 夜雨聆风
夜雨聆风





AI前沿|开源权重模型登顶:能免费下载的 AI,凭什么追上闭源巨头
导语:一个谁都能免费下载、抱回自家电脑跑的 AI,登上了全球公认的能力榜单第一梯队。这事听着有点反常识——免费的,怎么追得上那些藏着掖着、按次收费的大公司?这篇用大白话讲清楚”开源权重模型”到底是个啥,以及它为什么值得你我多看两眼。

一、先看个有点反常识的新闻
前两天刷到一条 AI 圈的新闻,标题大意是:一个叫 GLM-5.2 的模型,登顶了开源权重模型榜,跟那些闭着门收费的顶级 AI 掰手腕,居然没落下风。 做这个模型的,是中国一家叫智谱(对外用 Z.ai 这个牌子)的实验室。
我第一反应是:等等,哪里不对。
你想啊,咱们平时用的那些大牌 AI——不管是聊天的还是写代码的——基本都是”你掏钱、它给你答”的路子。模型本身锁在人家服务器里,你看不见、摸不着、更下载不走。这很合理,毕竟训练一个顶级模型,烧的是几千万甚至上亿美元的真金白银,凭啥免费给你?
可 GLM-5.2 偏偏反着来:它把模型本体直接放到网上,谁都能下载,抱回自己的服务器随便跑,连商用都不要钱。 而就是这么个”免费送”的东西,在一个挺权威的能力榜单上排到了开源阵营第一,还在一些具体任务上压过了某些收费的闭源大模型。
这就奇怪了。免费的东西,按常理说该是”便宜没好货”,怎么这回反过来了?一个不要钱、还能拷走的 AI,凭什么追上那些估值动辄上千亿美元的巨头?
别急着下结论。这背后藏着这两年 AI 行业一条很关键、但普通人很少听明白的暗线。咱们一层层拆,拆完你会发现,这事跟你我的关系比想象中近。
二、先把骨架立清楚
开拆之前,先把硬事实摆出来。
先立骨架 · 事件速览
-
• 谁 :中国 AI 实验室智谱(对外品牌 Z.ai)发布的大模型 GLM-5.2 。 -
• 啥事 :在第三方评测机构 Artificial Analysis 的”智能指数”上,GLM-5.2 成为领先的开源权重模型 ,综合分约 51 分 ,超过同为开源的 MiniMax-M3 和 DeepSeek V4 Pro(两者约 44 分)。 -
• 时间 :2026 年 6 月中旬发布并开放权重,在程序员社区 Hacker News 获 800 多个赞。 -
• 多大、多便宜 :约 7530 亿 参数(运行时实际激活约 400 亿),支持约 100 万 token 的超长上下文;权重以 MIT 许可证 放出,可免费商用、自行部署。其 API 价格约为同档闭源模型 GPT-5.5 的 六分之一 。
-
• 为何重要 :一个可免费下载、本地运行的模型登顶,意味着”顶级 AI 能力”第一次大规模地,从少数巨头的服务器里,漏到了普通公司和个人手里。
骨架立住了。下面分四层拆:先讲清”开源权重”到底是个啥、跟”开源”差在哪;再算两条路各自的经济账;接着聊为什么中国实验室在这条赛道领先;最后说说让它登顶的榜单到底能信几分。拆完,落到你我身上。
