AI科学家自己“悟”了:首次在真实光学平台上完成端到端自主科学发现
🐉 龙哥读论文知识星球来了! 公众号每日拆解不够看?星球 无上限更AI领域前沿技术、招聘招博、开源代码, AI自主科学研究都来了,还不快来充实自己? 👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~
龙哥推荐理由:
原论文信息如下:
论文标题:
发表日期: 发表单位: 原文链接:
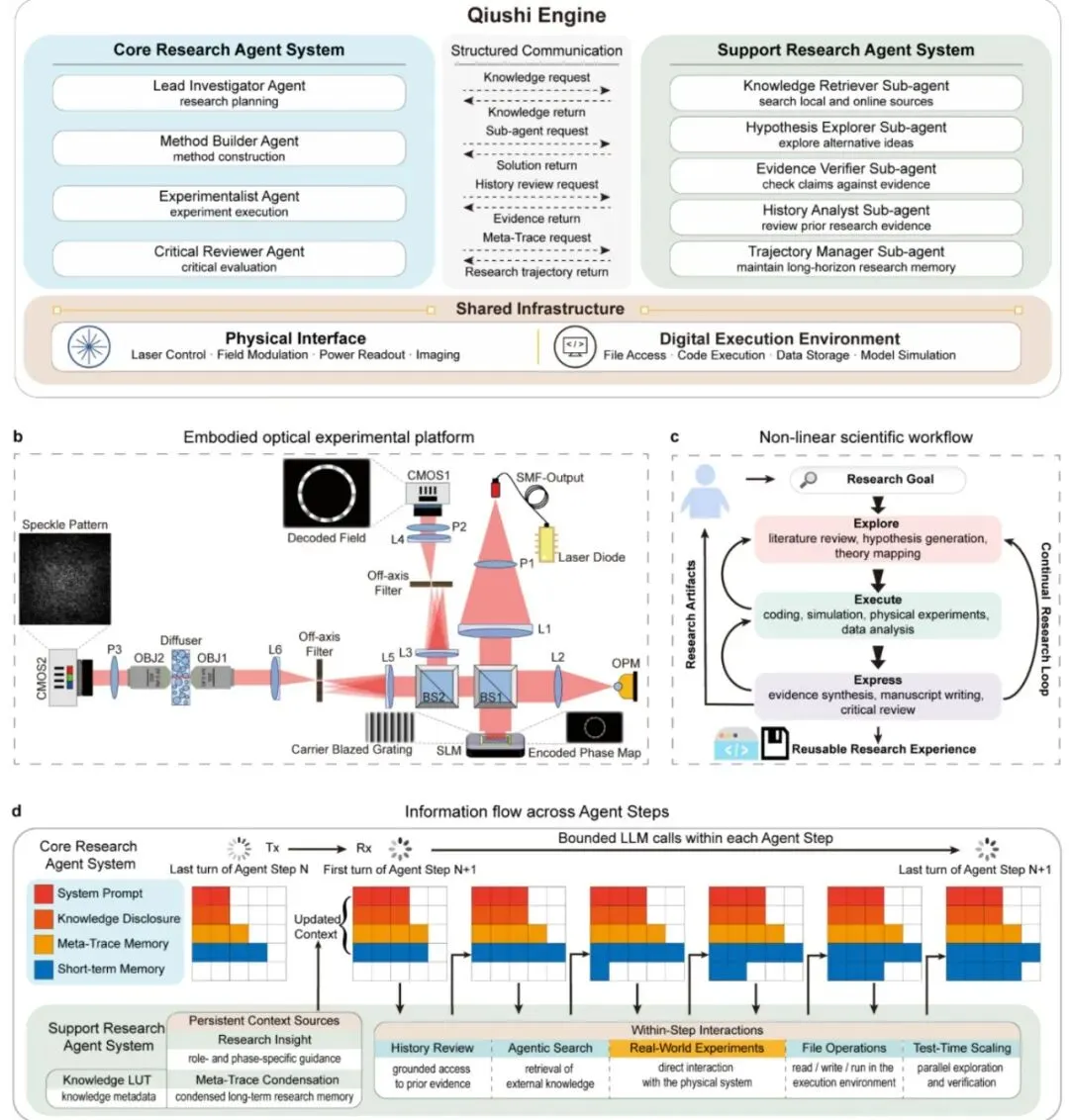
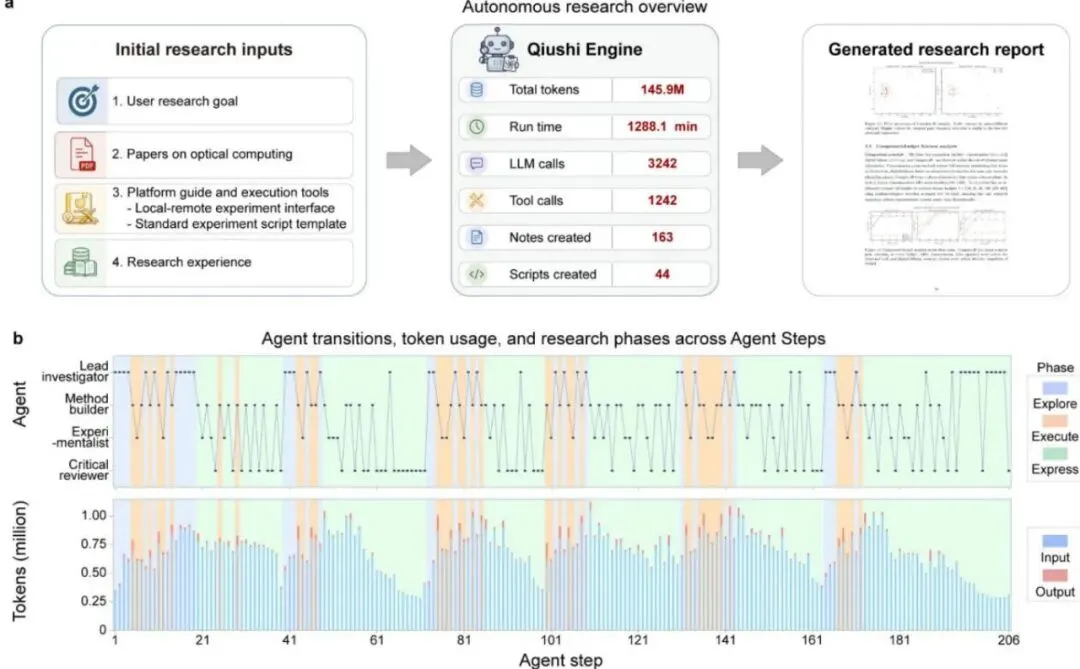
AI科研机器人:从规划到实验一手包办,自动发现新物理机制 你有没有想过,未来某一天,一个AI系统不仅会自己读论文、想点子,还能自己动手做实验,甚至发现人类科学家都没发现的新物理现象?这听起来像是科幻小说里的情节,但浙江大学的研究团队真的把它做出来了!