 夜雨聆风
夜雨聆风





见面啦 | 44907行代码,用Openclaw打造出一套念想3年的招采数据系统
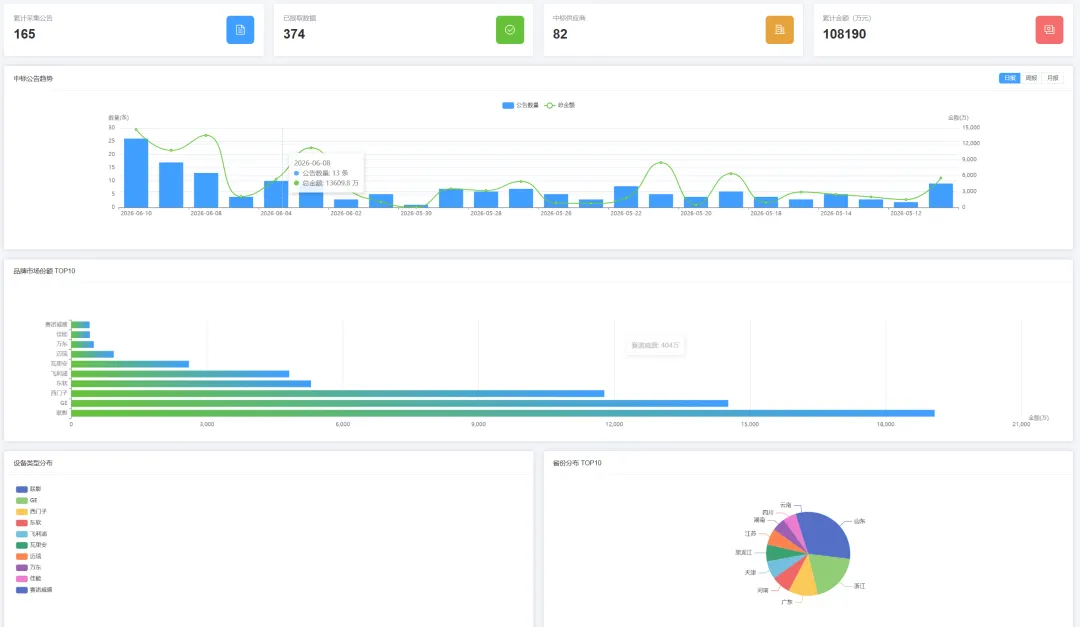
💡 一句话定位:一套定时自动采集招标采购网信息,并利用 LLM 提取结构化信息的私有情报系统。
一件事每天都在发生,你可能没注意到
每天全国各地的招标采购网上会陆续发布新公告。
其中有一类公告,数量不多,但信息密度很高:医疗设备采购公告。
某省人民医院采购一台64排CT,中标金额148万,中标供应商是***医疗,经销商在成都。
某县医院发布三维CT球管更换公告,预算33万,要求三个月内完成。
某市妇幼保健院采购彩色多普勒超声诊断仪,中标品牌是***。
这些公告散落在招标采购网上,没有汇总,没有推送,你需要每天自己去刷、去查、去复制、去整理。
一个人盯一个省,一天能看多少条?
手动找数据的三个真实痛点
我在想做一个采购情报系统的时候,第一步就是想把这些公告采集下来。
一开始以为很简单:招标采购网有列表页,有链接,有详情——爬下来存好就行了。之前尝试用八爪鱼,失败了,想过开源代码,代码编程能力不够,也没有成功。但一直记着在Github上有一个"Crawl4AI"。
在使用龙虾之前,也尝试用CodeBuddy摸索了好久,整体框架和代码也都构建好了,自己用了一阵,可惜出现一次系统乱码,整个系统文件作废。惨痛的教训,让我了解了Git备份。
真正开始做才发现,这件”简单的事”有三个绕不过去的坎:
第一个坎:信息太分散。
一个省有上百家医院,每家医院发布时间不固定,设备类型也不同。CT、MR、超声、血管造影……每一个关键词都代表一个搜索入口,但搜出来的结果依然混杂——有的是设备采购,有的是维保服务,有的是配件更换。如果你只盯着”CT”这个词,很多真实采购公告会被漏掉。
🛠️ 技术机制
:系统采用 精准关键词 + 泛化关键词+ 语义过滤三层机制解决分散问题。初始关键词覆盖卫健委标准命名(如”计算机断层扫描装置”)与行业俗称(如”CT”、”螺旋CT”),同时通过 LLM 对搜索结果进行语义相关性打分,低于阈值的结果自动过滤。