三、第一层:「开源权重」不等于「开源」,这俩字差着十万八千里
要看懂这条新闻,第一个、也是最容易搞混的概念,就是 “开源权重(open weights)” 。很多人一看”开源”俩字就以为是一回事,其实差得远。
结论先放这儿 :开源权重,放出来的只是 AI 的”成品大脑”;真正的开源,还得连”大脑是怎么练出来的”一起公开。前者给你一条鱼,后者教你打渔——现在登顶的这一批,给的基本都是”鱼”。
先说**”权重”是个啥** 。你可以把一个 AI 大模型想象成一个超级复杂的”调音台”,上面有几千亿个旋钮。训练的过程,说白了就是拿海量数据,把这几千亿个旋钮一个个拧到恰到好处的位置——拧好了,这台机器就”会说话、会写代码、会推理”了。这几千亿个旋钮最终的位置,合起来就叫”模型权重”。 它就是这个 AI 的”成品大脑”,整个训练过程最值钱的结晶。
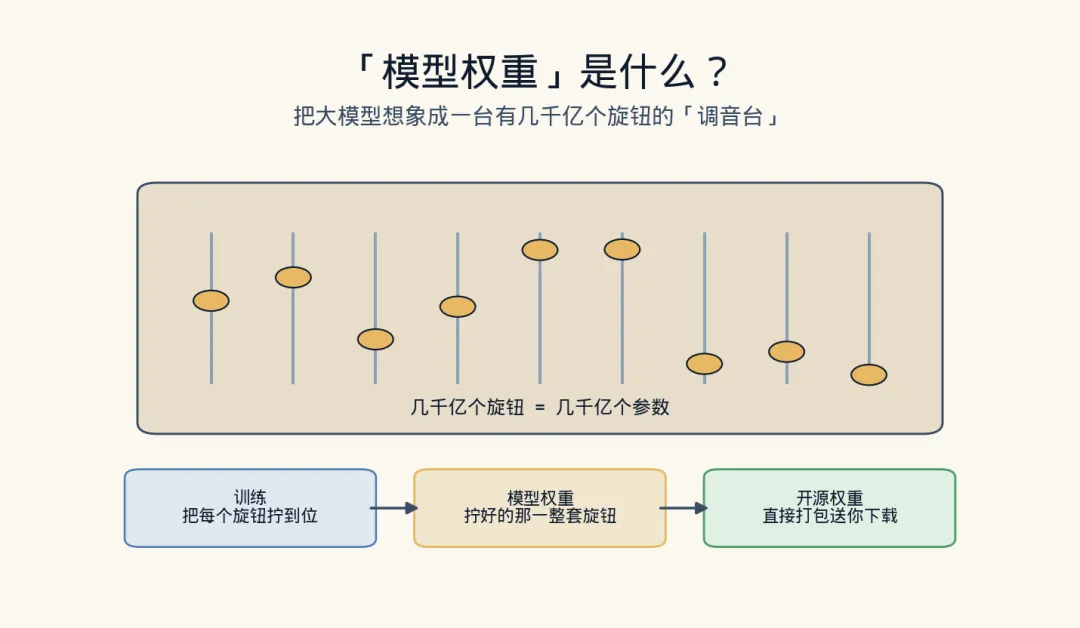
那 “开源权重” 就很直白了:把这套已经拧好的旋钮(权重文件)打包,直接放网上让你下载。 你拿回去装在自己服务器上,这个 AI 就能在你家里跑起来,不用连人家的网、不用看人家脸色。GLM-5.2 干的就是这事,用的还是最宽松的 MIT 许可证——爱怎么用怎么用,商用也行,不收钱。
听起来已经很慷慨了对吧?但它和真正的”开源”,还差着关键一截。
打个比方你就懂了。开源权重,好比一家餐厅把做好的招牌菜 端给你,随便吃、还能拿去摆摊卖,这当然很大方。但你尝得再仔细,也不知道这道菜到底用了哪些食材、什么配方、火候怎么掌握的 ——因为厨房没让你进。
而真正的”开源(open source)”,标准要高得多:按开源促进会(OSI)的定义,得把菜谱、食材清单、连后厨流程都一并公开 ,公开到别人照着就能复刻出”基本一样的菜”。对应到 AI,就是不光给你权重,还得给你训练数据信息、完整的训练代码 ,让别人能从头把这个模型重新训出来。
这就是关键差别 :现在市面上绝大多数号称”开放”的大模型——包括 GLM、包括早年大名鼎鼎的 Llama——给的都是权重,不是全套菜谱 。训练数据用了啥、怎么清洗、训练代码长啥样,往往不公开 。所以严格讲,它们是”开源权重”,不是 完整意义上的”开源”。
那为什么不干脆全公开?两个很现实的原因。一是训练数据是雷区 ——里面可能掺着版权存疑的内容,公开了等于把法律风险全亮给对手;二是训练代码和数据配方就是核心竞争力 ,等于武功秘籍,没人愿意原样奉送。所以”放权重、藏菜谱”,是算过账的最优解:既赚到了开放的名声和生态,又守住了最关键的护城河。
记住这一层就够了:开源权重 ≠ 开源。 你能免费拿到那个”会干活的大脑”,但通常拿不到”它是怎么造出来的”全部秘密。下次再看到”某某模型开源了”,先默念一句:它开的到底是”权重”,还是连菜谱一起的”真开源”?
