到底写了什么。