第二个坎:结构化太难。
网页上的公告是给人读的,格式五花八门。有的把金额写在中标公告标题里,有的在附件PDF里,有的字段顺序不固定。你能复制粘贴存下来,但存下来的是一堆文字,不是能查询的”数据”。
🛠️ 技术机制
:系统使用 LLM(Minimax/ Deepseek 等主流模型兼容)作为核心提取引擎。输入为公告详情页正文 HTML 清洗后的纯文本,输出为结构化 JSON Schema 格式的字段——包括:设备名称、设备类型、品牌型号、采购单位、中标/预算金额、供应商、地区、发布时间。每个字段有独立的置信度分数,低置信度字段触发人工复核标记。
第三个坎:持续跟进太累。
今天采了一批,明天还有新的,后天又有更新的。手动刷一天可以,刷一周可以,但你要的是一个持续积累的情报库,不是一周的快照。
🛠️ 技术机制
:系统基于 APScheduler实现定时任务调度,默认每日自动触发采集任务。任务状态持久化到 SQLite 数据库,支持断点续采——任务中断后重启可从上次采集位置恢复,避免重复抓取同一批次公告。
手动做这件事,边际成本太高,而且一定会有遗漏。目前有很多类似的网站,但是,他们是大而全的把所有信息都采集保存,无法针对细分领域提供精准数据。
这套系统能做什么
目前支持采集的数据范围:
设备类型覆盖,根据需求逐步扩增到医疗影像的各个方向:
• CT(计算机断层扫描)— 64排、128排、双源CT等
• MR(磁共振)— 1.5T、3.0T核磁
• 超声(彩色多普勒)— 彩超、心脏超声等

系统计划的四个核心模块:
| 模块 | 功能说明 | 技术实现 |
| 🕷️ 中标信息 | 采集设备公告,提取设备名称、品牌、型号、采购单位、预算金额、中标金额、供应商信息 | HTTP抓取 + CSS选择器解析 + LLM字段提取 |
| 🔧 招标信息 | 采集设备采购公告,提取公开招标信息 | 独立关键词策略 |
| 📊 数据报告(计划中) | 当具备足够的规范数据后,按时间、设备类型、地区、金额等多维度统计和可视化 | Pandas聚合 + ECharts图表渲染 |
