 夜雨聆风
夜雨聆风





大数据平台AI化改造日记 4:OpenClaw * Athena —— 数据工厂 CLI 上线后的第一次回归测试
工具开发完不叫完。Agent 真的能独立用它排查线上故障、审代码、分析趋势——才算验收通过。
引子
前几篇把 CLI、API Key 认证、Skills 体系都搭好了——代码在 GitLab,测试也绿了。工具开发到此告一段落;真正让人心跳加速的是下一关:Agent 能不能靠这套 CLI 和 Skills,独立把活干漂亮?
Hint 是否好懂、命令是否顺手、关键时刻能不能扛事——我既兴奋,也心里打鼓。
于是把第一项实战交给了 OpenClaw :用 cli-anything-athena,独立完成 Athena 数据工厂的全平台巡检与故障诊断。
这也是 CLI 上线后的第一次回归测试。
一、全量功能回归——21 项全覆盖
我让 OpenClaw 逐条验证 CLI 命令。不是”跑一遍看有没有报错”——而是带着业务验证——查真实的项目 2 数据、看最近的实例日志、拉血缘图谱。
OpenClaw 交出了一份 21 项命令全覆盖的测试报告:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
其中有几个关键细节:
• 实例日志查询——有一个 ads_hhcoin_fafang_details_h 的 HIVE SQL 任务连续 8 天失败,已重跑 4 次。Agent 直接拉取了第 4 次重跑的日志,在 88KB 的日志里定位到 SPARK_SQL_EXECUTION_ERROR: MISSING_AGGREGATION——SQL 里 GROUP BY 列和 SELECT 列不匹配。不是临时性故障,重跑多少次都会失败。Agent 没有盲目建议重跑,直接判为代码 bug。
• athena_spark_sql 引擎踩坑——这个队列名字里带 “spark”,但实际引擎是 Hive(engine=1)。Agent 按 Skill 指引先用默认 engine=1 试 Hive,失败后自动切 engine=2 试 Presto,最后报出”Presto 引擎挂起中”的精准提示。这个自动重试逻辑是我们在 CLI 里刚加的——Agent 不需要知道引擎类型,CLI 会自己试。
先别高兴——命令能跑通,不等于语义对。这个坑埋得很深,第五节再说。
二、第一战:全平台 7 日失败巡检
Skill 刚验证完,我给了第一项生产任务:检查近 7 天所有项目的失败实例。
OpenClaw 遍历了 48 个项目,逐项拉取失败实例(run-state=5)。结果:
• 46 个项目零失败 ✅
• 2 个项目有问题,共 14 个失败实例
快速锁定了关键异常:
|
|
|
|
|
|---|---|---|---|
|
|
|
ads_cc_fenxiao_ceshi_classroom_detail_s |
|
|
|
|
class_quality
push_left_hour_tag(2次) |
|
OpenClaw 没有停在”有 14 个失败”这个数字上。 它进一步拉取了每个失败实例的完整日志,给出了根因级判断:
class_quality — MySQL 唯一键冲突
|
|
链路:Hive → Seatunnel2(Spark) → JDBC → MySQL。Seatunnel 用 INSERT(非 UPSERT),源表同一唯一键多条记录 → 目标 MySQL 报唯一键冲突。连续 8 天都是同一块石头绊倒。
OpenClaw 给出三方案对比:A. Sink 改 UPSERT(低风险)、B. 源端 ROW_NUMBER 去重、C. 目标表改键(需业务确认)。建议 A+B 组合。
ads_cc_fenxiao_ceshi_classroom_detail_s — 每周一次,HOUR 级别的超时
修复方案值得商榷,但诊断本身已经够用——直接把分析转发给负责人就够了。