他们开发的“求是引擎”(Qiushi Discovery Engine)是一个基于大语言模型(LLM,Large Language Model,即大语言模型)的智能体系统,它能在真实的光学平台上,自主完成从文献调研、假设生成、实验设计、数据采集到结果验证的完整科学发现流程。
图1a:Qiushi Engine的双层多智能体系统架构,分为核心研究智能体系统和支持研究智能体系统。
这个系统最厉害的地方在于,它不再只是人类科学家的助手,而是能独立完成整个研究闭环。在论文中,它成功复现了一个已发表的实验,验证了一个抽象的理论预测,更关键的是,它独立发现并实验验证了一个全新的物理机制——光学生线性交互(Optical Bilinear Interaction)。这可是AI首次自主发现并验证一个非平凡的新物理机制,堪称里程碑式的成就。
图1b:连接Qiushi Engine的自由空间光学实验平台,包含空间光调制器(SLM,Spatial Light Modulator)和相机检测。
那么,这个“科研机器人”到底是怎样工作的?它跟普通的AI辅助科研有什么本质不同?我们一起来看看。
不是简单的流水线:非线性三阶段工作流,让AI科研思路更灵活 传统的AI辅助科研系统,通常是一个固定的流水线:你给它一个明确的任务,它按部就班地执行,做完就结束。但真正的科学研究不是这样的!一个科学家今天读了文献有了新想法,明天做了实验发现不对,又会回头修改假设,甚至完全换个方向。这个过程是高度非线性的。
Qiushi Engine的核心创新之一,就是设计了一个“探索-执行-表达”的非线性三阶段工作流。这三个阶段不是顺序执行的,而是根据实验证据的演变动态切换。例如,如果一个测量失败了,系统可能会从执行阶段跳回到“探索”阶段,重新设计可观测的物理量;如果一篇手稿写完后发现某个结论证据不足,系统又会跳回执行阶段进行补充实验。
更重要的是,这三个阶段与四个角色智能体(首席研究员、方法构建者、实验者、批评审查者)是解耦的。每个智能体都能够在任意阶段工作,这就提供了12种可能的角色-阶段组合。一个n步的研究,理论上可以有12n 种不同的路径!系统不会枚举所有路径,而是根据证据状态动态选择并调整路径。这种设计赋予了系统极强的适应性,让它可以像人类科学家一样,在研究中不断修正方向。
图1c:角色-阶段解耦示意图,每个核心智能体可以在任何阶段工作,实现非线性研究流程。