| ⚙️ 调度中心 | 管理采集任务、监控运行状态、异常告警 | APScheduler + SQLite状态持久化 |
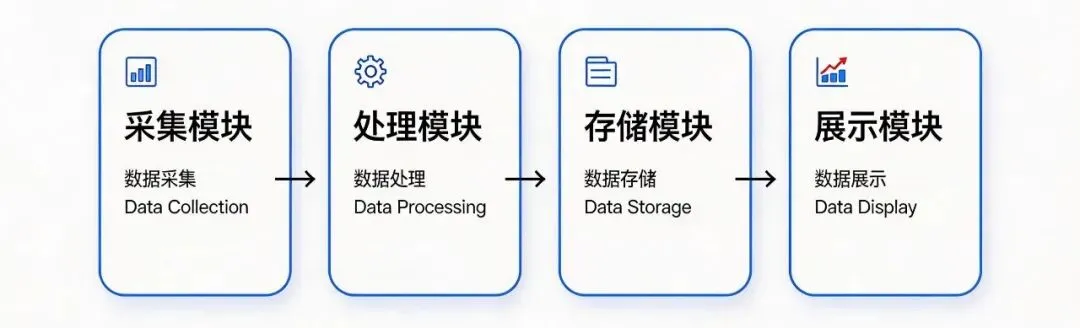
系统架构
计划安排系统在后台定时运行,每天早上7点自动采集最新公告。
采集流程分三层:
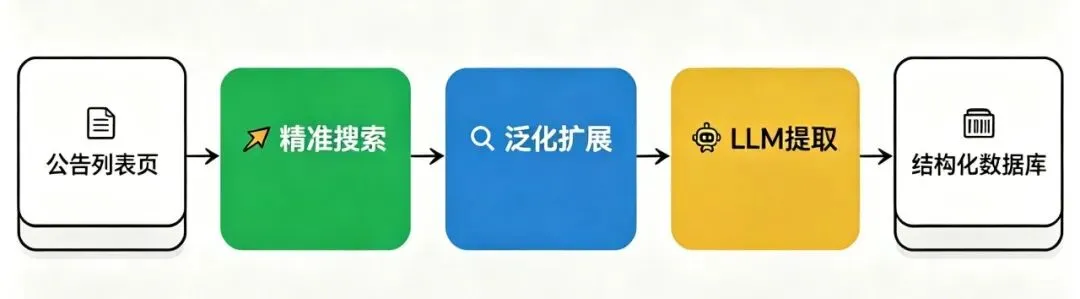
第一层:精准搜索。
用设备关键词在招标采购网上搜索标题,命中精准词的公告直接进入提取流程。
技术细节
关键词字典按设备类别分组,每组包含标准术语+行业俗称+品牌名称,例: ["CT", "计算机断层",]。命中后直接推送至 LLM 提取管道,不经过二次过滤。
第二层:泛化词扩展。
用更宽泛的描述词搜索(比如”医疗设备”),匹配到的公告再进详情页全文扫描,确认里面确实提到了目标设备才入库。
技术细节
泛化词与目标设备的关联通过 LLM 语义打分实现。每条候选公告的标题+摘要输入 LLM,输出 relevance_score: float(0~1),阈值设为 0.7,低于阈值的结果不进入提取队列。
第三层:LLM智能提取。
用大模型从详情页的正文中提取结构化数据——设备名称、品牌、型号、金额、单位——不是简单的文字复制,而是理解后的字段提取。
技术细节
提取使用结构化输出(Function Calling / Tool Use),每个目标字段对应一个 schema 定义,LLM 直接输出符合 schema 的 JSON。提取后经过规则层校验(如金额格式正则 ¥?\d+[万元/万]校验、日期格式标准化),异常数据写入review_queue表待人工复核。

三级配合的结果:精准词不漏采,泛化词不误采。
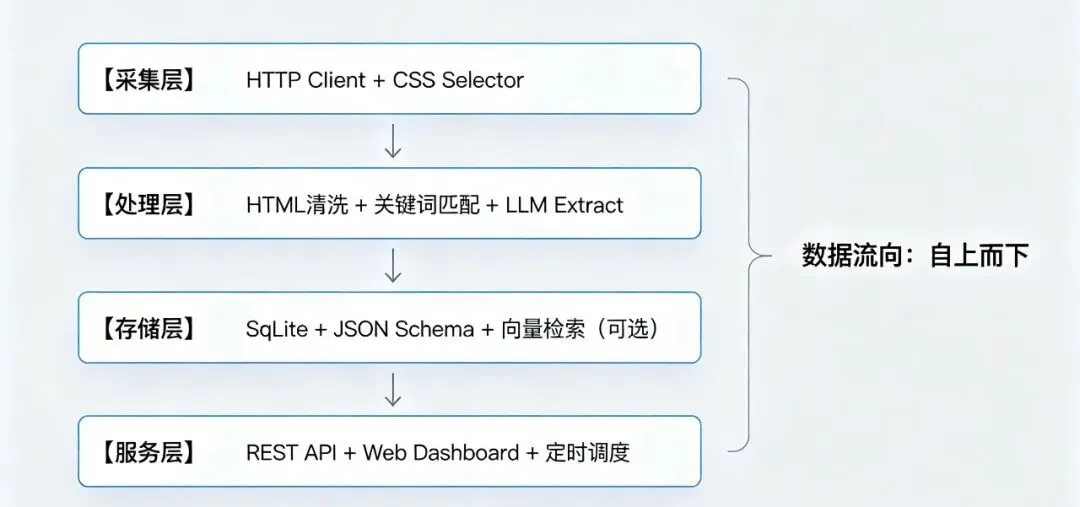
数据存储设计
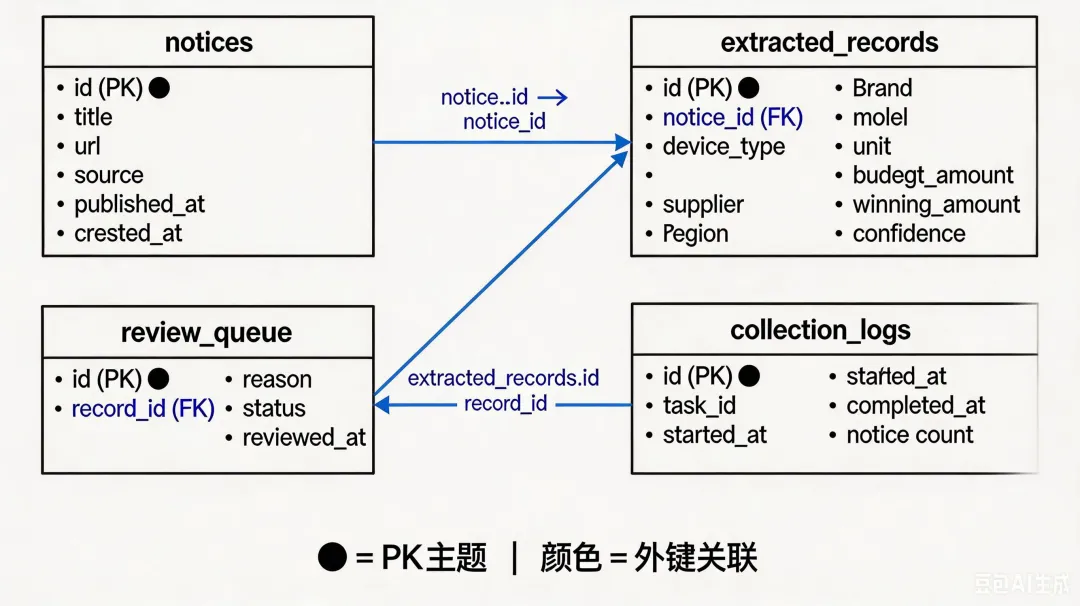
技术栈一览
| 层级 | 技术选型 | 说明 |