三、第二战:每日天调度任务失败原因分析
每天早上,监控脚本会扫一遍天调度任务的运行情况。过去报警一到,还得靠人一条条去 Airflow 翻日志、猜根因。这次想验证一件事:告警能否直接交给 Agent 处理。
5 月 16 日 7:50,飞书来了三条报警——只有任务名和责任人,没有日志,更没有根因。
按老办法:打开 Airflow → 找 DAG → 展开 Task → 点 Log → 人工分析,一条起码 10 分钟。
我只回了一句:「通过 Athena skill 查看。」
OpenClaw 随后走了这样一条链路:
1. class_quality(小张,项目 12) — 秒级定位。直接查项目 12 的实例列表 → op instance list --project-id 12 --run-state 5 → op log。根因:MySQL 唯一键冲突(同上,连续 8 天)。
2. push_left_hour_tag(小张,项目 12) — 状态为”运行中”,历史耗时约 1 小时。Agent 判断:不是失败,是慢——预判 ~08:06 完成。没有触发误报。实际确实跑完了。
3. ads_operation_management_mgmt_meeting_report_chin_d_s(小李) — 这是关键。在项目 6(Spark_CC,小李所负责的项目)搜索无结果。OpenClaw 没有放弃,扩大了搜索范围,最终在项目 95(Finance_Governance)找到了。
拉取实例和日志后,根因浮出水面:
|
|
任务代码最后修改时间:2026-05-15 17:16——前一天下午刚改。Agent 判断:高度疑似这个修改引入了列不匹配。修复只需在 INSERT SELECT 中补一行 t.date_of_mon_first。
三任务汇总
|
|
|
|
|
|
|---|---|---|---|---|
class_quality |
|
|
|
|
meeting_report_chin |
|
|
|
date_of_mon_first |
left_hour_tag |
|
|
|
|
从收到报警到完整诊断,不到 5 分钟。 过去至少要 10-15 分钟——而且还需要知道”去哪个项目找”这个前置条件。
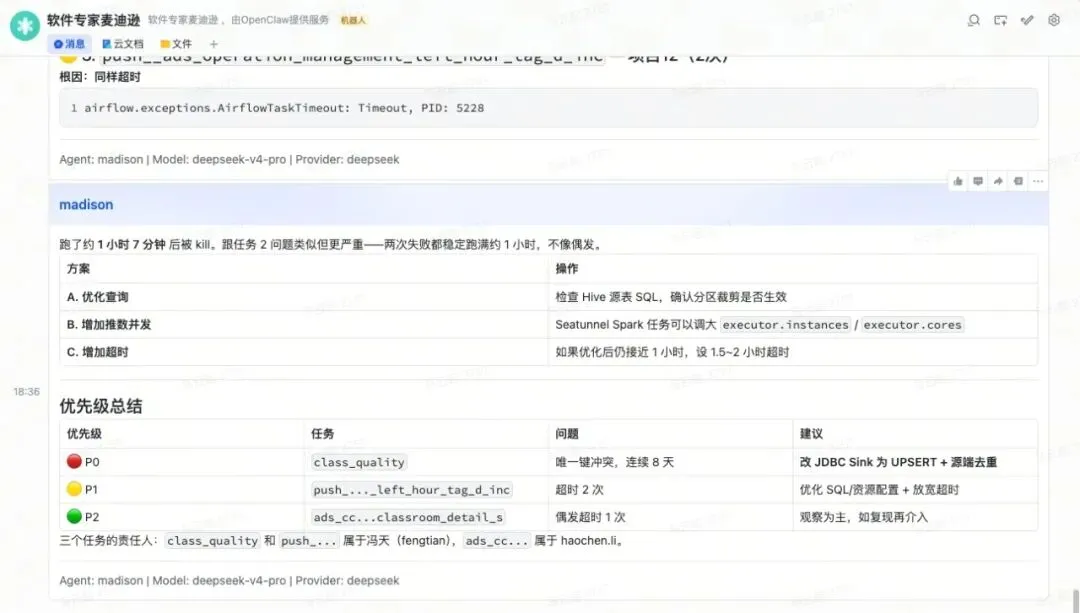
▲ 飞书中 Agent 给出的根因分析与优先级总结
四、不只是排障——SQL 代码审查
查完根因后,我让 OpenClaw 对小李的 meeting_report_chin 这个 500 行的 SQL 做完整代码审查。
OpenClaw 先肯定了设计的合理之处:骨架表驱动(Calendar × BU)、共享中间 CTE、注释规范、占位机制。
然后给出了分级问题清单:
|
|
|
|
|---|---|---|
|
|
date_of_mon_first 缺失) |
|
|
|
renewal_actual_refund_cnt
renewal_actual_gmv_refund_gmv 嵌了完全相同的 ~30 行子查询 |
|
|
|
|
|
|
|
|
|
|
|
class_hour_consumption_actual
|
|
优化建议有具体可执行的 SQL 重构方案——不只是”这里不好”,而是”改成这样”。
这次审查的价值不在于发现了 bug——那个 bug 已经自己暴露了。价值在于找到了藏在正常运行的代码里的 4 个技术债和 1 处重复扫描。这些是当下不会爆炸的地雷,但排爆越晚代价越大。
从此,「把 SQL 优化一下」不再只是数仓人员对业务的一句空话——而是带着优先级、影响说明和可执行改法的审查报告。
五、一个”接线错误”的暴露
回归测试中,OpenClaw 在分析提数记录时发现了一个奇怪的模式:我的 46 条查询里,大量用了 Presto(engine=2),Hive(engine=1)反而用得少。它据此建议”探索性查询用 Presto,速度快 10-50 倍”。