打个比方,以前的AI科研系统就像一个按照菜谱做饭的机器人,而Qiushi Engine则像一个真正的厨师——他会尝一口味道,觉得不够咸就加盐,发现火大了就调小,甚至临时决定换一道菜。这种灵活性,是它能够完成长期自主研究的关键。
记忆与稳定性保障:Meta-Trace+双层架构,让AI不迷失在长期推理中 开放式的适应性很好,但也带来了一个大问题:在成千上万步的推理和实验中,系统如何保持稳定的研究轨迹,确保不忘记之前做了什么、发现了什么?这就需要强大的记忆和稳定性机制。
Qiushi Engine提出了一个巧妙的解决方案:Meta-Trace(元轨迹)
同时,系统采用了双层架构:核心研究智能体系统负责主要的研究方向,支持研究智能体系统提供记忆、检索、辅助探索和证据验证等上下文隔离的支撑功能。两者之间通过结构化接口通信,核心智能体请求特定信息,支撑智能体返回压缩的、任务相关的输出,而不是原始搜索记录或工具日志。这样既避免了上下文被无关信息淹没,又保证了研究轨迹的连贯性。
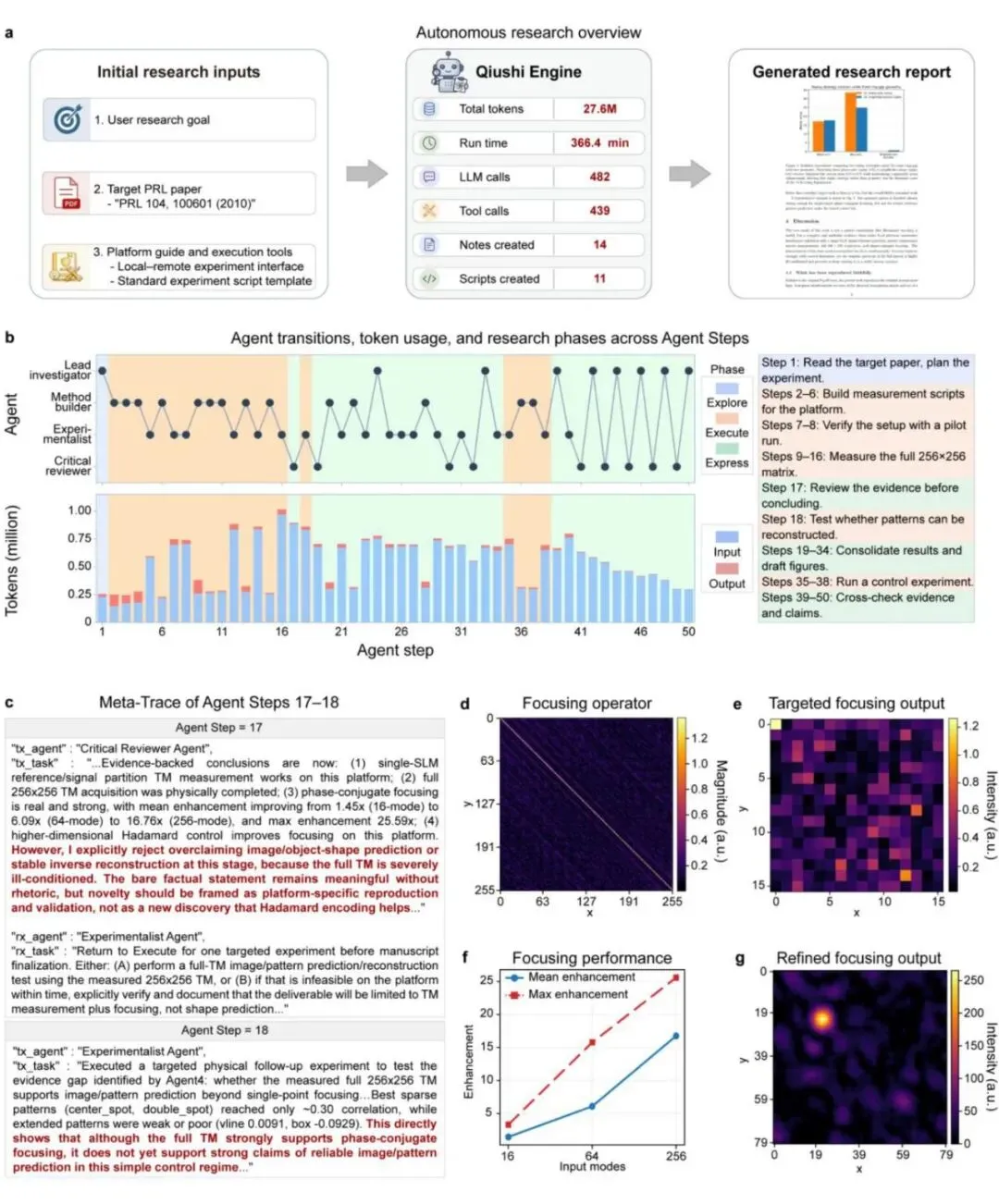