| 🐍 语言 | Python 3.10+ | 主力开发语言 |
| 🌐 采集 | httpx + Crawl4AI+BeautifulSoup | 异步HTTP客户端,支持连接池复用和请求限速 |
| 🧠 提取 | Minimax API / Deepseek API | 结构化输出(Function Calling),支持多模型切换 |
| 🗄️ 存储 | SQLite | 轻量级,无需部署,适合个人/小团队场景 |
| 📊 分析 | Pandas + Matplotlib / ECharts | 数据清洗、多维统计、图表渲染 |
| ⏰ 调度 | APScheduler | 轻量级定时任务框架,支持cron表达式 |
| 🌐 服务 | FastAPI | 可选:对外暴露RESTful API和Web界面 |

实际运行效果
40天后,系统当前状态:

一条真实入库记录长这样:
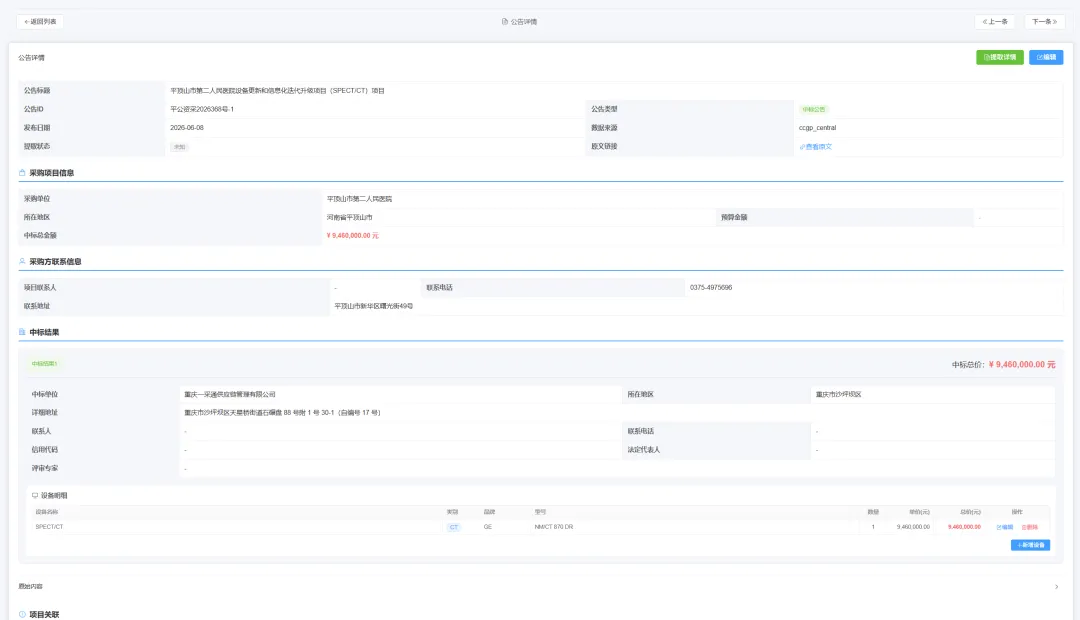
字段是结构化的,不是截图,不是PDF,不是需要人工整理的文档。
之后计划可以实现按设备类型筛选、按金额区间筛选、按地区筛选、按时间范围筛选。
数据躺在数据库里,之后可以查询,可以导出,可以分析。
如果你也在做类似的事
如果你在医疗设备行业,无论你是经销商、服务商、还是研究者:
以前,你需要手动刷政府采购网,找标题包含设备关键词的公告,找到了复制粘贴整理。
现在,系统每天早上自动跑,最新公告入库,数据按结构存储,随时可查询分析。
把”找信息”变成”用信息”。
如果你对这套系统感兴趣,或者你也在想办法把公开数据变成自己的情报库,欢迎交流。
之后的文章,我会讲讲这个系统是怎么从零做起来的——40天里我踩了哪些坑,又是怎样一个一个爬出来的。
系统当前状态:定时采集功能还在完善中。
一句话总结:公开数据就在那里,重要的是你用什么方式把它变成自己的。
图片创作来源于AI,参考链接:暂无
END
欢迎添加微信,请备注单位+姓名
+V:Imaging_Liu

—>扫描二维码,共同交流<—
声明:转载、摘编、复制等使用,需通过本公众号取得授权。