四、第二层:闭源 vs 开源权重,是两条路、两本经济账
搞懂了”权重是啥”,第二个绕不开的问题就来了:既然权重可以送,那为啥还有那么多顶级 AI 死活不送,非要锁在自己服务器里按次收费?
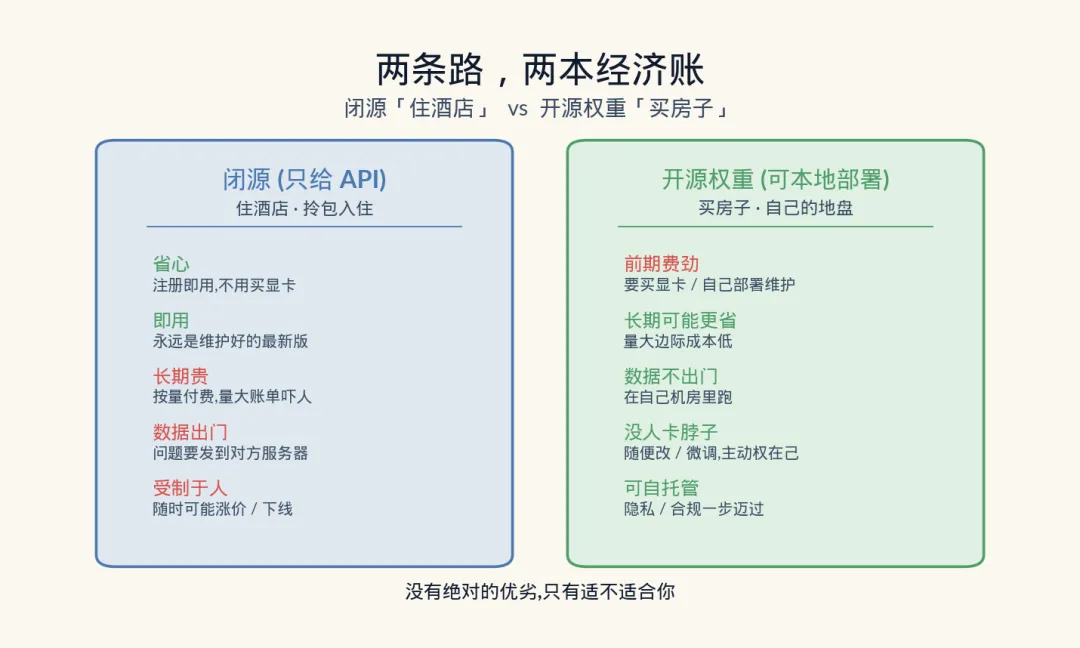
这就引出 AI 世界两条泾渭分明的路线:闭源(只给 API) 和 开源权重(可本地部署) 。它俩不是谁对谁错,而是两套不同的生意经。咱们掰开算算这两本账。
结论先放这儿 :闭源像”住酒店”,开源权重像”买房子”。住酒店省心、即开即用,但长住不划算还得守人家规矩;买房子前期费劲、要自己维护,但住进去就是自己的地盘。选哪条,看你是谁、用多少。
先说闭源这条路,代表是 API-only 模式 。所谓 API,你可以理解成一个”对外服务窗口”。模型本体锁在公司机房里,你够不着,只能隔着窗口递话:把问题发过去,它把答案传回来,按你用了多少字(token)收钱。OpenAI 的不少模型走的就是这路子——你用得上 GPT,但永远摸不到 GPT 本身。
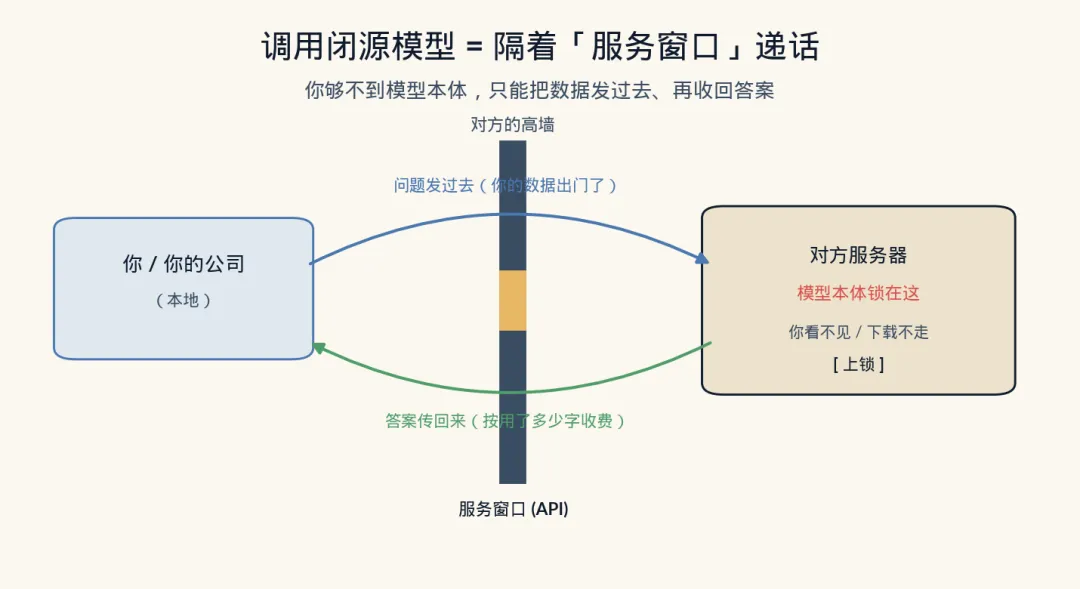
这条路的好处 很实在:省心。 你不用买昂贵的显卡、不用懂部署维护,注册个账号、拿个密钥,几行代码就能用上全世界最强的模型,永远是人家维护好的最新版。对绝大多数”偶尔用用”的场景,这就跟出差住酒店一样,拎包入住。
但这条路的代价 也藏在细节里,主要三条:
一是长期算下来可能很贵。 按量付费,用得越多账单越吓人。业务一旦做大,每天几百万、几千万次调用,那笔钱是流水一样往外淌。
二是数据得交出去。 你每问一句,问题就得发到人家服务器上。对个人聊天没啥,但对医院、律所、银行这种攥着敏感数据的公司,把病历、合同、交易记录发到外部服务器,这关很多时候根本过不了。
三是命门攥在别人手里。 人家随时可能涨价、改规则、限流,甚至哪天把你常用的老模型给下线。你的业务建在别人的地基上,地基怎么动,你说了不算。
再看开源权重这条路,核心就俩字:自托管 。把权重下载下来,部署在自己的服务器上(行话叫”本地部署”或”私有化部署”),从此这个 AI 就是你自己的了。正好补上闭源的三个坑:
第一,长期用,成本可能反而低。 前期你得砸钱买显卡、搭环境,门槛不低。但一旦量大、长期用,”买房”就比”长住酒店”划算——边际成本压得很低,不用每问一句都交一次过路费。GLM-5.2 还有个更狠的点:就算图省事直接用它官方 API,价格也只有同档闭源模型的六分之一 左右。开源权重把整条赛道的价格硬生生往下拽了一大截。
第二,数据不出门。 模型在你自己机房里跑,问它问题,数据压根不离开你的内网。这对”数据绝对不能外泄”的行业,几乎是唯一可行的方案。隐私和合规这道坎,自托管一步迈过。