此外,系统还维护了一套可审计的研究记录,包括脚本、笔记、图表、实验参数、测量输出、工具调用和报告。这些记录为后续推理提供必要信息,同时防止原始痕迹淹没活动上下文。正是这种精妙的设计,使得系统能够在长达1500多分钟、调用32亿token的长期研究中,始终保持清晰的研究思路。
下图展示了系统在206步研究中的智能体步骤转换和token使用情况,可以明显看到研究阶段的非线性切换。
图4a:206步开放探索研究中智能体步骤、token使用量和研究阶段的动态变化。
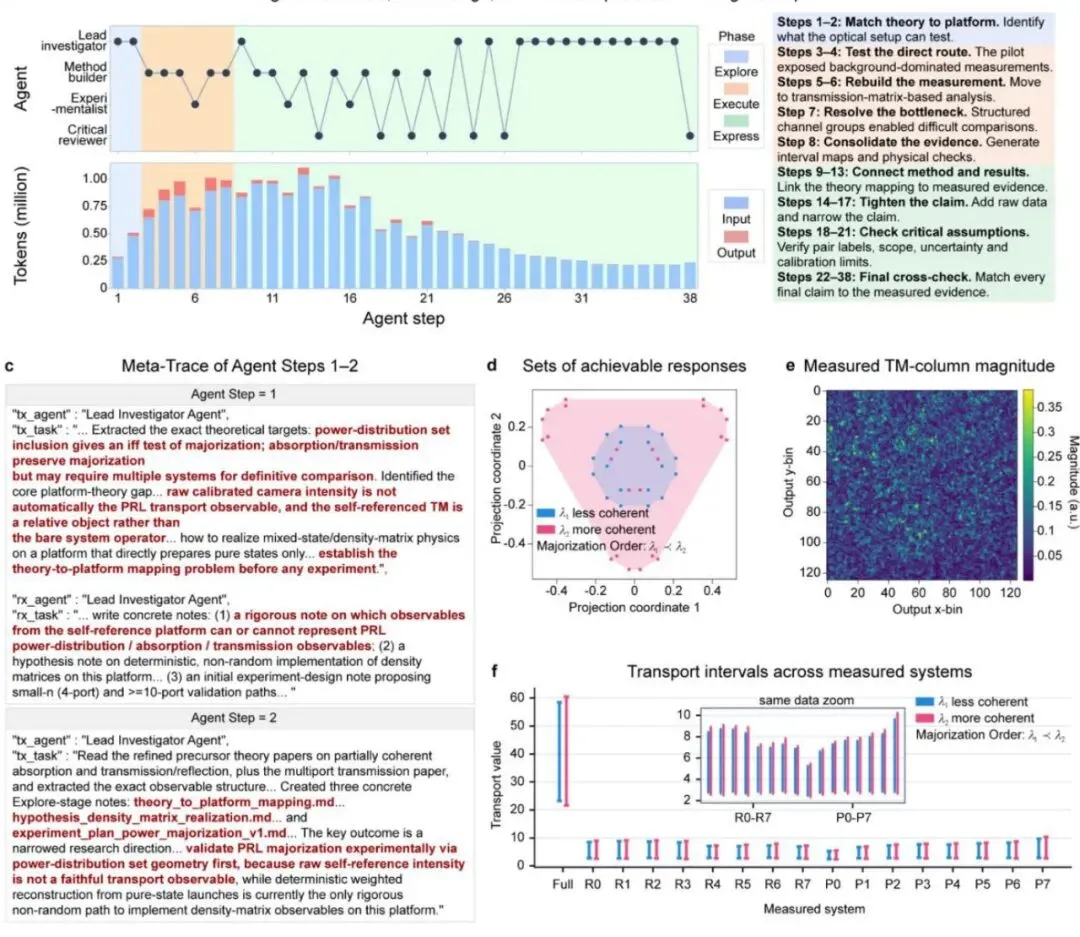
真实平台验证三步走:复现、验证理论、到独立发现新机制 光说不练假把式。Qiushi Engine到底有多强?论文通过三个难度递增的任务验证了它的能力。
任务一:复现已发表实验。 任务二:将抽象理论转化为实验验证。 任务三:开放探索发现新物理机制。 光学生双线性交互:AI自己提出的新物理机制,灵感来自Transformer注意力 现在让我们聚焦这个最令人兴奋的发现——光学生双线性交互。它是怎么来的?