但这个建议是错的——问题不在于我偏爱哪个引擎,而在于 CLI 的 query engines 命令接错了口子。
在开发 CLI 时,Agent(Claude Code)根据后端 API 文档找到了一个叫 /engineStyle 的接口,以为这就是”可用的引擎类型列表”。但实际上,/engineStyle 返回的是当前用户在前端 UI 里保存的个人偏好配置——不是平台实际支持的引擎。
真实的引擎类型码表存在前端源码里,而不是后端接口里。打开 src/components/sqlQuery/sqlQuery.vue:562-566:
| engineList
|
Spark 引擎已经被注释掉——整个平台目前只支持 Hive 和 Presto。但 Agent 通过 /engineStyle 拿到的是一个可能含 Spark 的用户偏好记录,导致 query engines 命令返回了错误的信息。
这是 AI 辅助开发的一个典型陷阱:Agent 不会区分”用户的个人配置”和”平台的系统能力”。它看到了 API,调通了 API,返回了数据——但它无法判断这个数据是不是它以为的那个数据。
修复也简单——把 query engines 从调后端接口改为直接返回前端码表中的硬编码值。同时 query run 的自动引擎切换也去掉了 Spark(engine=3)。改完后,Agent 给出的引擎建议才回归正确。
这给回归测试加了一课:Agent 开发的东西,接口接线是否正确,最终需要在真实数据上验证。Agent 自己不会发现”这个接口虽然能调通,但语义不对”。
六、这次回归测试暴露了什么
工具开发阶段,我们反复测试的是”能不能调通”——一个命令能不能返回正确数据。
Agent 真实使用时,暴露的是另一层问题:
1. 环境配置是最大的隐形门槛。命令名不匹配、env var 不在会话里——这些问题在开发者本机不存在,但在 Agent 的执行环境里是致命的。后续在 Skill 里加了明确的检查步骤。
2. 输出格式比功能更重要。Agent 不靠”看屏幕”判断结果,它靠解析 JSON 里的 ok 字段。如果输出格式不统一,Agent 每一步都要多写判断逻辑——而每一次额外判断都是出错的机会。JSON Envelope 改造({ok, data, meta})在这次回归中得到了充分验证。
3. Skills 的 depth matters。14 个 references 的拆分让 Agent 可以按需加载,而不是一次吃掉 361 行的 SKILL.md。每条 reference 里的 platform-specific 知识(如 athena_spark_sql 实际是 Hive 引擎)直接决定了 Agent 能不能走通。
七、写在最后
有人会问:这不就是 API 调用 + 日志分析吗?有什么特别的?
特别的不是技术,是体感。
过去:打开网页 → 登录 → 48 个项目逐一点 → 筛选失败 → 点日志 → 复制 → 分析 → 写结论。半小时起步,还得知道”去哪个项目找”。
现在:飞书上发一句话 → 2 分钟内收到完整诊断报告,含根因、影响范围、可执行的修复方案。Agent 不会因为”太多了看不完”而跳过任何一个——48 个项目、3500+ 个任务,一个不落。
这还不是终点。Agent 能在 46 条提数记录里发现你的引擎使用偏好,能在 500 行 SQL 里揪出藏在正常运行代码里的技术债,能扩搜全平台找到你以为不存在的任务——这些都是人做得到但懒得做的事。懒得做和做不到,在结果上是一回事。
AI 化改造的核心不是取代人做决策。是把重复性、遍历性、格式化的信息收集交给 Agent。人专注于判断、架构、权衡——这些 AI 还做不好的事情。
人拍板。Agent 跑腿。各司其职。
本系列文章记录了我在数据平台日常工作中逐步引入 AI Agent 的实践过程。这是第 4 篇。