第三,没人能卡你脖子。 模型在你手上,没人能给你涨价、限流、下线。你想怎么改、怎么微调(拿自己的数据再训一训,让它更懂你的业务),全凭自己。这种”主动权”,花多少钱买 API 都换不来。
所以这两本账,根本不是”谁更先进”,而是”谁更适合你” 。偶尔用用的个人或小团队,闭源 API 省心又划算;用量巨大、或死守数据隐私、或怕被卡脖子的公司,自托管的开源权重就香得很。GLM-5.2 这种登顶的开源权重模型一出现,等于给了后一拨人一个以前不存在的选项:自己家里也能跑上接近顶级水准的 AI。
五、第三层:开源权重这条赛道,为什么近来是中国实验室在领跑
第三个有意思的问题:这两年但凡说起”能打的开源权重模型”,名字总绕不开几家中国实验室——做 DeepSeek 的深度求索、阿里的 Qwen(通义千问)、还有这次登顶的智谱 GLM。这不是巧合,背后有几条挺硬的逻辑。
结论先放这儿 :在闭源这条路上,先发巨头占着身位和算力优势,后来者硬追性价比不高;但开源权重这条路,恰好是后来者弯道超车、攒口碑、聚生态 的最优打法。这不是凑巧,更像是想清楚之后的”集体选择”。

第一条,开源是后来者最快攒口碑、聚人气的办法。 一个新实验室,模型再好,怎么让全世界知道、让全世界信?最快的路就是把权重一放:全球开发者免费下载、上手实测、在 Hugging Face 上刷热度,口碑和生态就这么滚起来了。GLM-5.2 在 Hacker News 上 800 多个赞,就是这套打法的成果。闭源是关起门来自己强,开源是借全世界的手帮你证明你强。 对追赶者来说,后者的杠杆大得多。
第二条,这是一种聪明的”错位竞争”。 在纯比拼闭源旗舰那一档能力上,先发巨头握着海量用户数据和最猛的算力,正面硬刚不一定划算。但开源权重这条赛道,巨头们反而没那么上心 ——毕竟把权重免费送出去,多少会冲击自家”按次收费”的核心生意。这就给了追赶者一个相对空旷的赛道 :你不全力抢,那我就把它做到极致,做成全世界开发者的默认选择。避开对方最硬的正面,专攻对方不愿全力投入的侧翼,这是后来者的经典智慧。
第三条,得轻点一下、但不展开的现实背景 。这两年,先进 AI 芯片的获取受到出口管制等外部因素影响,是公开讨论里绕不开的一环。在算力这种”硬件燃料”受约束的环境下,把有限资源投到”如何把模型做得更高效、更省、更能借生态之力”上,某种程度上也是一种务实应对。这里只点到为止——它是理解整盘棋的一块背景板,但绝不是全部,更不该被简单贴标签、站队。 与此同时,新闻里那条”美国暂缓拉黑 DeepSeek 等百余家企业”,恰恰说明这盘博弈仍在反复拉锯、远未落定。技术归技术,咱们今天聊的是技术这一面。