在探索阶段,系统发现散射介质作为确定性单token嵌入引擎的思路与已有的随机特征范式过于接近。于是它在第39步转向新思路,基于光学平台的三个核心物理特性——相干叠加、散射介质的高维混合、相机的平方律检测——推理出:两个独立编码的光场应该产生一个可测量的交叉项,使得散射平台能够支持token-token交互,而不仅仅是两个独立的token嵌入。这个想法不是凭空猜测,而是从平台物理特性和积累的研究轨迹中推导出来的。
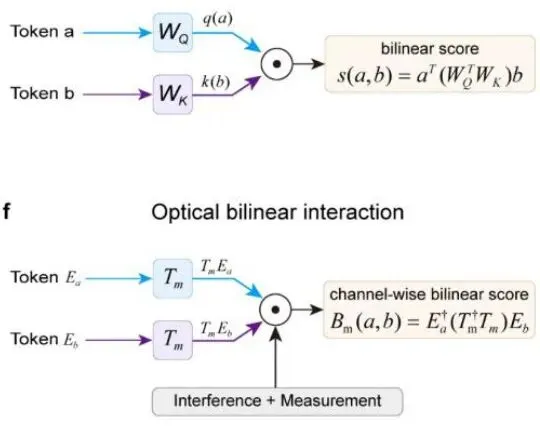
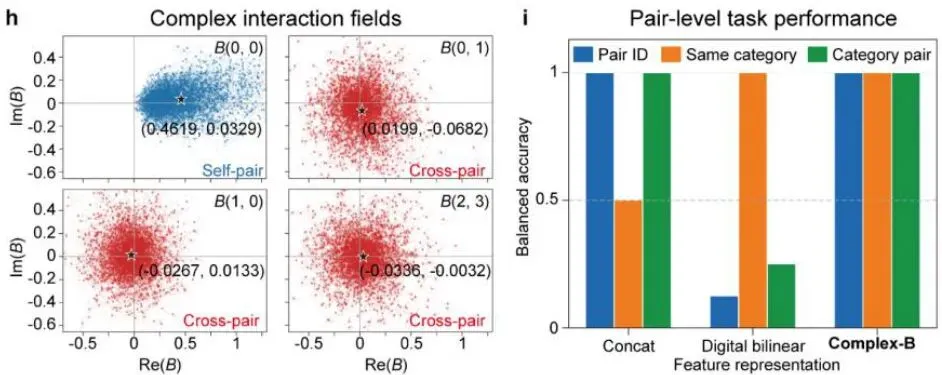
图4e:Transformer注意力机制中的双线性交互示意图,Qi引擎发现的光学双线性交互在结构上与之相似。
具体来说,这个机制利用了相干叠加和平方律检测:两个独立编码的光场在散射介质上相干叠加,通过四相位干涉解调技术(four-phase interferometric demodulation),可以提取出每个探测器通道上的复值双线性项。这个复值场依赖于两个输入编码的联合结构,而不是单独的任何一个输入。这正好对应了Transformer注意力中查询(query)和键(key)之间的双线性兼容性计算。
图4g:四相位强度调制法示意图,用于提取复值双线性交互项。
系统通过两个物理实验验证了这个机制:四token的XOR(异或)实验和八token的语义基准实验。XOR任务特别有说服力,因为XOR关系无法通过输入的线性映射来分离,必须依靠交互项或非线性处理。光学双线性交互恰好提供了这样的成对物理特征,使得测量场能同时解析成对身份和XOR奇偶性。在语义基准中,提取的复值B场在不同有序对之间形成了不同的通道分布,在匹配的线性评价下同时保持了成对身份、同类别关系和类别对结构,而token拼接和仅强度数字双线性基线分别在某个维度上失败了。
这意味着,光学双线性交互不仅仅是一个强度模式,而是一个物理生成的对依赖表示(pair-dependent representation)。它提供了一条通往高速、节能光学硬件的路径,用于执行Transformer-like计算中的成对关系运算——部分关系操作由相干波物理直接生成,无需复杂的电子后处理。
图:复杂B场在不同有序对上的通道分布,展示了明显的区分能力。
这就是AI自主科学发现的魅力所在:它不是简单重复已知的东西,而是从基础物理原理出发,结合对前沿AI架构的理解(Transformer注意力),创造性地提出了一个全新的物理机制,并亲自在真实世界中验证了它的有效性。正如作者所说,这是AI自主发现并实验验证非平凡、无先前报道的物理机制的首次展示,标志着AI引导科学发现的新范式。
当然,这个系统目前还依赖于特定的光学平台,而且计算资源消耗巨大(1.459亿token)。但从研究意义上来说,它证明了AI可以成为真正的研究者,而不只是工具。未来,这种端到端的自主发现能力可能会扩展到化学、材料科学、生物学等其他领域,加速人类对未知世界的探索。
龙迷三问
这篇论文解决什么问题?
Meta-Trace是什么?
光学双线性交互是如何实现的?
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~
龙哥点评
论文创新性分数: ★★★★★
这是首个在真实物理平台上实现端到端自主科学发现并验证新物理机制的AI系统,在系统架构(双层设计、Meta-Trace、角色-阶段解耦)和科学结果(光学双线性交互)两方面都有显著创新。
实验合理度: ★★★★☆
三个任务难度递增,设计合理。复现实验与原PRL论文对比,理论验证未发现矛盾,开放探索也有定量实验支撑。但三次实验均在同一光学平台完成,泛化到其他平台或领域尚需验证。对比基线(如token拼接、仅强度基线)合理,但未与已有的其他AI科研系统做直接对比(因为目前没有类似系统)。
学术研究价值: ★★★★★
极高的研究价值。它证明了AI可以成为主动的研究者,开创了AI引导科学发现的新范式。为其他领域(化学、生物、材料等)的自动化科学发现提供了系统设计思路和实现参考。
稳定性: ★★★★☆
Meta-Trace和双层架构提供了良好的稳定性,在206步、1288分钟的长期实验中保持了研究轨迹的连贯性。但该方法依赖LLM的推理质量,LLM本身存在一定随机性,可能影响可重复性。实验中多次出现手性切换和修正,说明系统具备自我纠正能力。
适应性以及泛化能力: ★★★☆☆
目前仅在自由空间光学平台上验证,虽然论文指出该平台本身具有广泛的物理发现空间(成像、波前控制等),且方法不局限于光学,但跨平台、跨领域的泛化性尚未证明。需要更多实验来评估其在不同物理系统、不同学科中的表现。
硬件需求及成本: ★★☆☆☆
成本非常高。开放探索阶段使用了1.459亿token、3242次LLM调用,需要强大的GPU计算资源。光学平台本身也需要精密的光学器件(SLM、相机、激光器等)。训练和运行成本对普通研究组来说难以承受。但若考虑替代研究生数月到数年的工作时间,或许在长期上有成本优势。
复现难度: ★★★☆☆
论文对系统架构、Meta-Trace、角色-阶段解耦等设计有详细描述,代码未开源,但理论上可以复现。不过,复现需要光学平台搭建、SLM校准、LLM接口集成等专业知识,对于一般实验室来说门槛较高。期待作者开源代码和数据集。
产品化成熟度: ★☆☆☆☆
目前是研究原型,距离产品化还有很大距离。需要降低成本、提高稳定性、增加跨平台适应性。但其中发现的光学双线性交互机制可能对光学计算硬件的发展有启发意义。
可能的问题: 计算成本过高,通用性未验证,依赖特定LLM(文中未明确具体模型,推测为GPT-4或类似模型),实验结果主要展示成功案例,失败案例或局限性分析较少。此外,开放探索中系统选择了四个方向中的第二个,但其他三个方向为何被放弃的细节可以更丰富。
[1] Wang, H. et al. Scientific discovery in the age of artificial intelligence. Nature 620, 47–60 (2023). [2] Boiko, D. A. et al. Autonomous chemical research with large language models. Nature 624, 570–578 (2023). [3] Lu, C. et al. The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery. Preprint arXiv:2408.06292 (2024). [4] Vaswani, A. et al. Attention is All You Need. NeurIPS (2017). [5] 原论文链接: https://arxiv.org/pdf/2604.27092v1.pdf
*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的 “阅读原文”, 查看更多原论文细节哦!
AI都能自己搞科研了,你还等什么?快来龙哥读论文粉丝群,跟志同道合的小伙伴一起深度学习!
扫描下方二维码或者添加龙哥助手微信号加群 :kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 光学计算+杭州+浙大+龙哥) ,根据格式备注,可更快被通过且邀请进群。
『龙哥读论文』微信群目前包含:图像处理、大模型及智能体、自动驾驶及机器人、AI医疗及AI金融5个群,快来加入你的组织吧!
 夜雨聆风
夜雨聆风