把这三条并起来看就清楚了:中国实验室在开源权重赛道领跑,不是运气,而是”借开放攒势能 + 错位竞争避锋芒 + 务实利用有限资源”几股劲拧在一起的结果。 而对全世界的普通用户和中小公司来说,这种”神仙打架”的副产品特别实在:能白嫖到的、越来越强的免费模型,一个接一个地冒出来。
六、第四层:那个让它「登顶」的榜单,到底能信几分
聊到这儿,得回头泼盆冷水。这条新闻的核心词是”登顶榜单”——可这个榜单到底是怎么回事?该不该当圣旨?这是最容易被带节奏的一层。
结论先放这儿 :榜单(这里是 Artificial Analysis 的”智能指数”)是个有用的参考系,但绝不是终极真理。 它能帮你快速看清大致格局,但”榜一”不等于”在你的活儿上也最强”。看榜要会看,更要留个心眼,别神化。
先说这榜是个啥 。Artificial Analysis 是一家第三方 评测机构——”第三方”这仨字很重要,它不卖模型、跟谁都没切身利益,相对中立。它搞的”智能指数(Intelligence Index)”,做法说白了就是:拿一大套统一的考题,让各家模型都来考,按总分排个名。 考题涵盖推理、科学、数学、写代码等好几方面,最后揉成一个综合分。GLM-5.2 这次拿了约 51 分,把同为开源的 MiniMax-M3、DeepSeek V4 Pro(都约 44 分)甩在身后,开源第一就是这么来的。
这种榜单有用 ,这点得承认。在模型多如牛毛、各家都自吹天下第一的当下,有一把相对中立、口径统一 的尺子,让大家在同一套题下同台竞技,对普通人快速建立”谁大概在什么段位”的认知——它至少帮你过滤掉了一大堆纯吹牛的。
但为什么不能神化它 ?三个很实在的理由,记牢了:
第一,考得好,不等于用得好。 这就跟高考状元不一定是最好的员工一个道理。榜单考的是标准化考题 ,可你实际要它干的活——比如写你们公司那套祖传代码——榜单根本没考。“综合分第一”和”在你的场景里第一”,完全是两码事。 真要用,自己拿真实任务测一测,比看榜实在一百倍。
第二,考题会被”应试”。 一旦某套评测题出名、成了行业标尺,各家训模型时难免”照着考纲补课”——行话叫”刷榜”或”数据污染”。结果就是榜上分数虚高,到了没见过的新问题面前,未必那么神。所以榜单分数,参考相对高低就好,别当成绝对真理去顶礼膜拜。
第三,”智能”本就难用一个数字概括。 一个模型可能数学贼强但写东西干巴,可能中文很溜但英文一般,可能反应快但偶尔一本正经地胡说八道(行话叫”幻觉”)。把这么多维度硬压成一个”综合分”,必然丢掉大量信息。一个分数,远不足以描述一个模型的全貌。
所以对”GLM-5.2 登顶”这条新闻,正确的姿势 是:把它当成一个强信号 ——”开源阵营又往前进了一大步,到了能跟闭源掰手腕的地步”,这个判断成立。但别 读成”GLM-5.2 现在天下第一”——那就过度解读了。信号,不是判决书。 这盘棋日新月异,今天的榜一下个月可能就被刷下去。看榜的正确心态,是”知道个大概格局”,而不是”押上全部信仰”。
七、那对咱们普通人、中小公司,到底意味着啥
聊了这么多大实验室之间的博弈,落到你我身上,有哪些实打实有用的?挑三条最要紧的。
第一,对普通用户:能免费白嫖的好东西,越来越多了。 开源权重模型一个接一个地变强、变便宜,最直接的好处就是——你能用上的免费或低价 AI 工具,水位整体在往上涨。 哪怕你从不自己部署,光是市面上一堆基于这些开源模型搭出来的免费产品,就够你薅一阵子。巨头神仙打架,红利落到普通人碗里。 多试、多用,别太早把自己绑死在某一个工具上。
第二,对中小公司:你第一次有了”自己养一个 AI”的现实选项。 这是最被低估、也最值钱的一条。过去想用顶级 AI,你只有一条路——给大公司交 API 费,且数据得发出去。现在不一样了:像 GLM-5.2 这种开源权重模型,你可以下载下来部署在自己服务器上,数据一步都不出门。 这对那些手里有敏感数据、又过不了”数据外传”这道合规坎 的行业——医疗、法律、金融、政务——几乎是打开了一扇新门。再算上”长期用成本可能更低””没人能卡你脖子”,“自己养一个懂自家业务的 AI”,从一句空话变成了一道真能算的账。
第三,对所有人:把 AI 当工具,别当信仰。 不管是闭源还是开源、是榜一还是榜十,AI 终归是个用来提效、解决问题的家伙事儿,不是用来膜拜的神。别因为某个模型”登顶了”就无脑追捧,也别因为它”免费”就觉得它一定差。 正确的姿势就一句话:手里多备几把刀,哪把顺手切哪把,但别把整个身家押在任何一把刀上。 模型换得比手机系统还快,唯一靠谱的,是你”会挑、会用、不被牵着走”的判断力。
八、说到底
一个能免费下载、抱回家随便跑的 AI,登上了能力榜单的第一梯队。这事的反常识之处,恰恰戳破了一层窗户纸:顶级 AI 能力,正在从少数巨头的高墙大院里,一点点漏到普通人手里。
但剥开”登顶”这层光环,内核其实很朴素。技术发展到某个节点,总会从”少数人垄断的奢侈品”,慢慢变成”多数人用得起的日用品”—— 电是这样,汽车是这样,互联网是这样,今天轮到了 AI。开源权重模型,就是把这个”飞入寻常百姓家”的进程又往前狠狠推了一把。
至于谁是榜一、谁能笑到最后,几个月后又是另一番光景,没必要太较真。真正确定的是这条大趋势:能力在扩散,门槛在变低,选择在变多。 而看懂了”开源权重”这四个字背后的门道,你就比大多数人多了一份在这场变局里不被忽悠的底气。
说到底,这世界的逻辑往往就是这么朴素:好东西一旦能被复制、被分享,就再也关不回笼子里。
参考来源
-
• Artificial Analysis:《GLM-5.2 is the new leading open weights model on the Artificial Analysis Intelligence Index》(GLM-5.2 登顶开源权重模型榜,综合分约 51,领先 MiniMax-M3、DeepSeek V4 Pro 约 44 分)。 -
• AI Weekly:《Zhipu AI’s GLM-5.2 Tops Open-Weights Intelligence Index With Score of 51》(综合分 51、智能指数 v4.1)。 -
• VentureBeat:《Z.ai’s open-weights GLM-5.2 beats GPT-5.5 on multiple long-horizon coding benchmarks for 1/6th the cost》(部分长程编程基准超 GPT-5.5、价格约六分之一、MIT 许可证)。 -
• Simon Willison:《GLM-5.2 is probably the most powerful text-only open weights LLM》(开源权重、参数与上下文规模);DeepLearning.AI The Batch《Zhipu’s GLM-5.2 is the new top open model》。 -
• 路透社 / CNBC:《U.S. holds off blacklisting China’s DeepSeek, more than 100 firms deemed security risks》(2026-06-17,美国暂缓将 DeepSeek 等 100 余家企业列入实体清单)。 -
• Open Source Initiative / hellofuture.orange.com 等:开源权重 vs 开源 vs 闭源的定义辨析(开源权重放出可下载权重但通常不公开训练数据与代码;OSI 定义的开源要求公开训练数据信息与完整训练代码)。 -
• 每日热点 2026-06-19「AI 热点」板块:GLM-5.2 登顶 Artificial Analysis 开源权重榜、美国暂缓拉黑 DeepSeek。
配图来源
-
• 开源模型-封面 / 01 / 02 / 03:本地生成(标题金句卡、”权重=旋钮”概念卡、闭源调用窗口示意图、”住酒店 vs 买房子”结构对照卡;概念与数据见正文及上方参考来源)。 -
• 开源模型-网络1: Hf-logo-with-title.svg(Hugging Face 标识),来自 Wikimedia Commons,授权以 Commons 文件页为准。 -
• 开源模型-网络2: Artificial neural network.svg(人工神经网络示意图),来自 Wikimedia Commons,授权以 Commons 文件页为准。